ICML 2026 | EvoGM:再トレーニング不要で、集団進化による大規模モデルの自律的マージ

概要
大規模言語モデルの能力が向上するにつれ、異なるタスク向けにファインチューニングされたエキスパートモデルも増え続けています。マージに参加する大規模モデルを再トレーニングせず、追加の大規模トレーニングデータにも依存せずに、これらのエキスパートモデルの能力を効率的に再利用する方法は、モデルマージにおける重要な課題です。既存の手法は通常、平均マージ、手動スケーリング、パラメータのトリミング、またはランダム探索に依存しています。これらはある程度まで複数モデルの能力を組み合わせられますが、過去の評価から継続的に学習し、マージ戦略を改善することは困難です。
この問題に対処するため、EvoX チームと鵬城実験室は、生成型進化モデルマージフレームワーク EvoGM(Evolutionary Generative Merging)を提案しました。EvoGM はマージ係数の探索を学習可能な生成型最適化問題に変換します。EvoGM は異なるマージ設定を候補集団として組織化し、winner-loser ペアリング、デュアル生成器の学習、循環一貫性制約、進化的エキスパート基底の更新を通じて、集団が「生成—評価—選択—再学習」の閉ループの中で継続的に進化するようにします。限られた検証フィードバックから、低性能設定を高性能設定へ変換する方法を自律的に学習します。実験結果は、EvoGM が既知タスクと未知タスクの両方のシナリオで、より強力なモデルマージ能力を示すことを明らかにしています。
一、なぜモデルマージが必要なのか?
近年、大規模言語モデルの能力はますます高まっていますが、トレーニングとファインチューニングのコストも高騰しています。自然な疑問が生じます。異なるタスクで良好な性能を示す複数のエキスパートモデルがすでにある場合、これらの大規模モデルを再トレーニングせずに、その能力を組み合わせて、より強力で汎用的な新モデルを得ることはできないでしょうか?
これこそが、モデルマージが解決しようとする問題です。
モデルマージの核心思想は直接的です。複数のエキスパートモデルは、多くの場合、同じベースモデルから派生し、異なるデータやタスクでファインチューニングされたものにすぎません。したがって、各エキスパートモデルのベースモデルに対するパラメータ変化を「能力方向」と見なし、これらの方向を重み付きで組み合わせて新しいマージモデルを構築できます。その利点は、マージに参加する大規模モデルを再トレーニングまたはファインチューニングする必要がなく、追加の大規模トレーニングデータにも依存せず、適切なマージ係数を探索するだけで済むことです。EvoGM は軽量な生成器を学習して係数を探索しますが、エキスパート大規模モデルのパラメータは更新しません。
二、モデルマージの本当の難しさはどこにあるのか?
本当に困難なのはここです。これらの係数をどのように選ぶべきでしょうか?
モデルマージは、複数のエキスパートモデルの重み付き組み合わせに見えますが、異なるエキスパートモデル間の能力関係は単純ではありません。一部のタスク方向は相互補完的ですが、一部のパラメータ更新は相互に競合する可能性があります。あるマージ係数の組み合わせはある種類のタスクでより良い性能を示す一方、別の種類のタスクでは性能低下をもたらす可能性があります。したがって、マージ係数と最終的なモデル性能の間には、容易に手動で特徴付けられる線形関係は存在しません。
