ICML 2026 | EvoGM : fusion de grands modèles autonome via l’évolution de population, sans réentraînement

Résumé
Avec l’amélioration continue des capacités des grands modèles de langage, le nombre de modèles experts obtenus par fine-tuning sur différentes tâches ne cesse de croître. Comment réutiliser efficacement les capacités de ces modèles experts sans réentraîner les grands modèles impliqués dans la fusion et sans dépendre de données d’entraînement à grande échelle supplémentaires constitue une question centrale dans la fusion de modèles. Les méthodes existantes reposent généralement sur la fusion moyenne, le scaling manuel, le pruning de paramètres ou la recherche aléatoire. Bien qu’elles permettent de combiner les capacités de plusieurs modèles à un certain niveau, elles peinent à apprendre continuellement des évaluations historiques et à améliorer les stratégies de fusion.
Pour répondre à ce problème, l’équipe EvoX en collaboration avec le Peng Cheng Laboratory propose EvoGM (Evolutionary Generative Merging), un framework de fusion évolutive générative qui transforme la recherche des coefficients de fusion en un problème d’optimisation générative apprenable. EvoGM organise différentes configurations de fusion en une population de candidats et, grâce au pairing winner-loser, à l’entraînement de double générateur, aux contraintes de cohérence cyclique et à la mise à jour évolutive de la base d’experts, fait évoluer la population dans une boucle fermée de « génération — évaluation — sélection — réapprentissage », apprenant autonomement à partir de retours de validation limités comment transformer des configurations de faible performance en configurations de haute performance. Les résultats expérimentaux montrent que EvoGM démontre une capacité de fusion de modèles plus forte dans les scénarios de tâches vues et non vues.
I. Pourquoi avons-nous besoin de la fusion de modèles ?
Ces dernières années, les capacités des grands modèles de langage se renforcent, mais les coûts d’entraînement et de fine-tuning augmentent également. Une question naturelle se pose : si nous avons déjà plusieurs modèles experts performants sur différentes tâches, peut-on combiner leurs capacités sans réentraîner ces grands modèles, pour obtenir un nouveau modèle plus puissant et plus général ?
C’est précisément le problème que la fusion de modèles cherche à résoudre.
L’idée centrale de la fusion de modèles est directe : plusieurs modèles experts partagent souvent le même modèle de base, mais ont été fine-tunés sur différentes données ou tâches. On peut donc considérer les variations de paramètres de chaque modèle expert par rapport au modèle de base comme des « directions de capacité », puis combiner ces directions pondérées pour construire un nouveau modèle fusionné. L’avantage est qu’il n’est pas nécessaire de réentraîner ou de fine-tuner les grands modèles impliqués, ni de dépendre de données d’entraînement à grande échelle supplémentaires — il suffit de rechercher les coefficients de fusion appropriés. Il convient de préciser que EvoGM entraîne des générateurs légers pour rechercher les coefficients, mais ne met pas à jour les paramètres des grands modèles experts.
II. Où se situe la véritable difficulté de la fusion de modèles ?
La véritable difficulté réside ici : comment choisir ces coefficients ?
La fusion de modèles semble n’être qu’une combinaison pondérée de plusieurs modèles experts, mais les relations de capacité entre différents modèles experts ne sont pas simples. Certaines directions de tâches peuvent se compléter, tandis que certaines mises à jour de paramètres peuvent entrer en conflit ; une combinaison de coefficients de fusion peut performer mieux sur un type de tâches, mais entraîner une perte de performance sur un autre. La relation entre les coefficients de fusion et la performance finale du modèle n’est donc pas une relation linéaire facile à caractériser manuellement.
Les méthodes traditionnelles reposent généralement sur des règles heuristiques telles que la fusion moyenne, le scaling manuel, le pruning de paramètres ou la sparsification. Ces méthodes sont simples et efficaces, mais présentent des limites évidentes : elles sont souvent statiques et empiriques, et peinent à s’adapter en fonction des retours de validation de différentes tâches.
Plus tard, des méthodes de recherche évolutive ont été introduites dans la fusion de modèles, organisant les configurations candidates en populations et recherchant de meilleurs coefficients par perturbation aléatoire, évaluation de fitness et sélection. Ces méthodes sont plus flexibles que les règles fixes, mais un problème clé persiste : les résultats de validation sont généralement utilisés uniquement pour le classement et le filtrage, sans être transformés en expérience de recherche apprenable. En d’autres termes, l’algorithme sait « quel candidat est meilleur », mais n’apprend pas vraiment « comment un candidat moins performant devrait s’améliorer ».
C’est le problème central que EvoGM cherche à résoudre : la fusion de modèles ne devrait pas se limiter à faire essayer et filtrer continuellement une population de candidats, mais devrait apprendre des directions d’amélioration à partir des évaluations historiques et générer autonomement des configurations de fusion plus prometteuses.
