ICML 2026 | EvoGM: fusão autónoma de modelos de grande escala através de evolução populacional sem reentrenamento

Resumo
À medida que as capacidades dos modelos de linguagem de grande escala continuam a melhorar, também aumenta o número de modelos especialistas ajustados para tarefas específicas. Como reutilizar eficientemente as capacidades destes modelos especialistas sem reentrenar os modelos de grande escala participantes na fusão nem depender de dados de treino adicionais em grande escala tornou-se um problema central na fusão de modelos. Os métodos existentes costumam depender da fusão por média, escalamento manual, recorte de parâmetros ou pesquisa aleatória. Embora consigam combinar as capacidades de vários modelos até certo ponto, têm dificuldade em aprender continuamente a partir de avaliações históricas e melhorar a estratégia de fusão.
Para abordar este problema, a equipa EvoX, em colaboração com o Laboratório Peng Cheng, apresenta o EvoGM (Evolutionary Generative Merging), um framework de fusão evolutiva generativa de modelos que transforma a pesquisa de coeficientes de fusão num problema de optimização generativa aprendível. O EvoGM organiza diferentes configurações de fusão numa população de candidatos e, através de emparelhamento winner-loser, treino de duplo gerador, restrições de consistência cíclica e actualização evolutiva da base de especialistas, faz com que a população evolua continuamente num ciclo fechado de «gerar—avaliar—seleccionar—reaprender», aprendendo de forma autónoma a partir de feedback limitado de validação como transformar configurações de baixo desempenho em configurações de alto desempenho. Os resultados experimentais mostram que o EvoGM exibe uma capacidade de fusão de modelos superior tanto em cenários de tarefas vistas como não vistas.
I. Porque precisamos da fusão de modelos?
Nos últimos anos, as capacidades dos modelos de linguagem de grande escala têm vindo a aumentar, mas também o custo do treino e do ajuste fino. Surge uma questão natural: se já dispomos de vários modelos especialistas que funcionam bem em tarefas distintas, será possível combinar as suas capacidades para obter um novo modelo mais forte e mais generalista, sem reentrenar estes modelos de grande escala?
É precisamente isto que a fusão de modelos pretende resolver.
A ideia central da fusão de modelos é directa: múltiplos modelos especialistas provêm normalmente do mesmo modelo base, tendo sido ajustados apenas em dados ou tarefas diferentes. Assim, pode considerar-se a alteração de parâmetros de cada modelo especialista relativamente ao modelo base como uma «direcção de capacidade», combinando ponderadamente estas direcções para construir um novo modelo fundido. A sua vantagem é que não requer reentrenar nem ajustar finamente os modelos de grande escala participantes na fusão, nem depender de dados de treino adicionais em grande escala; basta pesquisar os coeficientes de fusão adequados. Convém salientar que o EvoGM treina geradores ligeiros para pesquisar coeficientes, mas não actualiza os parâmetros dos modelos especialistas de grande escala.
II. Onde reside a verdadeira dificuldade da fusão de modelos?
A verdadeira dificuldade está aqui: como devem estes coeficientes ser escolhidos?
A fusão de modelos parece ser apenas uma combinação ponderada de vários modelos especialistas, mas as relações de capacidade entre diferentes modelos especialistas não são simples. Algumas direcções de tarefa podem complementar-se, enquanto certas actualizações de parâmetros podem entrar em conflito; um conjunto de coeficientes de fusão pode funcionar melhor num tipo de tarefas e provocar perda de desempenho noutro. Por conseguinte, a relação entre os coeficientes de fusão e o desempenho final do modelo não é uma relação linear de fácil caracterização manual.
Os métodos tradicionais costumam depender de regras heurísticas como a fusão por média, o escalamento manual, o recorte de parámetros ou a esparsificação. Estes métodos são simples e eficazes, mas apresentam limitações evidentes: tendem a ser estáticos e empíricos, e têm dificuldade em ajustar-se de forma adaptativa com base no feedback de validação de diferentes tarefas.
Posteriormente, foram introduzidos métodos de pesquisa evolutiva na fusão de modelos, organizando configurações candidatas de fusão numa população e procurando melhores coeficientes através de perturbação aleatória, avaliação de aptidão e selecção. Estes métodos são mais flexíveis do que regras fixas, mas continuam a ter um problema chave: os resultados de validação são normalmente utilizados apenas para ordenar e filtrar, sem se converterem em experiência de pesquisa aprendível. Por outras palavras, o algoritmo sabe «qual candidato é melhor», mas não aprende verdadeiramente «como um candidato pior deveria melhorar».
Este é o problema central que o EvoGM pretende resolver: a fusão de modelos não deve limitar-se a fazer com que a população candidata teste e filtre continuamente, mas sim aprender a partir de avaliações históricas direcções de melhoria e gerar de forma autónoma configurações de fusão mais promissoras.
