ICML 2026 | EvoGM: fusión autónoma de modelos de gran escala mediante evolución poblacional sin reentrenamiento

Resumen
A medida que las capacidades de los modelos de lenguaje de gran escala siguen mejorando, también aumenta el número de modelos expertos ajustados para tareas específicas. Cómo reutilizar eficientemente las capacidades de estos modelos expertos sin reentrenar los modelos de gran escala participantes en la fusión ni depender de datos de entrenamiento adicionales a gran escala se ha convertido en un problema central en la fusión de modelos. Los métodos existentes suelen depender de la fusión por promedio, escalado manual, recorte de parámetros o búsqueda aleatoria. Aunque pueden combinar las capacidades de varios modelos en cierta medida, les resulta difícil aprender continuamente de evaluaciones históricas y mejorar la estrategia de fusión.
Para abordar este problema, el equipo EvoX, en colaboración con el Laboratorio Peng Cheng, presenta EvoGM (Evolutionary Generative Merging), un marco de fusión evolutiva generativa de modelos que transforma la búsqueda de coeficientes de fusión en un problema de optimización generativa aprendible. EvoGM organiza distintas configuraciones de fusión en una población de candidatos y, mediante emparejamiento winner-loser, entrenamiento de doble generador, restricciones de consistencia cíclica y actualización evolutiva de la base de expertos, hace que la población evolucione continuamente en un bucle cerrado de «generar—evaluar—seleccionar—reaprender», aprendiendo de forma autónoma a partir de retroalimentación limitada de validación cómo transformar configuraciones de bajo rendimiento en configuraciones de alto rendimiento. Los resultados experimentales muestran que EvoGM exhibe una capacidad de fusión de modelos superior tanto en escenarios de tareas vistas como no vistas.
I. ¿Por qué necesitamos la fusión de modelos?
En los últimos años, las capacidades de los modelos de lenguaje de gran escala han ido en aumento, pero también lo han hecho los costes de entrenamiento y ajuste fino. Surge una pregunta natural: si ya disponemos de varios modelos expertos que funcionan bien en distintas tareas, ¿podemos combinar sus capacidades para obtener un modelo nuevo más potente y más general, sin reentrenar estos modelos de gran escala?
Eso es precisamente lo que la fusión de modelos pretende resolver.
La idea central de la fusión de modelos es directa: múltiples modelos expertos suelen proceder del mismo modelo base, ajustados únicamente en distintos datos o tareas. Por tanto, se puede considerar el cambio de parámetros de cada modelo experto respecto al modelo base como una «dirección de capacidad», y combinar ponderadamente estas direcciones para construir un nuevo modelo fusionado. Su ventaja es que no requiere reentrenar ni ajustar finamente los modelos de gran escala participantes en la fusión, ni depender de datos de entrenamiento adicionales a gran escala; solo hay que buscar los coeficientes de fusión adecuados. Cabe señalar que EvoGM entrena generadores ligeros para buscar coeficientes, pero no actualiza los parámetros de los modelos expertos de gran escala.
II. ¿Dónde reside la verdadera dificultad de la fusión de modelos?
La verdadera dificultad está aquí: ¿cómo deben elegirse estos coeficientes?
La fusión de modelos parece ser simplemente una combinación ponderada de varios modelos expertos, pero las relaciones de capacidad entre distintos modelos expertos no son sencillas. Algunas direcciones de tarea pueden complementarse, mientras que ciertas actualizaciones de parámetros pueden entrar en conflicto; un conjunto de coeficientes de fusión puede funcionar mejor en un tipo de tareas y provocar pérdida de rendimiento en otro. Por tanto, la relación entre los coeficientes de fusión y el rendimiento final del modelo no es una relación lineal fácil de caracterizar manualmente.
Los métodos tradicionales suelen depender de reglas heurísticas como la fusión por promedio, el escalado manual, el recorte de parámetros o la esparsificación. Estos métodos son simples y eficaces, pero presentan limitaciones evidentes: suelen ser estáticos y empíricos, y les resulta difícil ajustarse de forma adaptativa según la retroalimentación de validación de distintas tareas.
Posteriormente, se introdujeron métodos de búsqueda evolutiva en la fusión de modelos, organizando configuraciones candidatas de fusión en una población y buscando mejores coeficientes mediante perturbación aleatoria, evaluación de aptitud y selección. Estos métodos son más flexibles que las reglas fijas, pero siguen teniendo un problema clave: los resultados de validación suelen utilizarse solo para ordenar y filtrar, sin convertirse en experiencia de búsqueda aprendible. En otras palabras, el algoritmo sabe «qué candidato es mejor», pero no aprende realmente «cómo debería mejorar un candidato peor».
Este es el problema central que EvoGM pretende resolver: la fusión de modelos no debería limitarse a que la población candidata pruebe y filtre continuamente, sino que debería aprender de las evaluaciones históricas direcciones de mejora y generar de forma autónoma configuraciones de fusión más prometedoras.
