ICML 2026 | EvoGM: autonome Modellfusion durch Populationsentwicklung ohne erneutes Training

Zusammenfassung
Mit der kontinuierlichen Verbesserung der Fähigkeiten großer Sprachmodelle wächst auch die Zahl der durch Fine-Tuning auf verschiedene Aufgaben erhaltenen Expertenmodelle. Wie die Fähigkeiten dieser Expertenmodelle effizient wiederverwendet werden können, ohne die an der Fusion beteiligten großen Modelle erneut zu trainieren und ohne auf zusätzliche großskalige Trainingsdaten angewiesen zu sein, ist eine zentrale Frage in der Modellfusion. Bestehende Methoden stützen sich typischerweise auf Durchschnittsfusion, manuelles Scaling, Parameter-Pruning oder zufällige Suche. Obwohl sie die Fähigkeiten mehrerer Modelle zu einem bestimmten Grad kombinieren können, fällt es ihnen schwer, kontinuierlich aus historischen Bewertungen zu lernen und Fusionstrategien zu verbessern.
Um dieses Problem zu lösen, schlagen das EvoX-Team in Zusammenarbeit mit dem Peng Cheng Laboratory EvoGM (Evolutionary Generative Merging) vor, ein generatives evolutionäres Modellfusion-Framework, das die Suche nach Fusionskoeffizienten in ein lernbares generatives Optimierungsproblem umwandelt. EvoGM organisiert verschiedene Fusionkonfigurationen als Kandidatenpopulation und evolviert die Population durch winner-loser-Pairing, Training mit doppeltem Generator, zyklische Konsistenzbeschränkungen und evolutionäre Aktualisierung der Expertenbasis in einer geschlossenen Schleife von „Generierung — Bewertung — Selektion — erneutes Lernen“, wobei es autonom aus begrenztem Validierungsfeedback lernt, wie Konfigurationen mit niedriger Leistung in Konfigurationen mit hoher Leistung transformiert werden. Experimentelle Ergebnisse zeigen, dass EvoGM in Szenarien mit gesehenen und ungesehenen Aufgaben eine stärkere Modellfusion-Fähigkeit demonstriert.
I. Warum brauchen wir Modellfusion?
In den letzten Jahren werden die Fähigkeiten großer Sprachmodelle immer stärker, aber die Kosten für Training und Fine-Tuning steigen ebenfalls. Eine natürliche Frage lautet: Wenn wir bereits mehrere Expertenmodelle haben, die auf verschiedenen Aufgaben gut abschneiden, können wir ihre Fähigkeiten kombinieren, ohne diese großen Modelle erneut zu trainieren, und ein stärkeres, allgemeineres neues Modell erhalten?
Genau dieses Problem versucht die Modellfusion zu lösen.
Die Kernidee der Modellfusion ist einfach: Mehrere Expertenmodelle stammen oft vom selben Basismodell und wurden lediglich auf verschiedenen Daten oder Aufgaben fine-tuned. Daher kann man die Parameteränderungen jedes Expertenmodells relativ zum Basismodell als „Fähigkeitsrichtungen“ betrachten und diese Richtungen gewichtet kombinieren, um ein neues fusioniertes Modell zu konstruieren. Der Vorteil ist, dass die an der Fusion beteiligten großen Modelle nicht erneut trainiert oder fine-tuned werden müssen und keine zusätzlichen großskaligen Trainingsdaten benötigt werden — es genügt, geeignete Fusionskoeffizienten zu suchen. Es sei darauf hingewiesen, dass EvoGM leichtgewichtige Generatoren trainiert, um Koeffizienten zu suchen, aber die Parameter der großen Expertenmodelle nicht aktualisiert.
II. Wo liegt die wahre Schwierigkeit der Modellfusion?
Die wahre Schwierigkeit liegt hier: Wie sollten diese Koeffizienten gewählt werden?
Modellfusion scheint nur eine gewichtete Kombination mehrerer Expertenmodelle zu sein, aber die Fähigkeitsbeziehungen zwischen verschiedenen Expertenmodellen sind nicht einfach. Manche Aufgabenrichtungen können sich ergänzen, während manche Parameteraktualisierungen in Konflikt geraten können; eine Fusionskoeffizienten-Kombination kann bei einer Art von Aufgaben besser abschneiden, aber bei einer anderen Art Leistungsverluste verursachen. Die Beziehung zwischen Fusionskoeffizienten und der endgültigen Modellleistung ist daher keine leicht manuell charakterisierbare lineare Beziehung.
Traditionelle Methoden stützen sich typischerweise auf heuristische Regeln wie Durchschnittsfusion, manuelles Scaling, Parameter-Pruning oder Sparsifizierung. Diese Methoden sind einfach und effektiv, weisen aber offensichtliche Grenzen auf: Sie sind oft statisch und empirisch und fällt es schwer, sich adaptiv an Validierungsfeedback verschiedener Aufgaben anzupassen.
Später wurden evolutionäre Suchmethoden in die Modellfusion eingeführt, die Kandidatenfusionkonfigurationen als Populationen organisieren und durch zufällige Perturbation, Fitness-Bewertung und Selektion bessere Koeffizienten suchen. Diese Methoden sind flexibler als feste Regeln, aber ein zentrales Problem bleibt: Validierungsergebnisse werden typischerlich nur für Ranking und Filterung verwendet, ohne weiter in lernbare Sucherfahrung transformiert zu werden. Mit anderen Worten: Der Algorithmus weiß, „welcher Kandidat besser ist“, aber lernt nicht wirklich, „wie ein schlechterer Kandidat besser werden sollte“.