III. EvoGM : faire apprendre la stratégie de fusion dans l’évolution de population
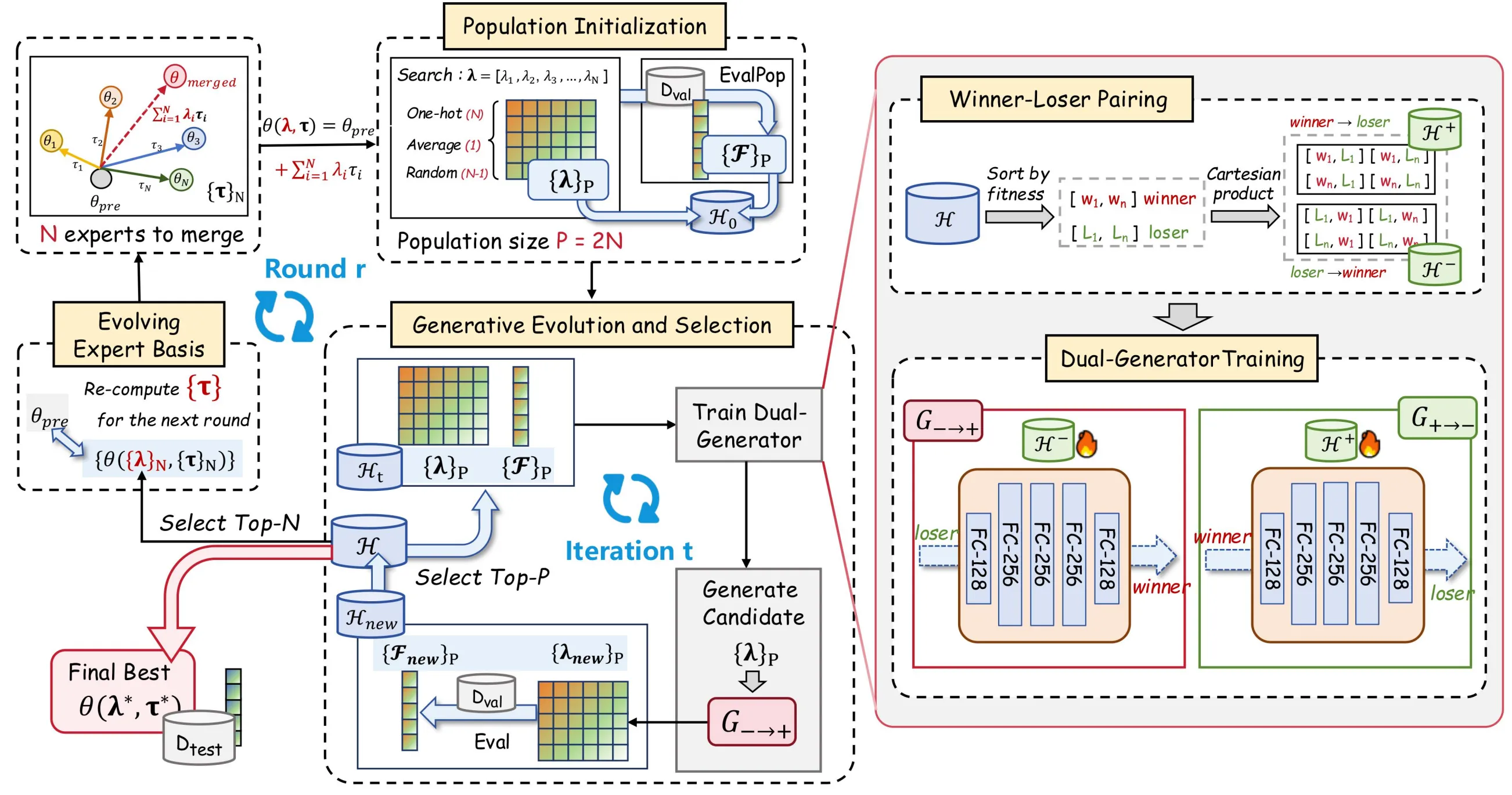
Pour résoudre les problèmes ci-dessus, nous proposons EvoGM (Evolutionary Generative Merging), dont le code est open source : https://github.com/JiangTao97/evogm.
L’idée centrale de EvoGM est d’organiser les configurations candidates de fusion en une population et de transformer le processus de recherche des coefficients de fusion en un problème d’apprentissage générative.
L’essentiel est que le modèle génératif n’apprend pas directement « quels sont les coefficients de fusion optimaux », mais plutôt « comment transformer une configuration moins performante en une configuration plus performante ». En effet, dans le contexte de la fusion de modèles, il est difficile d’établir un classement global fiable entre différentes configurations ; en comparaison, les comparaisons par paires fournissent des signaux de supériorité plus stables.
EvoGM utilise les résultats de validation historiques pour construire des données de pairing winner-loser, permettant au générateur d’apprendre la direction d’amélioration du loser vers le winner. Pour chaque paire de configurations candidates de fusion, l’algorithme enregistre non seulement leurs différences de performance, mais transforme également cette relation « de mauvais à bon » en échantillons d’entraînement. Grâce à l’accumulation et l’apprentissage continus, le générateur peut progressivement saisir quels ajustements de coefficients sont plus susceptibles d’améliorer la performance, formant ainsi une compréhension implicite de la structure de l’espace de recherche. En d’autres termes, il apprend non pas les solutions excellentes en elles-mêmes, mais les lois de l’amélioration de performance.
