ICML 2026 | EvoGM: fusione autonoma di grandi modelli tramite evoluzione di popolazione, senza ri-addestramento

Sintesi
Con il continuo miglioramento delle capacità dei grandi modelli linguistici, aumenta anche il numero di modelli esperti ottenuti tramite fine-tuning su diverse attività. Come riutilizzare efficacemente le capacità di questi modelli esperti senza ri-addestrare i grandi modelli coinvolti nella fusione e senza dipendere da dati di addestramento su larga scala aggiuntivi è una questione centrale nella fusione di modelli. I metodi esistenti si basano generalmente su fusione per media, scaling manuale, pruning dei parametri o ricerca casuale. Sebbene consentano di combinare le capacità di più modelli a un certo livello, faticano a imparare continuamente dalle valutazioni storiche e a migliorare le strategie di fusione.
Per affrontare questo problema, il team EvoX in collaborazione con il Peng Cheng Laboratory propone EvoGM (Evolutionary Generative Merging), un framework di fusione evolutiva generativa che trasforma la ricerca dei coefficienti di fusione in un problema di ottimizzazione generativa apprendibile. EvoGM organizza diverse configurazioni di fusione in una popolazione di candidati e, attraverso il pairing winner-loser, l’addestramento con doppio generatore, i vincoli di coerenza ciclica e l’aggiornamento evolutivo della base di esperti, fa evolvere la popolazione in un ciclo chiuso di «generazione — valutazione — selezione — riapprendimento», imparando autonomamente da feedback di validazione limitati come trasformare configurazioni a bassa performance in configurazioni ad alta performance. I risultati sperimentali mostrano che EvoGM dimostra una capacità di fusione di modelli più forte negli scenari di attività viste e non viste.
I. Perché abbiamo bisogno della fusione di modelli?
Negli ultimi anni, le capacità dei grandi modelli linguistici sono sempre più elevate, ma anche i costi di addestramento e fine-tuning aumentano. Una domanda naturale è: se abbiamo già diversi modelli esperti che performano bene su attività diverse, possiamo combinare le loro capacità senza ri-addestrare questi grandi modelli, ottenendo un nuovo modello più potente e più generale?
È proprio questo il problema che la fusione di modelli cerca di risolvere.
L’idea centrale della fusione di modelli è semplice: diversi modelli esperti spesso derivano dallo stesso modello base, ma sono stati fine-tuned su dati o attività diverse. Pertanto, le variazioni di parametri di ciascun modello esperto rispetto al modello base possono essere considerate come «direzioni di capacità», che possono essere combinate ponderatamente per costruire un nuovo modello fusionato. Il vantaggio è che non è necessario ri-addestrare o fine-tune i grandi modelli coinvolti, né dipendere da dati di addestramento su larga scala aggiuntivi — è sufficiente cercare i coefficienti di fusione appropriati. Si precisa che EvoGM addestra generatori leggeri per cercare i coefficienti, ma non aggiorna i parametri dei grandi modelli esperti.
II. Dove si trova la vera difficoltà della fusione di modelli?
La vera difficoltà è qui: come scegliere questi coefficienti?
La fusione di modelli sembra essere solo una combinazione ponderata di diversi modelli esperti, ma le relazioni di capacità tra diversi modelli esperti non sono semplici. Alcune direzioni di attività possono complementarsi, mentre alcuni aggiornamenti di parametri possono entrare in conflitto; una combinazione di coefficienti di fusione può performare meglio su un tipo di attività, ma causare perdita di performance su un altro. La relazione tra i coefficienti di fusione e la performance finale del modello non è quindi una relazione lineare facile da caratterizzare manualmente.
I metodi tradizionali si basano generalmente su regole euristiche come fusione per media, scaling manuale, pruning dei parametri o sparsificazione. Questi metodi sono semplici ed efficaci, ma presentano limiti evidenti: sono spesso statici ed empirici, e faticano ad adattarsi in base al feedback di validazione di diverse attività.
Successivamente, metodi di ricerca evolutiva sono stati introdotti nella fusione di modelli, organizzando le configurazioni candidate in popolazioni e cercando coefficienti migliori tramite perturbazione casuale, valutazione della fitness e selezione. Questi metodi sono più flessibili delle regole fisse, ma un problema chiave persiste: i risultati di validazione vengono generalmente utilizzati solo per il ranking e il filtraggio, senza essere ulteriormente trasformati in esperienza di ricerca apprendibile. In altre parole, l’algoritmo sa «qual candidato è migliore», ma non impara veramente «come un candidato con performance inferiore dovrebbe migliorare».
Questo è il problema centrale che EvoGM cerca di risolvere: la fusione di modelli non dovrebbe limitarsi a far provare e filtrare continuamente una popolazione di candidati, ma dovrebbe imparare direzioni di miglioramento dalle valutazioni storiche e generare autonomamente configurazioni di fusione più promettenti.