Dies ist das Kernproblem, das EvoGM lösen möchte: Modellfusion sollte nicht nur dazu dienen, dass die Kandidatenpopulation kontinuierlich trial-and-error und Filterung durchführt, sondern aus historischen Bewertungen Verbesserungsrichtungen lernen und autonom vielversprechendere Fusionkonfigurationen erzeugen.
III. EvoGM: Fusionstrategie in Populationsentwicklung autonom lernen lassen
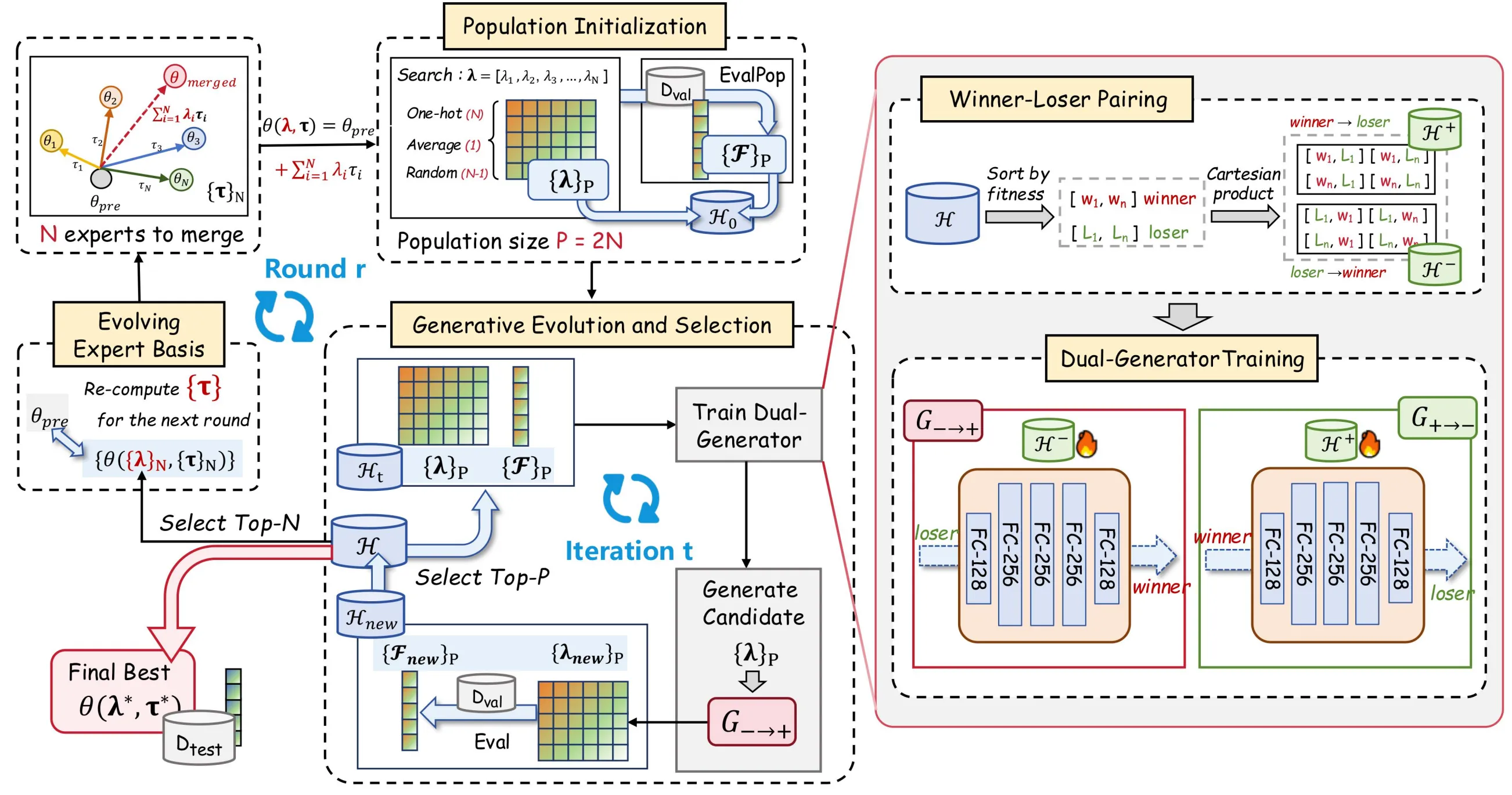
Um die oben genannten Probleme zu lösen, schlagen wir EvoGM (Evolutionary Generative Merging) vor, dessen Code open source verfügbar ist: https://github.com/JiangTao97/evogm.
Die Kernidee von EvoGM ist, Kandidatenfusionkonfigurationen als Population zu organisieren und den Suchprozess für Fusionskoeffizienten in ein generatives Lernproblem zu transformieren.
Entscheidend ist, dass das generative Modell nicht direkt lernt, „was die optimalen Fusionskoeffizienten sind“, sondern „wie eine schlechtere Konfiguration in eine bessere Konfiguration transformiert wird“. Denn im Kontext der Modellfusion ist es schwierig, eine zuverlässige globale Rangordnung zwischen verschiedenen Konfigurationen zu bilden; im Vergleich liefern paarweise Vergleiche stabilere Überlegenheitssignale.
