ICML 2026 | EvoGM:无需重新训练,通过群体进化实现大模型自主合并

摘要
随着大语言模型能力不断提升,针对不同任务微调得到的专家模型也越来越多。如何在不重新训练参与合并的大模型、不依赖额外大规模训练数据的前提下,高效复用这些专家模型的能力,成为模型合并中的重要问题。现有方法通常依赖平均合并、手工缩放、参数裁剪或随机搜索,虽然能够在一定程度上组合多个模型的能力,但难以从历史评估中持续学习并改进合并策略。
针对这一问题,EvoX团队联合鹏城实验室提出生成式演化模型合并框架EvoGM(Evolutionary Generative Merging),将合并系数搜索转化为可学习的生成式优化问题。EvoGM把不同合并配置组织成候选种群,通过赢家—输家配对、双生成器训练、循环一致性约束和演化专家基底更新,使种群在”生成—评估—选择—再学习”的闭环中持续进化,并从有限验证反馈中自主学习如何把低性能配置转化为高性能配置。实验结果表明,EvoGM在已见任务和未见任务场景下均展现出更强的模型合并能力。
一、为什么我们需要模型合并?
近年来,大语言模型的能力越来越强,但训练和微调的成本也越来越高。一个自然的问题是:如果我们已经有了多个在不同任务上表现较好的专家模型,能不能不重新训练这些大模型,而是把它们的能力组合起来,得到一个更强、更通用的新模型?
这正是模型合并要解决的问题。
模型合并的核心思想很直接:多个专家模型往往来自同一基础模型,只是在不同数据或任务上进行了微调。因此,可以把每个专家模型相对于基础模型的参数变化看作一种”能力方向”,再加权组合这些方向,构造新的合并模型。其优势是无需重新训练或微调参与合并的大模型,也不依赖额外大规模训练数据,只需搜索合适的合并系数。需要说明的是,EvoGM训练轻量级生成器来搜索系数,但不更新专家大模型参数。
二、模型合并真正难在哪里?
真正困难的地方在这里:这些系数到底应该怎么选?
模型合并看似只是对多个专家模型进行加权组合,但不同专家模型之间的能力关系并不简单。有些任务方向可以互补,有些参数更新可能相互冲突;一组合并系数在某类任务上表现更好,也可能在另一类任务上带来性能损失。因此,合并系数与最终模型性能之间并不是一个容易手工刻画的线性关系。
传统方法通常依赖平均合并、手工缩放、参数裁剪或稀疏化等启发式规则。这些方法简单有效,但也存在明显局限:它们往往是静态的、经验性的,很难根据不同任务的验证反馈自适应调整。