III. EvoGM: far apprendere la strategia di fusione nell’evoluzione di popolazione
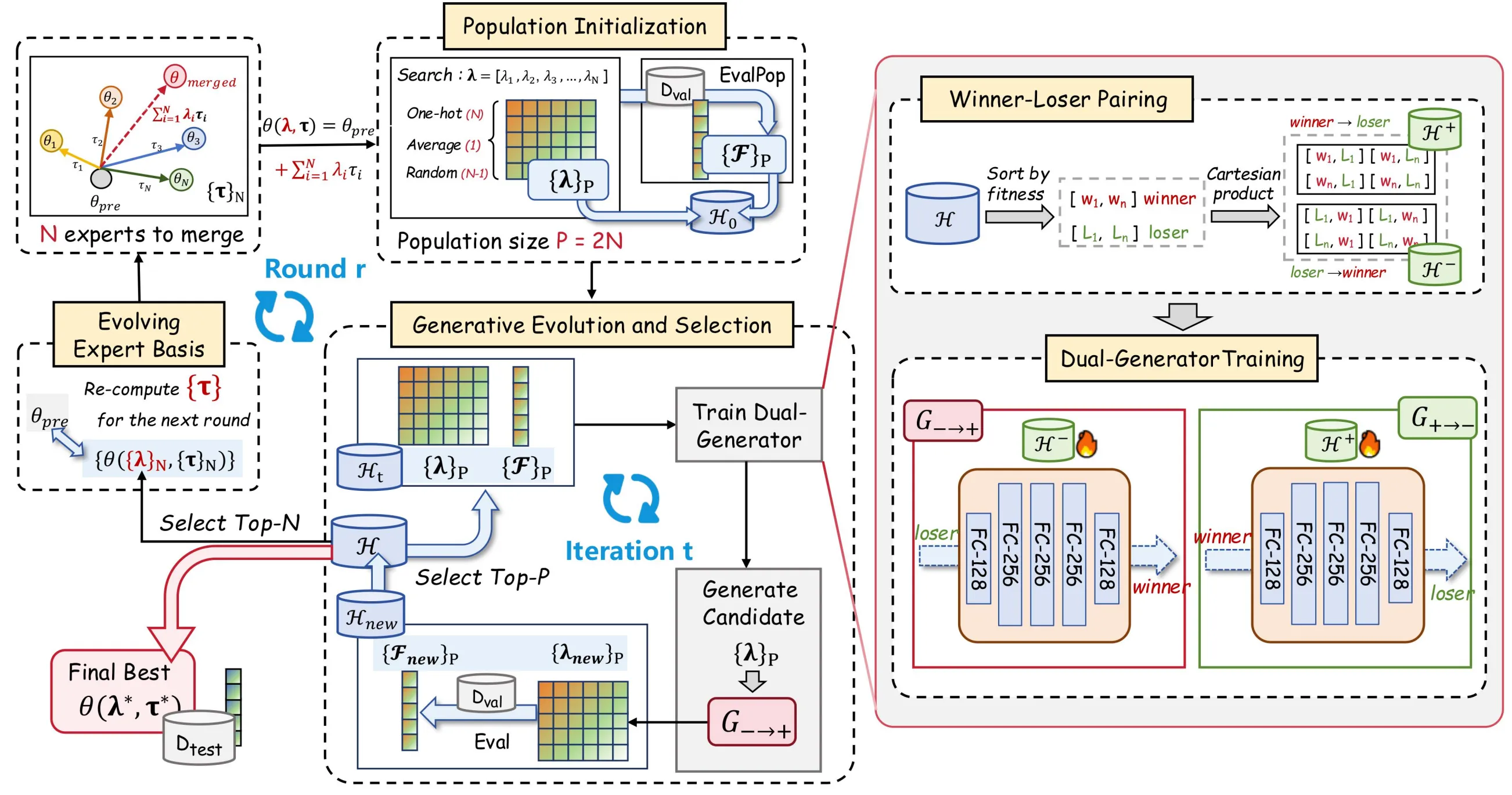
Per risolvere i problemi sopra descritti, proponiamo EvoGM (Evolutionary Generative Merging), il cui codice è open source: https://github.com/JiangTao97/evogm.
L’idea centrale di EvoGM è organizzare le configurazioni candidate di fusione in una popolazione e trasformare il processo di ricerca dei coefficienti di fusione in un problema di apprendimento generativo.
Il punto chiave è che il modello generativo non impara direttamente «quali sono i coefficienti di fusione ottimali», ma «come trasformare una configurazione con performance inferiore in una configurazione con performance superiore». Questo perché nel contesto della fusione di modelli è difficile stabilire un ranking globale affidabile tra diverse configurazioni; al contrario, i confronti a coppie forniscono segnali di superiorità più stabili.
EvoGM utilizza i risultati di validazione storici per costruire dati di pairing winner-loser, permettendo al generatore di imparare la direzione di miglioramento dal loser al winner. Per ogni coppia di configurazioni candidate di fusione, l’algoritmo non solo registra le differenze di performance, ma trasforma anche questa relazione «da cattivo a buono» in campioni di addestramento. Attraverso l’accumulo e l’apprendimento continui, il generatore può gradualmente cogliere quali aggiustamenti dei coefficienti sono più probabili di portare a un miglioramento della performance, formando così una comprensione implicita della struttura dello spazio di ricerca. In altre parole, impara non le soluzioni eccellenti in sé, ma le leggi del miglioramento della performance.
