ICML 2026 | EvoGM: автономное слияние больших моделей через популяционную эволюцию без переобучения

Аннотация
По мере роста возможностей больших языковых моделей увеличивается и число экспертных моделей, дообученных под конкретные задачи. Эффективное повторное использование возможностей таких экспертных моделей без переобучения участвующих в слиянии больших моделей и без опоры на дополнительные крупномасштабные обучающие данные становится ключевой проблемой в области слияния моделей. Существующие методы обычно опираются на усреднение, ручное масштабирование, обрезку параметров или случайный поиск. Хотя они в определённой степени позволяют комбинировать возможности нескольких моделей, им трудно непрерывно учиться на исторических оценках и улучшать стратегию слияния.
Для решения этой проблемы команда EvoX совместно с лабораторией Peng Cheng представляет EvoGM (Evolutionary Generative Merging) — эволюционный генеративный фреймворк слияния моделей, который преобразует поиск коэффициентов слияния в обучаемую задачу генеративной оптимизации. EvoGM организует различные конфигурации слияния в популяцию кандидатов и посредством winner-loser пар, обучения двух генераторов, ограничений циклической согласованности и эволюционного обновления экспертной базы обеспечивает непрерывную эволюцию популяции в замкнутом цикле «генерация—оценка—отбор—повторное обучение», автономно обучаясь на ограниченной валидационной обратной связи преобразовывать конфигурации с низкой производительностью в конфигурации с высокой производительностью. Экспериментальные результаты показывают, что EvoGM демонстрирует более сильные возможности слияния моделей как в сценариях с видимыми, так и с невидимыми задачами.
I. Зачем нужно слияние моделей?
В последние годы возможности больших языковых моделей неуклонно растут, но вместе с ними растут и затраты на обучение и дообучение. Возникает естественный вопрос: если у нас уже есть несколько экспертных моделей, хорошо работающих на разных задачах, можно ли объединить их возможности и получить более мощную и универсальную новую модель, не переобучая эти большие модели?
Именно эту задачу и решает слияние моделей.
Основная идея слияния моделей проста: несколько экспертных моделей обычно происходят от одной базовой модели и лишь дообучены на разных данных или задачах. Поэтому изменение параметров каждой экспертной модели относительно базовой можно рассматривать как «направление способности», а затем взвешенно комбинировать эти направления для построения новой объединённой модели. Преимущество в том, что не требуется переобучать или дообучать участвующие в слиянии большие модели и не нужны дополнительные крупномасштабные обучающие данные — достаточно найти подходящие коэффициенты слияния. Следует отметить, что EvoGM обучает лёгкие генераторы для поиска коэффициентов, но не обновляет параметры экспертных больших моделей.
II. В чём заключается настоящая сложность слияния моделей?
Настоящая сложность именно здесь: как выбирать эти коэффициенты?
Слияние моделей кажется простым взвешенным объединением нескольких экспертных моделей, однако отношения между их способностями далеки от простоты. Некоторые направления задач могут дополнять друг друга, а некоторые обновления параметров — конфликтовать; один набор коэффициентов слияния может лучше работать на одном типе задач и ухудшать производительность на другом. Следовательно, связь между коэффициентами слияния и итоговой производительностью модели не является легко описываемой вручную линейной зависимостью.
Традиционные методы обычно опираются на эвристические правила: усреднение, ручное масштабирование, обрезку параметров или разреживание. Эти методы просты и эффективны, но имеют очевидные ограничения: они, как правило, статичны и эмпиричны, и им трудно адаптивно настраиваться на основе валидационной обратной связи для разных задач.
Позже в слияние моделей были введены методы эволюционного поиска, организующие кандидатные конфигурации слияния в популяцию и ищущие лучшие коэффициенты через случайные возмущения, оценку приспособленности и отбор. Такие методы гибче фиксированных правил, но по-прежнему имеют ключевую проблему: результаты валидации обычно используются лишь для ранжирования и фильтрации, не превращаясь в обучаемый поисковый опыт. Иными словами, алгоритм знает, «какой кандидат лучше», но не учится по-настоящему, «как более слабый кандидат должен улучшиться».
Это и есть центральная проблема, которую EvoGM стремится решить: слияние моделей не должно сводиться к бесконечным пробам и отбору в популяции кандидатов — оно должно учиться на исторических оценках направлениям улучшения и автономно генерировать более перспективные конфигурации слияния.
