ICML 2026 | EvoGM:無需重新訓練,透過群體進化實現大模型自主合併

摘要
隨著大語言模型能力不斷提升,針對不同任務微調得到的專家模型也越來越多。如何在不重新訓練參與合併的大模型、不依賴額外大規模訓練資料的前提下,高效複用這些專家模型的能力,成為模型合併中的重要問題。現有方法通常依賴平均合併、手工縮放、參數裁剪或隨機搜尋,雖然能夠在一定程度上組合多個模型的能力,但難以從歷史評估中持續學習並改進合併策略。
針對這一問題,EvoX 團隊聯合鵬城實驗室提出生成式演化模型合併框架 EvoGM(Evolutionary Generative Merging),將合併係數搜尋轉化為可學習的生成式優化問題。EvoGM 把不同合併配置組織成候選種群,透過贏家—輸家配對、雙生成器訓練、循環一致性約束和演化專家基底更新,使種群在「生成—評估—選擇—再學習」的閉環中持續進化,並從有限驗證回饋中自主學習如何把低效能配置轉化為高效能配置。實驗結果表明,EvoGM 在已見任務和未見任務場景下均展現出更強的模型合併能力。
一、為什麼我們需要模型合併?
近年來,大語言模型的能力越來越強,但訓練和微調的成本也越來越高。一個自然的問題是:如果我們已經有了多個在不同任務上表現較好的專家模型,能不能不重新訓練這些大模型,而是把它們的能力組合起來,得到一個更強、更通用的新模型?
這正是模型合併要解決的問題。
模型合併的核心思想很直接:多個專家模型往往來自同一基礎模型,只是在不同資料或任務上進行了微調。因此,可以把每個專家模型相對於基礎模型的參數變化看作一種「能力方向」,再加權組合這些方向,建構新的合併模型。其優勢是無需重新訓練或微調參與合併的大模型,也不依賴額外大規模訓練資料,只需搜尋合適的合併係數。需要說明的是,EvoGM 訓練輕量級生成器來搜尋係數,但不更新專家大模型參數。
二、模型合併真正難在哪裡?
真正困難的地方在這裡:這些係數到底應該怎麼選?
模型合併看似只是對多個專家模型進行加權組合,但不同專家模型之間的能力關係並不簡單。有些任務方向可以互補,有些參數更新可能相互衝突;一組合併係數在某類任務上表現更好,也可能在另一類任務上帶來效能損失。因此,合併係數與最終模型效能之間並不是一個容易手工刻畫的線性關係。
傳統方法通常依賴平均合併、手工縮放、參數裁剪或稀疏化等啟發式規則。這些方法簡單有效,但也存在明顯侷限:它們往往是靜態的、經驗性的,很難根據不同任務的驗證回饋自適應調整。