Questo approccio è in continuità con i meccanismi di apprendimento competitivo nell’ottimizzazione evolutiva. Risale al CSO (Competitive Swarm Optimizer), che spinge gli individui ad aggiornarsi attraverso la competizione winner-loser, facendo avvicinare gli individui con performance inferiore a quelli con performance superiore; EvoGO (Evolutionary Generative Optimization) utilizza ulteriormente i modelli generativi per imparare le direzioni di miglioramento dai dati di ricerca storici, sostituendo in modo data-driven parte degli operatori di ricerca progettati manualmente. EvoGM introduce questa idea nel contesto della fusione di modelli, addestrando il generatore tramite feedback di validazione per guidare la ricerca successiva. In questo modo, i risultati di validazione non servono solo a filtrare ed eliminare i candidati, ma vengono continuamente trasformati in esperienza di ricerca riutilizzabile, permettendo al processo di ricerca di accumulare conoscenza e migliorare l’efficienza con le iterazioni.
IV. Come funziona EvoGM?
Il processo complessivo di EvoGM può essere suddiviso in cinque fasi: costruzione dei candidati, formazione delle coppie di addestramento winner-loser, addestramento del generatore, generazione e selezione di nuovi coefficienti, e aggiornamento della base di esperti. Una volta definiti i modelli esperti e le attività di validazione, queste fasi possono essere eseguite automaticamente in ciclo, senza intervento manuale per progettare le regole di fusione o regolare i coefficienti in ogni iterazione.
- Inizializzazione della popolazione: costruzione dei candidati di fusione
EvoGM inizia costruendo un insieme di candidati iniziali. Ogni candidato corrisponde a una combinazione di coefficienti di fusione, ovvero un modo diverso di combinare diversi modelli esperti.
In concreto, la popolazione iniziale include generalmente diversi tipi di configurazioni: i coefficienti corrispondenti alla fusione per media, i coefficienti one-hot corrispondenti a un singolo modello esperto, e i coefficienti di fusione ottenuti tramite campionamento casuale. Questo permette di coprire alcuni metodi di fusione di riferimento comuni e offrire sufficiente diversità per la ricerca successiva.
Per ogni combinazione di coefficienti candidati, EvoGM costruisce un modello fusionato e valuta la sua performance sul set di validazione. Dopo questo passaggio, l’algoritmo ottiene non solo diversi modelli candidati, ma anche una serie di record storici «coefficienti di fusione — performance di validazione». Tutto l’apprendimento generativo e la selezione evolutiva successivi si basano su questi record.
- Pairing winner-loser: trasformare i risultati di validazione in dati di addestramento
Dopo aver ottenuto i candidati e le loro performance di validazione, EvoGM divide le configurazioni candidate storiche in winner e loser in base alla performance. Il winner rappresenta una configurazione di fusione relativamente migliore, il loser una configurazione relativamente con performance inferiore.
Il punto chiave qui non è semplicemente conservare le configurazioni con punteggio alto e scartare quelle con punteggio basso, ma formarle in coppie di addestramento. Per il generatore, una coppia winner-loser fornisce un’informazione utile: da questa configurazione con performance inferiore, verso quale configurazione con performance superiore dovrebbe avvicinarsi?
Pertanto, i candidati con performance inferiore non sono campioni invalidi. Forniscono invece il «punto di partenza» del processo di ricerca, mentre i candidati con performance elevata forniscono la «direzione di miglioramento». Con questo modo di pairing, EvoGM può trasformare i risultati limitati di valutazione di validazione in più segnali di supervisione apprendibili, migliorando l’efficienza di utilizzo dei dati con feedback a campione ridotto.
- Addestramento con doppio generatore: imparare la trasformazione da configurazioni scarse a configurazioni buone
Dopo la costruzione delle coppie di addestramento winner-loser, EvoGM utilizza una struttura di doppio generatore per l’addestramento.
Il generatore forward impara il mapping dal loser al winner, ovvero la trasformazione di una configurazione di fusione a bassa performance in una configurazione ad alta performance più promettente. Il generatore backward impara il mapping inverso dal winner al loser, servendo a vincolare la coerenza strutturale del processo di generazione.
Questo design non mira a far memorizzare al generatore le configurazioni con punteggio alto esistenti, ma a fargli imparare le leggi di miglioramento nello spazio dei coefficienti di fusione. Attraverso i vincoli di coerenza ciclica, EvoGM può ridurre il rischio che il generatore collassi su pochi punti con punteggio alto, permettendo alle configurazioni candidate generate di orientarsi verso le regioni ad alta performance pur conservando il più possibile le informazioni strutturali dello spazio di ricerca.
- Evoluzione generativa e selezione: sostituire la perturbazione casuale con operatori appresi
Una volta completato l’addestramento del generatore, EvoGM utilizza il generatore forward per trasformare le configurazioni candidate attuali e generare un nuovo insieme di coefficienti di fusione. Questo passaggio corrisponde alla «produzione di nuovi individui» negli algoritmi evolutivi tradizionali, ma i nuovi individui non provengono principalmente da perturbazioni casuali, bensì dalle direzioni di miglioramento apprese dal modello generativo.