III. EvoGM: dejar que la estrategia de fusión aprenda de forma autónoma en la evolución poblacional
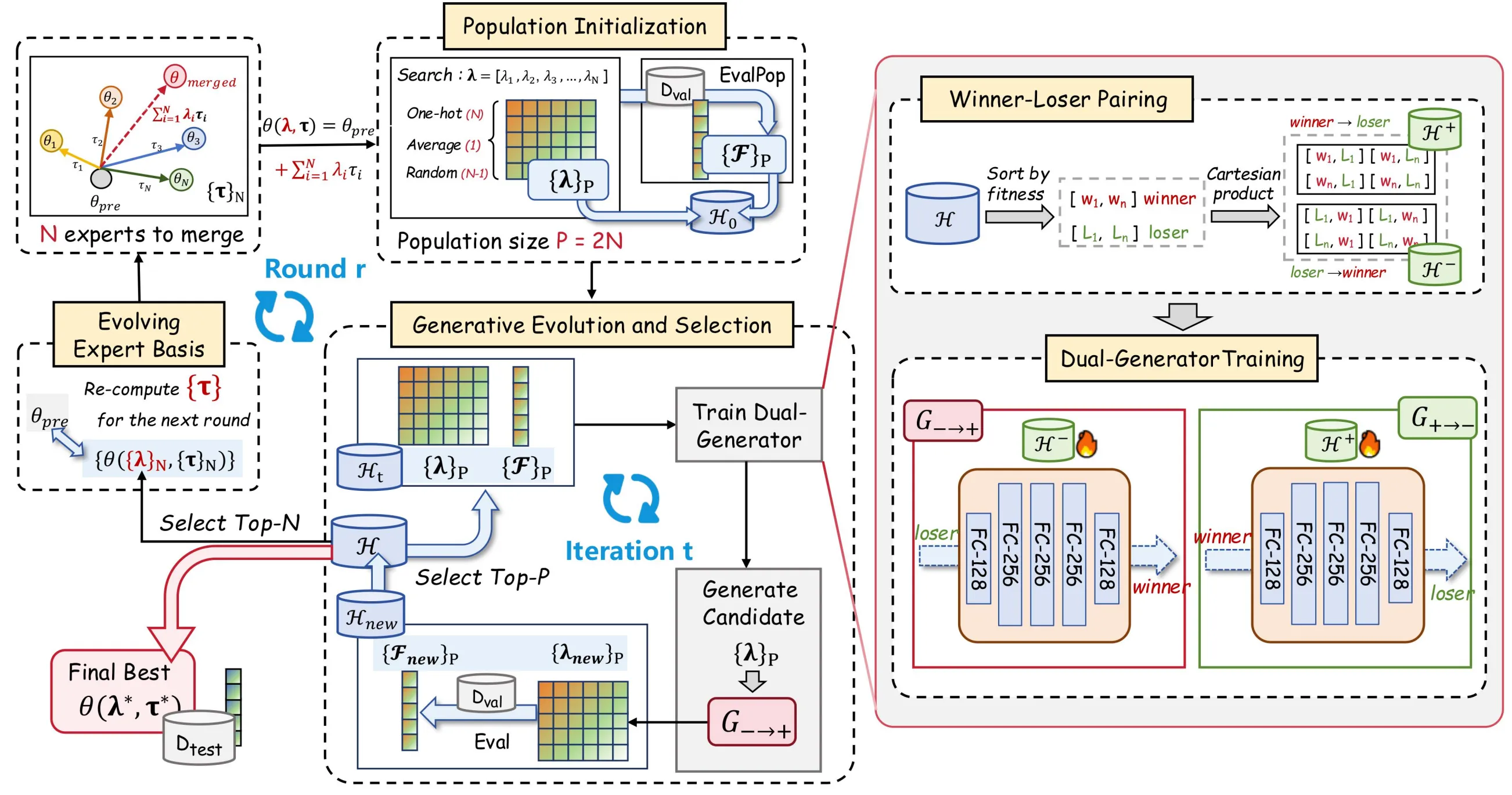
Para resolver los problemas anteriores, proponemos EvoGM (Evolutionary Generative Merging), cuyo código ya está disponible en código abierto: https://github.com/JiangTao97/evogm.
La idea central de EvoGM es organizar las configuraciones candidatas de fusión como una población y transformar el proceso de búsqueda de coeficientes de fusión en un problema de aprendizaje generativo.
Lo clave es que el modelo generativo no aprende directamente «cuáles son los coeficientes de fusión óptimos», sino «cómo pasar de una configuración peor a una mejor». Esto se debe a que, en escenarios de fusión de modelos, resulta difícil establecer un orden global fiable entre distintas configuraciones; en cambio, las comparaciones por pares ofrecen señales de superioridad e inferioridad más estables.
EvoGM utiliza resultados históricos de validación para construir datos de emparejamiento winner-loser, permitiendo que el generador aprenda la dirección de mejora de loser a winner. Para cada par de configuraciones candidatas de fusión, el algoritmo no solo registra la diferencia de rendimiento correspondiente, sino que también convierte esta relación de «de peor a mejor» en muestras de entrenamiento. Tras acumular y aprender continuamente, el generador puede captar gradualmente qué ajustes de coeficientes tienen más probabilidades de mejorar el rendimiento, formando así una comprensión implícita de la estructura del espacio de búsqueda. En otras palabras, no aprende la solución excelente en sí, sino las leyes de mejora del rendimiento.