III. EvoGM: автономное обучение стратегии слияния в популяционной эволюции
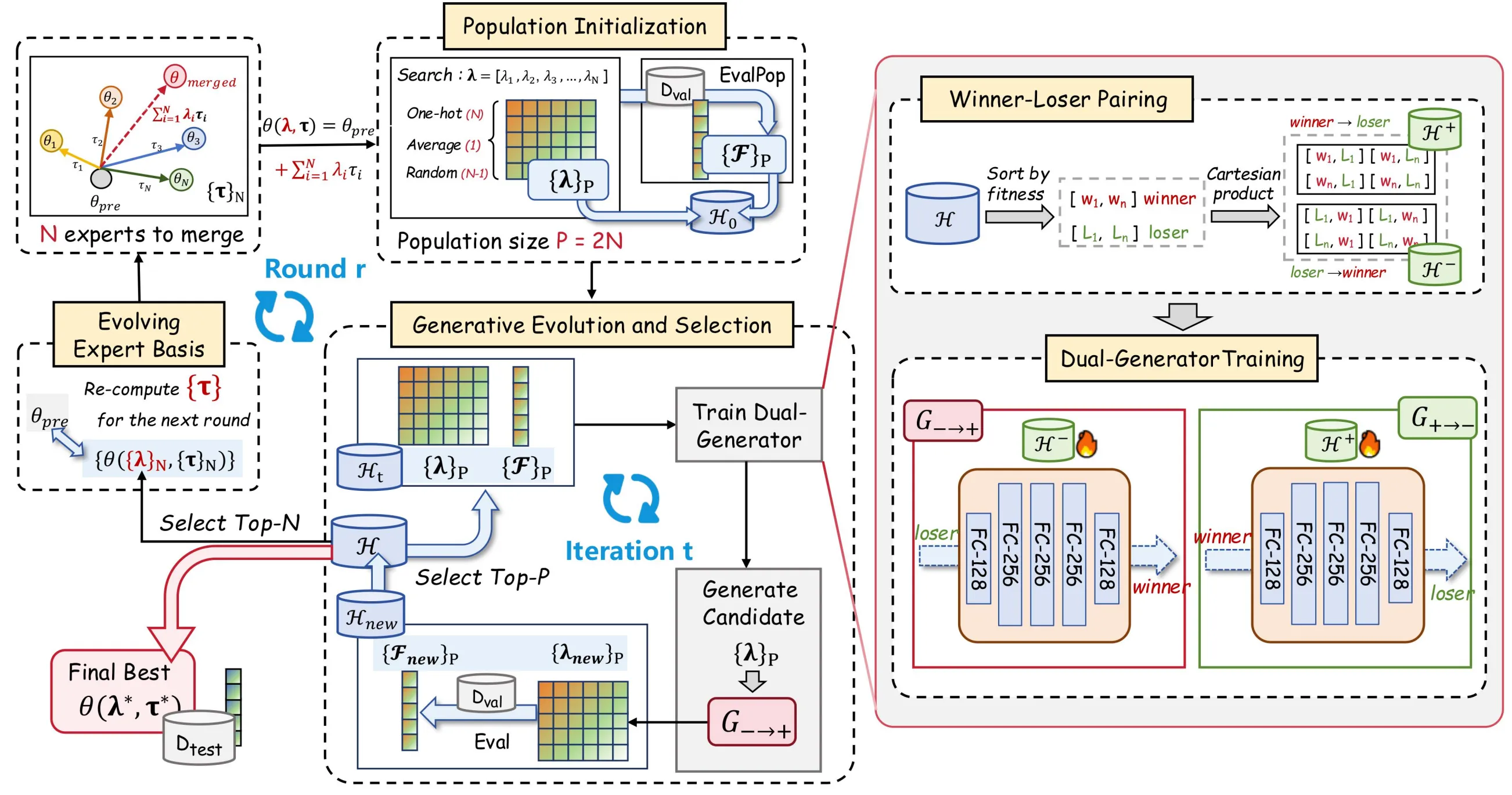
Для решения описанных проблем мы предлагаем EvoGM (Evolutionary Generative Merging); код уже открыт: https://github.com/JiangTao97/evogm.
Ключевая идея EvoGM — организовать кандидатные конфигурации слияния в виде популяции и преобразовать процесс поиска коэффициентов слияния в задачу генеративного обучения.
Важно, что генеративная модель обучается не напрямую отвечать на вопрос «каковы оптимальные коэффициенты слияния», а «как перейти от более слабой конфигурации к более сильной». В сценариях слияния моделей различным конфигурациям трудно присвоить надёжный глобальный порядок; напротив, попарные сравнения дают более стабильные сигналы превосходства и неполноценности.
EvoGM использует исторические результаты валидации для построения данных winner-loser пар, позволяя генератору обучаться направлению улучшения от loser к winner. Для каждой пары кандидатных конфигураций слияния алгоритм не только фиксирует соответствующую разницу в производительности, но и преобразует отношение «от слабого к сильному» в обучающие примеры. По мере накопления и обучения генератор постепенно улавливает, какие корректировки коэффициентов с большей вероятностью повысят производительность, формируя неявное понимание структуры пространства поиска. Иными словами, он обучается не самим отличным решениям, а закономерностям улучшения производительности.