后来,演化搜索类方法被引入模型合并,把候选合并配置组织成种群,通过随机扰动、适应度评估和选择来寻找更优系数。这类方法比固定规则更灵活,但仍然存在一个关键问题:验证结果通常只被用于排序和筛选,而没有进一步转化为可学习的搜索经验。换句话说,算法知道”哪个候选模型更好”,却没有真正学习”较差的候选模型应该如何变得更好”。
这也是 EvoGM 希望解决的核心问题:模型合并不应只是让候选群体不断试错和筛选,而应从历史评估中学习改进方向,自主产生更有潜力的合并配置。
三、EvoGM:让合并策略在群体进化中自主学习
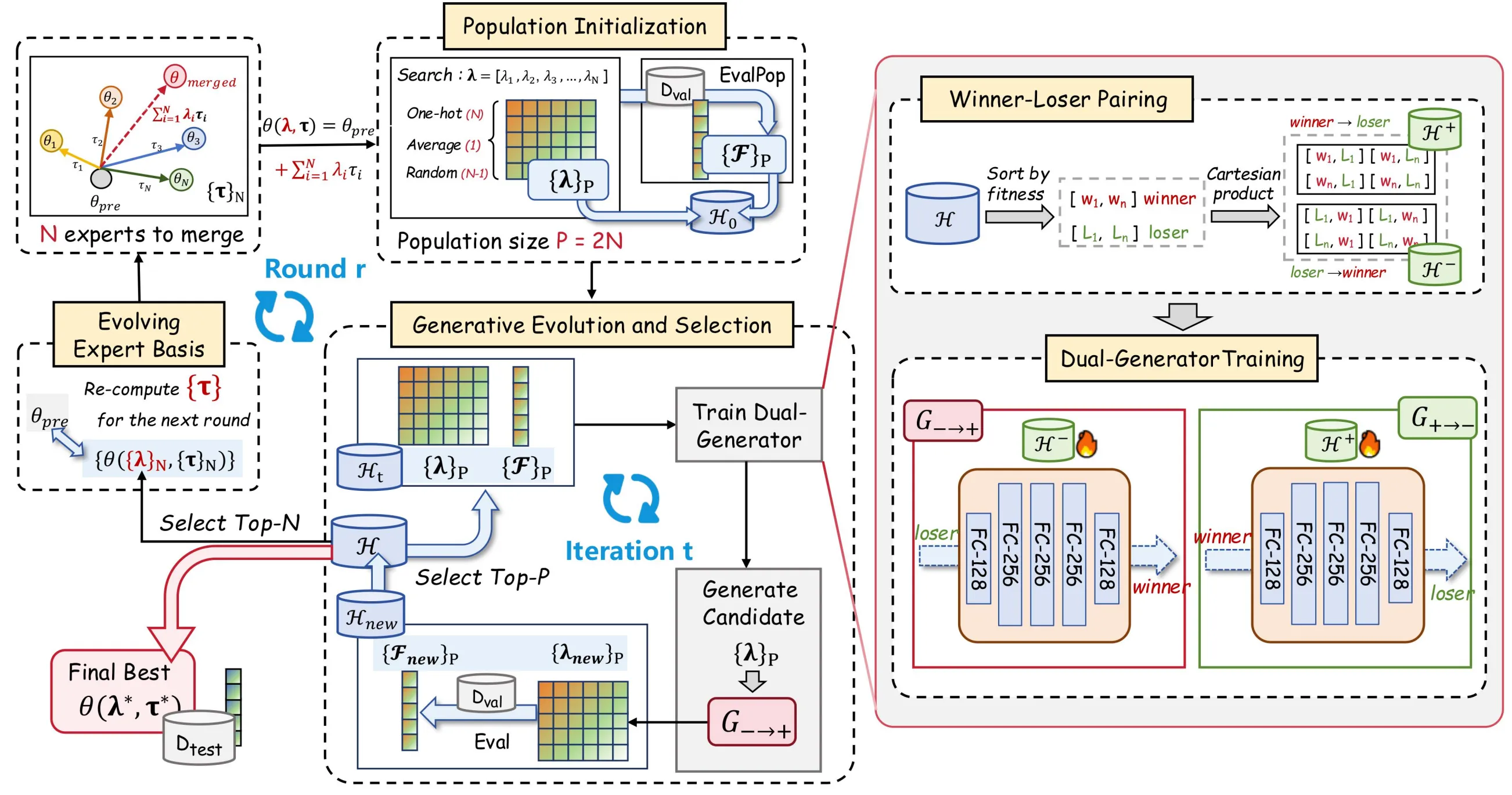
为解决上述问题,我们提出了 EvoGM(Evolutionary Generative Merging),代码已开源:https://github.com/JiangTao97/evogm。
EvoGM 的核心思想是:将候选合并配置组织为种群,并把合并系数的搜索过程转化为生成式学习问题。
关键在于,生成模型并不直接学习”最优合并系数是什么”,而是学习”如何从较差配置变成较优配置”。这是因为在模型合并场景中,不同配置往往难以形成可靠的全局排序;相比之下,两两比较更容易获得稳定的优劣信号。
EvoGM 利用历史验证结果构造 winner-loser 配对数据,让生成器学习从 loser 到 winner 的改进方向。对于每一对候选合并配置,算法不仅记录它们对应的性能差异,还将这种”由差变好”的关系转化为训练样本。经过不断积累和学习,生成器能够逐渐捕捉哪些系数调整更可能带来性能提升,从而形成对搜索空间结构的隐式理解。换句话说,它学习的不是优秀解本身,而是性能提升的规律。
这一思路与演化优化中的竞争学习机制一脉相承。最早可以追溯到CSO(Competitive Swarm Optimizer),其通过 winner-loser 竞争推动个体更新,让表现较差的个体向表现更好的个体靠近;EvoGO(Evolutionary Generative Optimization) 则进一步利用生成模型从历史搜索数据中学习改进方向,用数据驱动的方式替代部分人工设计的搜索算子。EvoGM 将这一思想引入模型合并场景,通过验证反馈训练生成器,引导后续搜索。这样一来,验证结果不再只是用于筛选和淘汰候选解,而是被持续转化为可复用的搜索经验,使搜索过程能够随着迭代不断积累知识、提高效率。
四、EvoGM 是如何工作的?