Esta idea está en línea con los mecanismos de aprendizaje competitivo en la optimización evolutiva. Puede remontarse a CSO (Competitive Swarm Optimizer), que impulsa la actualización de individuos mediante competición winner-loser, haciendo que los individuos de peor rendimiento se acerquen a los de mejor rendimiento; EvoGO (Evolutionary Generative Optimization) va un paso más allá al utilizar modelos generativos para aprender direcciones de mejora a partir de datos históricos de búsqueda, sustituyendo de forma basada en datos parte de los operadores de búsqueda diseñados manualmente. EvoGM introduce esta idea en el escenario de fusión de modelos, entrenando generadores mediante retroalimentación de validación para guiar la búsqueda posterior. De este modo, los resultados de validación ya no se utilizan solo para filtrar y descartar candidatos, sino que se convierten continuamente en experiencia de búsqueda reutilizable, permitiendo que el proceso de búsqueda acumule conocimiento e incremente su eficiencia a lo largo de las iteraciones.
IV. ¿Cómo funciona EvoGM?
El flujo general de EvoGM puede dividirse en cinco pasos: construir candidatos, formar pares de entrenamiento winner-loser, entrenar generadores, generar y seleccionar nuevos coeficientes, y actualizar la base de expertos. Tras proporcionar modelos expertos y tareas de validación, estos pasos pueden ejecutarse automáticamente en bucle, sin necesidad de diseñar manualmente reglas de fusión o ajustar coeficientes en cada ronda.
- Inicialización de la población: construir candidatos de fusión
EvoGM necesita primero construir un conjunto inicial de candidatos. Cada candidato corresponde a un conjunto de coeficientes de fusión, es decir, a una forma distinta de combinar varios modelos expertos.
En concreto, la población inicial suele incluir varios tipos de configuraciones: coeficientes correspondientes a la fusión por promedio, coeficientes one-hot correspondientes a modelos expertos individuales y coeficientes de fusión obtenidos por muestreo aleatorio. Así se cubren algunas formas de fusión de referencia habituales y se aporta diversidad para la búsqueda posterior.
Para cada conjunto de coeficientes candidatos, EvoGM construye un modelo fusionado y evalúa su rendimiento en el conjunto de validación. Tras este paso, el algoritmo obtiene no solo varios modelos candidatos, sino un conjunto de registros históricos de «coeficientes de fusión—rendimiento de validación». Todo el aprendizaje generativo y la selección evolutiva posteriores se basan en estos registros.
- Emparejamiento winner-loser: convertir resultados de validación en datos de entrenamiento
Tras obtener candidatos y su rendimiento de validación, EvoGM divide las configuraciones candidatas históricas en winner y loser según su rendimiento. winner denota la configuración de fusión relativamente mejor, y loser la relativamente peor.
Lo clave aquí no es simplemente conservar configuraciones de alta puntuación y descartar las de baja puntuación, sino emparejarlas para formar pares de entrenamiento. Para el generador, un par winner-loser proporciona un dato útil: desde esta configuración peor, ¿hacia qué configuración mejor debería acercarse?
Por tanto, los candidatos de bajo rendimiento no son muestras inútiles. Al contrario, proporcionan el «punto de partida» del proceso de búsqueda, mientras que los candidatos de alto rendimiento proporcionan la «dirección de mejora». Mediante este emparejamiento, EvoGM puede convertir resultados limitados de evaluación de validación en más señales de supervisión aprendibles, mejorando la eficiencia de aprovechamiento de datos con retroalimentación de pocas muestras.
- Entrenamiento de doble generador: aprender la transformación de configuraciones malas a buenas
Tras construir los pares de entrenamiento winner-loser, EvoGM utiliza una estructura de doble generador para el entrenamiento.
El generador directo aprende el mapeo de loser a winner, es decir, transforma configuraciones de fusión de bajo rendimiento en configuraciones de alto rendimiento más prometedoras. El generador inverso aprende el mapeo inverso de winner a loser, utilizado para restringir la consistencia estructural del proceso generativo.
El objetivo de este diseño no es que el generador memorice simplemente configuraciones de alta puntuación existentes, sino que aprenda las leyes de mejora en el espacio de coeficientes de fusión. Mediante restricciones de consistencia cíclica, EvoGM puede reducir el riesgo de que el generador colapse hacia unos pocos puntos de alta puntuación, de modo que las configuraciones candidatas generadas se orienten hacia regiones de alto rendimiento y, al mismo tiempo, conserven la información estructural del espacio de búsqueda.
- Evolución generativa y selección: sustituir la perturbación aleatoria por operadores aprendidos
Una vez entrenado el generador, EvoGM utiliza el generador directo para transformar las configuraciones candidatas actuales y generar un nuevo lote de coeficientes de fusión. Este paso equivale a «generar nuevos individuos» en un algoritmo evolutivo tradicional, pero los nuevos individuos ya no provienen principalmente de perturbación aleatoria, sino de las direcciones de mejora aprendidas por el modelo generativo.