従来の手法は通常、平均マージ、手動スケーリング、パラメータのトリミング、またはスパース化などのヒューリスティックなルールに依存しています。これらの手法はシンプルで効果的ですが、明確な限界もあります。静的で経験的であり、異なるタスクの検証フィードバックに応じて適応的に調整することが困難です。
その後、進化探索型の手法がモデルマージに導入され、候補マージ設定を集団として組織化し、ランダム摂動、適応度評価、選択を通じてより良い係数を探索するようになりました。これらの手法は固定ルールよりも柔軟ですが、依然として重要な問題が残っています。検証結果は通常、ランキングとフィルタリングにのみ使用され、学習可能な探索経験へとさらに変換されません。言い換えれば、アルゴリズムは「どの候補モデルがより良いか」を知っていますが、「より劣った候補モデルをどのように改善すべきか」を真に学習していません。
これこそが EvoGM が解決しようとする核心的な問題です。モデルマージは候補集団の試行錯誤とフィルタリングだけでなく、過去の評価から改善方向を学習し、より有望なマージ設定を自律的に生成すべきです。
三、EvoGM:集団進化の中でマージ戦略を自律的に学習する
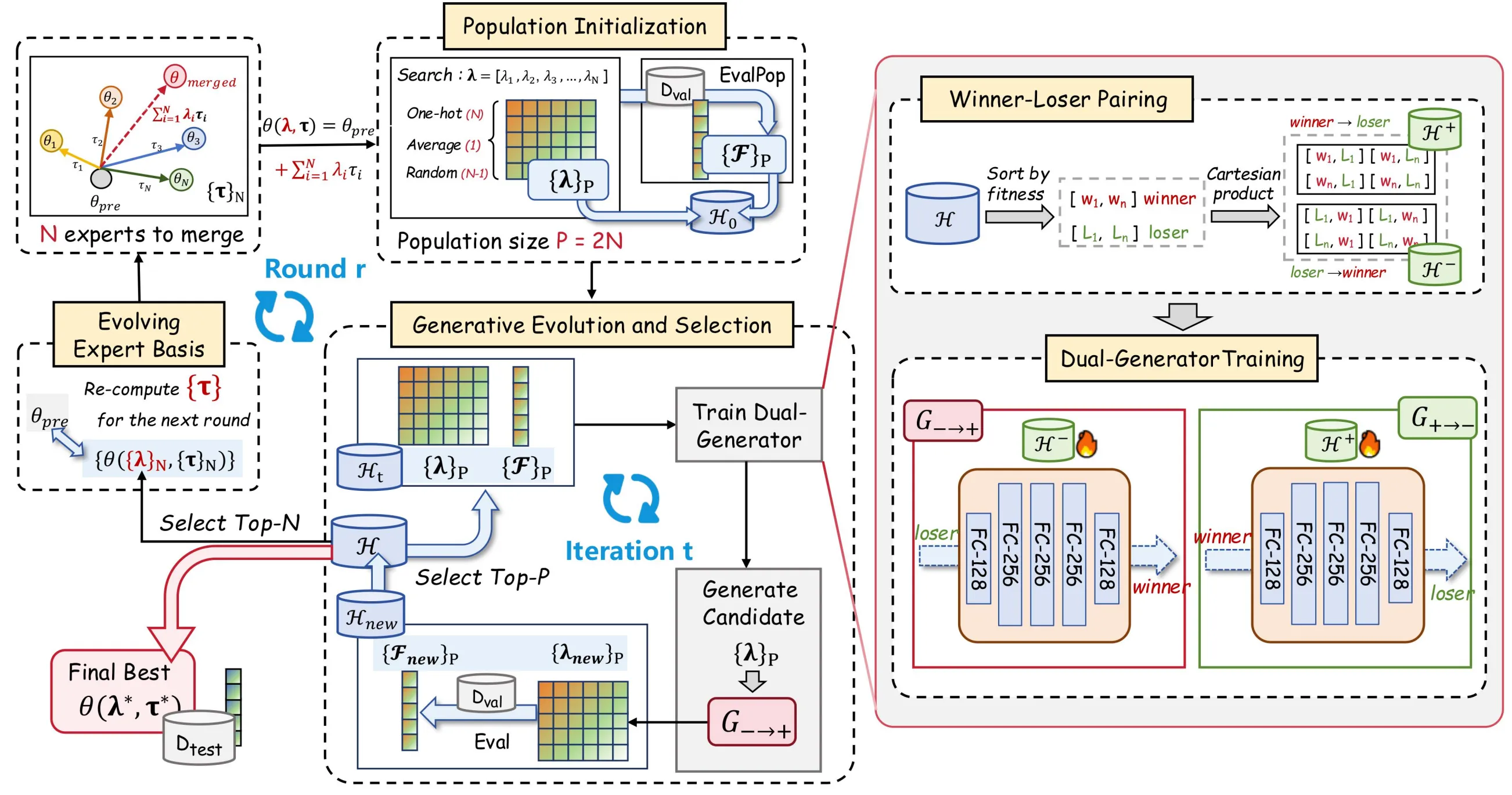
上記の問題を解決するため、EvoGM(Evolutionary Generative Merging)を提案しました。コードはオープンソース化されています:https://github.com/JiangTao97/evogm。
EvoGM の核心思想は、候補マージ設定を集団として組織化し、マージ係数の探索プロセスを生成型学習問題に変換することです。
重要なのは、生成モデルが直接「最適なマージ係数は何か」を学習するのではなく、「劣った設定からより良い設定へどのように変換するか」を学習することです。モデルマージのシナリオでは、異なる設定間で信頼性の高いグローバルランキングを形成することが困難なことが多いからです。対照的に、ペアワイズ比較の方が安定した優劣シグナルを得やすいです。
EvoGM は過去の検証結果を利用して winner-loser ペアリングデータを構築し、生成器が loser から winner への改善方向を学習できるようにします。各候補マージ設定のペアについて、アルゴリズムは対応する性能差を記録するだけでなく、この「劣化から改善への」関係を学習サンプルに変換します。継続的な蓄積と学習を通じて、生成器はどの係数調整が性能向上をもたらす可能性が高いかを徐々に捉え、探索空間の構造に対する暗黙的な理解を形成します。言い換えれば、優れた解そのものではなく、性能向上の法則を学習するのです。
このアプローチは、進化最適化における競争学習メカニズムと一脉相通じています。最初は CSO(Competitive Swarm Optimizer)に遡ります。winner-loser 競争を通じて個体の更新を推進し、性能の劣る個体を性能の良い個体に近づけます。EvoGO(Evolutionary Generative Optimization)はさらに一歩進み、生成モデルを利用して過去の探索データから改善方向を学習し、データ駆動型のアプローチで一部の手動設計された探索オペレータを置き換えます。EvoGM はこの思想をモデルマージのシナリオに導入し、検証フィードバックを通じて生成器を学習し、後続の探索を導きます。こうして、検証結果は候補解のフィルタリングと淘汰にのみ使用されるのではなく、継続的に再利用可能な探索経験へと変換され、探索プロセスが反復を重ねるごとに知識を蓄積し、効率を向上させることができます。
四、EvoGM はどのように動作するのか?