Cette approche s’inscrit dans la continuité des mécanismes d’apprentissage compétitif en optimisation évolutive. Elle remonte au CSO (Competitive Swarm Optimizer), qui pousse les individus à se mettre à jour par la compétition winner-loser, faisant que les individus moins performants se rapprochent des plus performants ; EvoGO (Evolutionary Generative Optimization) exploite davantage les modèles génératifs pour apprendre les directions d’amélioration à partir des données de recherche historiques, remplaçant par une approche data-driven une partie des opérateurs de recherche conçus manuellement. EvoGM introduit cette idée dans le contexte de la fusion de modèles, entraînant le générateur par les retours de validation pour guider la recherche ultérieure. Ainsi, les résultats de validation ne servent plus uniquement à filtrer et éliminer les candidats, mais sont continuellement transformés en expérience de recherche réutilisable, permettant au processus de recherche d’accumuler des connaissances et d’améliorer son efficacité au fil des itérations.
IV. Comment fonctionne EvoGM ?
Le processus global de EvoGM peut être divisé en cinq étapes : construction des candidats, formation des paires d’entraînement winner-loser, entraînement du générateur, génération et sélection de nouveaux coefficients, et mise à jour de la base d’experts. Une fois les modèles experts et les tâches de validation définis, ces étapes peuvent s’exécuter automatiquement en boucle, sans intervention manuelle pour concevoir les règles de fusion ou ajuster les coefficients à chaque itération.
- Initialisation de la population : construction des candidats de fusion
EvoGM commence par construire un ensemble de candidats initiaux. Chaque candidat correspond à une combinaison de coefficients de fusion, c’est-à-dire une façon différente de combiner plusieurs modèles experts.
Concrètement, la population initiale inclut généralement plusieurs types de configurations : les coefficients correspondant à la fusion moyenne, les coefficients one-hot correspondant à un seul modèle expert, et les coefficients de fusion obtenus par échantillonnage aléatoire. Cela permet de couvrir certaines méthodes de fusion de référence courantes tout en offrant une diversité suffisante pour la recherche ultérieure.
Pour chaque combinaison de coefficients candidats, EvoGM construit un modèle fusionné et évalue sa performance sur le jeu de validation. Après cette étape, l’algorithme obtient non seulement plusieurs modèles candidats, mais aussi un ensemble d’enregistrements historiques « coefficients de fusion — performance de validation ». Tout l’apprentissage générative et la sélection évolutive ultérieurs reposent sur ces enregistrements.
- Pairing winner-loser : transformer les résultats de validation en données d’entraînement
Une fois les candidats et leurs performances de validation obtenus, EvoGM divise les configurations candidates historiques en winner et loser selon leur performance. Le winner représente une configuration de fusion relativement meilleure, le loser une configuration relativement moins performante.
L’essentiel ici n’est pas simplement de conserver les configurations à score élevé et d’écarter les configurations à score faible, mais de les former en paires d’entraînement. Pour le générateur, une paire winner-loser fournit une information utile : depuis cette configuration moins performante, vers quelle configuration plus performante devrait-on se rapprocher ?
Ainsi, les candidats de faible performance ne sont pas des échantillons invalides. Ils fournissent plutôt le « point de départ » du processus de recherche, tandis que les candidats de haute performance fournissent la « direction d’amélioration ». Par ce mode de pairing, EvoGM peut transformer les résultats limités d’évaluation de validation en davantage de signaux de supervision apprenables, améliorant l’efficacité d’utilisation des données sous retour à petit échantillon.
- Entraînement de double générateur : apprendre la transformation de mauvaises configurations vers de bonnes configurations
Après la construction des paires d’entraînement winner-loser, EvoGM utilise une structure de double générateur pour l’entraînement.
Le générateur forward apprend le mapping du loser vers le winner, c’est-à-dire la transformation d’une configuration de fusion de faible performance vers une configuration de haute performance plus prometteuse. Le générateur backward apprend le mapping inverse du winner vers le loser, servant à contraindre la cohérence structurelle du processus de génération.
Cette conception ne vise pas à faire mémoriser au générateur les configurations à score élevé existantes, mais à lui faire apprendre les lois d’amélioration dans l’espace des coefficients de fusion. Grâce aux contraintes de cohérence cyclique, EvoGM peut réduire le risque que le générateur se réduise à quelques points à score élevé, permettant aux configurations candidates générées de se diriger vers les régions de haute performance tout en conservant autant que possible les informations structurelles de l’espace de recherche.
- Évolution générative et sélection : remplacer la perturbation aléatoire par des opérateurs appris
Une fois l’entraînement du générateur terminé, EvoGM utilise le générateur forward pour transformer les configurations candidates actuelles et générer un nouvel ensemble de coefficients de fusion. Cette étape correspond à la « production de nouveaux individus » dans les algorithmes évolutifs traditionnels, mais les nouveaux individus ne proviennent plus principalement de perturbations aléatoires, mais des directions d’amélioration apprises par le modèle génératif.