EvoGM nutzt historische Validierungsergebnisse, um winner-loser-Pairing-Daten zu konstruieren, und ermöglicht dem Generator, die Verbesserungsrichtung vom loser zum winner zu lernen. Für jede Paar von Kandidatenfusionkonfigurationen zeichnet der Algorithmus nicht nur ihre Leistungsunterschiede auf, sondern transformiert diese „von schlecht zu gut“-Beziehung auch in Trainingssamples. Durch kontinuierliche Akkumulation und Lernen kann der Generator allmählich erfassen, welche Koeffizientenanpassungen wahrscheinlicher zu Leistungssteigerungen führen, und so ein implizites Verständnis der Struktur des Suchraums aufbauen. Mit anderen Worten: Er lernt nicht die exzellenten Lösungen selbst, sondern die Gesetze der Leistungsverbesserung.
Dieser Ansatz steht in der Tradition der Wettbewerbslernmechanismen in evolutionärer Optimierung. Er reicht zurück bis zum CSO (Competitive Swarm Optimizer), der Individuen durch winner-loser-Wettbewerb zu Aktualisierungen antreibt und schlechter performende Individuen an besser performende heranführt; EvoGO (Evolutionary Generative Optimization) nutzt generative Modelle weiter, um Verbesserungsrichtungen aus historischen Suchdaten zu lernen und einen Teil der manuell entworfenen Suchoperatoren datengetrieben zu ersetzen. EvoGM führt diese Idee in den Kontext der Modellfusion ein, trainiert den Generator durch Validierungsfeedback und leitet die anschließende Suche. So dienen Validierungsergebnisse nicht mehr nur zum Filtern und Eliminieren von Kandidaten, sondern werden kontinuierlich in wiederverwendbare Sucherfahrung transformiert, sodass der Suchprozess mit jeder Iteration Wissen akkumulieren und seine Effizienz steigern kann.
IV. Wie funktioniert EvoGM?
Der Gesamtprozess von EvoGM kann in fünf Schritte unterteilt werden: Kandidatenkonstruktion, Bildung von winner-loser-Trainingpaaren, Generator-Training, Generierung und Selektion neuer Koeffizienten sowie Aktualisierung der Expertenbasis. Nach Festlegung der Expertenmodelle und Validierungsaufgaben können diese Schritte automatisch in Schleifen ausgeführt werden, ohne dass manuelle Gestaltung von Fusionregeln oder Koeffizientenanpassung in jeder Iteration erforderlich ist.
- Populationsinitialisierung: Kandidatenfusionpläne konstruieren
EvoGM beginnt mit der Konstruktion einer Menge initialer Kandidaten. Jeder Kandidat entspricht einer Kombination von Fusionskoeffizienten, also einer unterschiedlichen Art, mehrere Expertenmodelle zu kombinieren.
Konkret umfasst die initiale Population typischerweise mehrere Konfigurationstypen: Koeffizienten für Durchschnittsfusion, one-hot-Koeffizienten für ein einzelnes Expertenmodell und durch zufälliges Sampling erhaltene Fusionskoeffizienten. Dies deckt gängige Referenzfusionmethoden ab und bietet gleichzeitig ausreichende Diversität für die anschließende Suche.
Für jede Kandidatenkoeffizienten-Kombination konstruiert EvoGM ein fusioniertes Modell und bewertet dessen Leistung auf dem Validierungsdatensatz. Nach diesem Schritt erhält der Algorithmus nicht nur mehrere Kandidatenmodelle, sondern auch eine Reihe historischer Aufzeichnungen „Fusionskoeffizienten — Validierungsleistung“. Alle anschließenden generativen Lern- und evolutionären Selektionsprozesse basieren auf diesen Aufzeichnungen.
- Winner-loser-Pairing: Validierungsergebnisse in Trainingsdaten transformieren
Nach Erhalt der Kandidaten und ihrer Validierungsleistung teilt EvoGM historische Kandidatenkonfigurationen nach Leistung in winner und loser. Der winner repräsentiert eine relativ bessere Fusionkonfiguration, der loser eine relativ schlechtere Fusionkonfiguration.
Entscheidend ist hier nicht, einfach Konfigurationen mit hohen Scores zu behalten und solche mit niedrigen Scores zu verwerfen, sondern beide als Trainingpaare zu bilden. Für den Generator liefert ein winner-loser-Paar eine nützliche Information: Von dieser schlechteren Konfiguration aus, zu welcher besseren Konfiguration sollte man sich annähern?
Daher sind Kandidaten mit niedriger Leistung keine ungültigen Samples. Sie liefern vielmehr den „Startpunkt“ des Suchprozesses, während Kandidaten mit hoher Leistung die „Verbesserungsrichtung“ liefern. Durch dieses Pairing kann EvoGM begrenzte Validierungsbewertungsergebnisse in mehr lernbare Supervisionssignale transformieren und die Datennutzungseffizienz bei kleinem Feedback verbessern.
- Training mit doppeltem Generator: Transformation von schlechten zu guten Konfigurationen lernen
Nach der Konstruktion der winner-loser-Trainingpaare verwendet EvoGM eine Doppelgenerator-Struktur für das Training.
Der Forward-Generator lernt das Mapping vom loser zum winner, also die Transformation einer Fusionkonfiguration mit niedriger Leistung in eine vielversprechendere Fusionkonfiguration mit hoher Leistung. Der Backward-Generator lernt das inverse Mapping vom winner zurück zum loser und dient der Beschränkung der strukturellen Konsistenz des Generierungsprozesses.
Dieses Design zielt nicht darauf ab, dass der Generator vorhandene Konfigurationen mit hohen Scores einfach memorisiert, sondern dass er die Verbesserungsgesetze im Fusionskoeffizienten-Raum lernt. Durch zyklische Konsistenzbeschränkungen kann EvoGM das Risiko reduzieren, dass der Generator auf wenige Punkte mit hohen Scores kollabiert, sodass generierte Kandidatenkonfigurationen sowohl in Richtung Hochleistungsregionen gehen als auch möglichst strukturelle Informationen des Suchraums erhalten.