EvoGM 的整体流程可分为五步:构造候选方案、形成 winner-loser 训练对、训练生成器、生成并选择新系数,以及更新专家基底。在给定专家模型与验证任务后,这些步骤可以自动循环执行,无需人工逐轮设计合并规则或调节系数。
- 种群初始化:构建候选合并方案
EvoGM 首先需要构造一批初始候选解。这里的每个候选解对应一组合并系数,也就是对多个专家模型的不同组合方式。
具体来说,初始种群通常包括几类配置:平均合并对应的系数、单个专家模型对应的 one-hot 系数,以及随机采样得到的合并系数。这样既能覆盖一些常见的基准合并方式,也能为后续搜索提供一定的多样性。
对于每一组候选系数,EvoGM 都会据此构造一个合并模型,并在验证集上评估其性能。经过这一步,算法得到的不只是若干候选模型,而是一批”合并系数—验证性能”的历史记录。后续所有生成式学习和演化选择,都建立在这些记录之上。
- 赢家—输家配对:把验证结果转化为训练数据
得到候选解及其验证性能后,EvoGM 会根据表现将历史候选配置划分为 winner 和 loser。winner 表示相对更优的合并配置,loser 表示相对较差的合并配置。
这里的关键不是简单保留高分配置、丢弃低分配置,而是把两者组成训练对。对于生成器来说,一个 winner-loser pair 就提供了一条有用的信息:从这个较差配置出发,应该向哪个更优配置靠近。
因此,低性能候选并不是无效样本。相反,它们提供了搜索过程中的”起点”,而高性能候选提供了”改进方向”。通过这种配对方式,EvoGM 能够把有限的验证评估结果转化为更多可学习的监督信号,提高小样本反馈下的数据利用效率。
- 双生成器训练:学习从差配置到好配置的变换
在构造好 winner-loser 训练对之后,EvoGM 使用双生成器结构进行训练。
其中,前向生成器负责学习从 loser 到 winner 的映射,也就是把低性能合并配置转化为更有潜力的高性能配置。反向生成器则学习从 winner 回到 loser 的反向映射,用于约束生成过程的结构一致性。
这种设计的目的不是让生成器简单记住已有的高分配置,而是让它学习合并系数空间中的改进规律。通过循环一致性约束,EvoGM 可以减少生成器坍缩到少数高分点的风险,使生成出的候选配置既朝向高性能区域,又尽量保留搜索空间中的结构信息。
- 生成式演化与选择:用学出来的算子替代随机扰动
生成器训练完成后,EvoGM 会用前向生成器对当前候选配置进行变换,生成一批新的合并系数。这一步相当于传统演化算法中的”产生新个体”,但新个体不再主要来自随机扰动,而是来自生成模型学到的改进方向。
随后,这些新生成的合并系数会被用于构造新的合并模型,并再次在验证集上进行评估。评估结果会被加入历史记录中,与已有候选一起参与选择。
通过这样的循环,EvoGM 每一轮都会经历”生成—评估—选择—再学习”的过程。这一闭环构成了候选合并方案的群体进化:历史验证结果不断积累,生成器持续获得新的训练信号,从而逐步提高自主生成高质量合并配置的能力。
- 演化专家基底:让搜索空间不断自我更新
除了优化合并系数,EvoGM 还进一步引入了演化专家基底机制。
传统模型合并通常把专家模型视为固定输入,只在固定专家模型之间搜索合并系数。EvoGM 则不同:每一轮结束后,表现最好的若干合并模型会被选出来,作为下一轮搜索中的新专家基底。
这样做的意义在于,优秀的合并模型本身已经包含了某些有效的能力组合。把它们纳入新的专家基底后,后续搜索不再局限于原始专家模型之间的线性组合,而是可以在已经被验证有效的中间模型基础上继续演化。
因此,EvoGM 的搜索空间不是固定不变的,而是会随着搜索过程不断更新。它不仅在寻找更好的合并系数,也在逐步构造更适合当前任务的专家表示基础。
五、EvoGM 的关键优势是什么?