Ensuite, ces nouveaux coefficients de fusion générés sont utilisés pour construire de nouveaux modèles fusionnés et sont réévalués sur le jeu de validation. Les résultats d’évaluation sont ajoutés aux enregistrements historiques et participent à la sélection avec les candidats existants.
Par cette boucle, EvoGM traverse à chaque itération un processus de « génération — évaluation — sélection — réapprentissage ». Cette boucle fermée constitue l’évolution de population des candidats de fusion : les résultats de validation historiques s’accumulent continuellement, le générateur obtient de nouveaux signaux d’entraînement, améliorant progressivement sa capacité à générer autonomement des configurations de fusion de haute qualité.
- Base d’experts évolutive : faire évoluer continuellement l’espace de recherche
En plus d’optimiser les coefficients de fusion, EvoGM introduit davantage un mécanisme de base d’experts évolutive.
La fusion de modèles traditionnelle considère généralement les modèles experts comme des entrées fixes, recherchant uniquement les coefficients de fusion entre des modèles experts fixes. EvoGM est différent : après chaque itération, les meilleurs modèles fusionnés sont sélectionnés pour servir de nouvelle base d’experts dans la recherche de l’itération suivante.
L’intérêt de cette approche est que les excellents modèles fusionnés contiennent déjà certaines combinaisons de capacités efficaces. Une fois intégrés dans la nouvelle base d’experts, la recherche ultérieure n’est plus limitée à des combinaisons linéaires entre les modèles experts originaux, mais peut continuer à évoluer sur des modèles intermédiaires déjà validés comme efficaces.
Ainsi, l’espace de recherche de EvoGM n’est pas fixe, mais se met à jour continuellement au fil du processus de recherche. Il ne cherche pas seulement de meilleurs coefficients de fusion, mais construit progressivement une base de représentation d’experts plus adaptée à la tâche actuelle.
V. Quels sont les avantages clés de EvoGM ?
Par rapport aux méthodes traditionnelles de fusion de modèles, les avantages de EvoGM se manifestent principalement en trois aspects.
Premièrement, EvoGM fait progresser la fusion de modèles des règles heuristiques statiques vers une recherche autonome pilotée par les retours. Les méthodes traditionnelles reposent souvent sur la fusion moyenne, le scaling manuel ou la perturbation aléatoire, tandis que EvoGM peut ajuster continuellement la direction de recherche selon les résultats de validation historiques, rendant le processus de fusion indépendant de la conception manuelle des règles et de l’ajustement des coefficients à chaque itération.