EvoGM の全体的なフローは5つのステップに分けられます。候補案の構築、winner-loser 学習ペアの形成、生成器の学習、新しい係数の生成と選択、およびエキスパート基底の更新です。エキスパートモデルと検証タスクが与えられると、これらのステップは自動的に循環実行でき、マージルールや係数を手動でラウンドごとに設計・調整する必要はありません。
- 集団初期化:候補マージ案の構築
EvoGM はまず初期候補解のバッチを構築する必要があります。ここでの各候補解は、複数のエキスパートモデルの異なる組み合わせ方法、すなわち一組のマージ係数に対応します。
具体的には、初期集団には通常、いくつかの種類の設定が含まれます。平均マージに対応する係数、個々のエキスパートモデルに対応する one-hot 係数、およびランダムサンプリングで得られたマージ係数です。これにより、一般的なベンチマークマージ方式をカバーしつつ、後続の探索に一定の多様性を提供できます。
各候補係数の組み合わせについて、EvoGM はそれに基づいてマージモデルを構築し、検証セット上でその性能を評価します。このステップの後、アルゴリズムが得るのは単なる候補モデルではなく、「マージ係数—検証性能」の履歴記録のバッチです。後続のすべての生成型学習と進化的選択は、これらの記録の上に構築されます。
- 勝者—敗者ペアリング:検証結果を学習データに変換する
候補解とその検証性能を得た後、EvoGM は性能に基づいて過去の候補設定を winner と loser に分類します。winner は相対的により優れたマージ設定を表し、loser は相対的に劣ったマージ設定を表します。
ここでの重要な点は、高スコアの設定を単純に保持し、低スコアの設定を破棄することではなく、両者を学習ペアとして組み合わせることです。生成器にとって、一つの winner-loser pair は有用な情報を提供します。この劣った設定から出発して、どのより良い設定に近づくべきかを示します。
したがって、低性能の候補は無効なサンプルではありません。むしろ、探索プロセスにおける「出発点」を提供し、高性能の候補は「改善方向」を提供します。このペアリング方式により、EvoGM は限られた検証評価結果をより多くの学習可能な教師信号に変換し、小サンプルフィードバック下でのデータ利用効率を向上させることができます。
- デュアル生成器の学習:劣った設定から良い設定への変換を学習する
winner-loser 学習ペアを構築した後、EvoGM はデュアル生成器構造を使用して学習を行います。
フォワード生成器は loser から winner へのマッピング、すなわち低性能マージ設定をより有望な高性能設定へ変換する方法を学習します。逆方向生成器は winner から loser への逆マッピングを学習し、生成プロセスの構造的一貫性を制約するために使用されます。
この設計の目的は、生成器が既存の高スコア設定を単純に記憶することではなく、マージ係数空間における改善法則を学習することです。循環一貫性制約を通じて、EvoGM は生成器が少数の高スコア点に崩壊するリスクを軽減し、生成される候補設定が高性能領域に向かいつつ、探索空間の構造情報をできるだけ保持できるようにします。
- 生成型進化と選択:学習したオペレータでランダム摂動を置き換える
生成器の学習が完了すると、EvoGM はフォワード生成器を使用して現在の候補設定を変換し、新しいマージ係数のバッチを生成します。このステップは従来の進化アルゴリズムにおける「新個体の生成」に相当しますが、新個体は主にランダム摂動からではなく、生成モデルが学習した改善方向から生まれます。
その後、これらの新しく生成されたマージ係数を使用して新しいマージモデルを構築し、再び検証セット上で評価されます。評価結果は履歴記録に追加され、既存の候補とともに選択に参加します。
このような循環を通じて、EvoGM は各ラウンドで「生成—評価—選択—再学習」のプロセスを経験します。この閉ループが候補マージ案の集団進化を構成します。過去の検証結果が継続的に蓄積され、生成器が新しい学習信号を継続的に受け取り、高品質なマージ設定を自律的に生成する能力を段階的に向上させます。
- 進化的エキスパート基底:探索空間を継続的に自己更新する
マージ係数の最適化に加えて、EvoGM はさらに進化的エキスパート基底メカニズムを導入しています。
従来のモデルマージは通常、エキスパートモデルを固定入力として扱い、固定されたエキスパートモデル間でのみマージ係数を探索します。EvoGM は異なります。各ラウンドの終了後、最も性能の良いマージモデルのいくつかが選ばれ、次のラウンドの探索における新しいエキスパート基底となります。
これにより、優れたマージモデル自体がすでに特定の効果的な能力の組み合わせを含んでいることが意味します。これらを新しいエキスパート基底に組み込むことで、後続の探索は元のエキスパートモデル間の線形結合に限定されず、すでに検証済みの中間モデルを基盤として進化を続けることができます。
したがって、EvoGM の探索空間は固定ではなく、探索プロセスに応じて継続的に更新されます。より良いマージ係数を見つけるだけでなく、現在のタスクにより適したエキスパート表現基盤を段階的に構築しています。
五、EvoGM の主要な利点は何か?