A continuación, estos nuevos coeficientes de fusión se utilizan para construir nuevos modelos fusionados y se evalúan de nuevo en el conjunto de validación. Los resultados de evaluación se añaden al registro histórico y participan en la selección junto con los candidatos existentes.
Mediante este bucle, EvoGM experimenta en cada ronda un proceso de «generar—evaluar—seleccionar—reaprender». Este bucle cerrado constituye la evolución poblacional de las configuraciones candidatas de fusión: los resultados históricos de validación se acumulan continuamente, el generador recibe nuevas señales de entrenamiento de forma continua y, así, mejora progresivamente su capacidad de generar de forma autónoma configuraciones de fusión de alta calidad.
- Base de expertos evolutiva: actualizar continuamente el espacio de búsqueda
Además de optimizar los coeficientes de fusión, EvoGM introduce un mecanismo de base de expertos evolutiva.
La fusión de modelos tradicional suele tratar los modelos expertos como entradas fijas, buscando coeficientes de fusión solo entre modelos expertos fijos. EvoGM es diferente: al final de cada ronda, los mejores modelos fusionados se seleccionan como nueva base de expertos para la búsqueda de la ronda siguiente.
El sentido de hacerlo es que los modelos fusionados excelentes ya contienen ciertas combinaciones de capacidades eficaces. Al incorporarlos en la nueva base de expertos, la búsqueda posterior ya no se limita a combinaciones lineales entre los modelos expertos originales, sino que puede seguir evolucionando sobre modelos intermedios ya validados como eficaces.
Por tanto, el espacio de búsqueda de EvoGM no es fijo, sino que se actualiza continuamente con el proceso de búsqueda. No solo busca mejores coeficientes de fusión, sino que construye gradualmente una base de representación de expertos más adecuada para la tarea actual.
V. ¿Cuáles son las ventajas clave de EvoGM?
En comparación con los métodos tradicionales de fusión de modelos, las ventajas de EvoGM se manifiestan principalmente en tres aspectos.
En primer lugar, EvoGM lleva la fusión de modelos de reglas heurísticas estáticas a una búsqueda autónoma impulsada por retroalimentación. Los métodos tradicionales suelen depender de la fusión por promedio, el escalado manual o la perturbación aleatoria, mientras que EvoGM puede ajustar continuamente la dirección de búsqueda según resultados históricos de validación, de modo que el proceso de fusión ya no depende del diseño manual de reglas y del ajuste de coeficientes en cada ronda.