Deuxièmement, EvoGM améliore l’efficacité d’utilisation des données sous budget d’évaluation limité. Dans la fusion de modèles, chaque évaluation d’une configuration candidate nécessite la construction effective d’un modèle fusionné et l’exécution des tâches de validation, ce qui n’est pas peu coûteux. EvoGM transforme davantage ces résultats d’évaluation en signaux d’entraînement apprenables, permettant à chaque essai de fournir des informations pour la recherche ultérieure.
Enfin, EvoGM ne cherche pas seulement une meilleure combinaison de coefficients de fusion, mais apprend progressivement les lois de combinaison des capacités entre modèles experts. Grâce à la recherche générative de la population de candidats et à la mise à jour de la base d’experts, il peut continuellement recombiner et étendre l’espace de recherche sur la base des modèles experts existants, découvrant plus efficacement des modèles fusionnés de haute performance.
VI. Résultats expérimentaux : EvoGM est-il vraiment efficace ?
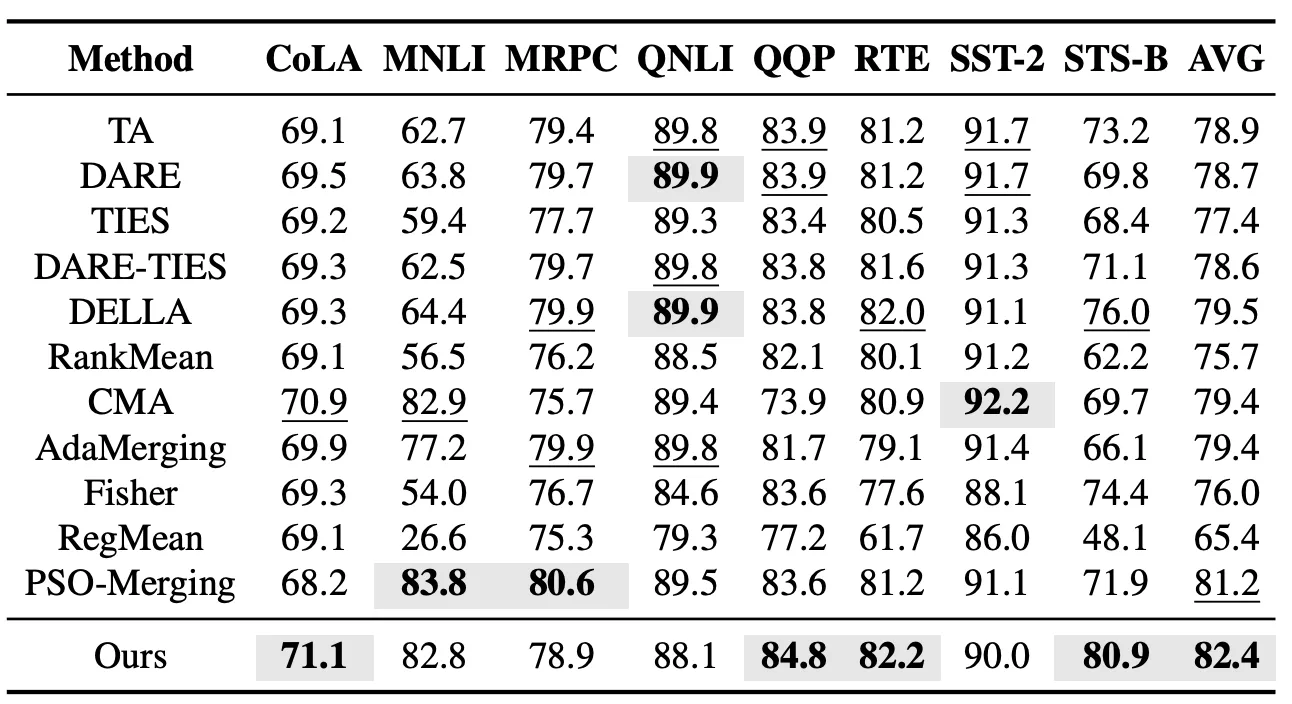
Dans le cadre des tâches vues, nous évaluons d’abord l’effet de fusion de modèles de EvoGM sur les tâches de la série GLUE. Cette expérience couvre 8 tâches de compréhension du langage : CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2 et STS-B, et compare EvoGM à des méthodes représentatives de fusion de modèles telles que Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging et PSO-Merging. Les résultats montrent que EvoGM surpasse le PSO-Merging, précédemment le meilleur, en performance moyenne sur les 8 tâches.
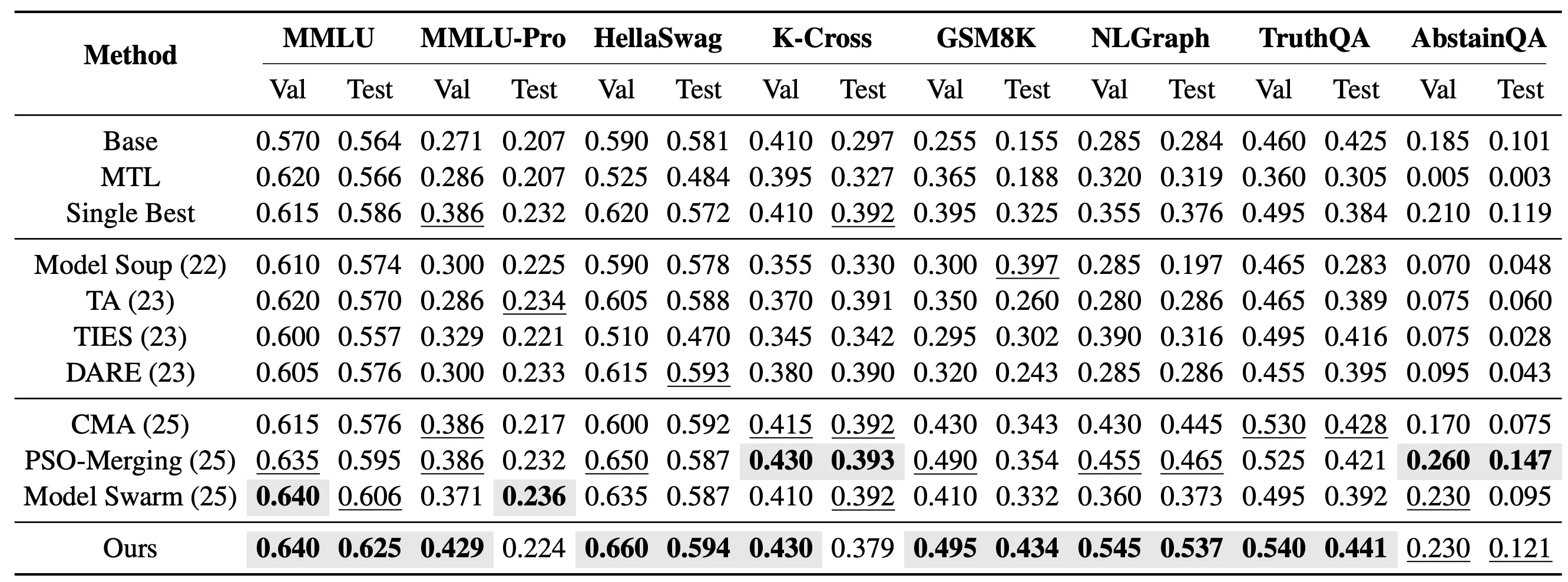
Dans le cadre plus exigeant des tâches non vues, nous évaluons davantage si EvoGM peut transférer les capacités des modèles experts existants vers de nouvelles tâches qui n’ont pas participé au fine-tuning des experts. Concrètement, nous fusionnons 10 modèles experts LoRA basés sur Qwen2.5-1.5B et testons sur 8 tâches non vues : MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA et AbstainQA. Ces tâches couvrent différentes dimensions de capacité telles que la compréhension des connaissances, le raisonnement complexe et la fiabilité de sécurité, reflétant mieux que les tâches vues la capacité de généralisation des méthodes de fusion de modèles.