従来のモデルマージ手法と比較して、EvoGM の利点は主に3つの側面に現れます。
第一に、EvoGM はモデルマージを静的なヒューリスティックルールからフィードバック駆動型の自律探索へと推進します。従来の手法は平均マージ、手動スケーリング、またはランダム摂動に依存することが多いのに対し、EvoGM は過去の検証結果に基づいて探索方向を継続的に調整でき、マージプロセスが手動でのルール設計と係数調整に依存しなくなります。
第二に、EvoGM は限られた評価予算下でのデータ利用効率を向上させます。モデルマージでは、各候補設定の評価に実際にマージモデルを構築し、検証タスクを実行する必要があり、コストは低くありません。EvoGM はこれらの評価結果をさらに学習可能な学習信号に変換し、各試行錯誤が後続の探索に情報を提供します。
第三に、EvoGM はより良いマージ係数の組み合わせを見つけるだけでなく、エキスパートモデル間の能力組み合わせ法則を段階的に学習します。候補集団の生成型探索とエキスパート基底の更新を通じて、既存のエキスパートモデルを基盤として探索空間を継続的に再編成・拡張し、より効果的に高性能マージモデルを自律的に発見できます。
六、実験結果:EvoGM は本当に有効か?
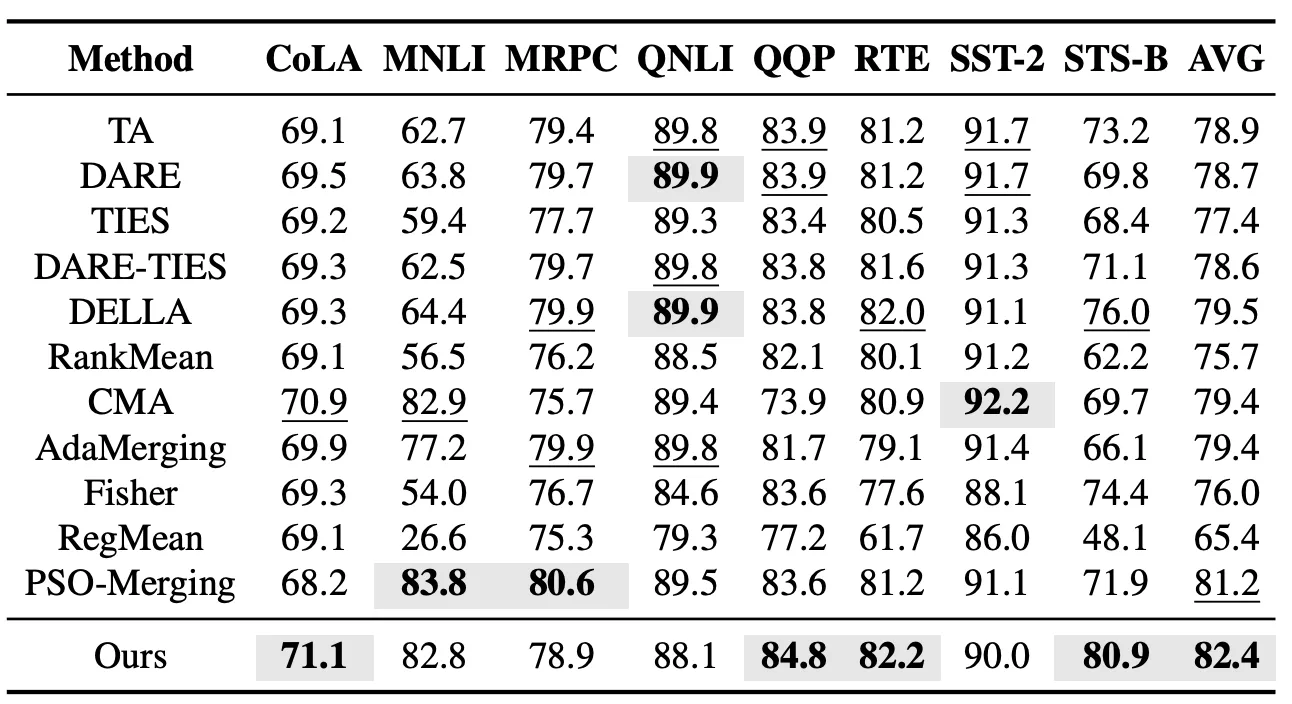
既知タスク設定では、まず GLUE シリーズのタスクで EvoGM のモデルマージ効果を評価しました。