Эта идея созвучна механизмам конкурентного обучения в эволюционной оптимизации. Её можно проследить до CSO (Competitive Swarm Optimizer), где конкуренция winner-loser стимулирует обновление особей, заставляя более слабых приближаться к более сильным; EvoGO (Evolutionary Generative Optimization) идёт дальше, используя генеративные модели для обучения направлениям улучшения на исторических поисковых данных и заменяя часть вручную спроектированных поисковых операторов подходом, управляемым данными. EvoGM переносит эту идею в сценарий слияния моделей, обучая генераторы на валидационной обратной связи для направления последующего поиска. Таким образом, результаты валидации используются не только для отбора и отсева кандидатов, но и непрерывно превращаются в переиспользуемый поисковый опыт, позволяя процессу поиска накапливать знания и повышать эффективность с каждой итерацией.
IV. Как работает EvoGM?
Общий процесс EvoGM можно разделить на пять этапов: построение кандидатов, формирование обучающих пар winner-loser, обучение генераторов, генерация и отбор новых коэффициентов, а также обновление экспертной базы. При заданных экспертных моделях и валидационных задачах эти этапы автоматически выполняются в цикле без необходимости вручную проектировать правила слияния или настраивать коэффициенты на каждом раунде.
- Инициализация популяции: построение кандидатных схем слияния
EvoGM сначала формирует начальный набор кандидатов. Каждый кандидат соответствует одному набору коэффициентов слияния, то есть определённому способу комбинирования нескольких экспертных моделей.
Как правило, начальная популяция включает несколько типов конфигураций: коэффициенты, соответствующие усреднённому слиянию, one-hot коэффициенты отдельных экспертных моделей и коэффициенты слияния, полученные случайной выборкой. Это позволяет охватить распространённые базовые способы слияния и обеспечить разнообразие для последующего поиска.
Для каждого набора кандидатных коэффициентов EvoGM строит объединённую модель и оценивает её производительность на валидационном наборе. После этого этапа алгоритм получает не просто несколько кандидатных моделей, а набор исторических записей «коэффициенты слияния—производительность на валидации». Всё последующее генеративное обучение и эволюционный отбор опираются на эти записи.
- Winner-loser парирование: преобразование результатов валидации в обучающие данные
Получив кандидатов и их валидационную производительность, EvoGM делит исторические кандидатные конфигурации на winner и loser в зависимости от результатов. winner обозначает относительно более сильную конфигурацию слияния, loser — относительно более слабую.
Ключевой момент здесь не в простом сохранении конфигураций с высокими баллами и отбрасывании слабых, а в формировании обучающих пар. Для генератора одна winner-loser пара даёт полезную информацию: от этой более слабой конфигурации к какой более сильной следует приближаться?
Следовательно, кандидаты с низкой производительностью не являются бесполезными образцами. Напротив, они задают «точку отправления» в процессе поиска, а кандидаты с высокой производительностью — «направление улучшения». Такой способ парирования позволяет EvoGM преобразовывать ограниченные результаты валидационной оценки в большее число обучаемых сигналов надзора, повышая эффективность использования данных при малом объёме обратной связи.
- Обучение двух генераторов: обучение преобразованию от слабых конфигураций к сильным
После формирования обучающих пар winner-loser EvoGM использует структуру с двумя генераторами.
Прямой генератор обучается отображению от loser к winner, то есть преобразует конфигурации слияния с низкой производительностью в более перспективные конфигурации с высокой производительностью. Обратный генератор обучается обратному отображению от winner к loser и используется для ограничения структурной согласованности генеративного процесса.
Цель такого дизайна — не в том, чтобы генератор просто запоминал уже известные конфигурации с высокими баллами, а в том, чтобы он обучался закономерностям улучшения в пространстве коэффициентов слияния. Благодаря ограничениям циклической согласованности EvoGM снижает риск коллапса генератора к небольшому числу точек с высокими баллами, так что сгенерированные кандидатные конфигурации направляются к областям высокой производительности и при этом сохраняют структурную информацию пространства поиска.
- Генеративная эволюция и отбор: замена случайных возмущений обученными операторами
После обучения генератора EvoGM использует прямой генератор для преобразования текущих кандидатных конфигураций и генерации нового набора коэффициентов слияния. Этот шаг аналогичен «созданию новых особей» в традиционном эволюционном алгоритме, но новые особи формируются уже не в основном случайными возмущениями, а направлениями улучшения, выученными генеративной моделью.
Затем эти новые коэффициенты слияния используются для построения новых объединённых моделей и повторной оценки на валидационном наборе. Результаты оценки добавляются в исторические записи и участвуют в отборе вместе с существующими кандидатами.