III. EvoGM: permitir que a estratégia de fusão aprenda de forma autónoma na evolução populacional
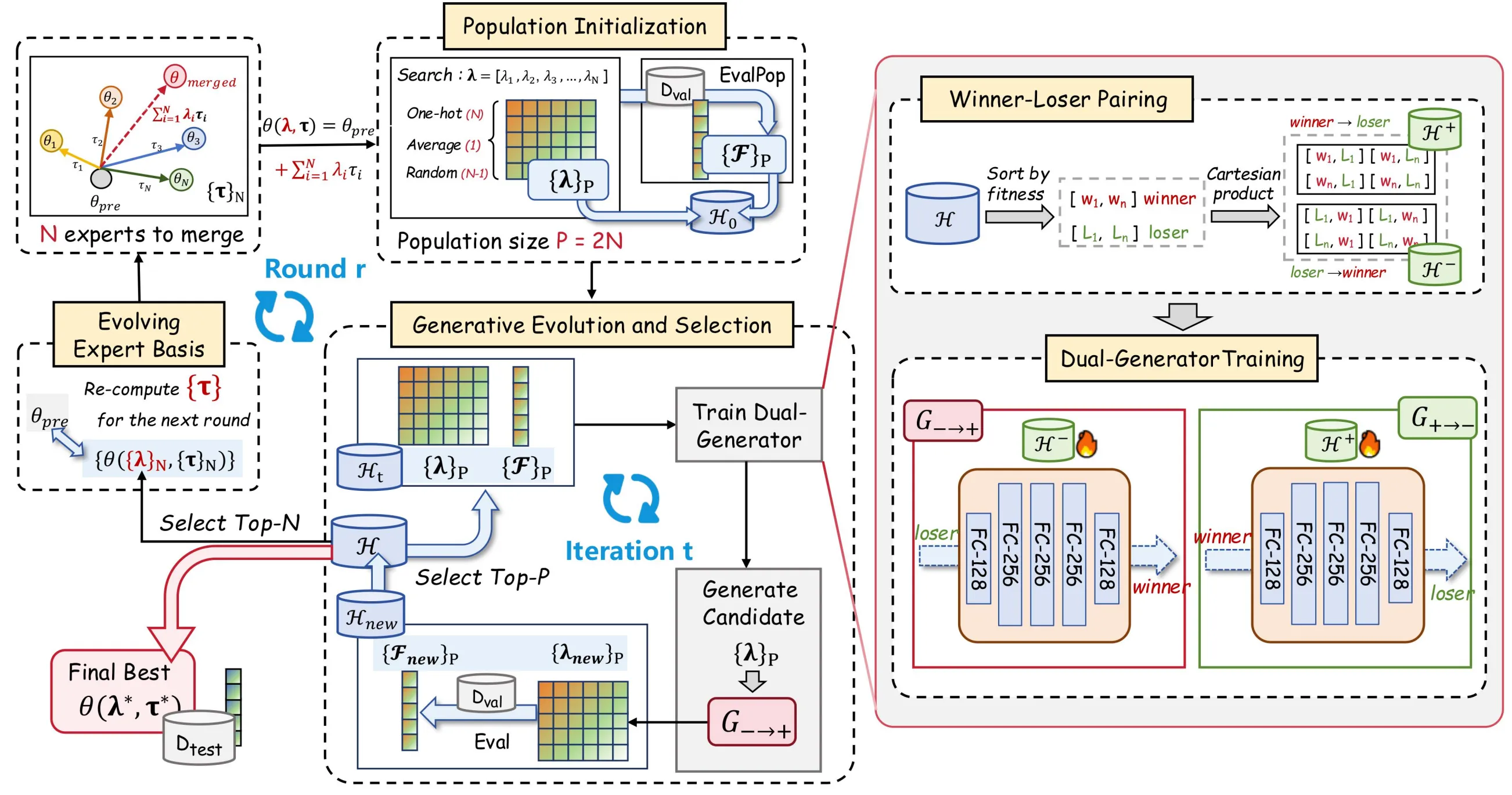
Para resolver os problemas anteriores, propomos o EvoGM (Evolutionary Generative Merging), cujo código já está disponível em open source: https://github.com/JiangTao97/evogm.
A ideia central do EvoGM é organizar as configurações candidatas de fusão como uma população e transformar o processo de pesquisa de coeficientes de fusão num problema de aprendizagem generativa.
O ponto chave é que o modelo generativo não aprende directamente «quais são os coeficientes de fusão óptimos», mas sim «como passar de uma configuração pior para uma melhor». Isto deve-se ao facto de, em cenários de fusão de modelos, ser difícil estabelecer uma ordenação global fiável entre diferentes configurações; em contrapartida, as comparações par a par oferecem sinais de superioridade e inferioridade mais estáveis.
O EvoGM utiliza resultados históricos de validação para construir dados de emparelhamento winner-loser, permitindo que o gerador aprenda a direcção de melhoria de loser para winner. Para cada par de configurações candidatas de fusão, o algoritmo não regista apenas a diferença de desempenho correspondente, mas também converte esta relação de «de pior para melhor» em amostras de treino. Após acumular e aprender continuamente, o gerador consegue captar gradualmente que ajustes de coeficientes têm maior probabilidade de melhorar o desempenho, formando assim uma compreensão implícita da estrutura do espaço de pesquisa. Por outras palavras, aprende não a solução excelente em si, mas as leis de melhoria de desempenho.