相比传统模型合并方法,EvoGM 的优势主要体现在三个方面。
首先,EvoGM 将模型合并从静态启发式规则推进到反馈驱动的自主搜索。传统方法往往依赖平均合并、手工缩放或随机扰动,而 EvoGM 可以根据历史验证结果持续调整搜索方向,使合并过程不再依赖人工逐轮设计规则和调节系数。
其次,EvoGM 提高了有限评估预算下的数据利用效率。在模型合并中,每一次候选配置评估都需要实际构造合并模型并运行验证任务,成本并不低。EvoGM 将这些评估结果进一步转化为可学习的训练信号,使每一次试错都能为后续搜索提供信息。
最后,EvoGM 不只是寻找一组更好的合并系数,也在逐步学习专家模型之间的能力组合规律。通过候选种群的生成式搜索与专家基底更新,它能够在已有专家模型的基础上不断重组和扩展搜索空间,从而更有效地自主发现高性能合并模型。
六、实验结果:EvoGM 是否真的有效?
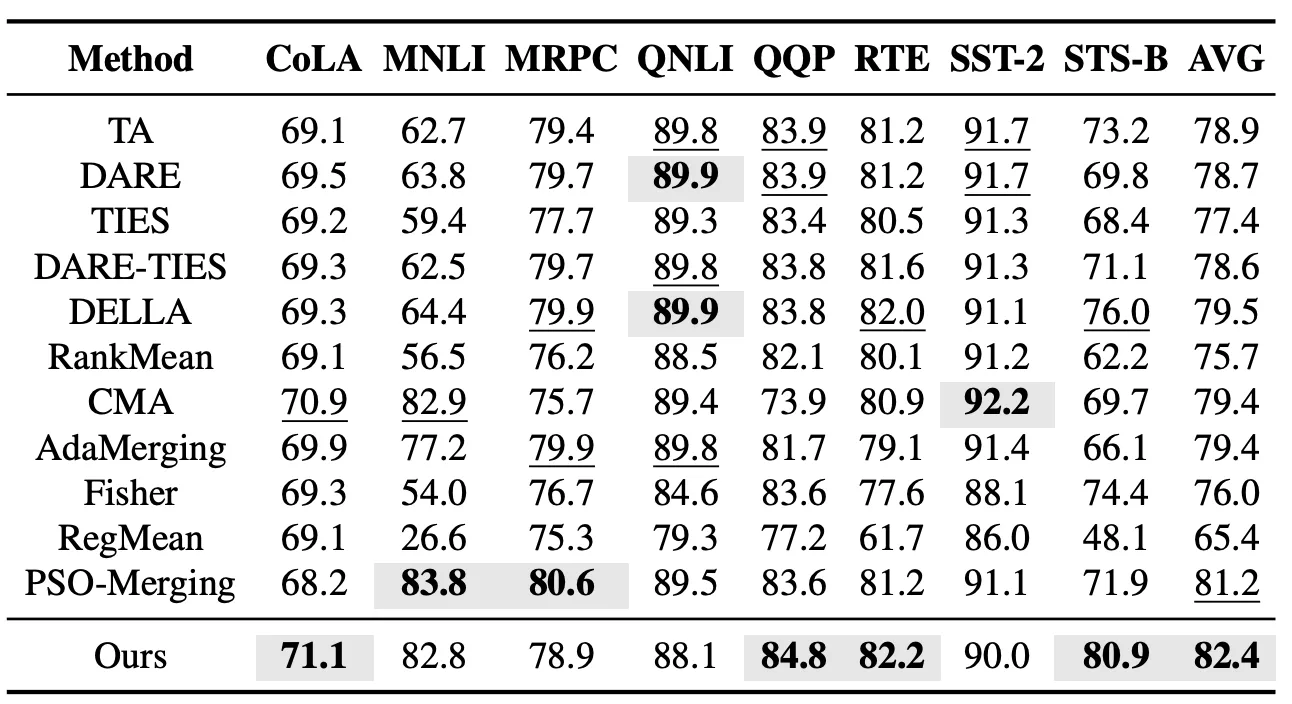
在已见任务设置中,我们首先在 GLUE 系列任务上评估 EvoGM 的模型合并效果。