Successivamente, questi nuovi coefficienti di fusione generati vengono utilizzati per costruire nuovi modelli fusionati e vengono rivalutati sul set di validazione. I risultati di valutazione vengono aggiunti ai record storici e partecipano alla selezione insieme ai candidati esistenti.
Attraverso questo ciclo, EvoGM in ogni iterazione attraversa un processo di «generazione — valutazione — selezione — riapprendimento». Questo ciclo chiuso costituisce l’evoluzione di popolazione dei candidati di fusione: i risultati di validazione storici si accumulano continuamente, il generatore riceve nuovi segnali di addestramento, migliorando gradualmente la capacità di generare autonomamente configurazioni di fusione di alta qualità.
- Base di esperti evolutiva: aggiornare continuamente lo spazio di ricerca
Oltre all’ottimizzazione dei coefficienti di fusione, EvoGM introduce ulteriormente un meccanismo di base di esperti evolutiva.
La fusione di modelli tradizionale considera generalmente i modelli esperti come input fissi, cercando solo i coefficienti di fusione tra modelli esperti fissi. EvoGM è diverso: dopo ogni iterazione, i modelli fusionati con le migliori performance vengono selezionati per servire come nuova base di esperti nella ricerca dell’iterazione successiva.
Il significato di questo approccio è che i modelli fusionati eccellenti già contengono alcune combinazioni di capacità efficaci. Una volta inclusi nella nuova base di esperti, la ricerca successiva non è più limitata a combinazioni lineari tra i modelli esperti originali, ma può continuare a evolvere su modelli intermedi già validati come efficaci.
Pertanto, lo spazio di ricerca di EvoGM non è fisso, ma si aggiorna continuamente con il processo di ricerca. Non cerca solo coefficienti di fusione migliori, ma costruisce gradualmente una base di rappresentazione degli esperti più adatta all’attività attuale.
V. Quali sono i vantaggi chiave di EvoGM?
Rispetto ai metodi tradizionali di fusione di modelli, i vantaggi di EvoGM si manifestano principalmente in tre aspetti.
In primo luogo, EvoGM spinge la fusione di modelli da regole euristiche statiche a ricerca autonoma guidata dal feedback. I metodi tradizionali si basano spesso su fusione per media, scaling manuale o perturbazione casuale, mentre EvoGM può regolare continuamente la direzione di ricerca in base ai risultati di validazione storici, rendendo il processo di fusione indipendente dalla progettazione manuale delle regole e dalla regolazione dei coefficienti in ogni iterazione.
In secondo luogo, EvoGM migliora l’efficienza di utilizzo dei dati con budget di valutazione limitato. Nella fusione di modelli, ogni valutazione di una configurazione candidata richiede la costruzione effettiva di un modello fusionato e l’esecuzione delle attività di validazione, con un costo non trascurabile. EvoGM trasforma ulteriormente questi risultati di valutazione in segnali di addestramento apprendibili, permettendo a ogni tentativo di fornire informazioni per la ricerca successiva.
Infine, EvoGM non cerca solo una migliore combinazione di coefficienti di fusione, ma impara gradualmente le leggi di combinazione delle capacità tra modelli esperti. Attraverso la ricerca generativa della popolazione di candidati e l’aggiornamento della base di esperti, può continuamente ricombinare ed estendere lo spazio di ricerca sulla base dei modelli esperti esistenti, scoprendo più efficacemente modelli fusionati ad alta performance.