Esta ideia está alinhada com os mecanismos de aprendizagem competitiva na optimização evolutiva. Pode remontar-se ao CSO (Competitive Swarm Optimizer), que impulsiona a actualização de indivíduos através de competição winner-loser, fazendo com que indivíduos de pior desempenho se aproximem dos de melhor desempenho; o EvoGO (Evolutionary Generative Optimization) vai mais além ao utilizar modelos generativos para aprender direcções de melhoria a partir de dados históricos de pesquisa, substituindo de forma orientada por dados parte dos operadores de pesquisa concebidos manualmente. O EvoGM introduz esta ideia no cenário de fusão de modelos, treinando geradores com feedback de validação para orientar a pesquisa subsequente. Deste modo, os resultados de validação deixam de ser utilizados apenas para filtrar e eliminar candidatos, passando a converter-se continuamente em experiência de pesquisa reutilizável, permitindo que o processo de pesquisa acumule conhecimento e aumente a sua eficiência ao longo das iterações.
IV. Como funciona o EvoGM?
O fluxo geral do EvoGM pode dividir-se em cinco passos: construir candidatos, formar pares de treino winner-loser, treinar geradores, gerar e seleccionar novos coeficientes, e actualizar a base de especialistas. Após fornecer modelos especialistas e tarefas de validação, estes passos podem executar-se automaticamente em ciclo, sem necessidade de conceber manualmente regras de fusão ou ajustar coeficientes em cada ronda.
- Inicialização da população: construir candidatos de fusão
O EvoGM necessita primeiro de construir um conjunto inicial de candidatos. Cada candidato corresponde a um conjunto de coeficientes de fusão, ou seja, a uma forma distinta de combinar vários modelos especialistas.
Concretamente, a população inicial inclui normalmente vários tipos de configurações: coeficientes correspondentes à fusão por média, coeficientes one-hot correspondentes a modelos especialistas individuais e coeficientes de fusão obtidos por amostragem aleatória. Isto permite cobrir algumas formas de fusão de referência habituais e proporcionar diversidade para a pesquisa subsequente.
Para cada conjunto de coeficientes candidatos, o EvoGM constrói um modelo fundido e avalia o seu desempenho no conjunto de validação. Após este passo, o algoritmo obtém não apenas vários modelos candidatos, mas um conjunto de registos históricos de «coeficientes de fusão—desempenho de validação». Toda a aprendizagem generativa e selecção evolutiva subsequentes assentam nestes registos.
- Emparelhamento winner-loser: converter resultados de validação em dados de treino
Após obter candidatos e o seu desempenho de validação, o EvoGM divide as configurações candidatas históricas em winner e loser consoante o desempenho. winner denota a configuração de fusão relativamente melhor, e loser a relativamente pior.
O ponto chave aqui não é simplesmente conservar configurações de alta pontuação e descartar as de baixa pontuação, mas emparelhá-las para formar pares de treino. Para o gerador, um par winner-loser fornece uma informação útil: a partir desta configuração pior, para que configuração melhor deveria aproximar-se?
Assim, os candidatos de baixo desempenho não são amostras inúteis. Pelo contrário, fornecem o «ponto de partida» do processo de pesquisa, enquanto os candidatos de alto desempenho fornecem a «direcção de melhoria». Através deste emparelhamento, o EvoGM consegue converter resultados limitados de avaliação de validação em mais sinais de supervisão aprendíveis, melhorando a eficiência de aproveitamento de dados com feedback de poucas amostras.
- Treino de duplo gerador: aprender a transformação de configurações más para boas
Após construir os pares de treino winner-loser, o EvoGM utiliza uma estrutura de duplo gerador para o treino.
O gerador directo aprende o mapeamento de loser para winner, ou seja, transforma configurações de fusão de baixo desempenho em configurações de alto desempenho mais promissoras. O gerador inverso aprende o mapeamento inverso de winner para loser, utilizado para restringir a consistência estrutural do processo generativo.
O objectivo deste desenho não é que o gerador memorize simplesmente configurações de alta pontuação existentes, mas sim que aprenda as leis de melhoria no espaço de coeficientes de fusão. Através de restrições de consistência cíclica, o EvoGM pode reduzir o risco de colapso do gerador para poucos pontos de alta pontuação, de modo que as configurações candidatas geradas se orientem para regiões de alto desempenho e, ao mesmo tempo, preservem a informação estrutural do espaço de pesquisa.
- Evolução generativa e selecção: substituir a perturbação aleatória por operadores aprendidos
Após o treino do gerador, o EvoGM utiliza o gerador directo para transformar as configurações candidatas actuais e gerar um novo lote de coeficientes de fusão. Este passo equivale a «gerar novos indivíduos» num algoritmo evolutivo tradicional, mas os novos indivíduos já não provêm principalmente de perturbação aleatória, e sim das direcções de melhoria aprendidas pelo modelo generativo.