该实验涵盖 CoLA、MNLI、MRPC、QNLI、QQP、RTE、SST-2 和 STS-B 等 8 个语言理解任务,并与 Task Arithmetic、TIES、DARE-TIES、DELLA、RankMean、CMA、AdaMerging 和 PSO-Merging 等代表性模型合并方法进行比较。实验结果显示,EvoGM 在 8 个任务上的平均性能超过此前表现最好的 PSO-Merging。
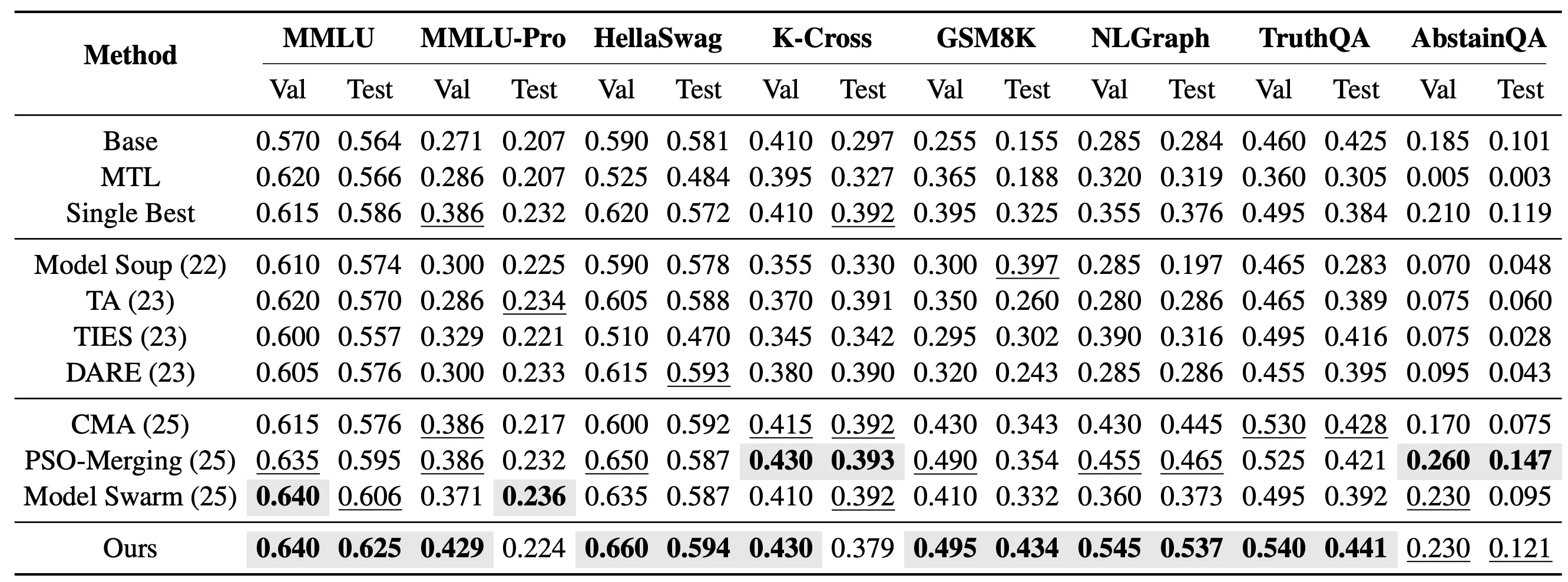
在更具挑战性的未见任务设置中,我们进一步评估 EvoGM 是否能够将已有专家模型的能力迁移到未参与专家微调的新任务上。具体来说,我们合并了 10 个基于 Qwen2.5-1.5B 的 LoRA 专家模型,并在 MMLU、MMLU-Pro、HellaSwag、Knowledge Crosswords、GSM8K、NLGraph、TruthfulQA 和 AbstainQA 等 8 个未见任务上进行测试。这些任务覆盖知识理解、复杂推理和安全可靠性等不同能力维度,比已见任务更能反映模型合并方法的泛化能力。
在单任务未见合并设置中,EvoGM 会针对每个目标任务分别搜索一组合并系数。实验结果显示,EvoGM 在 8 个测试任务中的 5 个任务上取得最高测试性能。