- Generative Evolution und Selektion: gelernte Operatoren statt zufälliger Perturbation
Nach Abschluss des Generator-Trainings verwendet EvoGM den Forward-Generator, um aktuelle Kandidatenkonfigurationen zu transformieren und eine neue Menge von Fusionskoeffizienten zu generieren. Dieser Schritt entspricht der „Erzeugung neuer Individuen“ in traditionellen evolutionären Algorithmen, aber neue Individuen stammen nicht mehr primär aus zufälligen Perturbationen, sondern aus den vom generativen Modell gelernten Verbesserungsrichtungen.
Anschließend werden diese neu generierten Fusionskoeffizienten verwendet, um neue fusionierte Modelle zu konstruieren und erneut auf dem Validierungsdatensatz zu bewerten. Bewertungsergebnisse werden in die historischen Aufzeichnungen aufgenommen und gemeinsam mit vorhandenen Kandidaten an der Selektion teilnehmen.
Durch diese Schleife durchläuft EvoGM in jeder Iteration einen Prozess von „Generierung — Bewertung — Selektion — erneutes Lernen“. Diese geschlossene Schleife bildet die Populationsentwicklung der Kandidatenfusionpläne: Historische Validierungsergebnisse akkumulieren kontinuierlich, der Generator erhält neue Trainingssignale und steigert allmählich seine Fähigkeit, autonom hochwertige Fusionkonfigurationen zu generieren.
- Evolutionäre Expertenbasis: Suchraum kontinuierlich selbst aktualisieren
Neben der Optimierung von Fusionskoeffizienten führt EvoGM zusätzlich einen Mechanismus der evolutionären Expertenbasis ein.
Traditionelle Modellfusion betrachtet Expertenmodelle typischerweise als feste Eingaben und sucht nur Fusionskoeffizienten zwischen festen Expertenmodellen. EvoGM ist anders: Nach jeder Iteration werden die bestperformenden fusionierten Modelle ausgewählt und dienen als neue Expertenbasis in der Suche der nächsten Iteration.
Der Sinn dieses Vorgehens ist, dass exzellente fusionierte Modelle bereits bestimmte effektive Fähigkeitskombinationen enthalten. Nach ihrer Aufnahme in die neue Expertenbasis ist die anschließende Suche nicht mehr auf lineare Kombinationen zwischen den ursprünglichen Expertenmodellen beschränkt, sondern kann auf bereits als effektiv validierten Zwischenmodellen weiter evolvieren.
Daher ist der Suchraum von EvoGM nicht fest, sondern wird mit dem Suchprozess kontinuierlich aktualisiert. Es sucht nicht nur bessere Fusionskoeffizienten, sondern konstruiert allmählich eine Expertenrepräsentationsbasis, die besser für die aktuelle Aufgabe geeignet ist.
V. Was sind die zentralen Vorteile von EvoGM?
Im Vergleich zu traditionellen Modellfusion-Methoden manifestieren sich die Vorteile von EvoGM vor allem in drei Aspekten.
Erstens treibt EvoGM Modellfusion von statischen heuristischen Regeln zu feedbackgetriebener autonomer Suche voran. Traditionelle Methoden stützen sich oft auf Durchschnittsfusion, manuelles Scaling oder zufällige Perturbation, während EvoGM die Suchrichtung kontinuierlich an historischen Validierungsergebnissen anpassen kann, sodass der Fusionprozess nicht von manueller Regelgestaltung und Koeffizientenanpassung in jeder Iteration abhängt.
Zweitens verbessert EvoGM die Datennutzungseffizienz unter begrenztem Bewertungsbudget. In der Modellfusion erfordert jede Bewertung einer Kandidatenkonfiguration die tatsächliche Konstruktion eines fusionierten Modells und die Ausführung von Validierungsaufgaben, was nicht gering ist. EvoGM transformiert diese Bewertungsergebnisse weiter in lernbare Trainingssignale, sodass jeder Trial Informationen für die anschließende Suche liefern kann.
Schließlich sucht EvoGM nicht nur eine bessere Kombination von Fusionskoeffizienten, sondern lernt allmählich die Gesetze der Fähigkeitskombination zwischen Expertenmodellen. Durch generative Suche der Kandidatenpopulation und Aktualisierung der Expertenbasis kann es den Suchraum auf Basis vorhandener Expertenmodelle kontinuierlich recombinieren und erweitern und so effektiver hochperformante fusionierte Modelle autonom entdecken.