De seguida, estes novos coeficientes de fusão são utilizados para construir novos modelos fundidos e avaliados novamente no conjunto de validação. Os resultados de avaliação são adicionados ao registo histórico e participam na selecção juntamente com os candidatos existentes.
Através deste ciclo, o EvoGM experiencia em cada ronda um processo de «gerar—avaliar—seleccionar—reaprender». Este ciclo fechado constitui a evolução populacional das configurações candidatas de fusão: os resultados históricos de validação acumulam-se continuamente, o gerador recebe novos sinais de treino de forma contínua e, assim, melhora progressivamente a sua capacidade de gerar de forma autónoma configurações de fusão de alta qualidade.
- Base de especialistas evolutiva: actualizar continuamente o espaço de pesquisa
Para além de optimizar os coeficientes de fusão, o EvoGM introduz ainda um mecanismo de base de especialistas evolutiva.
A fusão de modelos tradicional trata normalmente os modelos especialistas como entradas fixas, pesquisando coeficientes de fusão apenas entre modelos especialistas fixos. O EvoGM é diferente: no final de cada ronda, os melhores modelos fundidos são seleccionados como nova base de especialistas para a pesquisa da ronda seguinte.
O sentido de o fazer é que os modelos fundidos excelentes já contêm certas combinações de capacidades efectivas. Ao incorporá-los na nova base de especialistas, a pesquisa subsequente deixa de se limitar a combinações lineares entre os modelos especialistas originais, podendo continuar a evoluir sobre modelos intermédios já validados como efectivos.
Assim, o espaço de pesquisa do EvoGM não é fixo, mas actualiza-se continuamente com o processo de pesquisa. Não procura apenas melhores coeficientes de fusão, mas também constrói gradualmente uma base de representação de especialistas mais adequada à tarefa actual.
V. Quais são as vantagens chave do EvoGM?
Em comparação com os métodos tradicionais de fusão de modelos, as vantagens do EvoGM manifestam-se principalmente em três aspectos.
Em primeiro lugar, o EvoGM leva a fusão de modelos de regras heurísticas estáticas para uma pesquisa autónoma orientada por feedback. Os métodos tradicionais costumam depender da fusão por média, do escalamento manual ou da perturbação aleatória, enquanto o EvoGM pode ajustar continuamente a direcção de pesquisa com base em resultados históricos de validação, de modo que o processo de fusão deixa de depender da concepção manual de regras e do ajuste de coeficientes em cada ronda.