この実験は CoLA、MNLI、MRPC、QNLI、QQP、RTE、SST-2、STS-B の8つの言語理解タスクをカバーし、Task Arithmetic、TIES、DARE-TIES、DELLA、RankMean、CMA、AdaMerging、PSO-Merging などの代表的なモデルマージ手法と比較しました。実験結果は、EvoGM が8つのタスクにおける平均性能が、これまで最高の性能を示していた PSO-Merging を上回ることを示しています。
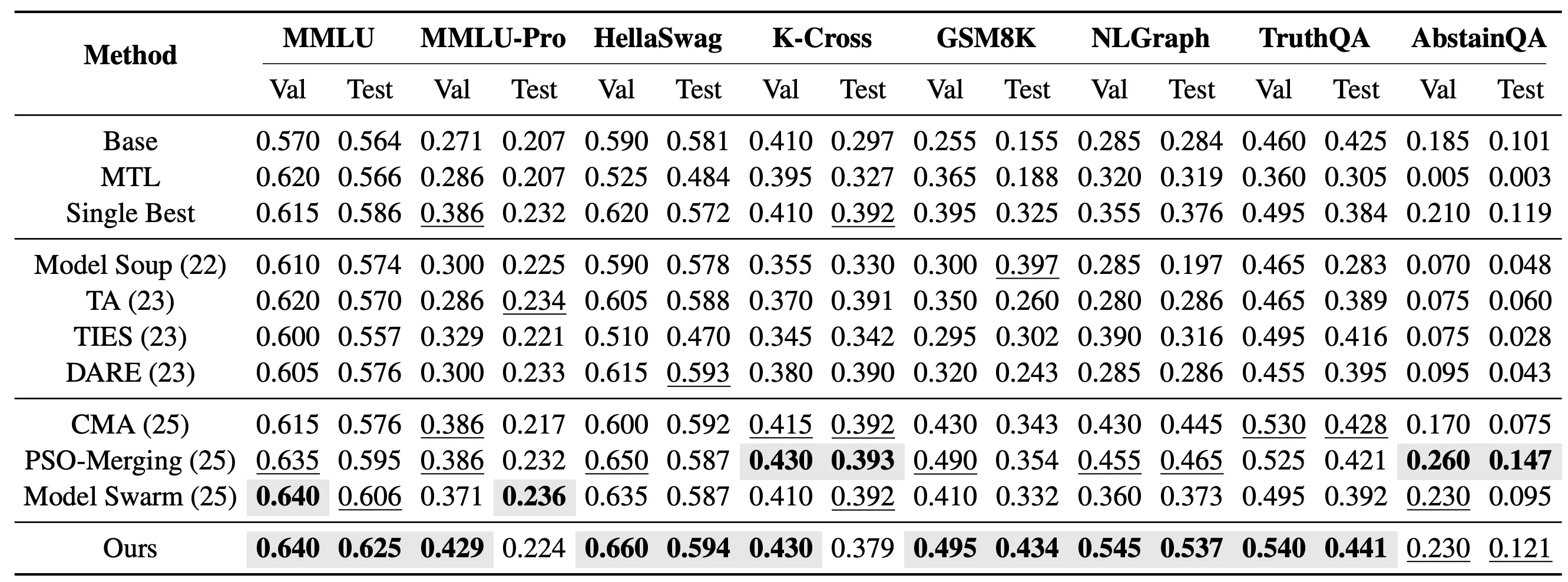
より挑戦的な未知タスク設定では、EvoGM が既存のエキスパートモデルの能力を、エキスパートのファインチューニングに参加していない新しいタスクへ移転できるかをさらに評価しました。具体的には、Qwen2.5-1.5B ベースの10個の LoRA エキスパートモデルをマージし、MMLU、MMLU-Pro、HellaSwag、Knowledge Crosswords、GSM8K、NLGraph、TruthfulQA、AbstainQA の8つの未知タスクでテストしました。これらのタスクは知識理解、複雑な推論、安全性・信頼性など異なる能力次元をカバーし、既知タスクよりもモデルマージ手法の汎化能力をよりよく反映します。
単一タスク未知マージ設定では、EvoGM は各ターゲットタスクに対して個別に一組のマージ係数を探索します。実験結果は、EvoGM が8つのテストタスクのうち5つで最高のテスト性能を達成したことを示しています。