後來,演化搜尋類方法被引入模型合併,把候選合併配置組織成種群,透過隨機擾動、適應度評估和選擇來尋找更優係數。這類方法比固定規則更靈活,但仍然存在一個關鍵問題:驗證結果通常只被用於排序和篩選,而沒有進一步轉化為可學習的搜尋經驗。換句話說,演算法知道「哪個候選模型更好」,卻沒有真正學習「較差的候選模型應該如何變得更好」。
這也是 EvoGM 希望解決的核心問題:模型合併不應只是讓候選群體不斷試錯和篩選,而應從歷史評估中學習改進方向,自主產生更有潛力的合併配置。
三、EvoGM:讓合併策略在群體進化中自主學習
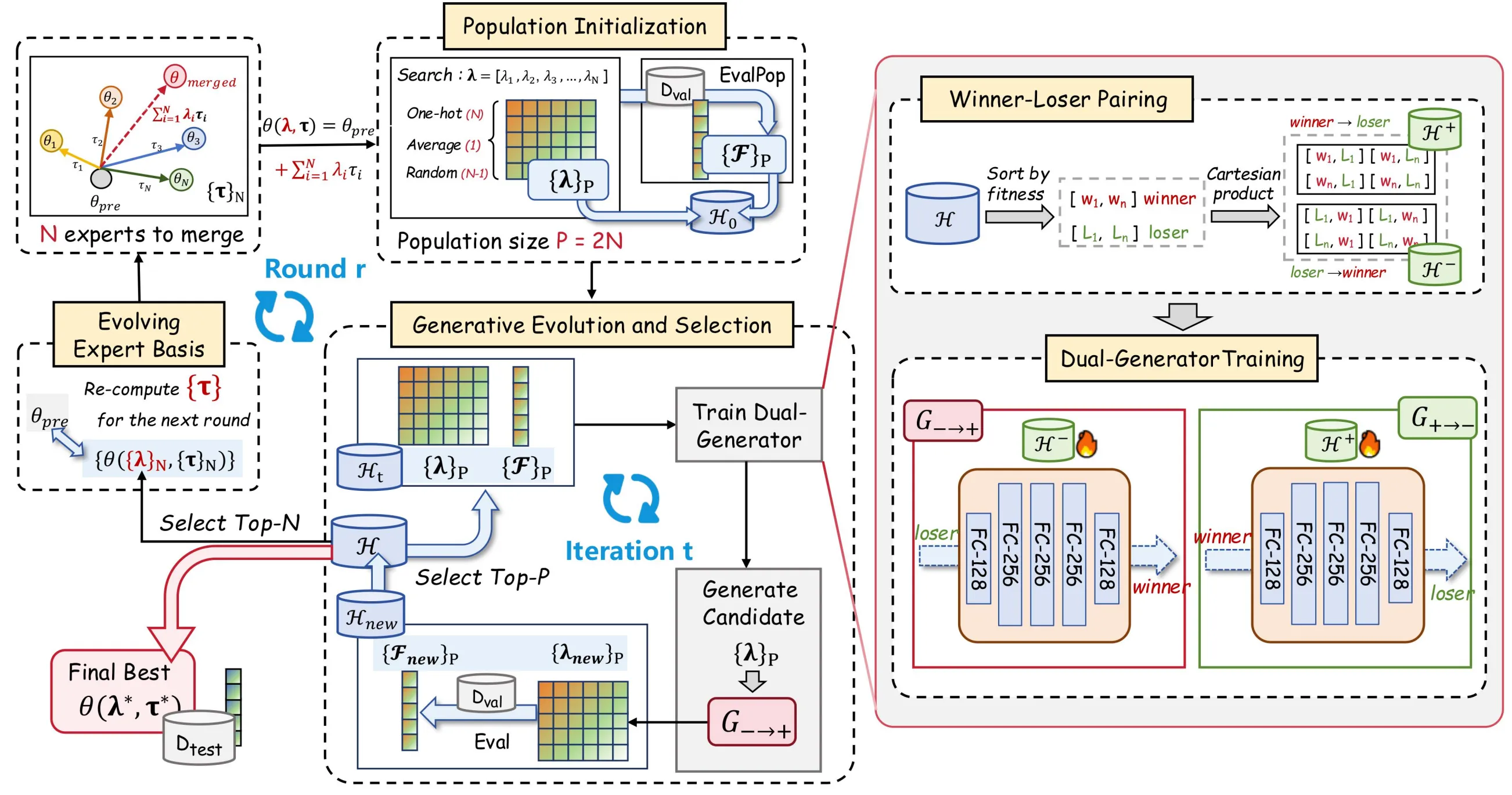
為解決上述問題,我們提出了 EvoGM(Evolutionary Generative Merging),程式碼已開源:https://github.com/JiangTao97/evogm。
EvoGM 的核心思想是:將候選合併配置組織為種群,並把合併係數的搜尋過程轉化為生成式學習問題。
關鍵在於,生成模型並不直接學習「最優合併係數是什麼」,而是學習「如何從較差配置變成較優配置」。這是因為在模型合併場景中,不同配置往往難以形成可靠的全域排序;相比之下,兩兩比較更容易獲得穩定的優劣訊號。
EvoGM 利用歷史驗證結果建構 winner-loser 配對資料,讓生成器學習從 loser 到 winner 的改進方向。對於每一對候選合併配置,演算法不僅記錄它們對應的效能差異,還將這種「由差變好」的關係轉化為訓練樣本。經過不斷累積和學習,生成器能夠逐漸捕捉哪些係數調整更可能帶來效能提升,從而形成對搜尋空間結構的隱式理解。換句話說,它學習的不是優秀解本身,而是效能提升的規律。
這一思路與演化優化中的競爭學習機制一脈相承。最早可以追溯到 CSO(Competitive Swarm Optimizer),其透過 winner-loser 競爭推動個體更新,讓表現較差的個體向表現更好的個體靠近;EvoGO(Evolutionary Generative Optimization)則進一步利用生成模型從歷史搜尋資料中學習改進方向,以資料驅動的方式替代部分人工設計的搜尋算子。EvoGM 將這一思想引入模型合併場景,透過驗證回饋訓練生成器,引導後續搜尋。這樣一來,驗證結果不僅用於篩選和淘汰候選解,而是被持續轉化為可複用的搜尋經驗,使搜尋過程能夠隨著迭代不斷累積知識、提高效率。
四、EvoGM 是如何運作的?