Em segundo lugar, o EvoGM melhora a eficiência de aproveitamento de dados com um orçamento limitado de avaliações. Na fusão de modelos, cada avaliação de configuração candidata requer construir um modelo fundido e executar tarefas de validação, com um custo não negligenciável. O EvoGM converte ainda estes resultados de avaliação em sinais de treino aprendíveis, de modo que cada tentativa fornece informação para a pesquisa subsequente.
Por fim, o EvoGM não procura apenas um conjunto melhor de coeficientes de fusão, mas aprende gradualmente as leis de combinação de capacidades entre modelos especialistas. Através da pesquisa generativa da população candidata e da actualização da base de especialistas, consegue recombinar e expandir continuamente o espaço de pesquisa com base em modelos especialistas existentes, descobrindo de forma mais efectiva modelos fundidos de alto desempenho.
VI. Resultados experimentais: o EvoGM é realmente eficaz?
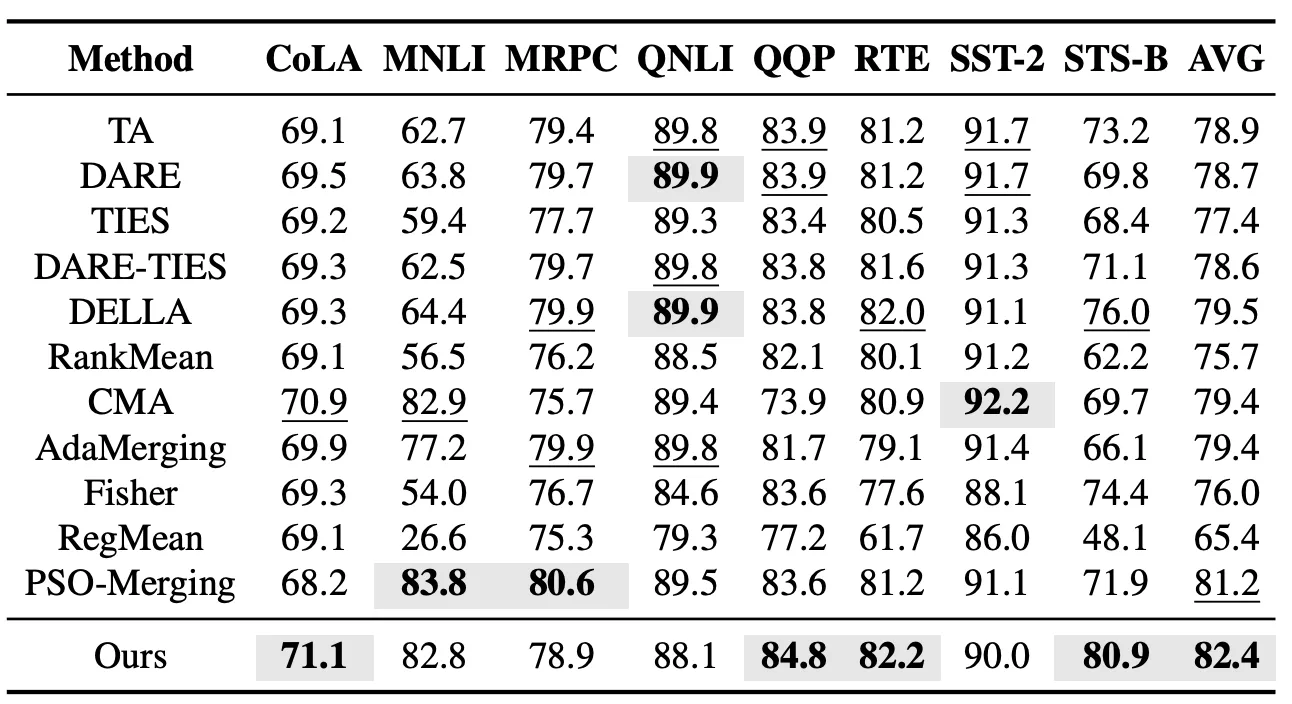
Na configuração de tarefas vistas, avaliámos primeiro o efeito de fusão de modelos do EvoGM nas tarefas da série GLUE. Este experimento abrange 8 tarefas de compreensão de linguagem — CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2 e STS-B — e compara o EvoGM com métodos representativos de fusão de modelos como Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging e PSO-Merging. Os resultados mostram que o EvoGM supera em desempenho médio nas 8 tarefas o anterior melhor método, PSO-Merging.
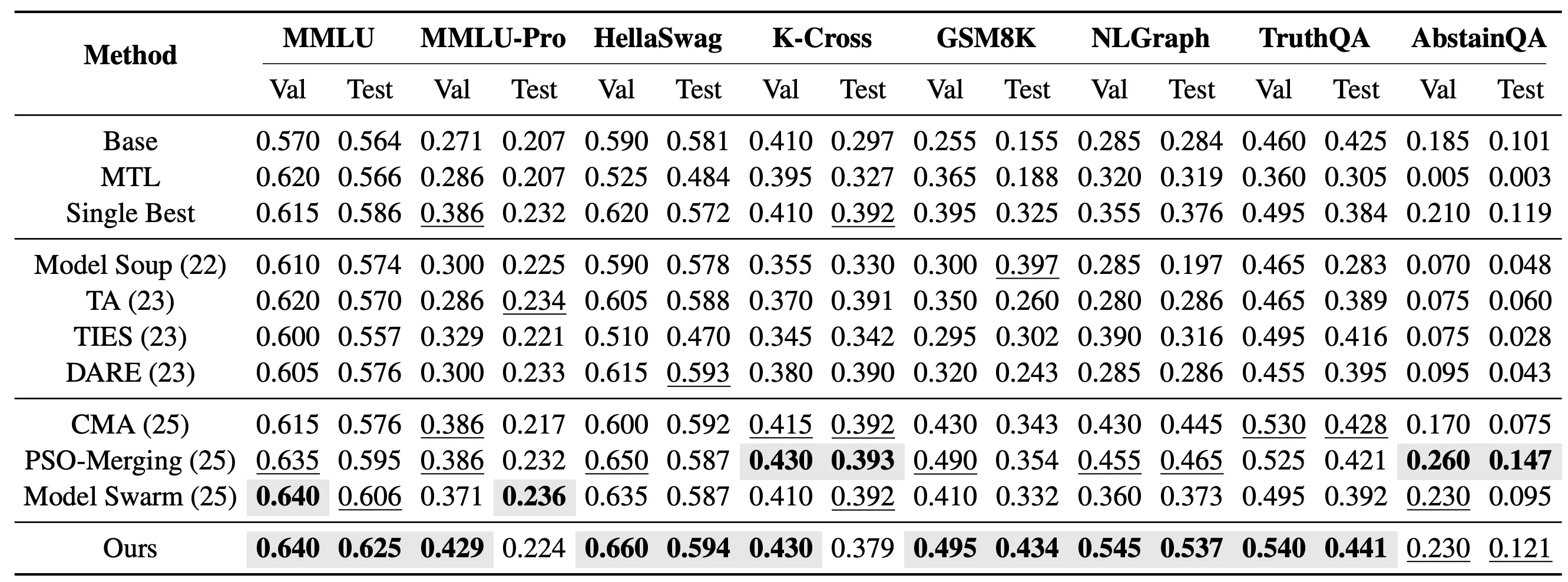
Na configuração mais exigente de tarefas não vistas, avaliámos ainda se o EvoGM consegue transferir as capacidades de modelos especialistas existentes para novas tarefas não incluídas no ajuste fino dos especialistas. Concretamente, fundimos 10 modelos especialistas LoRA baseados em Qwen2.5-1.5B e testámo-los em 8 tarefas não vistas: MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA e AbstainQA. Estas tarefas abrangem compreensão de conhecimento, raciocínio complexo e fiabilidade em segurança, entre outras dimensões de capacidade, reflectindo melhor a capacidade de generalização dos métodos de fusão de modelos do que as tarefas vistas.