В таком цикле EvoGM на каждом раунде проходит процесс «генерация—оценка—отбор—повторное обучение». Этот замкнутый контур составляет популяционную эволюцию кандидатных схем слияния: исторические результаты валидации непрерывно накапливаются, генератор постоянно получает новые обучающие сигналы и постепенно повышает способность автономно генерировать высококачественные конфигурации слияния.
- Эволюционная экспертная база: непрерывное обновление пространства поиска
Помимо оптимизации коэффициентов слияния, EvoGM вводит механизм эволюционной экспертной базы.
Традиционное слияние моделей обычно рассматривает экспертные модели как фиксированный вход и ищет коэффициенты слияния только между неизменными экспертными моделями. EvoGM иначе: по завершении каждого раунда лучшие объединённые модели отбираются в качестве новой экспертной базы для поиска на следующем раунде.
Смысл в том, что отличные объединённые модели уже содержат определённые эффективные комбинации способностей. Включив их в новую экспертную базу, последующий поиск перестаёт ограничиваться линейными комбинациями исходных экспертных моделей и может продолжать эволюцию на основе уже проверенных промежуточных моделей.
Таким образом, пространство поиска EvoGM не фиксировано, а непрерывно обновляется в ходе поиска. Он не только ищет лучшие коэффициенты слияния, но и постепенно формирует более подходящую для текущей задачи основу экспертного представления.
V. Ключевые преимущества EvoGM
По сравнению с традиционными методами слияния моделей преимущества EvoGM проявляются в трёх аспектах.
Во-первых, EvoGM переводит слияние моделей от статических эвристических правил к автономному поиску, управляемому обратной связью. Традиционные методы обычно опираются на усреднение, ручное масштабирование или случайные возмущения, тогда как EvoGM может непрерывно корректировать направление поиска на основе исторических результатов валидации, и процесс слияния больше не зависит от ручного проектирования правил и настройки коэффициентов на каждом раунде.
Во-вторых, EvoGM повышает эффективность использования данных при ограниченном бюджете оценок. При слиянии моделей каждая оценка кандидатной конфигурации требует фактического построения объединённой модели и выполнения валидационных задач, что связано с немалыми затратами. EvoGM дополнительно преобразует эти результаты оценки в обучаемые сигналы, так что каждая попытка приносит информацию для последующего поиска.
Наконец, EvoGM не просто ищет лучший набор коэффициентов слияния, но и постепенно обучается закономерностям комбинирования способностей между экспертными моделями. Благодаря генеративному поиску в популяции кандидатов и обновлению экспертной базы он может непрерывно рекомбинировать и расширять пространство поиска на основе существующих экспертных моделей, более эффективно обнаруживая высокопроизводительные объединённые модели.
VI. Экспериментальные результаты: действительно ли эффективен EvoGM?
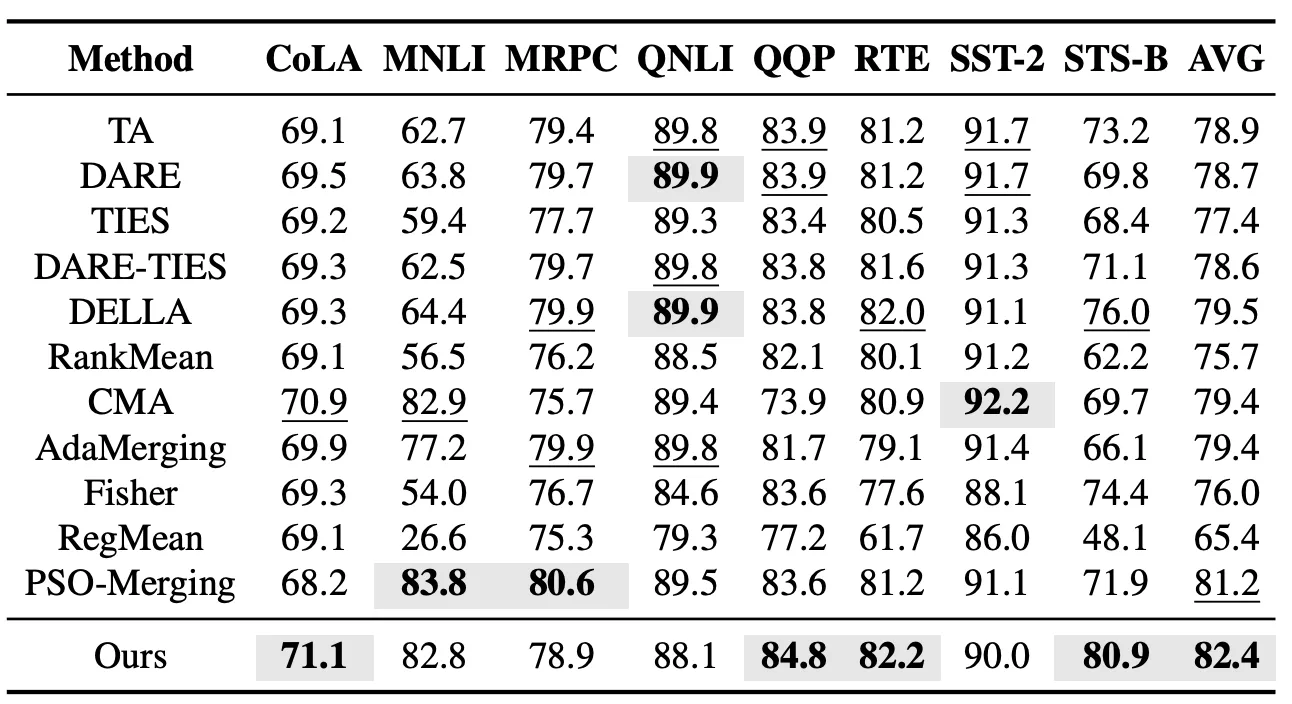
В настройке с видимыми задачами мы сначала оценили эффект слияния моделей EvoGM на задачах серии GLUE. Эксперимент охватывает 8 задач понимания языка — CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2 и STS-B — и сравнивает EvoGM с представительными методами слияния моделей: Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging и PSO-Merging. Результаты показывают, что EvoGM превосходит по средней производительности на всех 8 задачах ранее лучший метод PSO-Merging.