単一タスクマージに加えて、マルチタスク未知マージ設定もさらに検討しました。この設定では、各タスクに対して個別に最適モデルを見つけるのではなく、8つの未知タスクを同時にカバーできる統一マージモデルを得ることが目標です。実験結果は、マルチタスク未知マージにおいて、EvoGM がすべてのマージ手法の中で最高の平均テスト性能を達成したことを示しています。
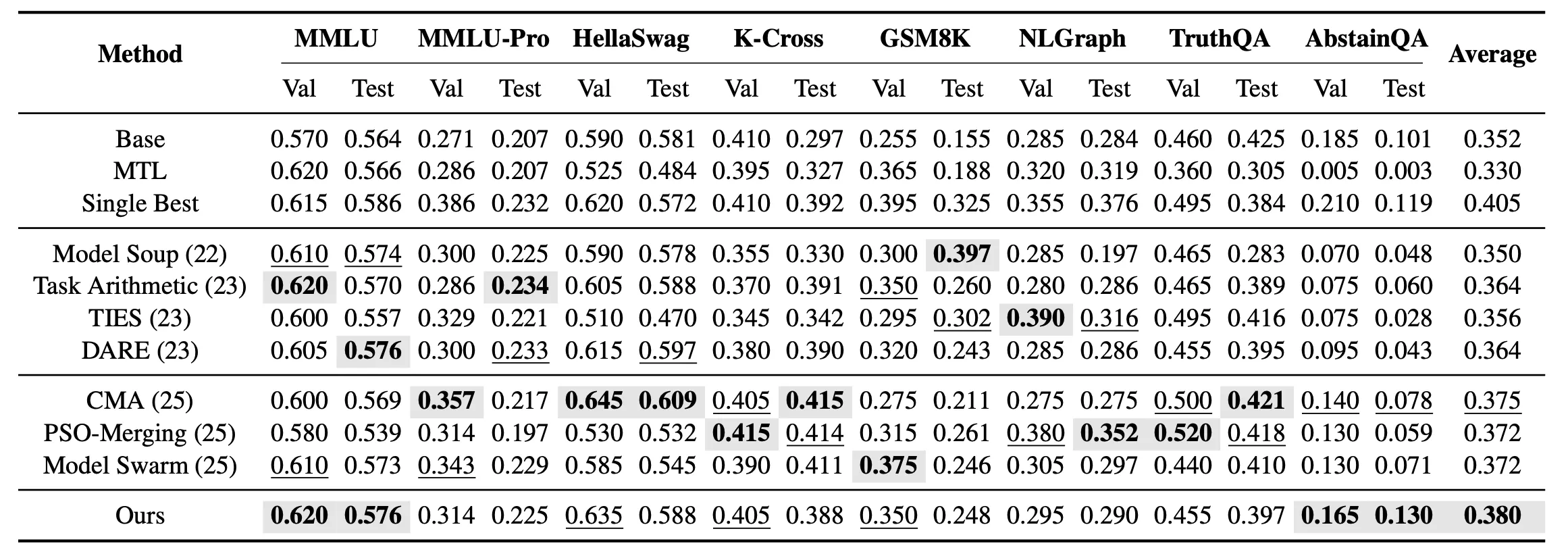
結果は、EvoGM が単一タスクマージとマルチタスク設定の両方で、より強力な全体的な汎化性能を達成し、複数の知識、推論、安全関連タスクで既存のモデルマージ手法を上回ることを示しています。
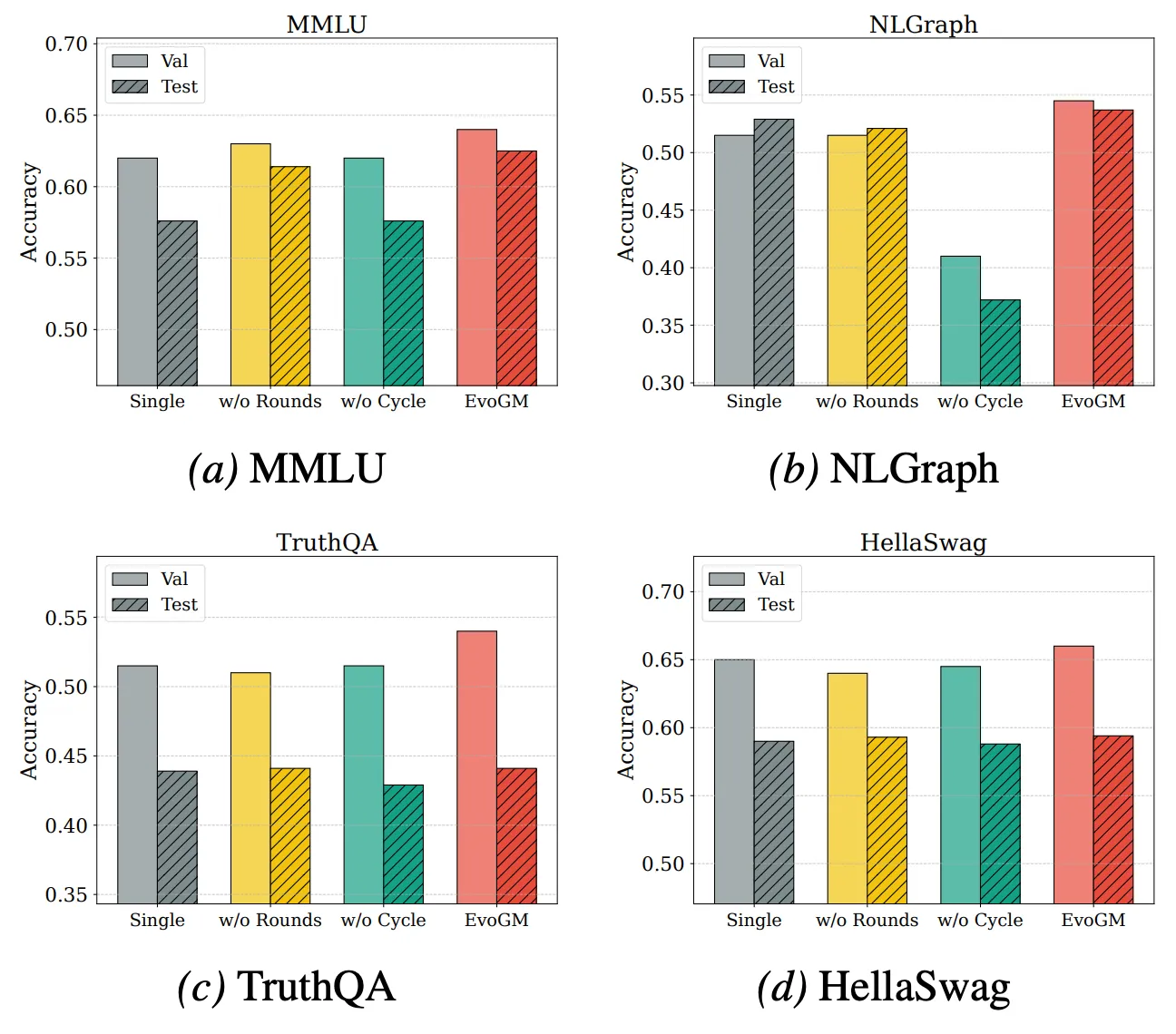
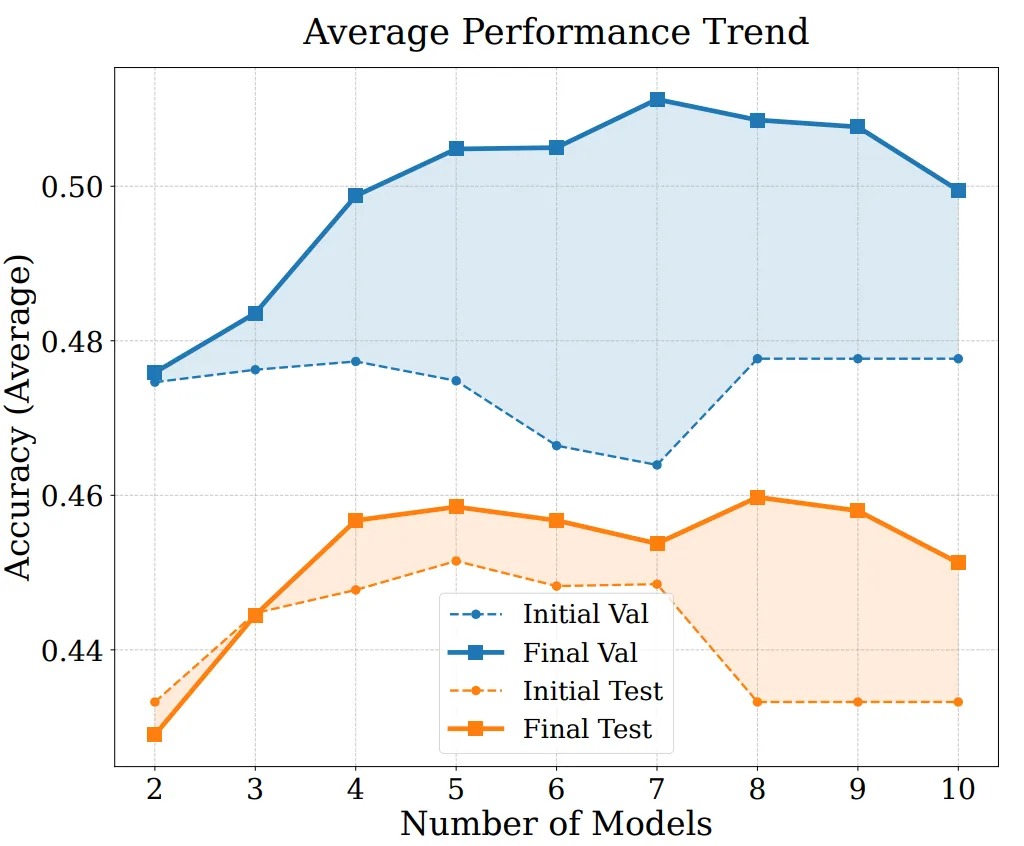
EvoGM の性能の源泉と拡張能力をさらに分析するため、消融実験と異なるモデル数でのマージ実験を実施しました。結果は、完全な EvoGM が常に最適または最も安定した性能を達成し、主要コンポーネントを除去すると性能がさまざまな程度で低下することを示しています。これは、その優位性が主に生成型進化メカニズムに由来し、単純なランダム探索やより多くの探索ラウンドではないことを示しています。同時に、マージに参加するエキスパートモデルの数が増加しても、EvoGM は良好な性能を維持し、安定した向上傾向を示し、より大規模で複雑なマージ空間に効果的に対応し、異なるエキスパートモデル間の相互補完的能力を十分に活用できる優れた拡張性を持つことを示しています。
七、EvoGO から EvoGM へ:生成型進化思想の延伸