VI. Risultati sperimentali: EvoGM è davvero efficace?
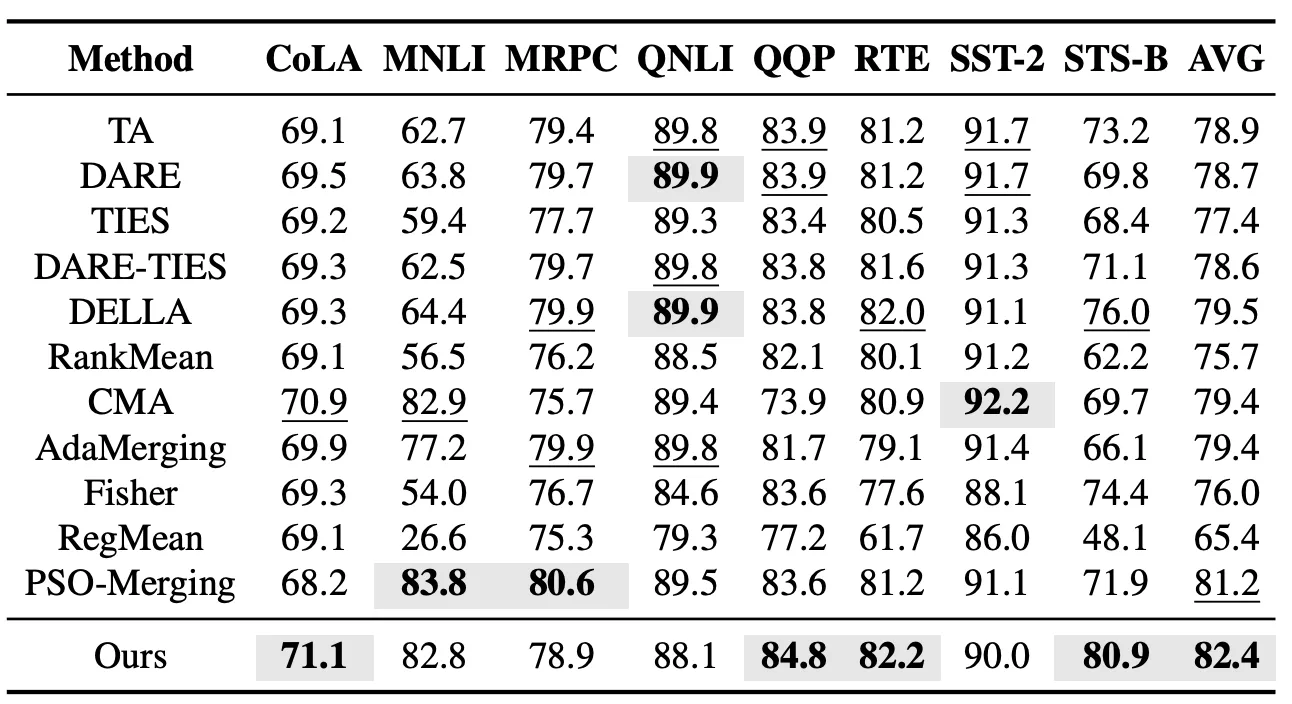
Nel setting con attività viste, valutiamo innanzitutto l’effetto di fusione di modelli di EvoGM sulle attività della serie GLUE. Questo esperimento copre 8 attività di comprensione del linguaggio: CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2 e STS-B, e confronta EvoGM con metodi rappresentativi di fusione di modelli come Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging e PSO-Merging. I risultati mostrano che EvoGM supera il PSO-Merging, precedentemente il migliore, in performance media su tutte le 8 attività.
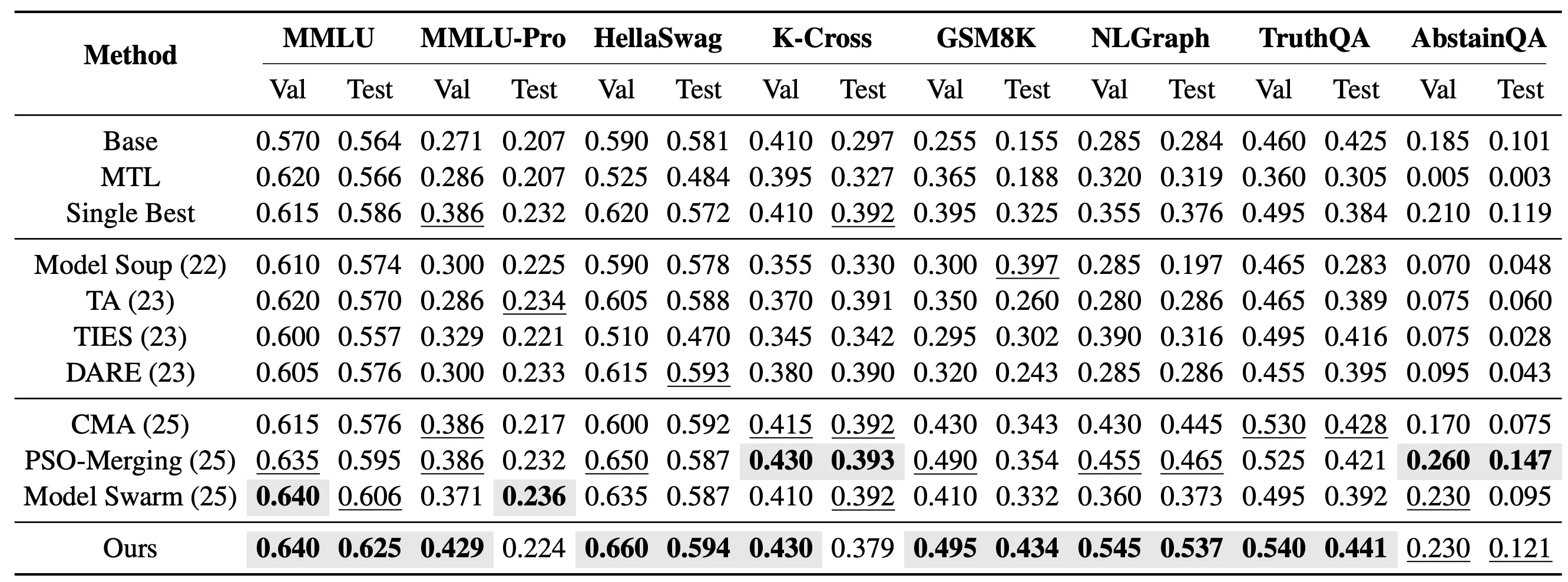
Nel setting più impegnativo con attività non viste, valutiamo ulteriormente se EvoGM può trasferire le capacità dei modelli esperti esistenti a nuove attività che non hanno partecipato al fine-tuning degli esperti. In concreto, fusioniamo 10 modelli esperti LoRA basati su Qwen2.5-1.5B e testiamo su 8 attività non viste: MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA e AbstainQA. Queste attività coprono diverse dimensioni di capacità come comprensione delle conoscenze, ragionamento complesso e affidabilità di sicurezza, riflettendo meglio delle attività viste la capacità di generalizzazione dei metodi di fusione di modelli.