VI. Experimentelle Ergebnisse: Ist EvoGM wirklich effektiv?
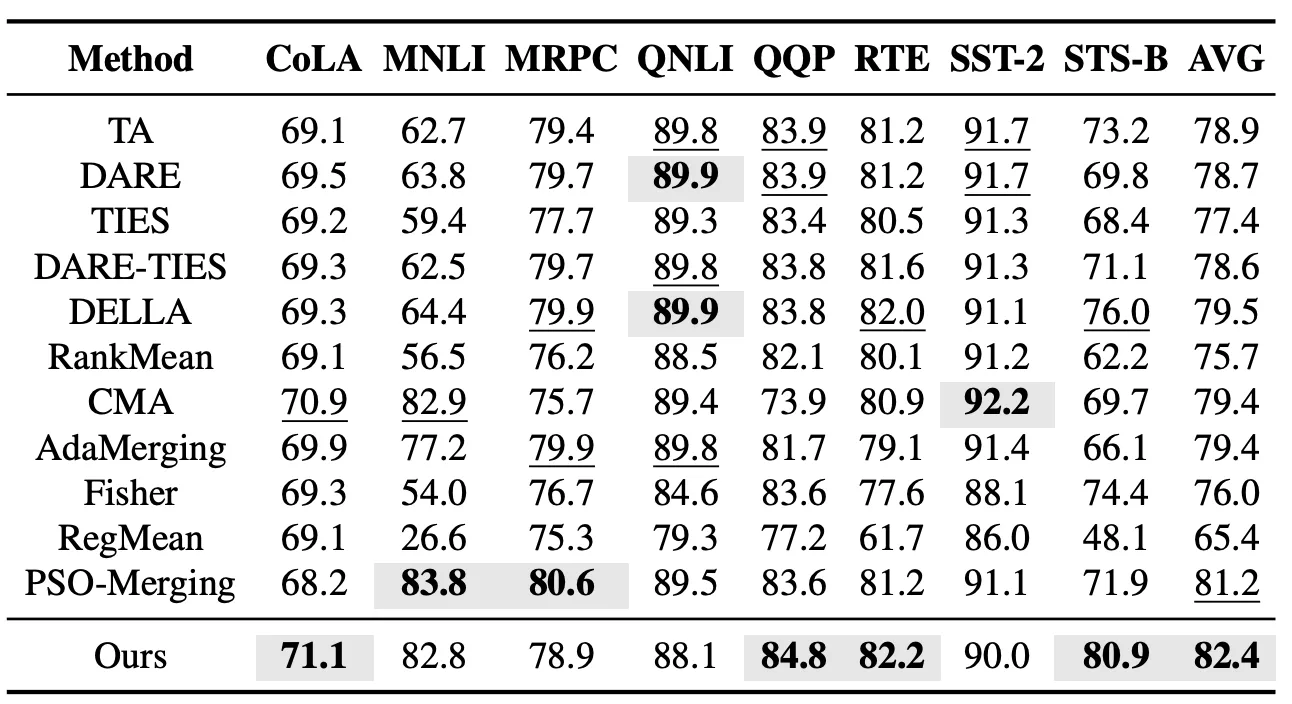
Im Setting mit gesehenen Aufgaben bewerten wir zunächst die Modellfusion-Effekte von EvoGM auf GLUE-Aufgaben. Dieses Experiment umfasst 8 Sprachverständnisaufgaben: CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2 und STS-B, und vergleicht EvoGM mit repräsentativen Modellfusion-Methoden wie Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging und PSO-Merging. Die Ergebnisse zeigen, dass EvoGM in der Durchschnittsleistung über alle 8 Aufgaben das zuvor beste PSO-Merging übertrifft.
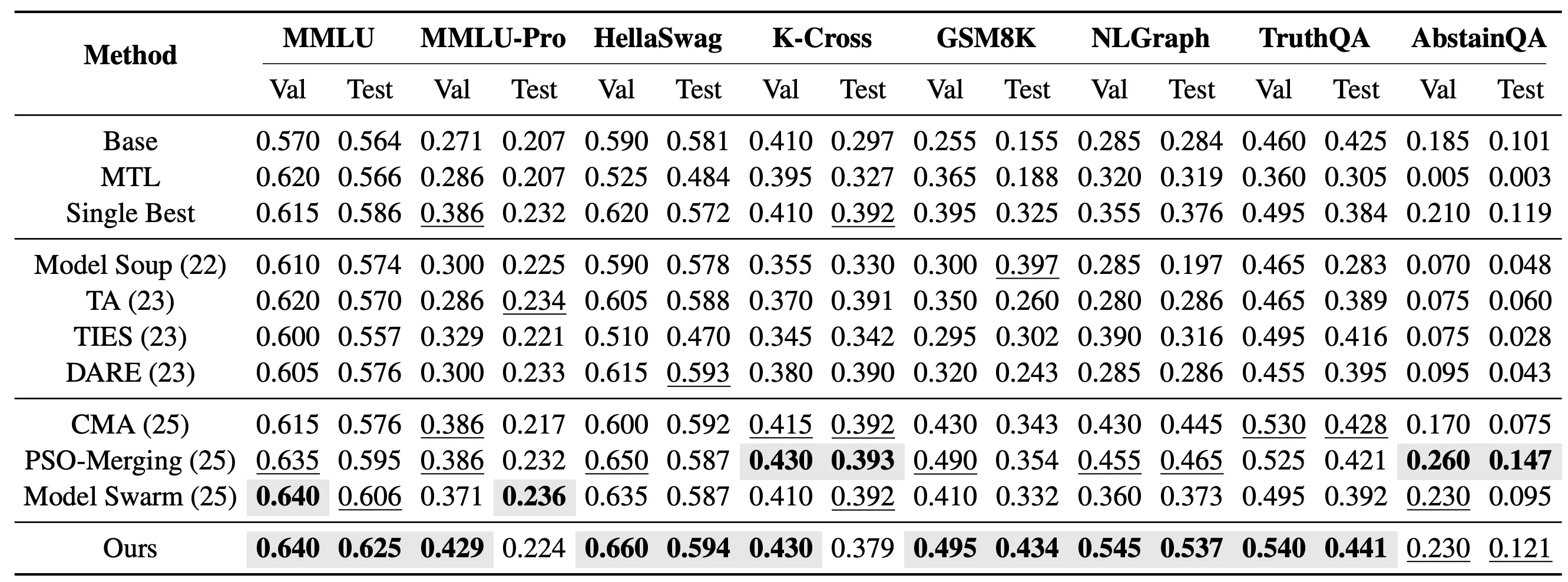
Im anspruchsvolleren Setting mit ungesehenen Aufgaben bewerten wir weiter, ob EvoGM die Fähigkeiten vorhandener Expertenmodelle auf neue Aufgaben transferieren kann, die nicht am Fine-Tuning der Experten beteiligt waren. Konkret fusionieren wir 10 LoRA-Expertenmodelle basierend auf Qwen2.5-1.5B und testen auf 8 ungesehenen Aufgaben: MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA und AbstainQA. Diese Aufgaben decken verschiedene Fähigkeitsdimensionen wie Wissensverständnis, komplexes Reasoning und Sicherheitszuverlässigkeit ab und spiegeln die Generalisierungsfähigkeit von Modellfusion-Methoden besser wider als gesehene Aufgaben.