EvoGM 的整體流程可分為五步:建構候選方案、形成 winner-loser 訓練對、訓練生成器、生成並選擇新係數,以及更新專家基底。在給定專家模型與驗證任務後,這些步驟可以自動循環執行,無需人工逐輪設計合併規則或調節係數。
- 種群初始化:建構候選合併方案
EvoGM 首先需要建構一批初始候選解。這裡的每個候選解對應一組合併係數,也就是對多個專家模型的不同組合方式。
具體來說,初始種群通常包括幾類配置:平均合併對應的係數、單個專家模型對應的 one-hot 係數,以及隨機取樣得到的合併係數。這樣既能涵蓋一些常見的基準合併方式,也能為後續搜尋提供一定的多樣性。
對於每一組候選係數,EvoGM 都會據此建構一個合併模型,並在驗證集上評估其效能。經過這一步,演算法得到的不只是若干候選模型,而是一批「合併係數—驗證效能」的歷史記錄。後續所有生成式學習和演化選擇,都建立在這些記錄之上。
- 贏家—輸家配對:把驗證結果轉化為訓練資料
得到候選解及其驗證效能後,EvoGM 會根據表現將歷史候選配置劃分為 winner 和 loser。winner 表示相對更優的合併配置,loser 表示相對較差的合併配置。
這裡的關鍵不是簡單保留高分配置、丟棄低分配置,而是把兩者組成訓練對。對於生成器來說,一個 winner-loser pair 就提供了一條有用的資訊:從這個較差配置出發,應該向哪個更優配置靠近。
因此,低效能候選並不是無效樣本。相反,它們提供了搜尋過程中的「起點」,而高效能候選提供了「改進方向」。透過這種配對方式,EvoGM 能夠把有限的驗證評估結果轉化為更多可學習的監督訊號,提高小樣本回饋下的資料利用效率。
- 雙生成器訓練:學習從差配置到好配置的變換
在建構好 winner-loser 訓練對之後,EvoGM 使用雙生成器結構進行訓練。
其中,前向生成器負責學習從 loser 到 winner 的映射,也就是把低效能合併配置轉化為更有潛力的高效能配置。反向生成器則學習從 winner 回到 loser 的反向映射,用於約束生成過程的結構一致性。
這種設計的目的不是讓生成器簡單記住已有的高分配置,而是讓它學習合併係數空間中的改進規律。透過循環一致性約束,EvoGM 可以減少生成器坍縮到少數高分點的風險,使生成出的候選配置既朝向高效能區域,又盡量保留搜尋空間中的結構資訊。
- 生成式演化與選擇:用學出來的算子替代隨機擾動
生成器訓練完成後,EvoGM 會用前向生成器對當前候選配置進行變換,生成一批新的合併係數。這一步相當於傳統演化演算法中的「產生新個體」,但新個體不再主要來自隨機擾動,而是來自生成模型學到的改進方向。
隨後,這些新生成的合併係數會被用於建構新的合併模型,並再次在驗證集上進行評估。評估結果會被加入歷史記錄中,與已有候選一起參與選擇。
透過這樣的循環,EvoGM 每一輪都會經歷「生成—評估—選擇—再學習」的過程。這一閉環構成了候選合併方案的群體進化:歷史驗證結果不斷累積,生成器持續獲得新的訓練訊號,從而逐步提高自主生成高品質合併配置的能力。
- 演化專家基底:讓搜尋空間不斷自我更新
除了優化合併係數,EvoGM 還進一步引入了演化專家基底機制。
傳統模型合併通常把專家模型視為固定輸入,只在固定專家模型之間搜尋合併係數。EvoGM 則不同:每一輪結束後,表現最好的若干合併模型會被選出來,作為下一輪搜尋中的新專家基底。
這樣做的意義在於,優秀的合併模型本身已經包含了某些有效的能力組合。把它們納入新的專家基底後,後續搜尋不再侷限於原始專家模型之間的線性組合,而是可以在已經被驗證有效的中間模型基礎上繼續演化。
因此,EvoGM 的搜尋空間不是固定不變的,而是會隨著搜尋過程不斷更新。它不僅在尋找更好的合併係數,也在逐步建構更適合當前任務的專家表示基礎。
五、EvoGM 的關鍵優勢是什麼?
