iStratDE:GPU 運算 x 超大族群,釋放差分演化的全部潛力

差分演化(DE)對策略選擇高度敏感。現有的大多數 DE 變體透過自適應機制或越來越精密的控制結構追求更好的效能。然而,雖然動態自適應已被廣泛研究,靜態策略多樣性的結構性優勢卻鮮少受到關注。
為了填補這一空白,EvoX 團隊研究了個體層級的策略多樣性如何影響 DE 的搜尋動態與最佳化效能,並提出了一種極簡變體:iStratDE(Individual-Level Strategy Diversity Differential Evolution)。其核心概念非常簡單:在初始化時,每個個體被指定自己的突變與交叉策略,且該指定在整個演化過程中保持不變。透過在個體層級引入多樣性——同時捨棄複雜的自適應與回饋迴路——iStratDE 在族群中創造了持久的行為異質性。
這一特性在大族群中尤其強大。由於演算法的設計本身就無需通訊,它天然支援高效的平行執行,並能順暢地擴展到 GPU 環境。團隊還在標準可達性假設下提供了收斂分析,建立了最佳適應度的幾乎確定收斂性。在 CEC2022 基準測試套件和機器人控制任務上的大量實驗顯示,iStratDE 能夠匹配甚至超越主流的自適應 DE 變體。原始碼已在 GitHub 上公開釋出:https://github.com/EMI-Group/istratde
背景:演化計算的複雜性陷阱
DE 長期以來一直是連續最佳化最有效的工具之一,因為它擁有簡潔的運算子和強大的搜尋能力。然而,其效能高度依賴於突變策略以及控制參數(如 F 和 CR)的選擇。根據「沒有免費午餐」定理,沒有任何單一配置能在所有問題上占據優勢。
在過去二十年中,主流的因應方式是讓 DE 變得越來越具自適應性。從 SaDE 到 LSHADE 家族,演算法透過維護歷史檔案、估計策略成功率,以及在族群層級調整參數,變得越來越「智慧」。但這種智慧是有代價的。集中式控制邏輯引入了大量的計算負擔,更重要的是,嚴重的同步障礙。在 GPU 平行運算的時代,這種對全域資訊交換的依賴往往導致硬體利用率低下,使演算法無法充分利用可用的運算資源。
打破僵局:極簡主義與結構多樣性
是否有可能在保留 DE 極簡本質的同時,達到複雜自適應變體的穩健性——甚至更強的效能?
EvoX 團隊以一個反直覺的提案回答了這個問題:iStratDE。iStratDE 並非試圖讓演算法在執行過程中變得「更聰明」,而是從一開始就賦予族群最大的多樣性。在分散式 GPU 加速的 EvoX 框架支援下,iStratDE 證明了大規模平行演化可以透過簡單的個體層級策略指定來大幅增強,完全不需要引入任何自適應機制。
什麼是 iStratDE?
iStratDE 的設計理念可以概括為**「不同個體,不同角色」**。
在傳統的 DE 變體中,策略通常在族群層級定義或自適應調整。而在 iStratDE 中,策略多樣性是在個體層級引入的:
- 一次指定,終身不變。 在初始化時,每個個體被隨機指定一個獨立的突變-交叉策略和一組控制參數。
- 去中心化執行。 一旦指定,這些策略在整個演化過程中保持不變。每個個體按照自己的規則集進行搜尋,無需向中央控制器報告或等待其他個體的回饋。
- 內在平行性。 由於個體之間不透過複雜的同步機制相互依賴,iStratDE 消除了通訊負擔,並自然地映射到 GPU 的 SIMT 架構。
如果說傳統的自適應 DE 像是一支由指揮官集中協調戰術的軍隊,那麼 iStratDE 更像是一個生態系統。某些個體天生適合遠距離探索,而另一些則更擅長局部開發。這種異質性不僅提供了對抗過早收斂的冗餘機制,還能透過非同步貢獻讓族群穩定地朝更好的解前進。
為什麼 iStratDE 有效?