En segundo lugar, EvoGM mejora la eficiencia de aprovechamiento de datos con un presupuesto limitado de evaluaciones. En la fusión de modelos, cada evaluación de configuración candidata requiere construir un modelo fusionado y ejecutar tareas de validación, con un coste no despreciable. EvoGM convierte además estos resultados de evaluación en señales de entrenamiento aprendibles, de modo que cada prueba aporta información para la búsqueda posterior.
Por último, EvoGM no solo busca un conjunto mejor de coeficientes de fusión, sino que aprende gradualmente las leyes de combinación de capacidades entre modelos expertos. Mediante la búsqueda generativa de la población candidata y la actualización de la base de expertos, puede recombinar y ampliar continuamente el espacio de búsqueda sobre la base de modelos expertos existentes, descubriendo de forma más eficaz modelos fusionados de alto rendimiento.
VI. Resultados experimentales: ¿es realmente eficaz EvoGM?
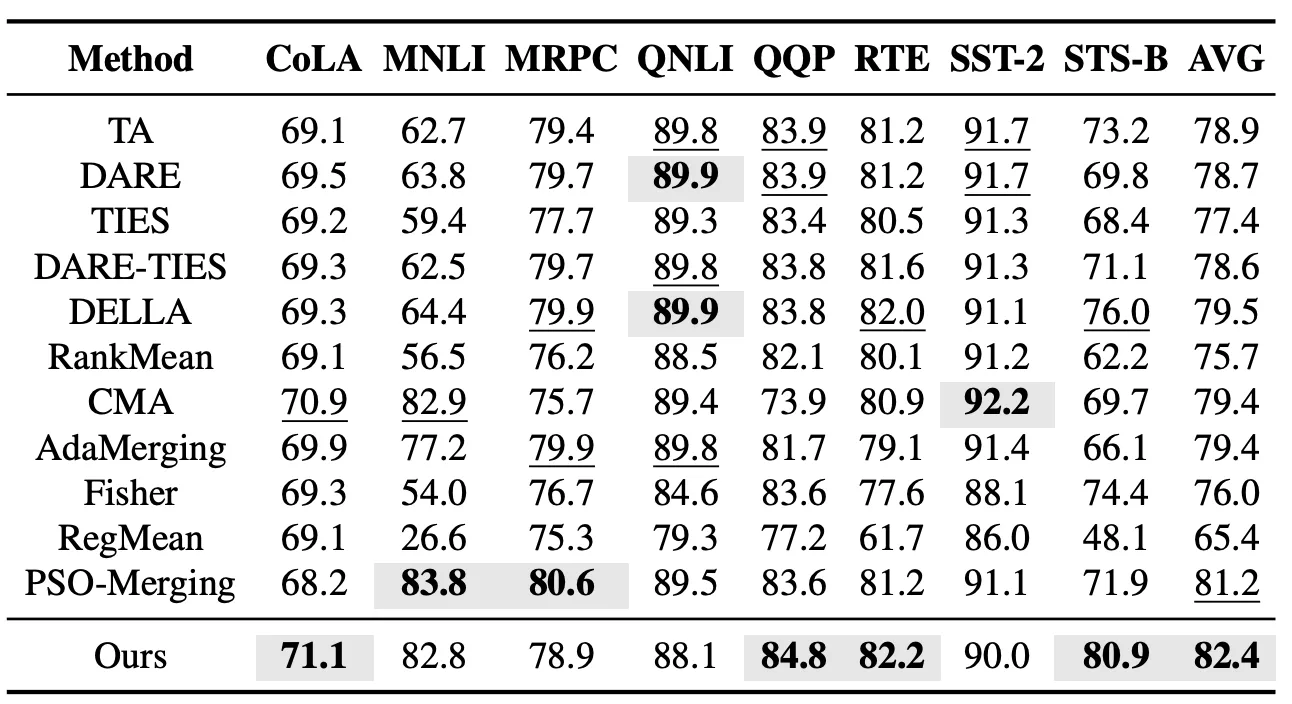
En la configuración de tareas vistas, evaluamos primero el efecto de fusión de modelos de EvoGM en las tareas de la serie GLUE. Este experimento abarca 8 tareas de comprensión del lenguaje —CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2 y STS-B— y compara EvoGM con métodos representativos de fusión de modelos como Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging y PSO-Merging. Los resultados muestran que EvoGM supera en rendimiento medio en las 8 tareas al anterior mejor método, PSO-Merging.
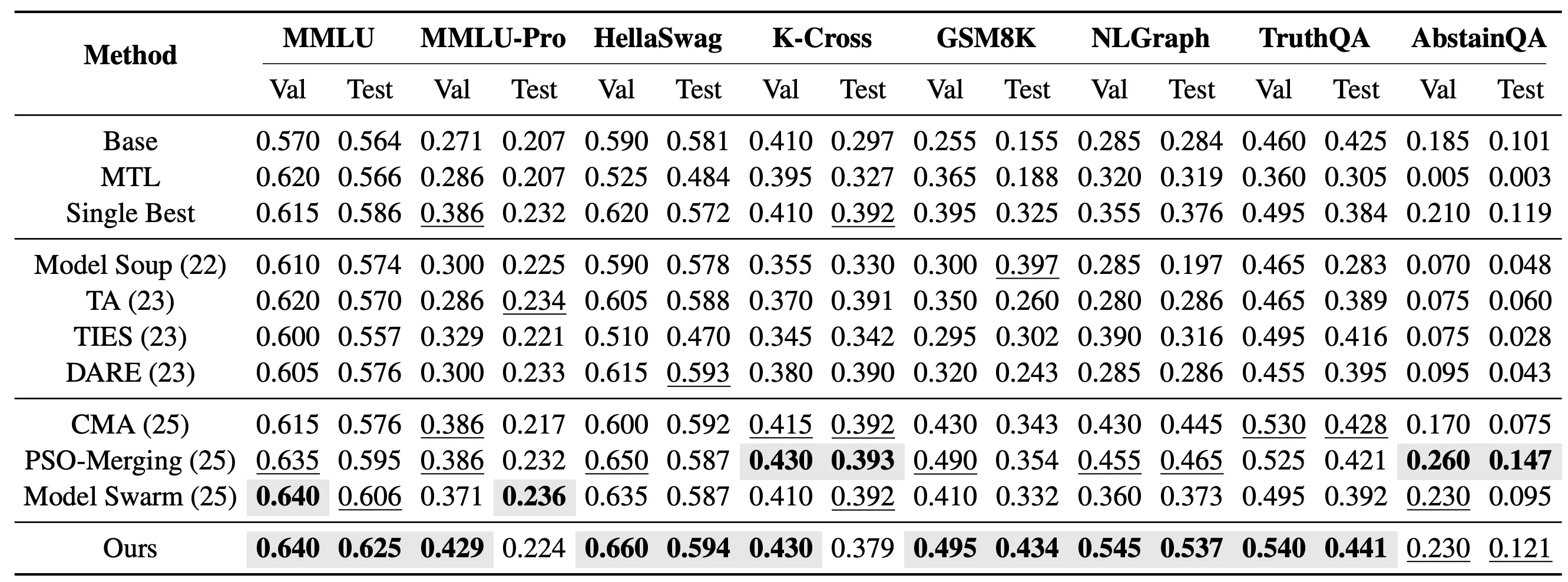
En la configuración más exigente de tareas no vistas, evaluamos además si EvoGM puede transferir las capacidades de modelos expertos existentes a nuevas tareas no incluidas en el ajuste fino de los expertos. En concreto, fusionamos 10 modelos expertos LoRA basados en Qwen2.5-1.5B y los probamos en 8 tareas no vistas: MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA y AbstainQA. Estas tareas abarcan comprensión del conocimiento, razonamiento complejo y fiabilidad en seguridad, entre otras dimensiones de capacidad, y reflejan mejor la capacidad de generalización de los métodos de fusión de modelos que las tareas vistas.