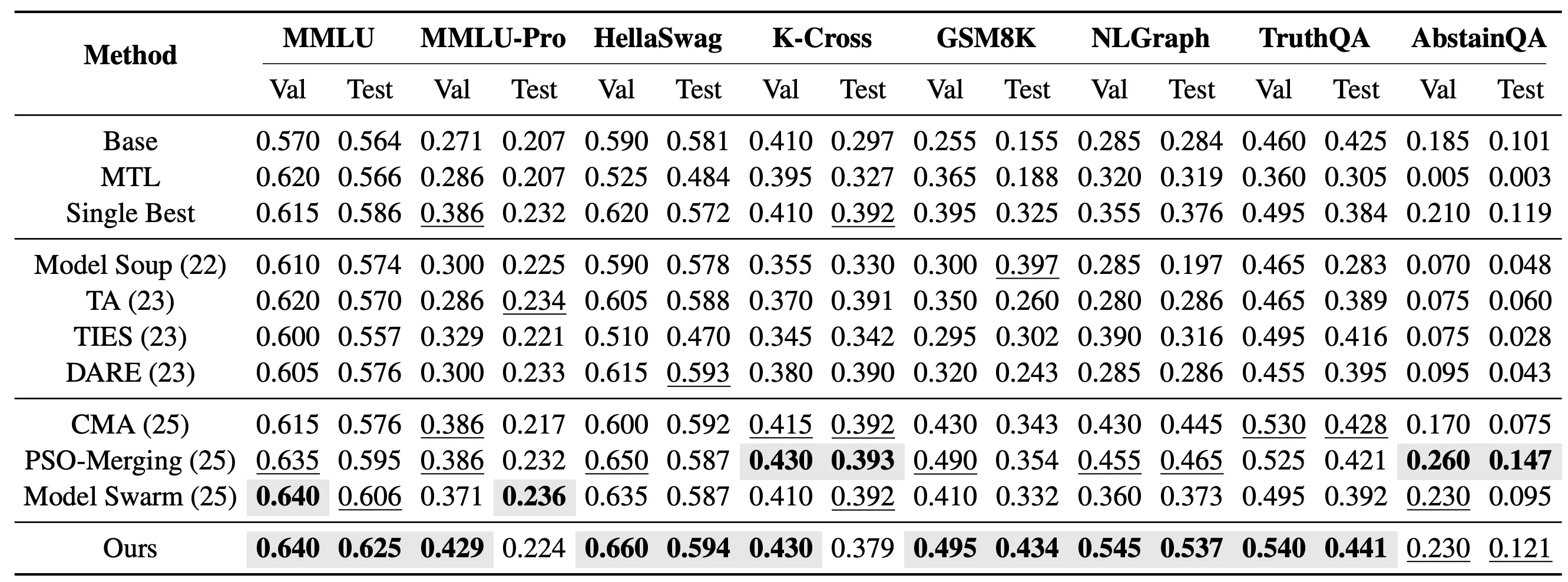
В более сложной настройке с невидимыми задачами мы дополнительно оценили, способен ли EvoGM переносить возможности существующих экспертных моделей на новые задачи, не участвовавшие в дообучении экспертов. В частности, мы объединили 10 экспертных моделей LoRA на базе Qwen2.5-1.5B и протестировали их на 8 невидимых задачах: MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA и AbstainQA. Эти задачи охватывают понимание знаний, сложное рассуждение, надёжность и безопасность и другие измерения способностей, лучше отражая способность к обобщению методов слияния моделей, чем видимые задачи.