Na configuração de fusão não vista de tarefa única, o EvoGM pesquisa um conjunto de coeficientes de fusão para cada tarefa alvo separadamente. Os resultados mostram que o EvoGM obtém o melhor desempenho de teste em 5 das 8 tarefas de teste.
Para além da fusão de tarefa única, examinámos ainda a configuração de fusão não vista multitarefa. Nesta configuração, o objectivo deixa de ser encontrar o modelo óptimo para cada tarefa separadamente, mas sim obter um modelo fundido unificado capaz de cobrir simultaneamente as 8 tarefas não vistas. Os resultados indicam que, na fusão não vista multitarefa, o EvoGM obtém o melhor desempenho médio de teste entre todos os métodos de fusão.
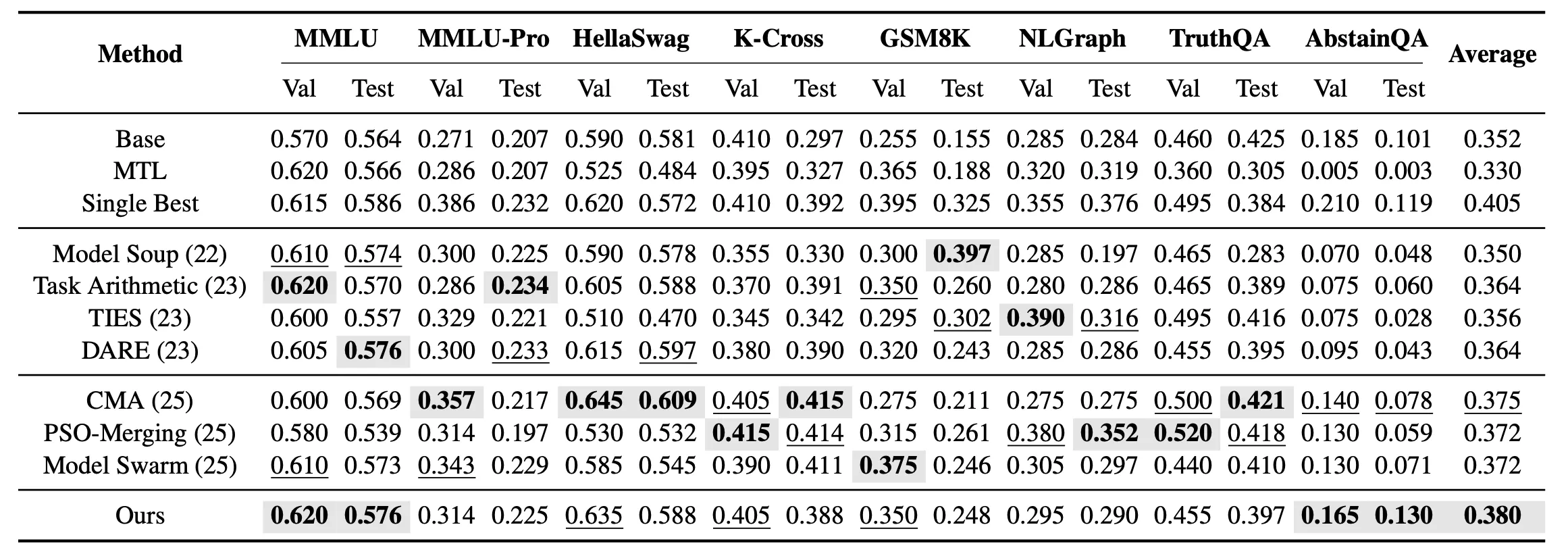
Os resultados mostram que o EvoGM alcança um desempenho de generalização global mais sólido tanto na fusão de tarefa única como na configuração multitarefa, superando os métodos existentes de fusão de modelos em múltiplas tarefas relacionadas com conhecimento, raciocínio e segurança.