Dans le cadre de fusion non vue mono-tâche, EvoGM recherche une combinaison de coefficients de fusion pour chaque tâche cible respectivement. Les résultats montrent que EvoGM obtient la performance de test la plus élevée sur 5 des 8 tâches de test.
Au-delà de la fusion mono-tâche, nous examinons davantage le cadre de fusion non vue multi-tâches. Dans ce cadre, l’objectif n’est plus de trouver le modèle optimal pour chaque tâche individuellement, mais d’obtenir un modèle fusionné unifié capable de couvrir simultanément les 8 tâches non vues. Les résultats expérimentaux montrent que dans la fusion non vue multi-tâches, EvoGM obtient la performance de test moyenne la plus élevée parmi toutes les méthodes de fusion.
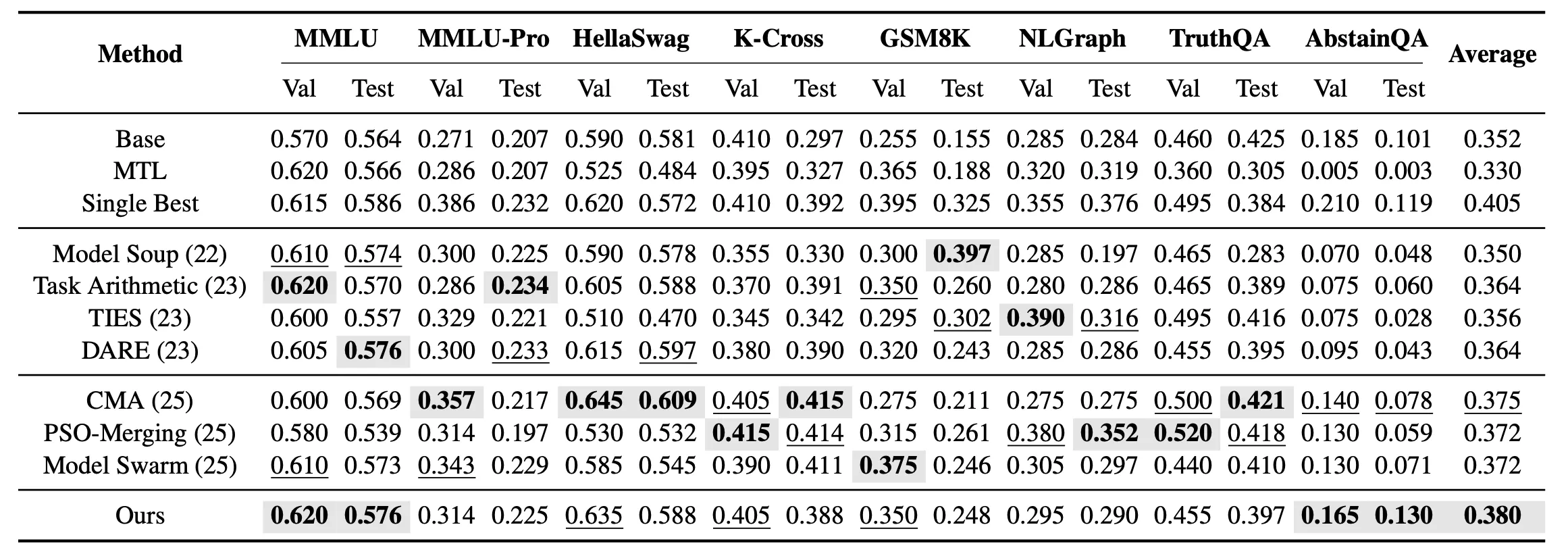
Les résultats montrent que EvoGM obtient une performance de généralisation globale plus forte dans les cadres de fusion mono-tâche et multi-tâches, surpassant les méthodes existantes de fusion de modèles sur plusieurs tâches liées aux connaissances, au raisonnement et à la sécurité.