Im Setting der ungesehenen Einzelaufgaben-Fusion sucht EvoGM für jede Zielaufgabe jeweils eine Kombination von Fusionskoeffizienten. Die Ergebnisse zeigen, dass EvoGM auf 5 der 8 Testaufgaben die höchste Testleistung erzielt.
Über Einzelaufgaben-Fusion gehen wir weiter und untersuchen das Setting der ungesehenen Multi-Task-Fusion. In diesem Setting ist das Ziel nicht mehr, für jede Aufgabe einzeln das optimale Modell zu finden, sondern ein einheitliches fusioniertes Modell zu erhalten, das alle 8 ungesehenen Aufgaben gleichzeitig abdecken kann. Experimentelle Ergebnisse zeigen, dass EvoGM in der ungesehenen Multi-Task-Fusion die höchste Durchschnittstestleistung unter allen Fusionmethoden erzielt.
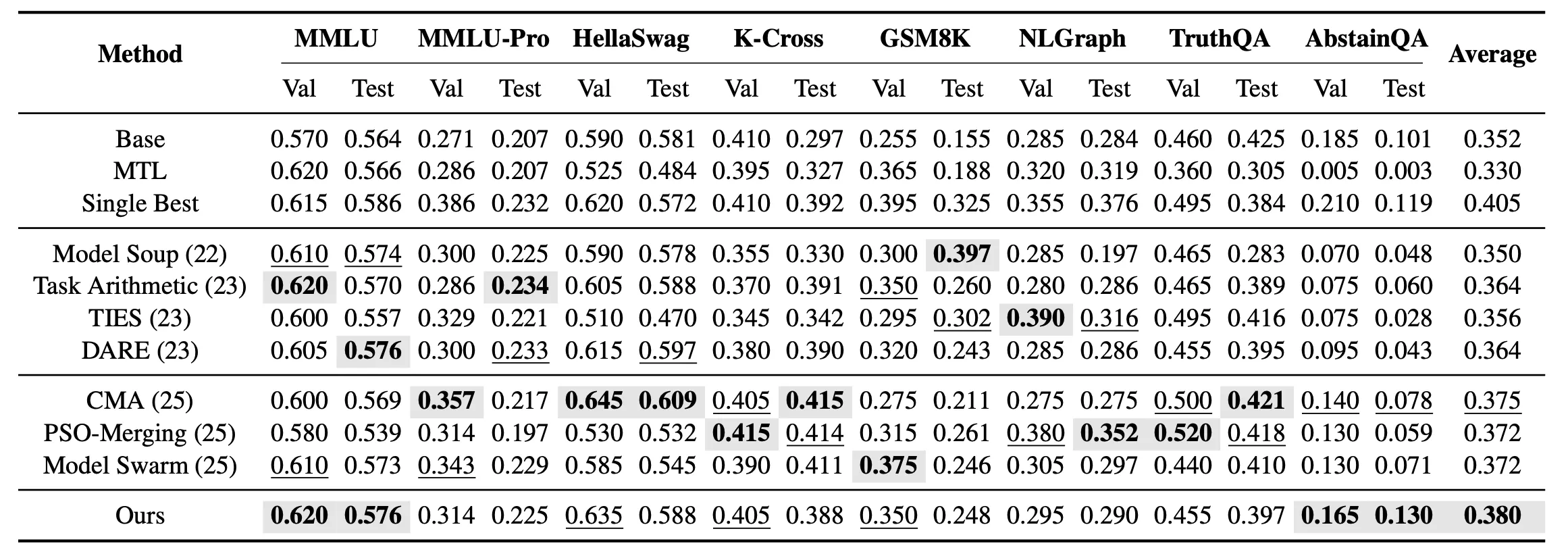
Die Ergebnisse zeigen, dass EvoGM in Einzelaufgaben- und Multi-Task-Settings eine stärkere Gesamtgeneralisierungsleistung erzielt und in mehreren wissens-, reasoning- und sicherheitsbezogenen Aufgaben bestehende Modellfusion-Methoden übertrifft.