より大きな視点から見ると、EvoGM は大規模モデルマージにおける EvoGO 思想の延伸と理解できます。EvoGO は、進化最適化が手動設計された交叉、変異、摂動オペレータへの依存から、生成モデルが過去の探索データに基づいて新しい解の生成方法を自動的に学習する方向へ移行する方法に焦点を当てています。つまり、進化探索は「候補解をランダムに生成してフィルタリングする」だけでなく、「より有望な候補解をどのように生成するか」を学習し始めます。
EvoGM はこの思想を大規模モデルマージのシナリオに適用します。ここでは、候補解は一般最適化問題の数値変数ではなく、一組のマージ係数です。一度の評価も単純な目的関数の計算ではなく、マージモデルを構築し、下流タスクで性能を検証することです。したがって、EvoGM は実際にモデルマージを生成型最適化問題として再定式化します。過去の評価結果からエキスパートモデル間の能力組み合わせ法則を学習し、より優れたマージ設定を生成する方法です。
この点が EvoGM を従来の探索型モデルマージと明確に区別します。従来の手法は通常、検証結果をランキングとフィルタリングにのみ使用しますが、EvoGM はさらに検証結果を学習信号に変換します。低性能設定は単純に破棄されるのではなく、高性能設定と winner-loser pairs を形成し、生成器が劣った設定から良い設定への進化方向を学習するために使用されます。