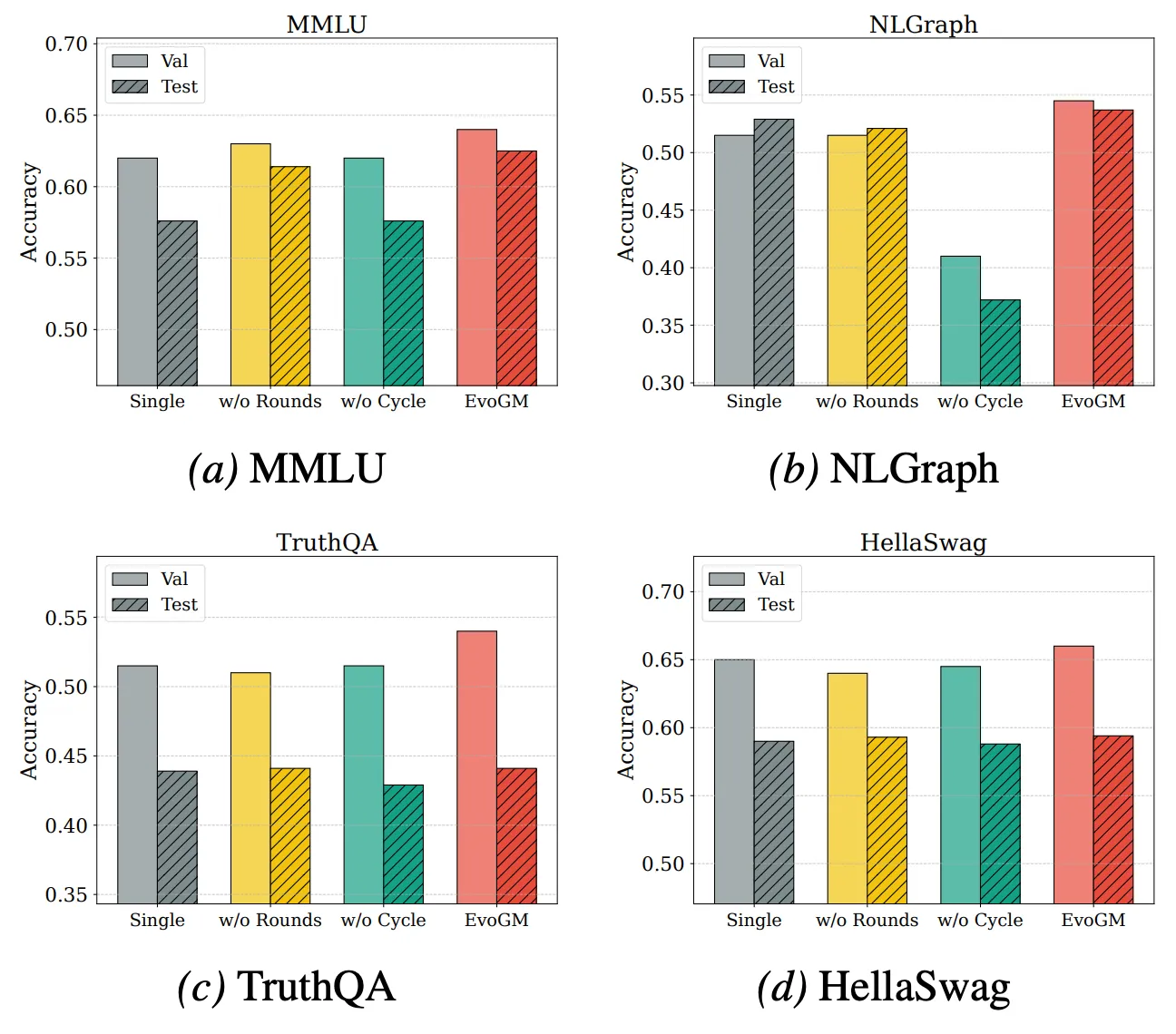
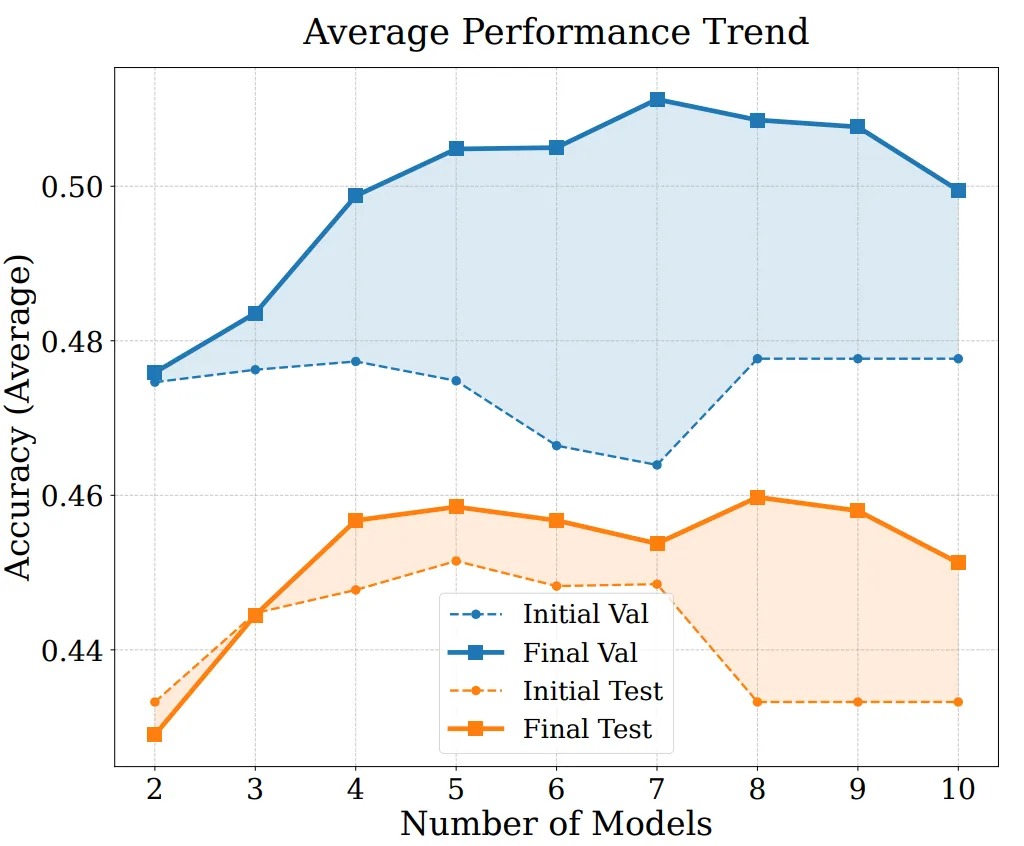
Pour analyser davantage les sources de performance et les capacités d’extension de EvoGM, nous avons mené des expériences d’ablation et des expériences de fusion avec différents nombres de modèles. Les résultats montrent que EvoGM complet obtient toujours la performance optimale ou la plus stable ; après suppression des composants clés, la performance diminue à des degrés divers, indiquant que ses avantages proviennent principalement du mécanisme d’évolution générative, et non d’une simple recherche aléatoire ou de plus d’itérations de recherche. Parallèlement, lorsque le nombre de modèles experts impliqués dans la fusion augmente, EvoGM maintient une bonne performance et montre une tendance d’amélioration stable, indiquant qu’il peut efficacement gérer des espaces de fusion plus grands et plus complexes, exploiter pleinement les capacités complémentaires entre différents modèles experts, et possède une bonne extensibilité.
VII. De EvoGO à EvoGM : l’extension de l’idée d’évolution générative
D’un point de vue plus large, EvoGM peut être compris comme une extension de l’idée EvoGO dans la fusion de grands modèles. EvoGO se concentre sur la question de comment faire évoluer l’optimisation évolutive de l’opérateur de croisement, de mutation et de perturbation conçu manuellement vers un apprentissage automatique par le modèle génératif de nouvelles façons de générer des solutions à partir des données de recherche historiques. Autrement dit, la recherche évolutive ne se contente plus de « générer aléatoirement des candidats et filtrer », mais commence à apprendre « comment générer des candidats plus prometteurs ».
EvoGM applique cette idée au contexte de la fusion de grands modèles. Ici, les candidats ne sont plus des variables numériques dans un problème d’optimisation général, mais une combinaison de coefficients de fusion ; une évaluation n’est plus un simple calcul de fonction objectif, mais la construction d’un modèle fusionné et la validation de sa performance sur des tâches en aval. EvoGM reformule donc la fusion de modèles en un problème d’optimisation générative : comment apprendre des résultats d’évaluation historiques les lois de combinaison des capacités entre modèles experts, et générer de meilleures configurations de fusion.