儘管設計簡潔,iStratDE 在 CEC2022 基準測試套件和 Brax 機器人控制任務上都表現出色。兩個機制尤為重要:
- 隱含的菁英機制。 並非每種策略都適合每個問題,但在足夠大的族群中,某些個體恰好會獲得高度相容的配置。這些「菁英」迅速崛起,引導搜尋朝高品質區域前進。
- 非同步收斂。 不同的策略以不同的速度收斂。某些個體在早期進行積極的突破,而另一些則在後期更穩定地改進。這種收斂節奏的多樣性有助於防止族群過早陷入局部最優。
iStratDE 的核心優勢
透過引入個體層級的策略多樣性,iStratDE 提供了幾項重大優勢:
- 極致的結構簡潔性。 移除了歷史檔案、參數學習模組和額外的超參數,讓 DE 回歸乾淨且高度可重現的形式。
- 卓越的 GPU 效率。 得益於無通訊設計,iStratDE 在 GPU 上實現了接近線性的加速,能夠驅動超過 100,000 個個體的族群。
- 族群越大效能越好。 與許多傳統 DE 變體在族群過大時常遭遇效率瓶頸不同,iStratDE 直接受益於規模:更多的個體意味著更豐富的多樣性、更廣泛的策略覆蓋和更強的搜尋效能。