В настройке слияния одной невидимой задачи EvoGM отдельно ищет набор коэффициентов слияния для каждой целевой задачи. Результаты показывают, что EvoGM достигает наивысшей тестовой производительности на 5 из 8 тестовых задач.
Помимо слияния одной задачи, мы также исследовали настройку многозадачного слияния невидимых задач. В этой настройке цель состоит не в поиске оптимальной модели для каждой задачи по отдельности, а в получении единой объединённой модели, одновременно охватывающей все 8 невидимых задач. Результаты показывают, что при многозадачном слиянии невидимых задач EvoGM достигает наивысшей средней тестовой производительности среди всех методов слияния.
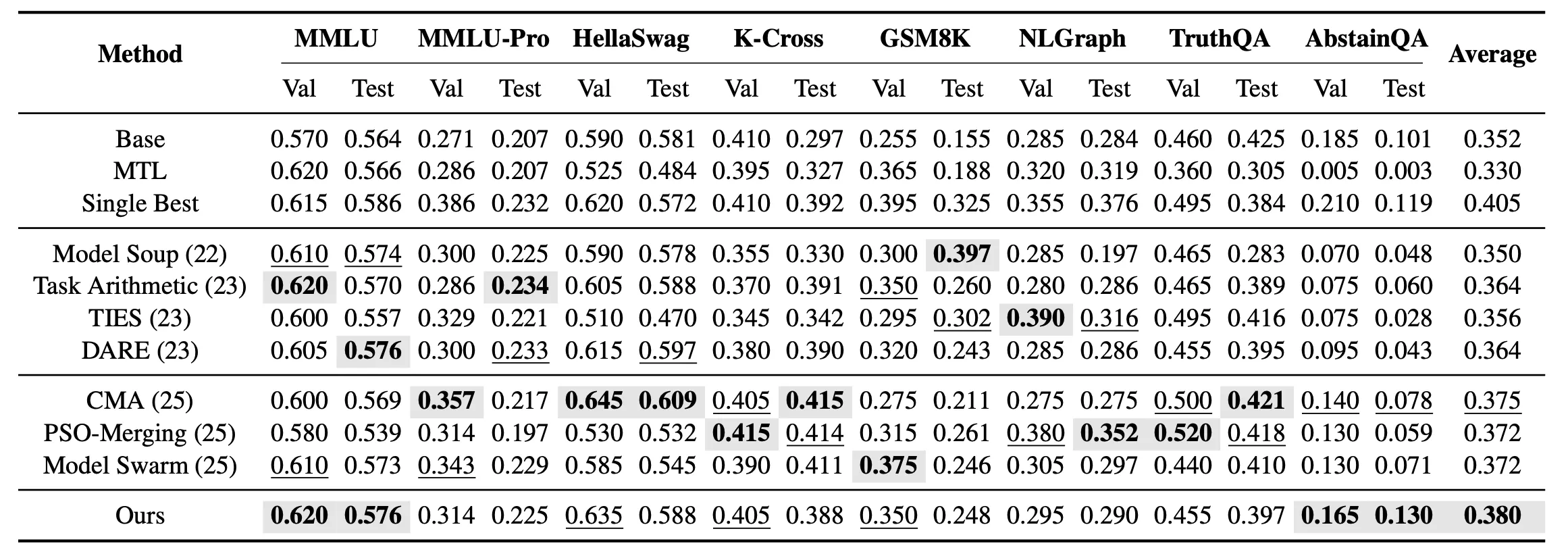
Результаты показывают, что EvoGM демонстрирует более сильное общее обобщение как при слиянии одной задачи, так и в многозадачной настройке, превосходя существующие методы слияния моделей на множестве задач, связанных со знаниями, рассуждением и безопасностью.