En la configuración de fusión no vista de tarea única, EvoGM busca un conjunto de coeficientes de fusión para cada tarea objetivo por separado. Los resultados muestran que EvoGM obtiene el mejor rendimiento de prueba en 5 de las 8 tareas de prueba.
Además de la fusión de tarea única, examinamos la configuración de fusión no vista multitarea. En esta configuración, el objetivo ya no es encontrar el modelo óptimo para cada tarea por separado, sino obtener un modelo fusionado unificado capaz de cubrir simultáneamente las 8 tareas no vistas. Los resultados indican que, en la fusión no vista multitarea, EvoGM obtiene el mejor rendimiento medio de prueba entre todos los métodos de fusión.
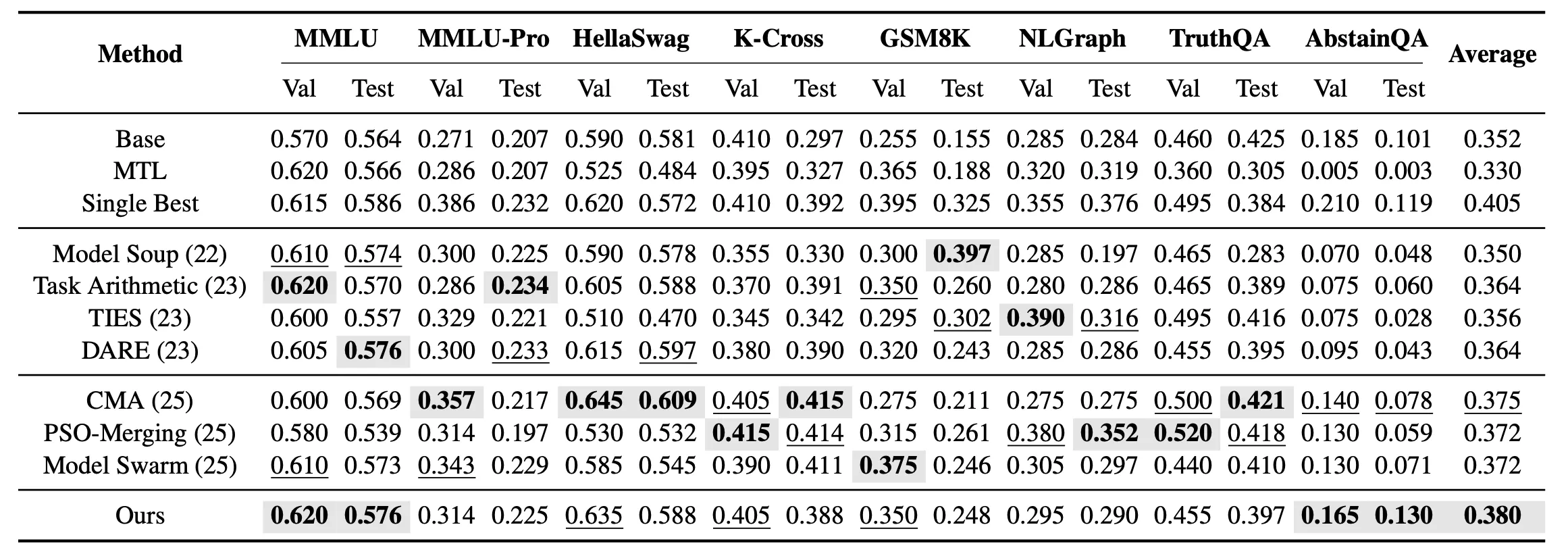
Los resultados muestran que EvoGM logra un rendimiento de generalización global más sólido tanto en fusión de tarea única como en configuración multitarea, superando a los métodos existentes de fusión de modelos en múltiples tareas relacionadas con conocimiento, razonamiento y seguridad.