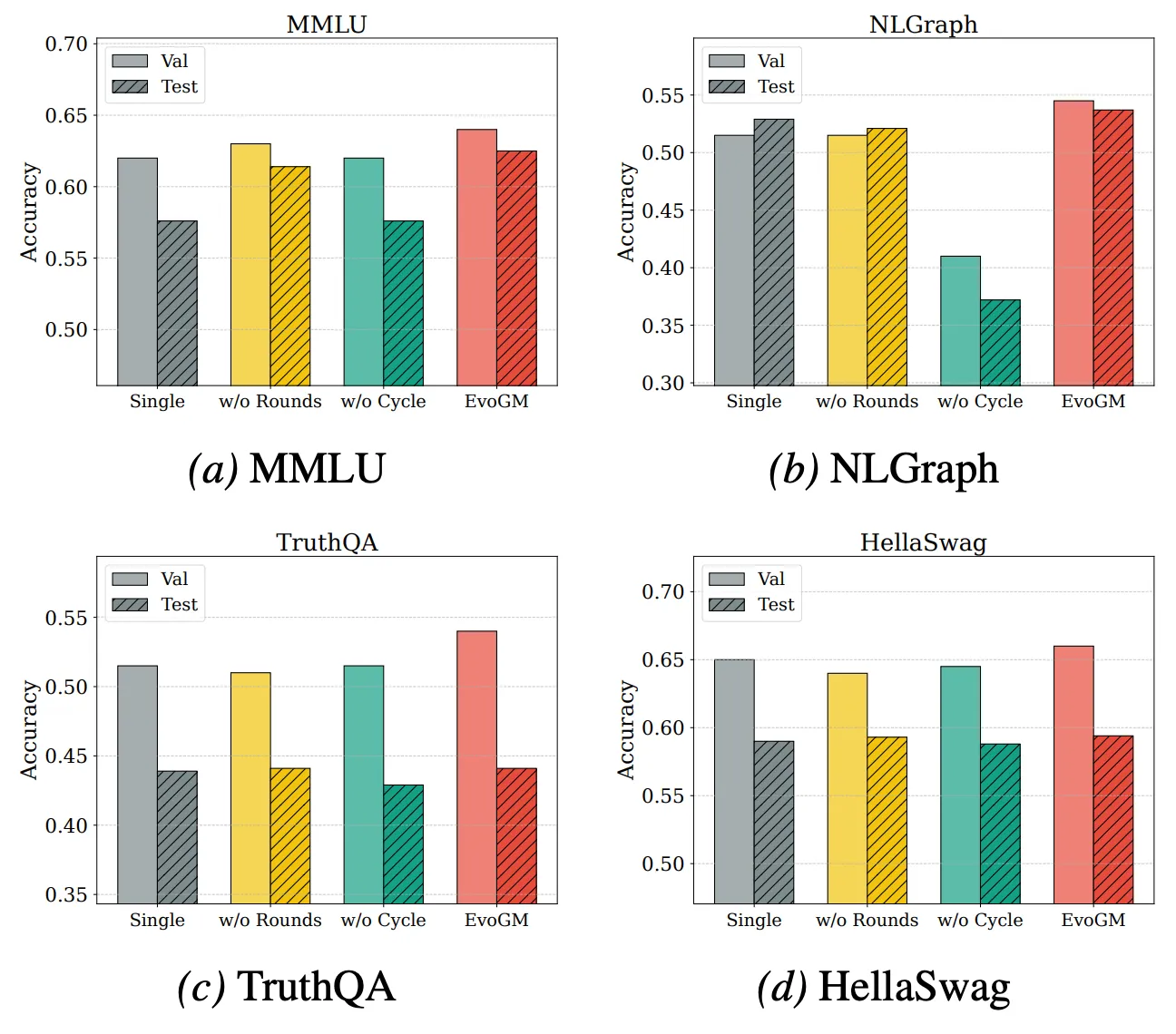
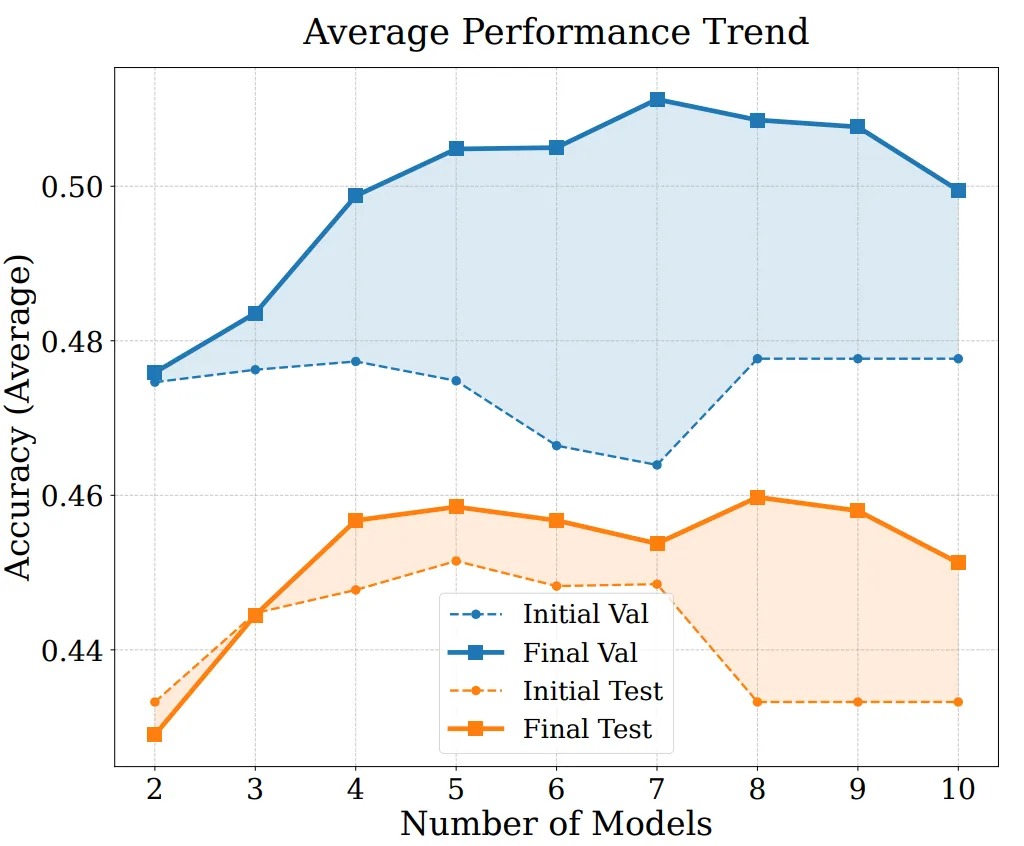
Um die Leistungsquellen und Erweiterungsfähigkeiten von EvoGM weiter zu analysieren, führten wir Ablationsexperimente und Fusionsexperimente mit unterschiedlichen Modellzahlen durch. Die Ergebnisse zeigen, dass vollständiges EvoGM stets optimale oder stabilste Leistung erzielt; nach Entfernung zentraler Komponenten sinkt die Leistung in unterschiedlichem Grad, was darauf hinweist, dass seine Vorteile primär aus dem generativen Evolutionmechanismus stammen und nicht aus einfacher zufälliger Suche oder mehr Suchiterationen. Gleichzeitig hält EvoGM bei steigender Zahl der an der Fusion beteiligten Expertenmodelle gute Leistung und zeigt eine stabile Verbesserungstendenz, was darauf hinweist, dass es größere und komplexere Fusionräume effektiv bewältigen kann, die komplementären Fähigkeiten verschiedener Expertenmodelle vollständig nutzt und gute Erweiterbarkeit besitzt.