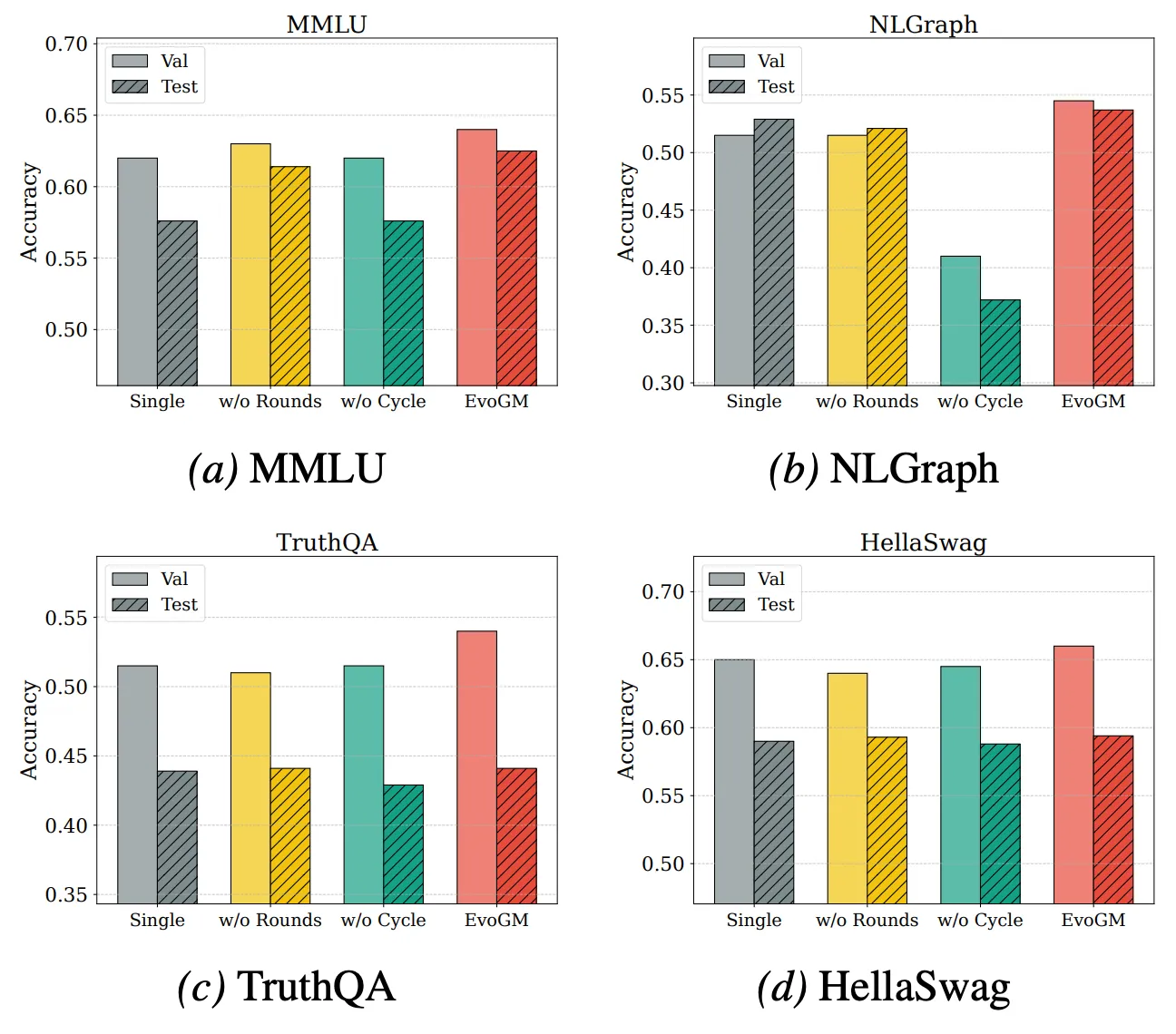
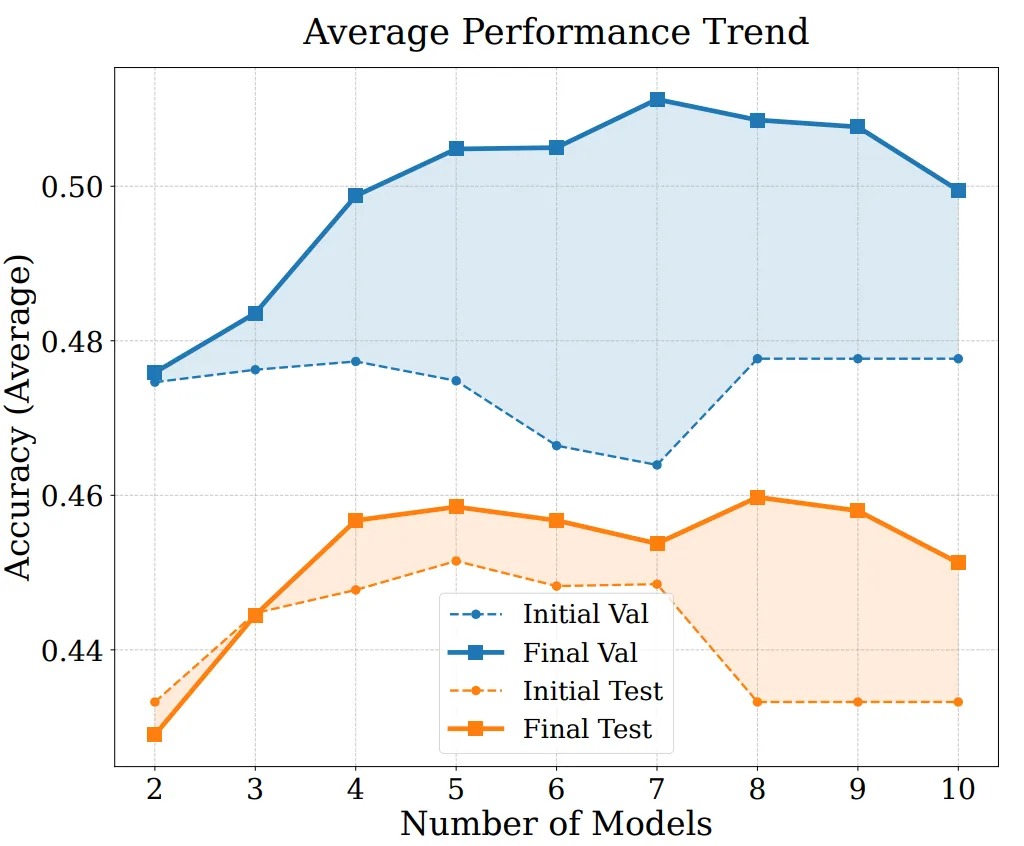
Для более глубокого анализа источников производительности EvoGM и его масштабируемости мы провели абlation-эксперименты и эксперименты слияния с различным числом моделей. Результаты показывают, что полный EvoGM всегда достигает оптимальной или наиболее стабильной производительности; при удалении ключевых компонентов производительность снижается в разной степени, что подтверждает: преимущество обусловлено прежде всего механизмом генеративной эволюции, а не простым случайным поиском или большим числом раундов поиска. При увеличении числа участвующих в слиянии экспертных моделей EvoGM сохраняет хорошую производительность и демонстрирует устойчивую тенденцию к улучшению, что указывает на способность эффективно справляться с более крупным и сложным пространством слияния, полно использовать взаимодополняющие способности различных экспертных моделей и обладает хорошей масштабируемостью.
VII. От EvoGO к EvoGM: развитие идеи генеративной эволюции
С более широкой точки зрения EvoGM можно понимать как развитие идеи EvoGO в области слияния больших моделей. EvoGO сосредоточен на том, как перевести эволюционную оптимизацию от зависимости от вручную спроектированных операторов скрещивания, мутации и возмущения к автоматическому обучению генеративными моделями на исторических поисковых данных новых способов генерации решений. Иными словами, эволюционный поиск перестаёт быть лишь «случайной генерацией кандидатов и отбором» и начинает учиться «как генерировать более перспективных кандидатов».
EvoGM переносит эту идею в сценарий слияния больших моделей. Здесь кандидаты — не числовые переменные общей задачи оптимизации, а наборы коэффициентов слияния; одна оценка — не просто вычисление целевой функции, а построение объединённой модели и проверка её производительности на downstream-задачах. Таким образом, EvoGM фактически переформулирует слияние моделей как задачу генеративной оптимизации: как на исторических результатах оценки обучаться закономерностям комбинирования способностей между экспертными моделями и генерировать более сильные конфигурации слияния.