除了单任务合并,我们还进一步考察了多任务未见合并设置。在这一设置中,目标不再是为每个任务单独寻找最优模型,而是得到一个能够同时覆盖 8 个未见任务的统一合并模型。实验结果表明,在多任务未见合并中,EvoGM 在所有合并方法中取得最高平均测试性能。
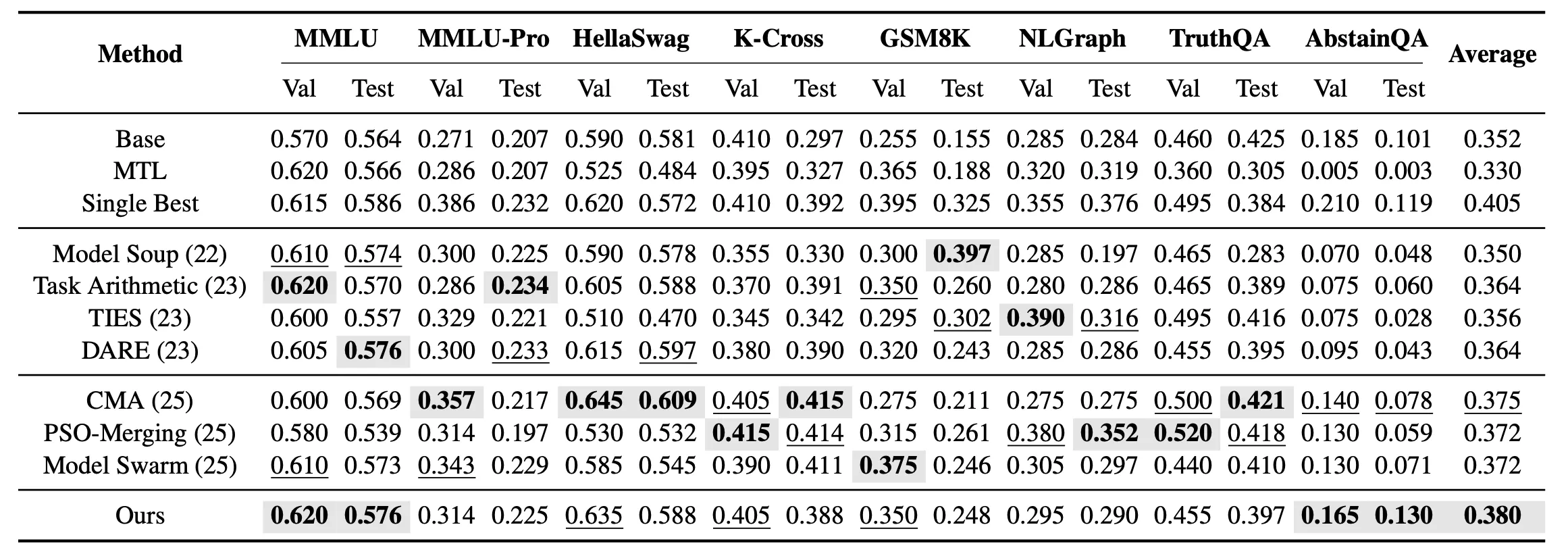
结果显示,EvoGM 无论在单任务合并还是多任务设置中,均取得了更强的整体泛化表现,并在多个知识、推理和安全相关任务上优于现有模型合并方法。
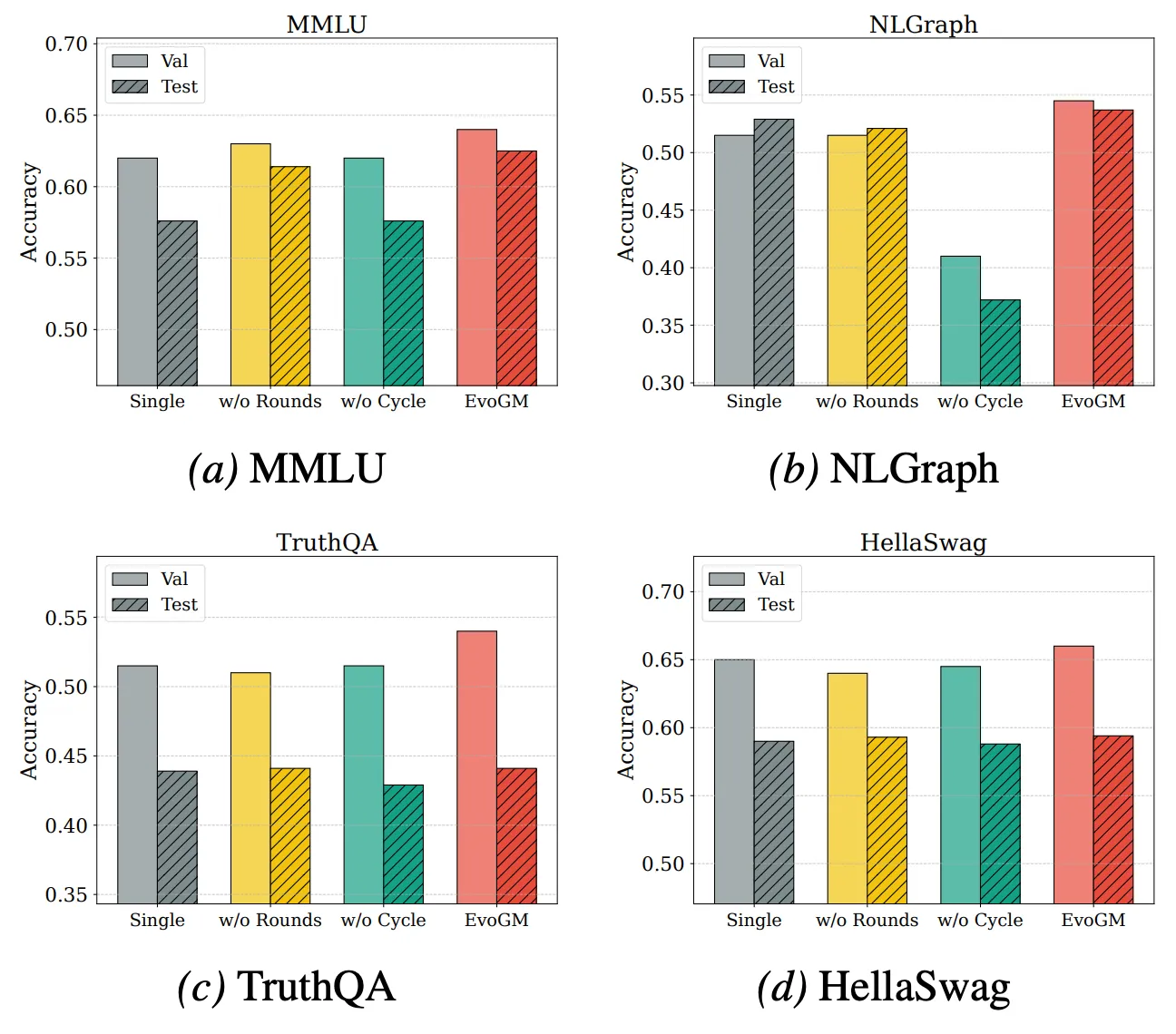
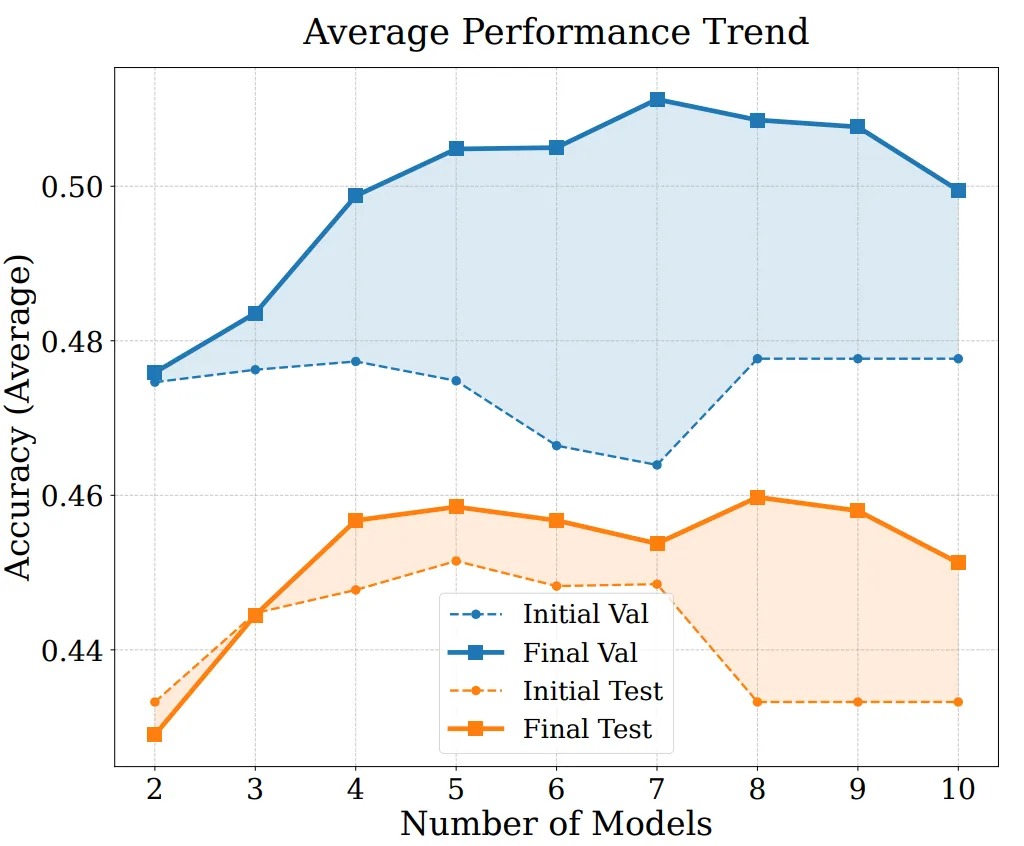
为了进一步分析 EvoGM 的性能来源及扩展能力,我们进行了消融实验和不同模型数量下的合并实验。结果表明,完整的 EvoGM 始终取得最优或最稳定的表现,移除关键组件后性能均出现不同程度下降,说明其优势主要来自生成式演化机制,而非简单的随机搜索或更多搜索轮次。同时,在参与合并的专家模型数量增加时,EvoGM 仍能保持良好性能,并展现出稳定的提升趋势,表明其能够有效应对更大规模、更复杂的合并空间,充分利用不同专家模型之间的互补能力,具有较好的扩展性。