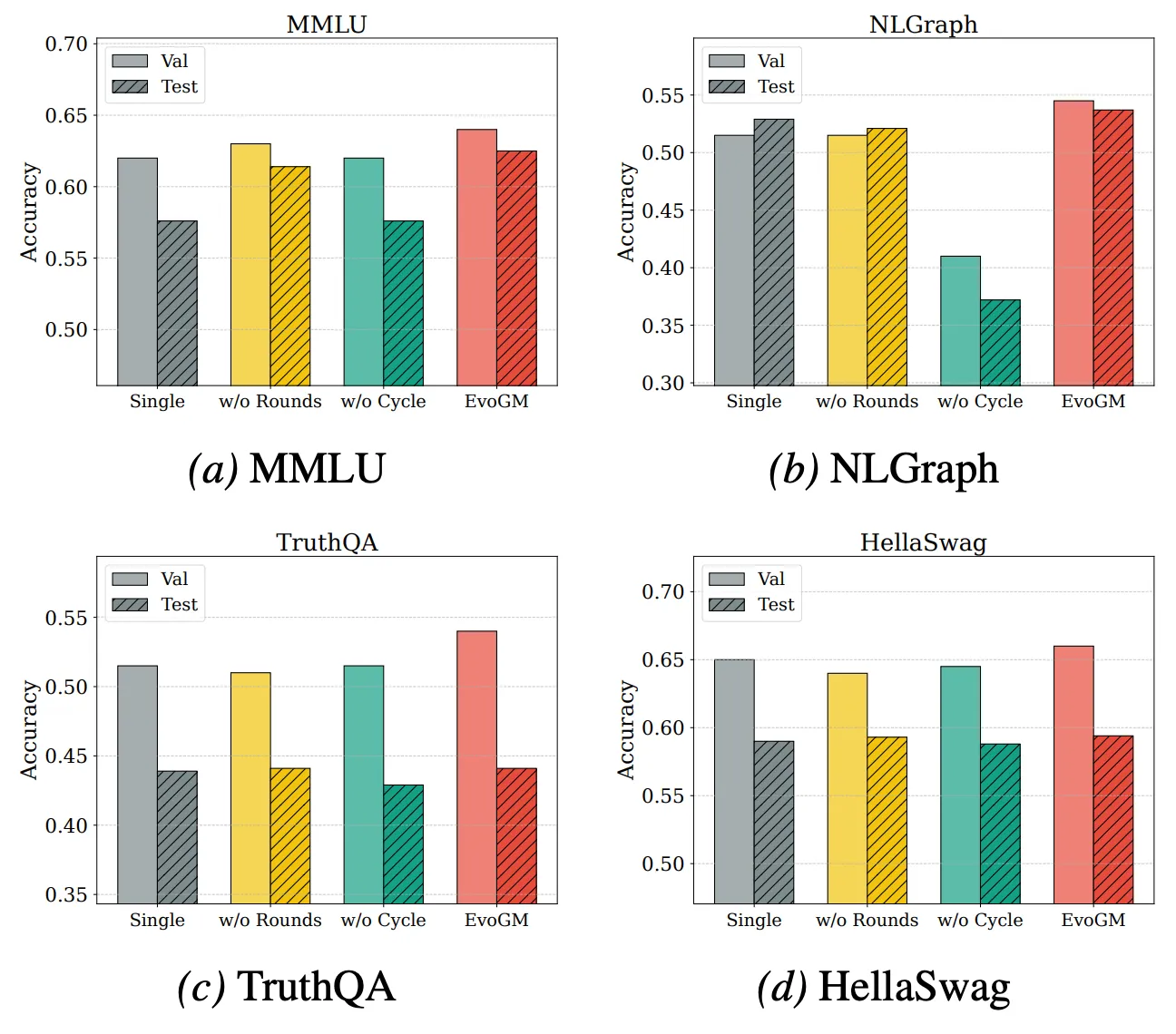
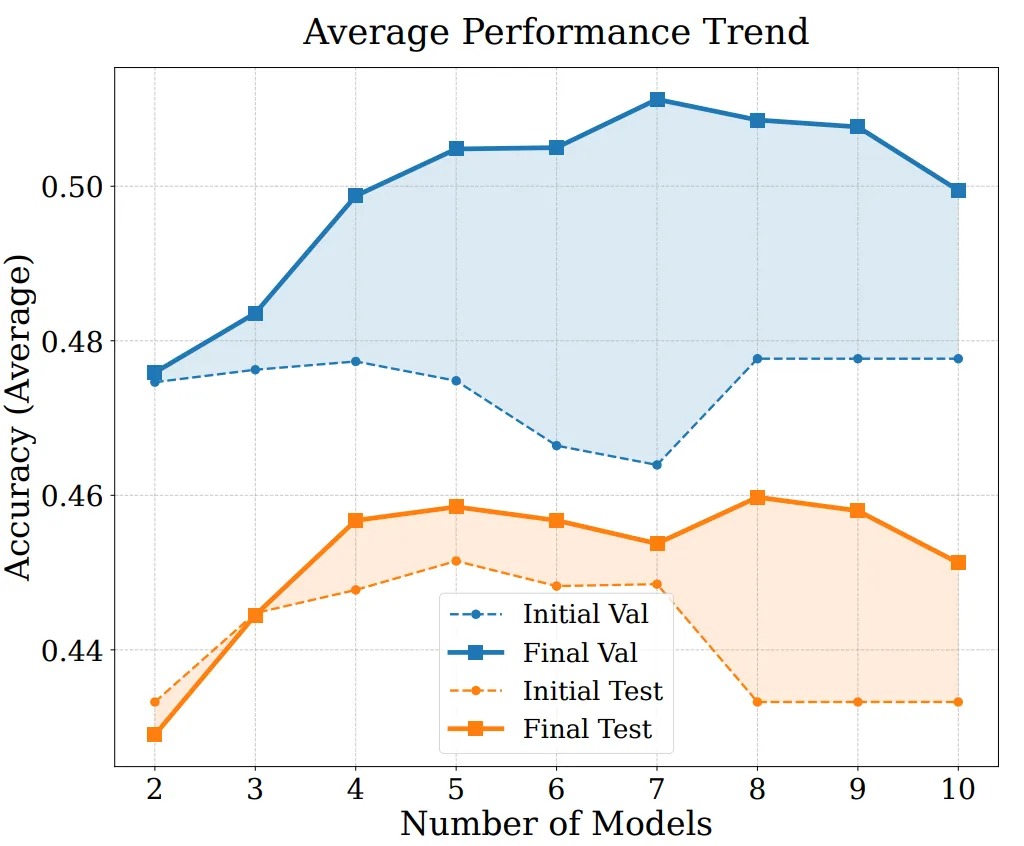
Para analisar mais a fundo a origem do desempenho do EvoGM e a sua capacidade de escalabilidade, realizámos experiências de ablação e de fusão com diferentes números de modelos. Os resultados indicam que o EvoGM completo obtém sempre o melhor desempenho ou o mais estável; ao remover componentes chave, o desempenho diminui em diferentes graus, o que demonstra que a sua vantagem provém principalmente do mecanismo de evolução generativa, e não de uma simples pesquisa aleatória ou de mais rondas de pesquisa. Ao mesmo tempo, quando aumenta o número de modelos especialistas participantes na fusão, o EvoGM mantém um bom desempenho e mostra uma tendência de melhoria estável, indicando que consegue enfrentar de forma efectiva espaços de fusão maiores e mais complexos, aproveitar plenamente as capacidades complementares entre diferentes modelos especialistas e apresenta uma boa escalabilidade.
VII. De EvoGO a EvoGM: extensão do pensamento evolutivo generativo
De uma perspectiva mais ampla, o EvoGM pode compreender-se como uma extensão da ideia do EvoGO à fusão de modelos de grande escala. O EvoGO centra-se em como fazer com que a optimização evolutiva passe de depender de operadores de cruzamento, mutação e perturbação concebidos manualmente para aprender automaticamente, através de modelos generativos a partir de dados históricos de pesquisa, novas formas de gerar soluções. Ou seja, a pesquisa evolutiva deixa de ser apenas «gerar candidatos ao acaso e filtrar», e começa a aprender «como gerar candidatos mais promissores».
O EvoGM leva esta ideia ao cenário de fusão de modelos de grande escala. Aqui, os candidatos já não são variáveis numéricas de um problema de optimização geral, mas conjuntos de coeficientes de fusão; uma avaliação já não é simplesmente calcular uma função objectivo, mas construir um modelo fundido e validar o seu desempenho em tarefas downstream. Assim, o EvoGM reformula na prática a fusão de modelos como um problema de optimização generativa: como aprender a partir de resultados históricos de avaliação as leis de combinação de capacidades entre modelos especialistas e gerar configurações de fusão superiores.