- 理論支撐。 幾乎確定收斂的結果為這種極簡設計提供了堅實的數學基礎。
實作細節
iStratDE 將張量化與 GPU 加速緊密整合。其效率源自獨特的通訊阻斷設計:不同於依賴集中式統計的自適應演算法,iStratDE 個體的策略是完全獨立的,消除了同步需求,與 GPU SIMT 模型完美契合。
在 EvoX 框架的支援下,iStratDE 能夠高效地平行演化 100,000 個以上的個體族群。這種張量化的獨立性不僅提高了大規模最佳化的吞吐量,還能透過大量的並行探索實現搜尋空間的廣泛覆蓋。
策略池建構
為了在族群中創造多樣性,團隊建構了一個包含 192 種配置的策略池。每種策略遵循 DE/bl-to-br/dn/cs 的形式,由模組化元素組成:
- 左基底向量,從
rand、best、pbest或current中選取 - 右基底向量,同樣從
rand、best、pbest或current中選取 - 差分向量數量,從
{1, 2, 3, 4}中選取 - 交叉方案,包括二項式交叉、指數交叉和算術交叉
此外,每個個體的縮放因子 F 和交叉率 CR 分別從 U(0, 1) 中獨立取樣。透過這些組件的不同組合,iStratDE 產生了從高度探索性到強力開發性的廣泛搜尋行為。
架構概覽
iStratDE 遵循一個極為簡潔的去中心化工作流程:
- 初始指定。 系統初始化族群位置,並隨機為每個個體指定專屬的策略和參數組。
- 持久演化。 在最佳化迴圈中,每個個體始終按照其被指定的配置執行突變和交叉。解在演化,但策略不會改變。
- 隱含整合。 由於族群既龐大又異質,iStratDE 不需要明確的自適應協調。自然的分工自行浮現:探索導向的個體發現新區域,而開發導向的個體精煉有潛力的解。
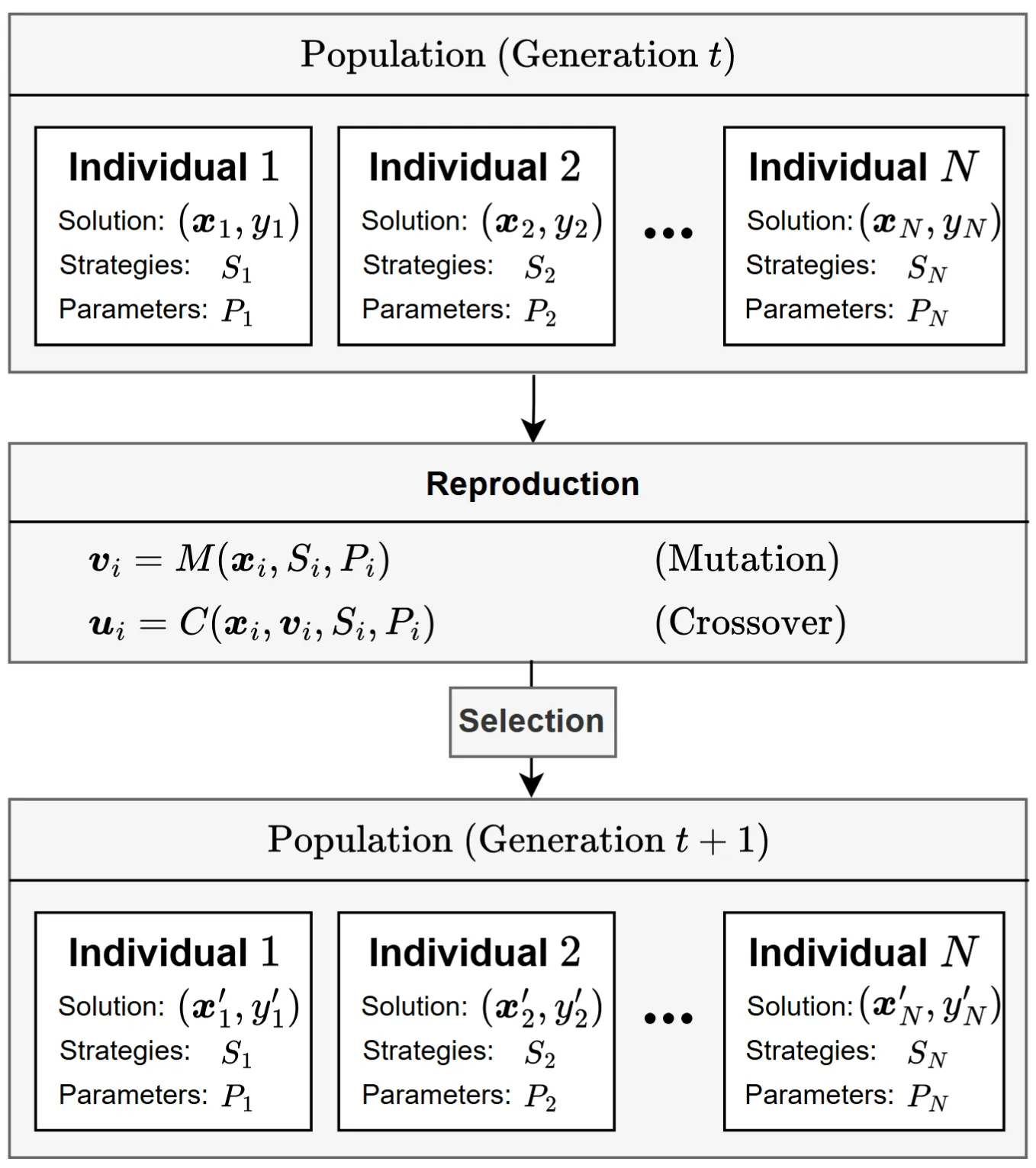 圖 1. iStratDE 框架,展示初始化、去中心化策略指定和持久演化。
圖 1. iStratDE 框架,展示初始化、去中心化策略指定和持久演化。