相比傳統模型合併方法,EvoGM 的優勢主要體現在三個方面。
首先,EvoGM 將模型合併從靜態啟發式規則推進到回饋驅動的自主搜尋。傳統方法往往依賴平均合併、手工縮放或隨機擾動,而 EvoGM 可以根據歷史驗證結果持續調整搜尋方向,使合併過程不再依賴人工逐輪設計規則和調節係數。
其次,EvoGM 提高了有限評估預算下的資料利用效率。在模型合併中,每一次候選配置評估都需要實際建構合併模型並執行驗證任務,成本並不低。EvoGM 將這些評估結果進一步轉化為可學習的訓練訊號,使每一次試錯都能為後續搜尋提供資訊。
最後,EvoGM 不只是尋找一組更好的合併係數,也在逐步學習專家模型之間的能力組合規律。透過候選種群的生成式搜尋與專家基底更新,它能夠在已有專家模型的基礎上不斷重組和擴展搜尋空間,從而更有效地自主發現高效能合併模型。
六、實驗結果:EvoGM 是否真的有效?
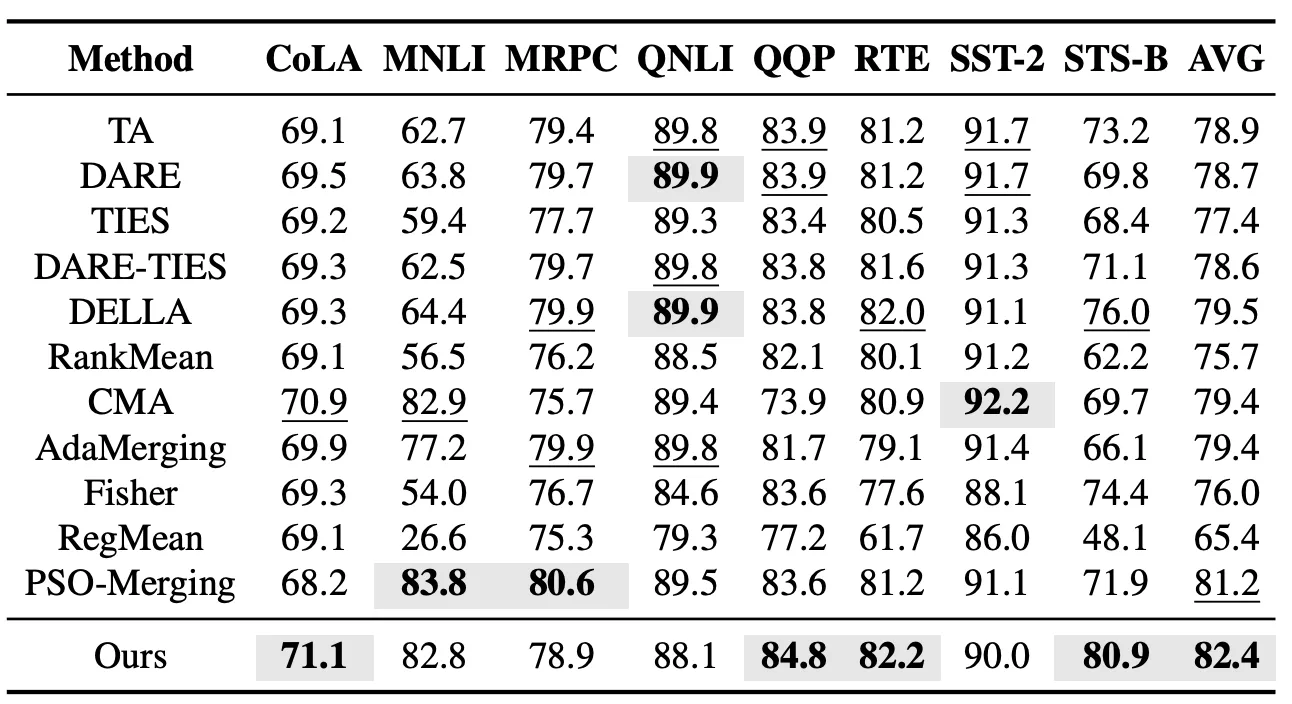
在已見任務設定中,我們首先在 GLUE 系列任務上評估 EvoGM 的模型合併效果。