Isto distingue claramente o EvoGM dos métodos de fusão de modelos baseados em pesquisa tradicional. Os métodos tradicionais utilizam normalmente os resultados de validação apenas para ordenar e filtrar, enquanto o EvoGM os converte ainda em sinais de treino. As configurações de baixo desempenho não são simplesmente descartadas, mas emparelhadas com configurações de alto desempenho em pares winner-loser para treinar o gerador a aprender a direcção evolutiva de configurações más para boas.
De EvoGO a EvoGM, em essência passa-se de «aprender a optimizar candidatos» a «permitir que a estratégia de fusão de modelos de grande escala evolua de forma autónoma na população». Isto não liberta apenas a fusão de modelos de regras empíricas e perturbações aleatórias, mas também oferece uma nova perspectiva: as capacidades dos modelos de grande escala podem ser fundidas, e a própria estratégia de fusão também pode aprender continuamente a partir do feedback populacional.
VIII. Conclusões e perspectivas
À medida que aumentam os modelos especialistas, modelos LoRA e modelos de tarefa no ecossistema open source, a questão chave do futuro pode não ser apenas «como treinar um novo modelo», mas «como combinar eficientemente as capacidades de modelos existentes». O EvoGM oferece uma nova resposta: sem reentrenar os modelos de grande escala participantes na fusão, aprende através de evolução generativa a partir de feedback limitado de validação e completa de forma autónoma a construção da população candidata, a geração de esquemas de fusão, a avaliação e selecção, e a actualização da base de especialistas. Em suma, o EvoGM leva a fusão de modelos de «ajustar coeficientes por experiência» para «deixar que a estratégia de fusão aprenda e evolua por si mesma». Isto também significa que a reutilização de capacidades de modelos de grande escala pode entrar numa nova fase: não reentrenar um modelo sempre que surge uma nova tarefa, mas deixar que os modelos especialistas existentes combinem continuamente, através de evolução populacional e fusão autónoma, modelos mais adequados para novas tarefas.
Código aberto / Comunidade
📄 Artigo: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 Projecto upstream (EvoX):
https://github.com/EMI-Group/evox 🌐 Grupo QQ:
297969717