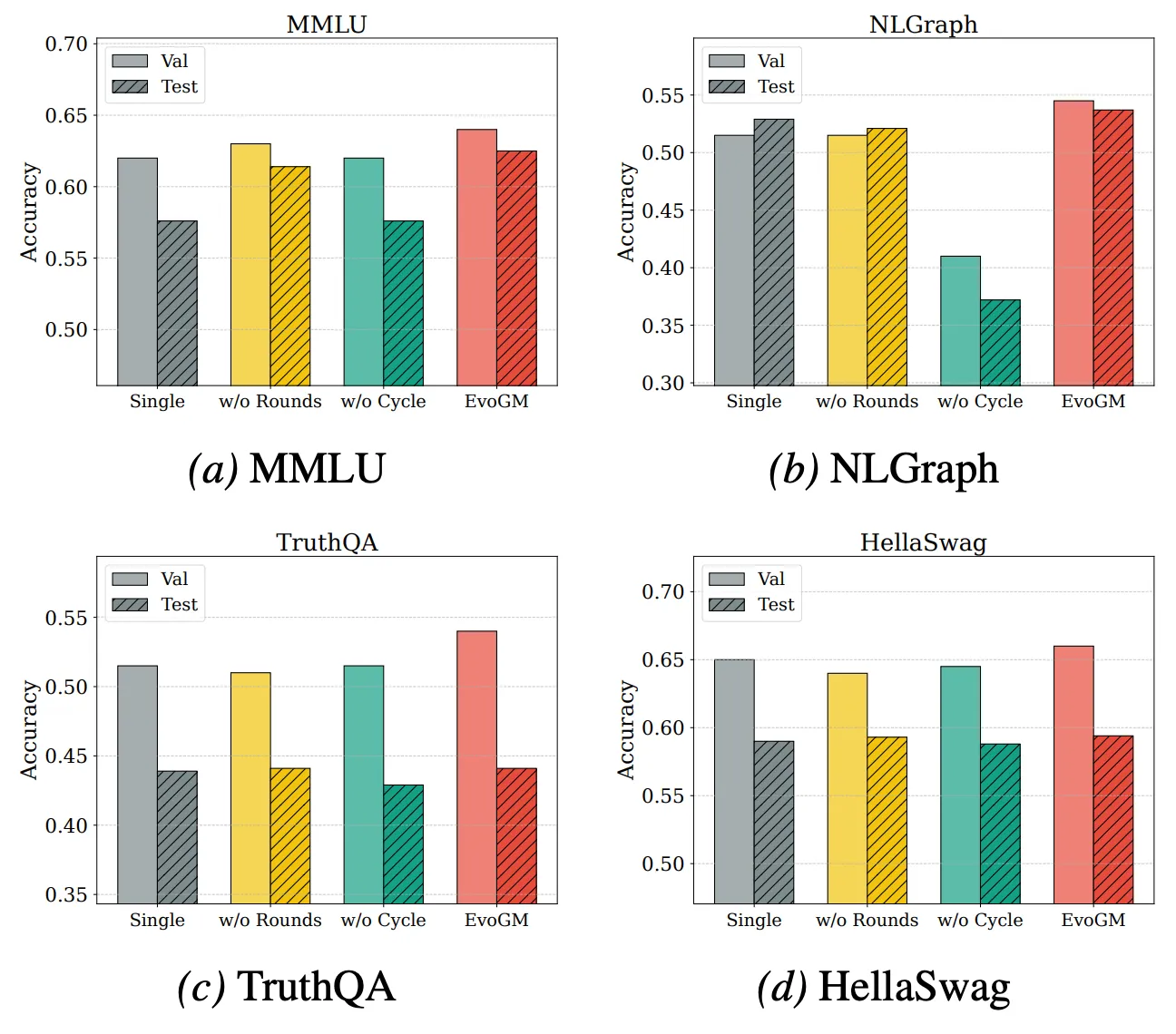
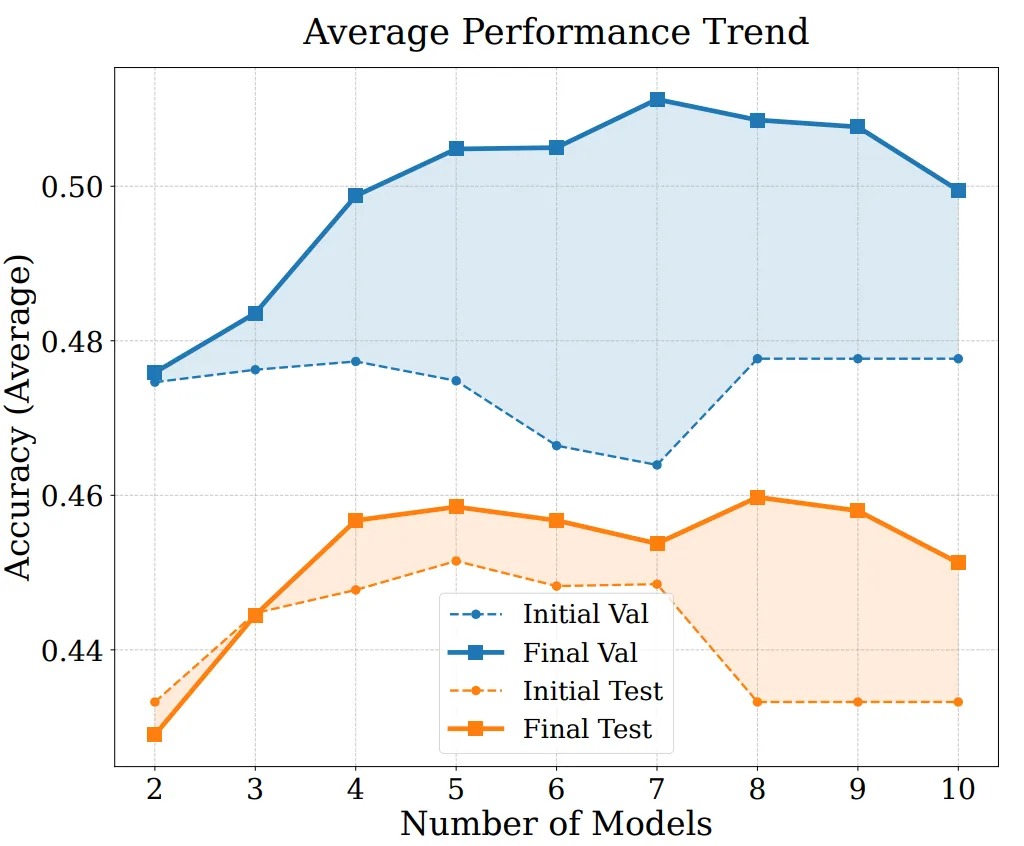
Para analizar más a fondo el origen del rendimiento de EvoGM y su capacidad de escalado, realizamos experimentos de ablación y de fusión con distintos números de modelos. Los resultados indican que EvoGM completo obtiene siempre el mejor rendimiento o el más estable; al eliminar componentes clave, el rendimiento disminuye en distintos grados, lo que demuestra que su ventaja proviene principalmente del mecanismo de evolución generativa, y no de una simple búsqueda aleatoria o de más rondas de búsqueda. Al mismo tiempo, cuando aumenta el número de modelos expertos participantes en la fusión, EvoGM mantiene un buen rendimiento y muestra una tendencia de mejora estable, lo que indica que puede hacer frente de forma eficaz a espacios de fusión más grandes y complejos, aprovechar plenamente las capacidades complementarias entre distintos modelos expertos y presenta una buena escalabilidad.
VII. De EvoGO a EvoGM: extensión del pensamiento evolutivo generativo
Desde una perspectiva más amplia, EvoGM puede entenderse como una extensión de la idea de EvoGO a la fusión de modelos de gran escala. EvoGO se centra en cómo hacer que la optimización evolutiva pase de depender de operadores de cruce, mutación y perturbación diseñados manualmente a aprender automáticamente, mediante modelos generativos a partir de datos históricos de búsqueda, nuevas formas de generar soluciones. Es decir, la búsqueda evolutiva deja de ser solo «generar candidatos al azar y filtrar», y empieza a aprender «cómo generar candidatos más prometedores».
EvoGM lleva esta idea al escenario de fusión de modelos de gran escala. Aquí, los candidatos ya no son variables numéricas de un problema de optimización general, sino conjuntos de coeficientes de fusión; una evaluación ya no es simplemente calcular una función objetivo, sino construir un modelo fusionado y validar su rendimiento en tareas downstream. Por tanto, EvoGM reformula en la práctica la fusión de modelos como un problema de optimización generativa: cómo aprender de resultados históricos de evaluación las leyes de combinación de capacidades entre modelos expertos y generar configuraciones de fusión superiores.