該實驗涵蓋 CoLA、MNLI、MRPC、QNLI、QQP、RTE、SST-2 和 STS-B 等 8 個語言理解任務,並與 Task Arithmetic、TIES、DARE-TIES、DELLA、RankMean、CMA、AdaMerging 和 PSO-Merging 等代表性模型合併方法進行比較。實驗結果顯示,EvoGM 在 8 個任務上的平均效能超過此前表現最好的 PSO-Merging。
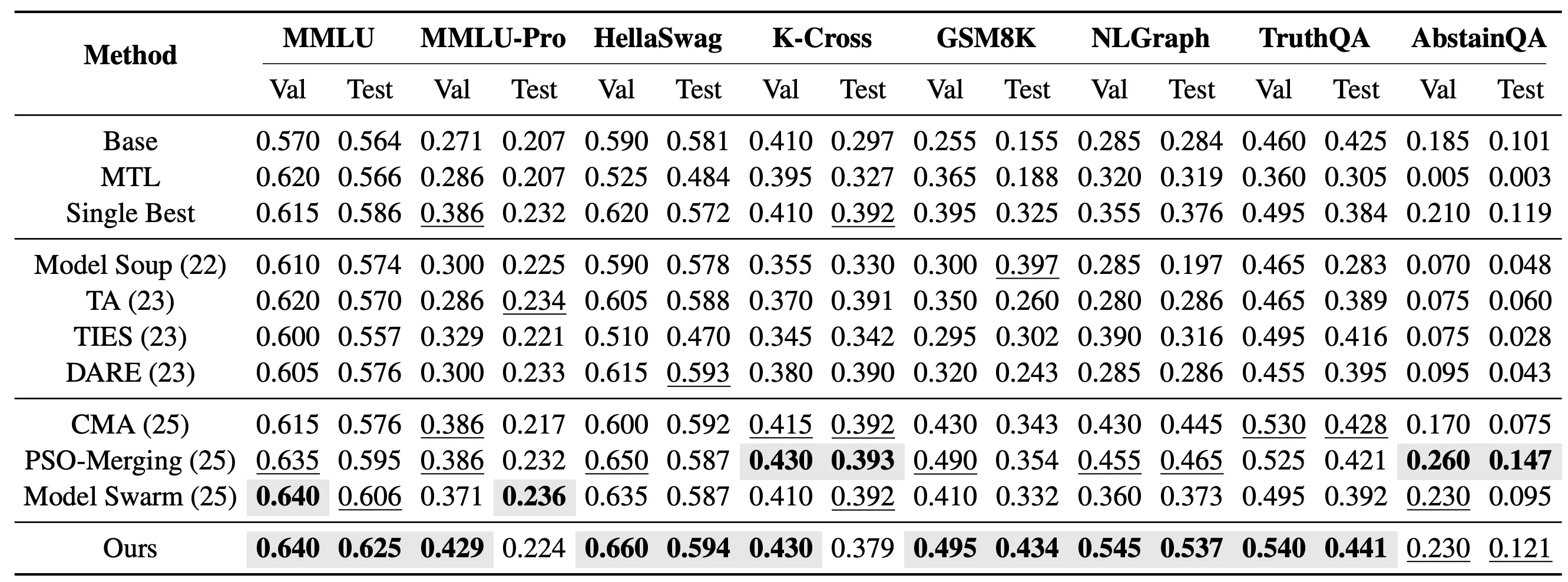
在更具挑戰性的未見任務設定中,我們進一步評估 EvoGM 是否能夠將已有專家模型的能力遷移到未參與專家微調的新任務上。具體來說,我們合併了 10 個基於 Qwen2.5-1.5B 的 LoRA 專家模型,並在 MMLU、MMLU-Pro、HellaSwag、Knowledge Crosswords、GSM8K、NLGraph、TruthfulQA 和 AbstainQA 等 8 個未見任務上進行測試。這些任務涵蓋知識理解、複雜推理和安全可靠性等不同能力維度,比已見任務更能反映模型合併方法的泛化能力。
在單任務未見合併設定中,EvoGM 會針對每個目標任務分別搜尋一組合併係數。實驗結果顯示,EvoGM 在 8 個測試任務中的 5 個任務上取得最高測試效能。