Nel setting di fusione non vista mono-attività, EvoGM cerca rispettivamente una combinazione di coefficienti di fusione per ogni attività target. I risultati mostrano che EvoGM ottiene la performance di test più elevata su 5 delle 8 attività di test.
Oltre alla fusione mono-attività, esaminiamo ulteriormente il setting di fusione non vista multi-attività. In questo setting, l’obiettivo non è più trovare il modello ottimale per ogni attività singolarmente, ma ottenere un modello fusionato unificato capace di coprire simultaneamente le 8 attività non viste. I risultati sperimentali mostrano che nella fusione non vista multi-attività, EvoGM ottiene la performance di test media più elevata tra tutti i metodi di fusione.
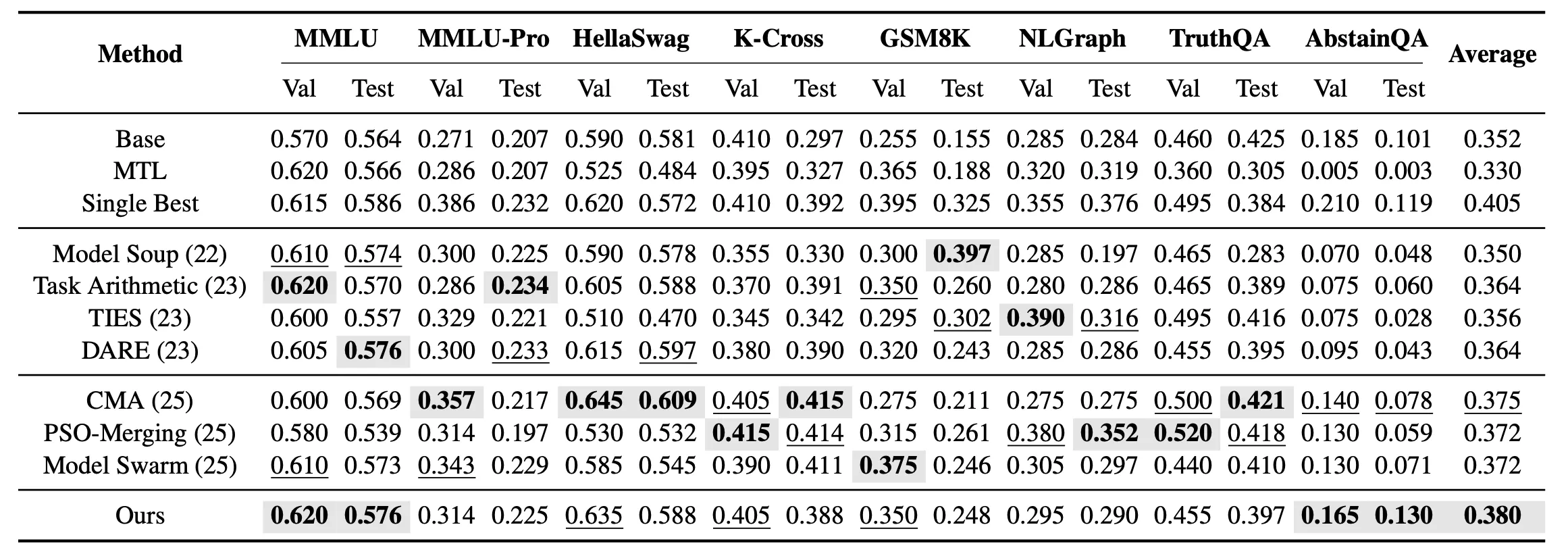
I risultati mostrano che EvoGM ottiene una performance di generalizzazione complessiva più forte nei setting di fusione mono-attività e multi-attività, superando i metodi esistenti di fusione di modelli in diverse attività legate a conoscenza, ragionamento e sicurezza.