Esto distingue claramente a EvoGM de los métodos de fusión de modelos basados en búsqueda tradicional. Los métodos tradicionales suelen utilizar los resultados de validación solo para ordenar y filtrar, mientras que EvoGM los convierte además en señales de entrenamiento. Las configuraciones de bajo rendimiento no se descartan simplemente, sino que se emparejan con configuraciones de alto rendimiento en pares winner-loser para entrenar al generador a aprender la dirección evolutiva de configuraciones malas a buenas.
De EvoGO a EvoGM, en esencia se pasa de «aprender a optimizar candidatos» a «dejar que la estrategia de fusión de modelos de gran escala evolucione de forma autónoma en la población». Esto no solo libera la fusión de modelos de reglas empíricas y perturbaciones aleatorias, sino que también ofrece una nueva perspectiva: las capacidades de los modelos de gran escala pueden fusionarse, y la propia estrategia de fusión también puede aprender continuamente a partir de la retroalimentación poblacional.
VIII. Conclusiones y perspectivas
A medida que aumentan los modelos expertos, modelos LoRA y modelos de tarea en el ecosistema de código abierto, la cuestión clave del futuro puede no ser solo «cómo entrenar un modelo nuevo», sino «cómo combinar eficientemente las capacidades de modelos existentes». EvoGM ofrece una nueva respuesta: sin reentrenar los modelos de gran escala participantes en la fusión, aprende mediante evolución generativa a partir de retroalimentación limitada de validación y completa de forma autónoma la construcción de la población candidata, la generación de esquemas de fusión, la evaluación y selección, y la actualización de la base de expertos. En pocas palabras, EvoGM lleva la fusión de modelos de «ajustar coeficientes por experiencia» a «dejar que la estrategia de fusión aprenda y evolucione por sí misma». Esto también significa que la reutilización de capacidades de modelos de gran escala puede entrar en una nueva fase: no reentrenar un modelo cada vez que surge una nueva tarea, sino dejar que los modelos expertos existentes combinen continuamente, mediante evolución poblacional y fusión autónoma, modelos más adecuados para nuevas tareas.
Código abierto / Comunidad
📄 Artículo: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 Proyecto upstream (EvoX):
https://github.com/EMI-Group/evox 🌐 Grupo QQ:
297969717