除了單任務合併,我們還進一步考察了多任務未見合併設定。在這一設定中,目標不再是為每個任務單獨尋找最優模型,而是得到一個能夠同時涵蓋 8 個未見任務的統一合併模型。實驗結果表明,在多任務未見合併中,EvoGM 在所有合併方法中取得最高平均測試效能。
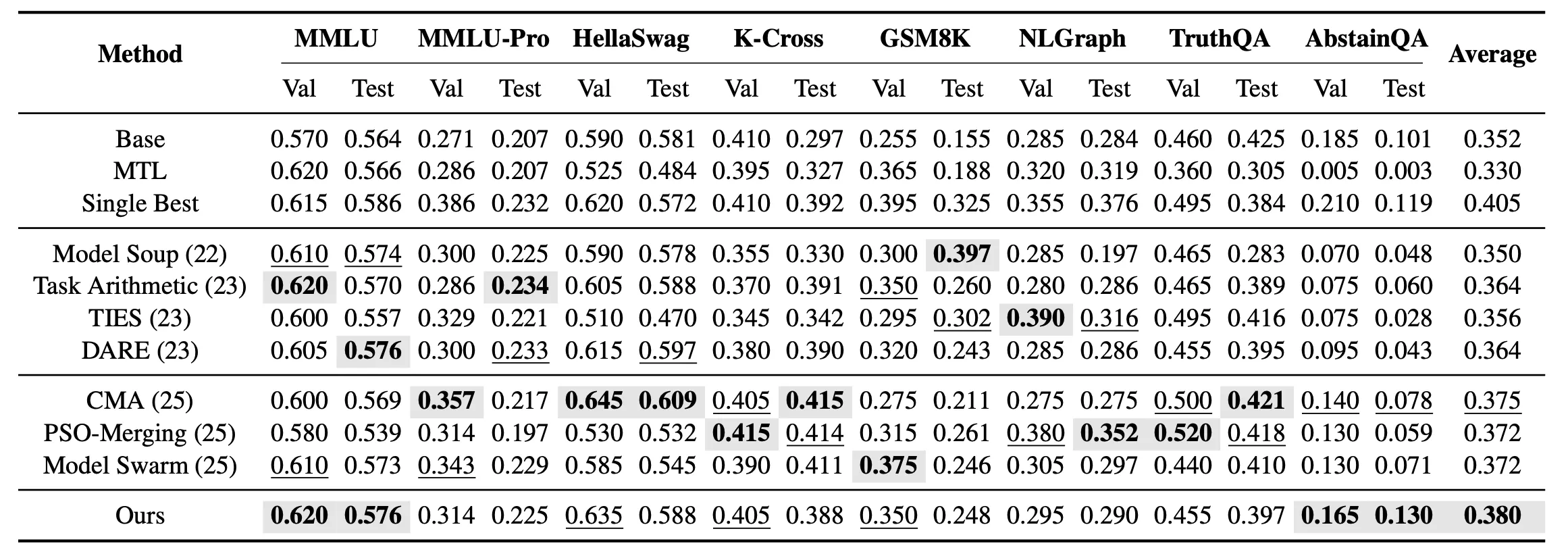
結果顯示,EvoGM 無論在單任務合併還是多任務設定中,均取得了更強的整體泛化表現,並在多個知識、推理和安全相關任務上優於現有模型合併方法。
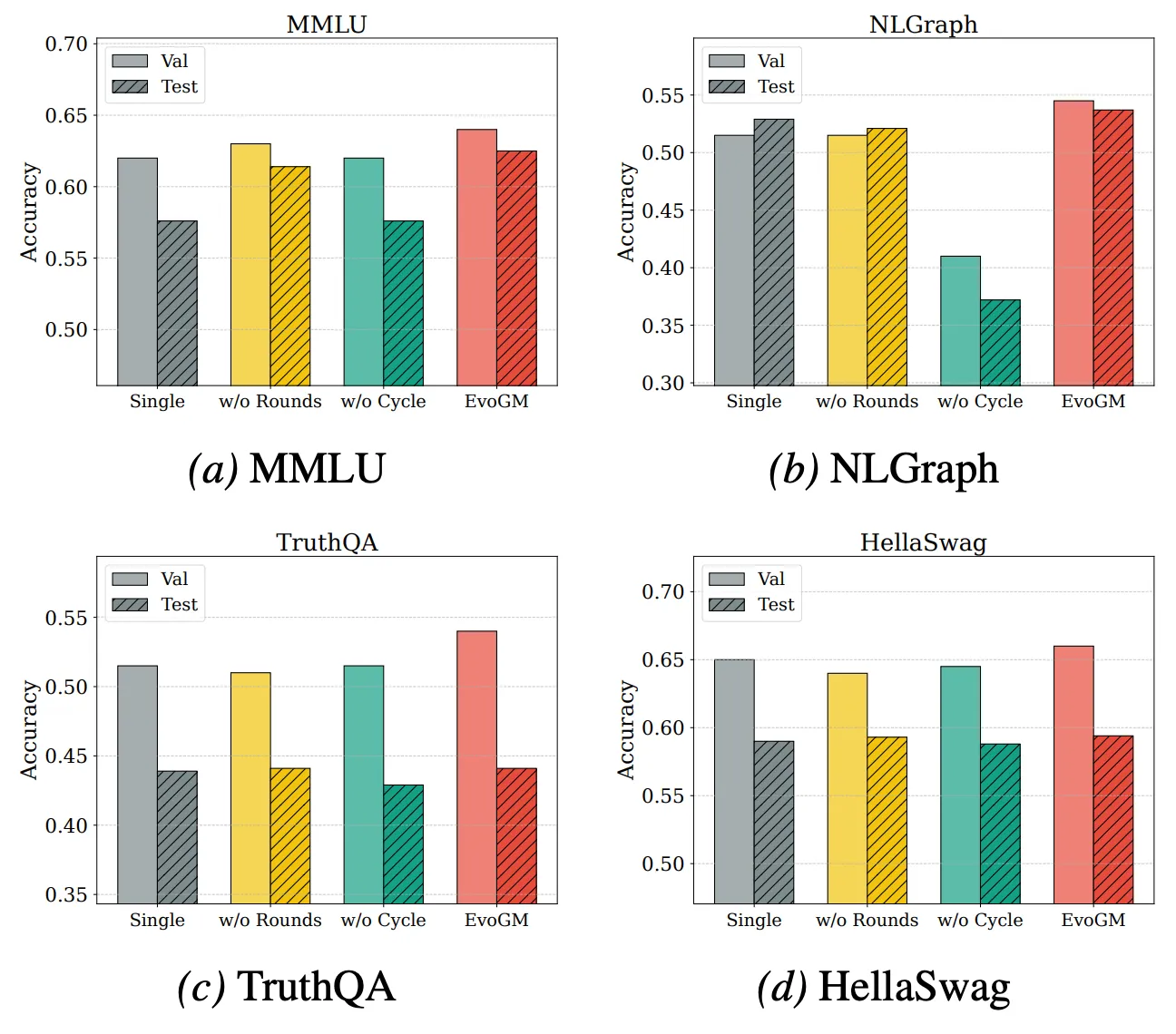
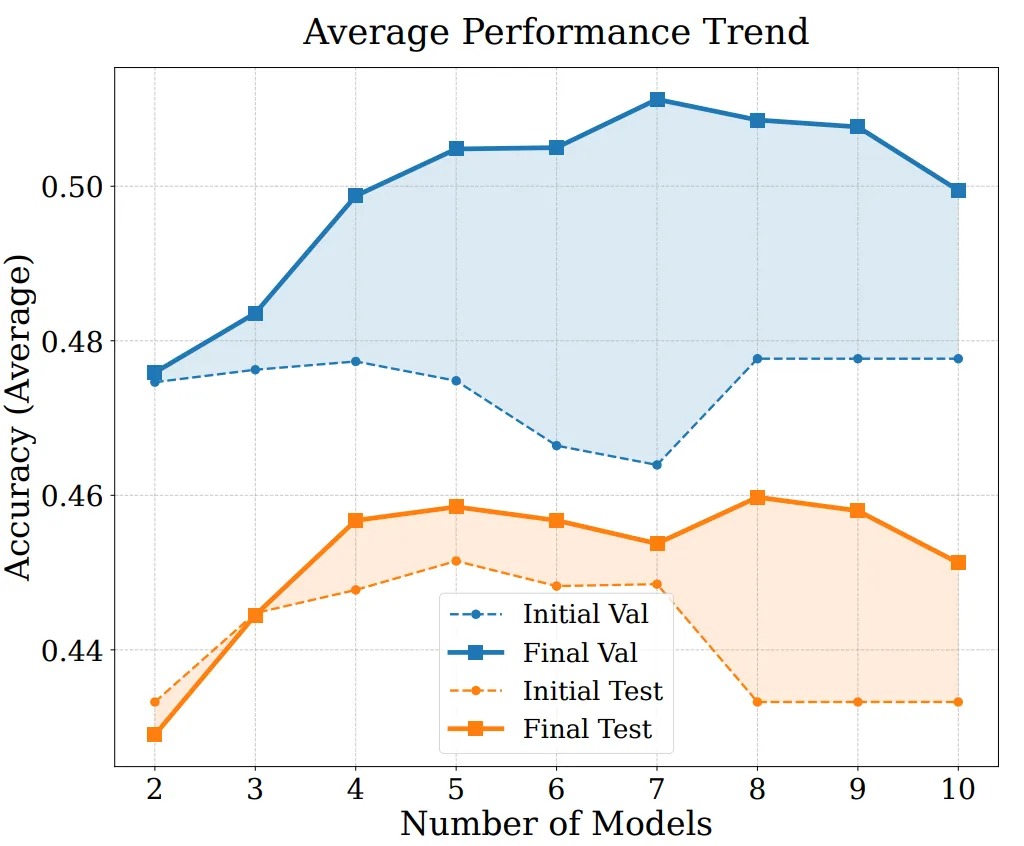
為了進一步分析 EvoGM 的效能來源及擴展能力,我們進行了消融實驗和不同模型數量下的合併實驗。結果表明,完整的 EvoGM 始終取得最優或最穩定的表現,移除關鍵元件後效能均出現不同程度下降,說明其優勢主要來自生成式演化機制,而非簡單的隨機搜尋或更多搜尋輪次。同時,在參與合併的專家模型數量增加時,EvoGM 仍能保持良好效能,並展現出穩定的提升趨勢,表明其能夠有效應對更大規模、更複雜的合併空間,充分利用不同專家模型之間的互補能力,具有較好的擴展性。