七、从 EvoGO 到 EvoGM:生成式演化思想的延伸
从更大的视角看,EvoGM 可以被理解为 EvoGO 思想在大模型合并中的一次延伸。EvoGO 关注的是如何让演化优化从依赖人工设计的交叉、变异和扰动算子,转向由生成模型根据历史搜索数据自动学习新解生成方式。也就是说,演化搜索不再只是”随机产生候选解并筛选”,而是开始学习”如何产生更有潜力的候选解”。
EvoGM 将这一思想落到大模型合并场景中。在这里,候选解不再是一般优化问题中的数值变量,而是一组合并系数;一次评估也不再是简单计算目标函数,而是构造合并模型并在下游任务上验证性能。因此,EvoGM 实际上把模型合并重新表述为一个生成式优化问题:如何从历史评估结果中学习专家模型之间的能力组合规律,并生成更优的合并配置。
这一点使 EvoGM 与传统搜索式模型合并形成了明显区别。传统方法通常只把验证结果用于排序和筛选,而 EvoGM 进一步把验证结果转化为训练信号。低性能配置并不会被简单丢弃,而是与高性能配置组成 winner-loser pairs,用来训练生成器学习从差配置到好配置的演化方向。
从 EvoGO 到 EvoGM,本质上是从”学习如何优化候选解”走向”让大模型合并策略在群体中自主进化”。这不仅让模型合并从经验规则和随机扰动中解放出来,也提供了一种新的思路:大模型能力可以被合并,而合并策略本身也可以从群体反馈中持续学习。
八、结论与展望
随着开源生态中专家模型、LoRA 模型和任务模型越来越多,未来的关键问题可能不只是”如何训练一个新模型”,而是”如何高效组合已有模型能力”。EvoGM 提供了一种新的答案:在不重新训练参与合并的大模型的前提下,通过生成式演化学习利用有限验证反馈,自主完成候选种群构建、合并方案生成、评估选择和专家基底更新。简单来说,EvoGM 让模型合并从”凭经验调系数”走向”让合并策略自己学习和进化”。这也意味着,大模型能力复用可能进入一个新的阶段:不是每遇到一个新任务都重新训练一个模型,而是让已有专家模型通过群体进化与自主合并,持续组合出更适合新任务的模型。
开源代码 / 社区
📄 论文: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 上游项目(EvoX):
https://github.com/EMI-Group/evox 🌐 QQ交流群:297969717