實驗亮點
為了在真正的大規模平行設定下評估 iStratDE,EvoX 團隊在固定時間預算下進行了系統性實驗,這比傳統的固定函數評估次數更能反映真實的高效能運算條件。
實驗包括:
- 超大族群壓力測試,擴展至 100,000 個個體
- CEC2022 基準測試,在 60 秒內將 iStratDE 與主流自適應 DE 變體及頂尖競賽方法進行比較
- 族群可擴展性分析,顯示 iStratDE 隨著族群增長持續改善,而傳統方法則遇到規模瓶頸
- 機器人控制任務,使用大族群在 Brax 中最佳化高維神經控制器
1. 固定時間預算下的 CEC2022 基準測試
在相同的 60 秒預算下,傳統自適應演算法因其序列邏輯和同步負擔而受限於約 100 的經典族群大小。相比之下,iStratDE 專為 GPU SIMT 執行而設計,能夠高效驅動 100,000 個個體的族群。
因此,iStratDE 據報在相同時間窗口內執行了高達 10^9 次函數評估,達到傳統方法約 100 倍的計算吞吐量。在大多數基準函數上,這種極簡結構與大規模平行性的結合帶來了更強的收斂速度和最終精確度。
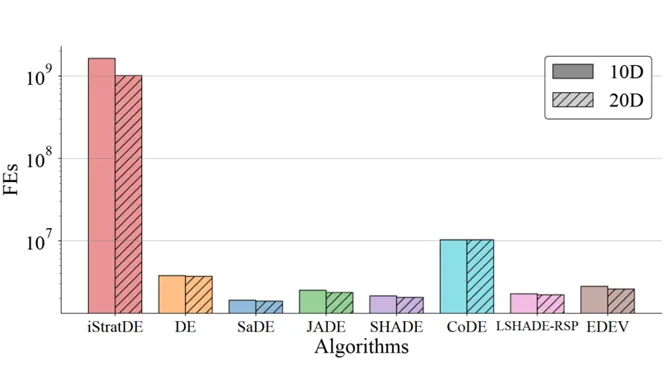 圖 2. 固定時間預算下的函數評估吞吐量比較。
圖 2. 固定時間預算下的函數評估吞吐量比較。
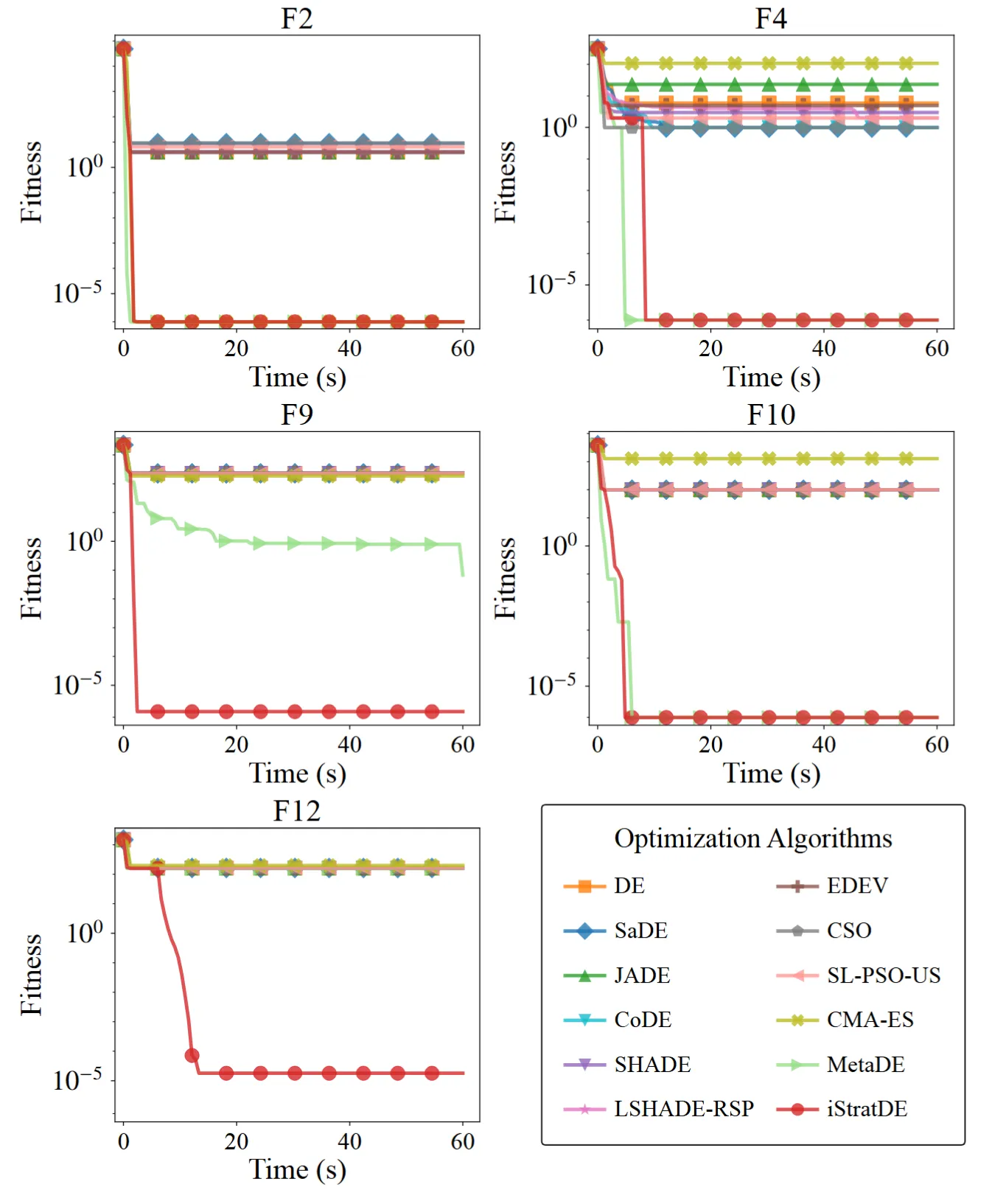 圖 3. 10 維 CEC2022 基準測試套件上的最佳化效能比較。
圖 3. 10 維 CEC2022 基準測試套件上的最佳化效能比較。
2. 高維空間中的穩健性
團隊進一步在具有挑戰性的 200 維旋轉和平移版本的 Schwefel、Rastrigin 和 Ackley 函數上評估 iStratDE。傳統自適應 DE 方法(如 JADE 和 SHADE)以及 CMA-ES 深受維度災難的影響,往往早期就停滯不前。