七、從 EvoGO 到 EvoGM:生成式演化思想的延伸
從更大的視角看,EvoGM 可以被理解為 EvoGO 思想在大模型合併中的一次延伸。EvoGO 關注的是如何讓演化優化從依賴人工設計的交叉、變異和擾動算子,轉向由生成模型根據歷史搜尋資料自動學習新解生成方式。也就是說,演化搜尋不再只是「隨機產生候選解並篩選」,而是開始學習「如何產生更有潛力的候選解」。
EvoGM 將這一思想落到大模型合併場景中。在這裡,候選解不再是一般優化問題中的數值變數,而是一組合併係數;一次評估也不再是簡單計算目標函數,而是建構合併模型並在下游任務上驗證效能。因此,EvoGM 實際上把模型合併重新表述為一個生成式優化問題:如何從歷史評估結果中學習專家模型之間的能力組合規律,並生成更優的合併配置。
這一點使 EvoGM 與傳統搜尋式模型合併形成了明顯區別。傳統方法通常只把驗證結果用於排序和篩選,而 EvoGM 進一步把驗證結果轉化為訓練訊號。低效能配置並不會被簡單丟棄,而是與高效能配置組成 winner-loser pairs,用來訓練生成器學習從差配置到好配置的演化方向。
從 EvoGO 到 EvoGM,本質上是從「學習如何優化候選解」走向「讓大模型合併策略在群體中自主進化」。這不僅讓模型合併從經驗規則和隨機擾動中解放出來,也提供了一種新的思路:大模型能力可以被合併,而合併策略本身也可以從群體回饋中持續學習。
八、結論與展望
隨著開源生態中專家模型、LoRA 模型和任務模型越來越多,未來的關鍵問題可能不只是「如何訓練一個新模型」,而是「如何高效組合已有模型能力」。EvoGM 提供了一種新的答案:在不重新訓練參與合併的大模型的前提下,透過生成式演化學習利用有限驗證回饋,自主完成候選種群建構、合併方案生成、評估選擇和專家基底更新。簡單來說,EvoGM 讓模型合併從「憑經驗調係數」走向「讓合併策略自己學習和進化」。這也意味著,大模型能力複用可能進入一個新的階段:不是每遇到一個新任務都重新訓練一個模型,而是讓已有專家模型透過群體進化與自主合併,持續組合出更適合新任務的模型。
開源程式碼 / 社群
📄 論文: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 上游專案(EvoX):
https://github.com/EMI-Group/evox 🌐 QQ 交流群:297969717