EvoGO から EvoGM へは、本質的に「候補解の最適化方法を学習する」から「大規模モデルマージ戦略を集団の中で自律的に進化させる」への移行です。これにより、モデルマージは経験則とランダム摂動から解放されるだけでなく、新しいアプローチも提供します。大規模モデルの能力はマージでき、マージ戦略自体も集団フィードバックから継続的に学習できるのです。
八、結論と展望
オープンソースエコシステムにおけるエキスパートモデル、LoRA モデル、タスクモデルが増え続ける中、将来の重要な問題は「新しいモデルをどのようにトレーニングするか」だけでなく、「既存のモデル能力をどのように効率的に組み合わせるか」かもしれません。EvoGM は新しい答えを提供します。マージに参加する大規模モデルを再トレーニングすることなく、生成型進化学習を通じて限られた検証フィードバックを活用し、候補集団の構築、マージ案の生成、評価選択、エキスパート基底の更新を自律的に完了します。簡単に言えば、EvoGM はモデルマージを「経験に基づく係数調整」から「マージ戦略自身が学習し進化する」方向へ導きます。これは、大規模モデル能力の再利用が新たな段階に入る可能性を意味します。新しいタスクに遭遇するたびにモデルを再トレーニングするのではなく、既存のエキスパートモデルが集団進化と自律的マージを通じて、新しいタスクにより適したモデルを継続的に組み合わせ出すのです。
オープンソースコード / コミュニティ
📄 論文: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 上流プロジェクト(EvoX):
https://github.com/EMI-Group/evox 🌐 QQ 交流グループ:297969717