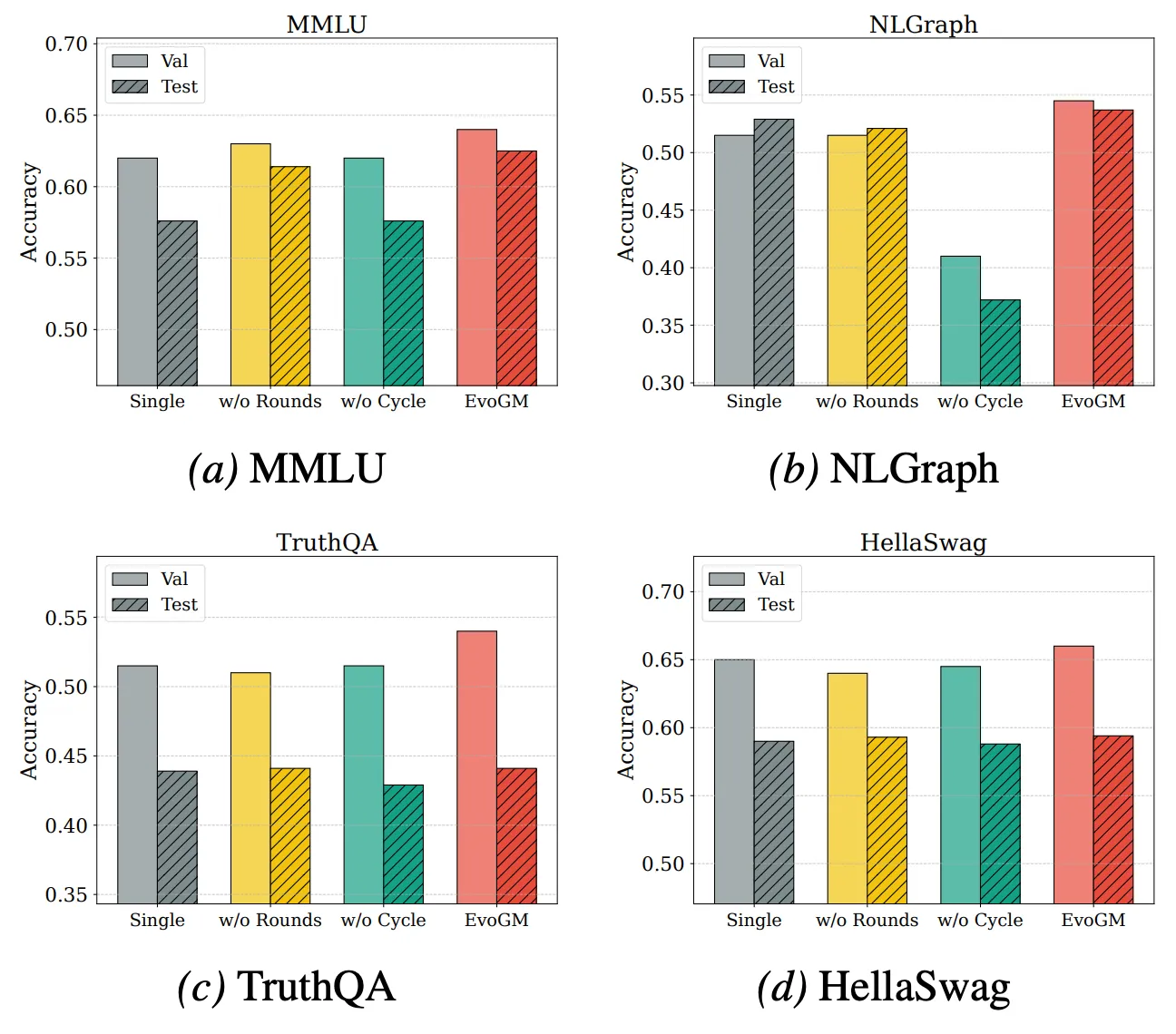
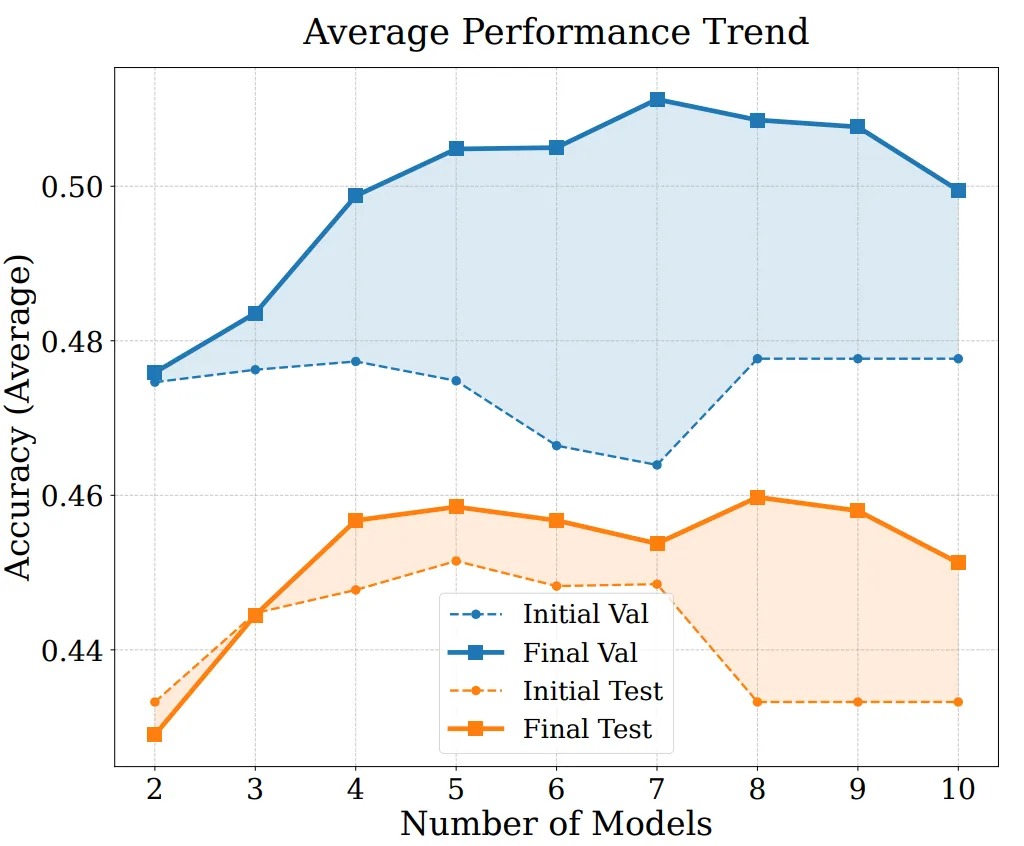
Per analizzare ulteriormente le fonti di performance e le capacità di estensione di EvoGM, abbiamo condotto esperimenti di ablazione e esperimenti di fusione con diversi numeri di modelli. I risultati mostrano che EvoGM completo ottiene sempre la performance ottimale o più stabile; dopo la rimozione dei componenti chiave, la performance diminuisce in diversi gradi, indicando che i suoi vantaggi derivano principalmente dal meccanismo di evoluzione generativa, e non da una semplice ricerca casuale o da più iterazioni di ricerca. Allo stesso tempo, con l’aumento del numero di modelli esperti coinvolti nella fusione, EvoGM mantiene una buona performance e mostra una tendenza di miglioramento stabile, indicando che può gestire efficacemente spazi di fusione più grandi e più complessi, sfruttare pienamente le capacità complementari tra diversi modelli esperti, e possiede una buona estensibilità.
VII. Da EvoGO a EvoGM: l’estensione dell’idea di evoluzione generativa
Da una prospettiva più ampia, EvoGM può essere inteso come un’estensione dell’idea EvoGO nella fusione di grandi modelli. EvoGO si concentra su come far evolvere l’ottimizzazione evolutiva dagli operatori di crossover, mutazione e perturbazione progettati manualmente all’apprendimento automatico di nuovi modi di generare soluzioni da parte del modello generativo basato sui dati di ricerca storici. In altre parole, la ricerca evolutiva non si limita più a «generare candidati casualmente e filtrare», ma inizia a imparare «come generare candidati più promettenti».
EvoGM applica questa idea al contesto della fusione di grandi modelli. Qui, i candidati non sono più variabili numeriche in problemi di ottimizzazione generali, ma una combinazione di coefficienti di fusione; una valutazione non è più un semplice calcolo della funzione obiettivo, ma la costruzione di un modello fusionato e la validazione della sua performance su attività downstream. EvoGM riformula quindi la fusione di modelli come un problema di ottimizzazione generativa: come imparare dai risultati di valutazione storici le leggi di combinazione delle capacità tra modelli esperti e generare configurazioni di fusione migliori.