相比之下,iStratDE 透過大規模平行性與策略多樣性的結合,維持了強勁的搜尋動力。它不僅超越了 CSO 等專門的基準方法,還展現了與 MetaDE(一種近期的 GPU 學習式最佳化器)相當的穩健性。在 Ackley 等困難函數上,iStratDE 成功找到了全域最優解。
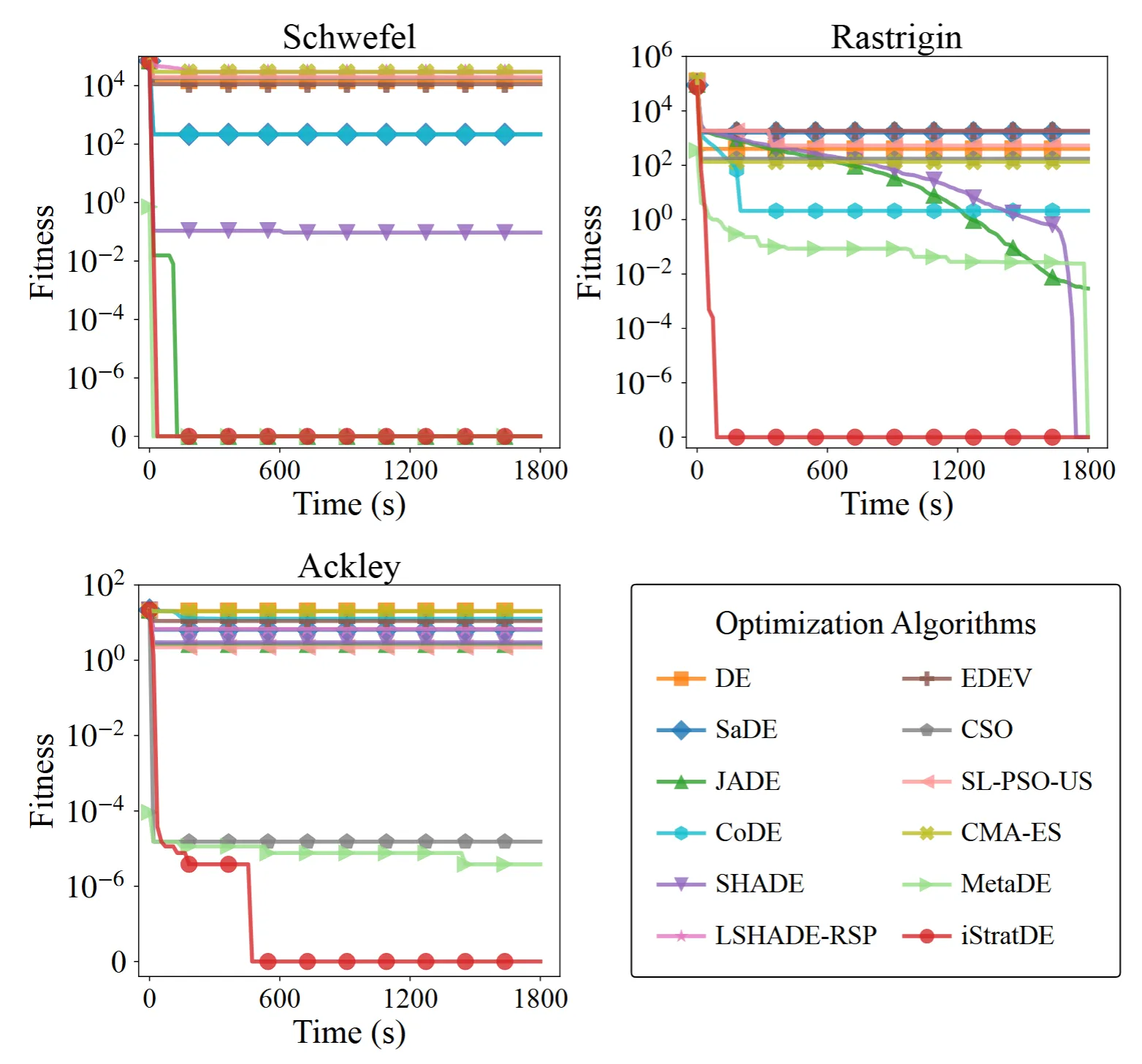 圖 4. 200 維平移旋轉基準問題上的效能比較。
圖 4. 200 維平移旋轉基準問題上的效能比較。
3. 族群可擴展性
最引人注目的發現之一是,iStratDE 打破了「單純擴大族群並不能持續改善 DE」的經典假設。當族群大小從 10^2 增長到 4 x 10^5 時,iStratDE 持續穩定改善,沒有明顯的飽和跡象。
相比之下,傳統自適應 DE 演算法通常在族群超過適度閾值後便不再受益,甚至可能因同步負擔而退化。這一結果表明,iStratDE 能夠將額外的運算資源直接轉化為更好的最佳化效能。
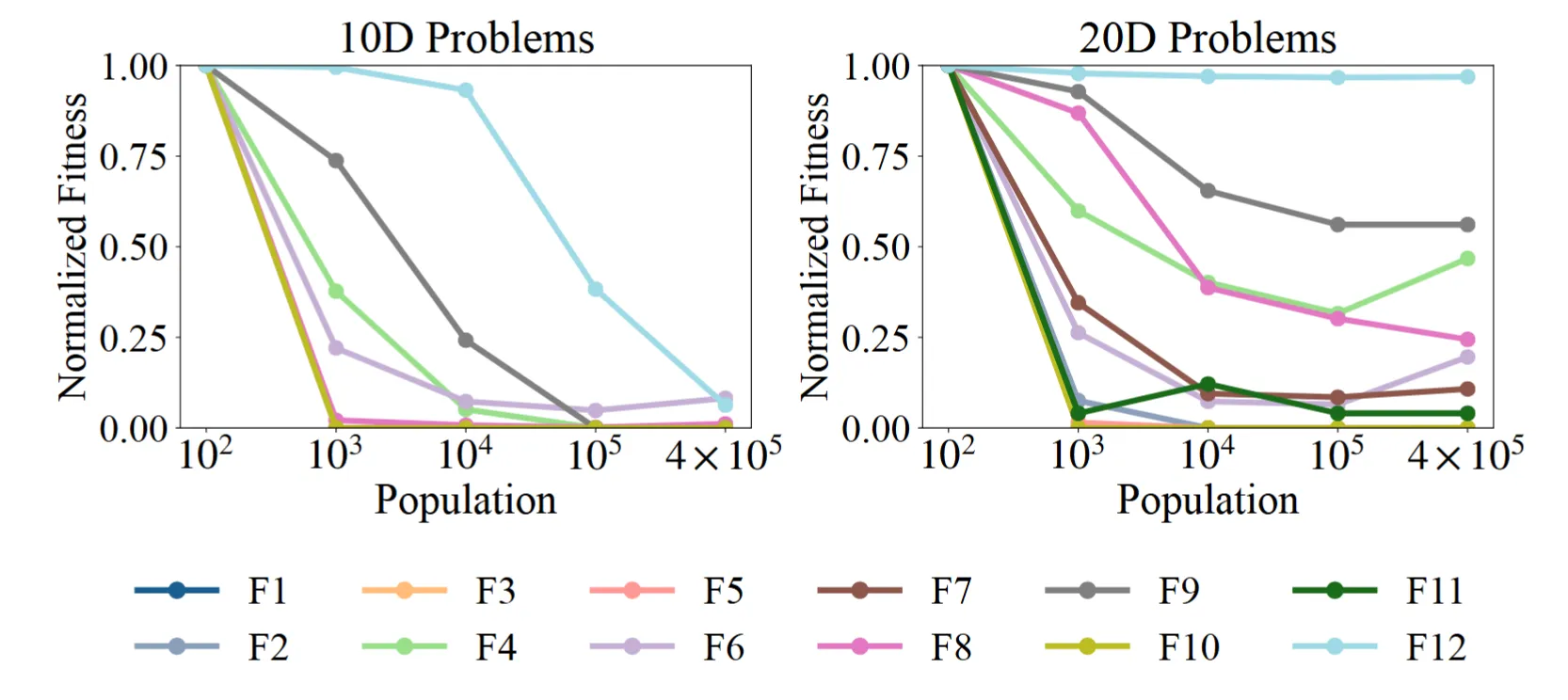 圖 5. iStratDE 在不同族群規模下的可擴展性分析。