Cela distingue clairement EvoGM des méthodes traditionnelles de fusion de modèles par recherche. Les méthodes traditionnelles utilisent généralement les résultats de validation uniquement pour le classement et le filtrage, tandis que EvoGM transforme davantage les résultats de validation en signaux d’entraînement. Les configurations de faible performance ne sont pas simplement écartées, mais formées en paires winner-loser avec les configurations de haute performance pour entraîner le générateur à apprendre la direction d’évolution de mauvaises configurations vers de bonnes configurations.
De EvoGO à EvoGM, il s’agit essentiellement du passage de « apprendre à optimiser les candidats » à « faire évoluer autonomement la stratégie de fusion de grands modèles dans la population ». Cela libère non seulement la fusion de modèles des règles empiriques et des perturbations aléatoires, mais offre également une nouvelle perspective : les capacités des grands modèles peuvent être fusionnées, et la stratégie de fusion elle-même peut continuer à apprendre des retours de population.
VIII. Conclusion et perspectives
Avec l’augmentation continue des modèles experts, des modèles LoRA et des modèles de tâches dans l’écosystème open source, la question clé de l’avenir pourrait ne plus être « comment entraîner un nouveau modèle », mais « comment combiner efficacement les capacités des modèles existants ». EvoGM offre une nouvelle réponse : sans réentraîner les grands modèles impliqués dans la fusion, il utilise l’apprentissage évolutif générative pour exploiter des retours de validation limités et accomplir autonomement la construction de la population de candidats, la génération des plans de fusion, la sélection par évaluation et la mise à jour de la base d’experts. En bref, EvoGM fait évoluer la fusion de modèles de « ajuster les coefficients par expérience » vers « faire apprendre et évoluer la stratégie de fusion elle-même ». Cela signifie également que la réutilisation des capacités des grands modèles pourrait entrer dans une nouvelle phase : plutôt que de réentraîner un modèle pour chaque nouvelle tâche, les modèles experts existants peuvent, par l’évolution de population et la fusion autonome, continuer à combiner des modèles plus adaptés aux nouvelles tâches.
Code open source / Communauté
📄 Article : https://arxiv.org/pdf/2605.29295 🔗 GitHub :
https://github.com/JiangTao97/evogm 🔼 Projet parent (EvoX) :
https://github.com/EMI-Group/evox 🌐 Groupe QQ : 297969717