Questo distingue chiaramente EvoGM dai metodi tradizionali di fusione di modelli basati sulla ricerca. I metodi tradizionali utilizzano generalmente i risultati di validazione solo per il ranking e il filtraggio, mentre EvoGM trasforma ulteriormente i risultati di validazione in segnali di addestramento. Le configurazioni a bassa performance non vengono semplicemente scartate, ma formate in coppie winner-loser con le configurazioni ad alta performance per addestrare il generatore a imparare la direzione di evoluzione da configurazioni scarse a configurazioni buone.
Da EvoGO a EvoGM, si tratta essenzialmente del passaggio da «imparare come ottimizzare i candidati» a «far evolvere autonomamente la strategia di fusione di grandi modelli nella popolazione». Questo libera non solo la fusione di modelli da regole empiriche e perturbazioni casuali, ma offre anche una nuova prospettiva: le capacità dei grandi modelli possono essere fuse, e la strategia di fusione stessa può continuare a imparare dal feedback della popolazione.
VIII. Conclusioni e prospettive
Con il continuo aumento di modelli esperti, modelli LoRA e modelli per attività nell’ecosistema open source, la questione chiave del futuro potrebbe non essere più «come addestrare un nuovo modello», ma «come combinare efficacemente le capacità dei modelli esistenti». EvoGM offre una nuova risposta: senza ri-addestrare i grandi modelli coinvolti nella fusione, utilizza l’apprendimento evolutivo generativo per sfruttare feedback di validazione limitati e completare autonomamente la costruzione della popolazione di candidati, la generazione dei piani di fusione, la selezione per valutazione e l’aggiornamento della base di esperti. In breve, EvoGM fa evolvere la fusione di modelli da «regolare i coefficienti per esperienza» a «far apprendere ed evolvere la strategia di fusione stessa». Ciò significa anche che il riutilizzo delle capacità dei grandi modelli potrebbe entrare in una nuova fase: anziché ri-addestrare un modello per ogni nuova attività, i modelli esperti esistenti possono, attraverso l’evoluzione di popolazione e la fusione autonoma, continuare a combinare modelli più adatti alle nuove attività.
Codice open source / Community
📄 Paper: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 Progetto upstream (EvoX):
https://github.com/EMI-Group/evox 🌐 Gruppo QQ: 297969717