VII. Von EvoGO zu EvoGM: die Erweiterung der generativen Evolution-Idee
Aus einer größeren Perspektive kann EvoGM als Erweiterung der EvoGO-Idee in der Fusion großer Modelle verstanden werden. EvoGO konzentriert sich darauf, wie evolutionäre Optimierung von manuell entworfenen Kreuzungs-, Mutations- und Perturbationsoperatoren zu einem automatischen Lernen neuer Lösungsgenerierungsweisen durch generative Modelle aus historischen Suchdaten übergehen kann. Mit anderen Worten: Evolutionäre Suche generiert nicht mehr nur „zufällig Kandidaten und filtert“, sondern beginnt zu lernen, „wie vielversprechendere Kandidaten generiert werden“.
EvoGM bringt diese Idee in den Kontext der Fusion großer Modelle. Hier sind Kandidaten nicht mehr numerische Variablen in allgemeinen Optimierungsproblemen, sondern eine Kombination von Fusionskoeffizienten; eine Bewertung ist nicht mehr einfache Zielfunktionsberechnung, sondern Konstruktion eines fusionierten Modells und Validierung seiner Leistung auf Downstream-Aufgaben. EvoGM formuliert Modellfusion daher als generatives Optimierungsproblem: Wie aus historischen Bewertungsergebnissen die Gesetze der Fähigkeitskombination zwischen Expertenmodellen gelernt werden und bessere Fusionkonfigurationen generiert werden.
Dies unterscheidet EvoGM deutlich von traditionellen suchbasierten Modellfusion-Methoden. Traditionelle Methoden verwenden Validierungsergebnisse typischerweise nur für Ranking und Filterung, während EvoGM Validierungsergebnisse weiter in Trainingssignale transformiert. Konfigurationen mit niedriger Leistung werden nicht einfach verworfen, sondern mit Konfigurationen mit hoher Leistung zu winner-loser-Paaren gebildet, um den Generator zu trainieren, die Evolutionrichtung von schlechten zu guten Konfigurationen zu lernen.
Von EvoGO zu EvoGM ist es im Wesentlichen der Übergang von „lernen, wie Kandidaten optimiert werden“ zu „Fusionstrategie großer Modelle in der Population autonom evolvieren lassen“. Dies befreit Modellfusion nicht nur von empirischen Regeln und zufälligen Perturbationen, sondern bietet auch eine neue Perspektive: Fähigkeiten großer Modelle können fusioniert werden, und die Fusionstrategie selbst kann kontinuierlich aus Populationsfeedback lernen.
VIII. Schlussfolgerung und Ausblick
Mit dem kontinuierlichen Wachstum von Expertenmodellen, LoRA-Modellen und Aufgabenmodellen im Open-Source-Ökosystem könnte die zentrale Frage der Zukunft nicht mehr „wie ein neues Modell trainiert wird“ lauten, sondern „wie Fähigkeiten vorhandener Modelle effizient kombiniert werden“. EvoGM bietet eine neue Antwort: Ohne die an der Fusion beteiligten großen Modelle erneut zu trainieren, nutzt es generatives evolutionäres Lernen, um begrenztes Validierungsfeedback zu verwerten und autonom Kandidatenpopulation-Konstruktion, Fusionplan-Generierung, Bewertungsselektion und Expertenbasis-Aktualisierung zu vollenden. Kurz gesagt: EvoGM bringt Modellfusion von „Koeffizienten nach Erfahrung anpassen“ zu „Fusionstrategie selbst lernen und evolvieren lassen“. Dies bedeutet auch, dass die Wiederverwendung von Fähigkeiten großer Modelle in eine neue Phase eintreten könnte: Statt für jede neue Aufgabe ein Modell erneut zu trainieren, können vorhandene Expertenmodelle durch Populationsentwicklung und autonome Fusion kontinuierlich Modelle kombinieren, die besser für neue Aufgaben geeignet sind.
Open-Source-Code / Community
📄 Paper: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 Upstream-Projekt (EvoX):
https://github.com/EMI-Group/evox 🌐 QQ-Gruppe: 297969717