Это отчётливо отличает EvoGM от традиционных поисковых методов слияния моделей. Традиционные методы обычно используют результаты валидации только для ранжирования и отбора, тогда как EvoGM дополнительно преобразует их в обучающие сигналы. Конфигурации с низкой производительностью не отбрасываются просто так, а объединяются с конфигурациями высокой производительности в winner-loser pairs для обучения генератора направлению эволюции от слабых конфигураций к сильным.
От EvoGO к EvoGM — по сути переход от «обучения оптимизации кандидатов» к «автономной эволюции стратегии слияния больших моделей в популяции». Это не только освобождает слияние моделей от эмпирических правил и случайных возмущений, но и предлагает новый подход: возможности больших моделей можно объединять, а сама стратегия слияния может непрерывно обучаться на популяционной обратной связи.
VIII. Заключение и перспективы
По мере роста числа экспертных моделей, моделей LoRA и задачных моделей в экосистеме открытого ПО ключевым вопросом будущего может стать не только «как обучить новую модель», но и «как эффективно комбинировать возможности существующих моделей». EvoGM предлагает новый ответ: без переобучения участвующих в слиянии больших моделей, посредством генеративной эволюции на ограниченной валидационной обратной связи автономно выполняет построение популяции кандидатов, генерацию схем слияния, оценку и отбор, а также обновление экспертной базы. Проще говоря, EvoGM переводит слияние моделей от «подбора коэффициентов по опыту» к «самообучению и эволюции стратегии слияния». Это также означает, что повторное использование возможностей больших моделей может войти в новую фазу: не переобучать модель при каждой новой задаче, а позволять существующим экспертным моделям через популяционную эволюцию и автономное слияние непрерывно комбинировать модели, более подходящие для новых задач.
Открытый код / Сообщество
📄 Статья: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 Upstream-проект (EvoX):
https://github.com/EMI-Group/evox 🌐 QQ-группа:
297969717