圖 5. iStratDE 在不同族群規模下的可擴展性分析。
4. 與 CEC2022 頂尖競賽方法的比較
為了測試效能上限,團隊將 iStratDE 與 CEC2022 競賽排名最高的方法進行比較,包括 EA4eig、NL-SHADE-LBC 和 NL-SHADE-RSP。在相同的函數評估預算下,iStratDE 儘管結構遠為簡潔,仍保持高度競爭力。在多個困難的 10D 和 20D 函數上,它取得了與這些精密基準方法相當甚至更好的結果。
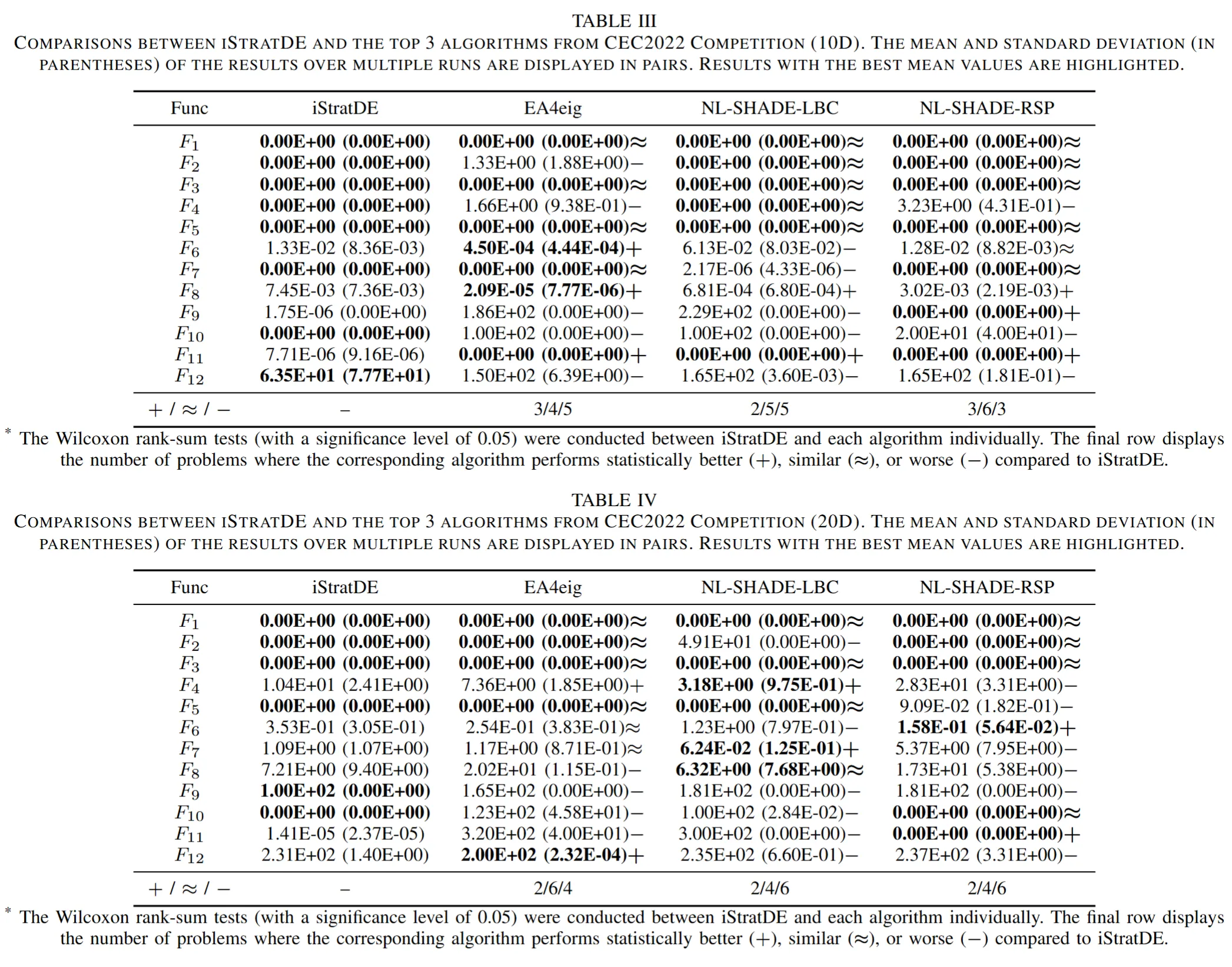 圖 6. iStratDE 與 CEC2022 競賽排名最高方法的比較。
圖 6. iStratDE 與 CEC2022 競賽排名最高方法的比較。
5. 真實應用:Brax 機器人控制
最後,團隊將 iStratDE 應用於 Brax 中的機器人控制任務,包括 Swimmer、Reacher 和 Hopper,目標是最佳化約 1,500 個參數的神經網路控制器。
使用 10,000 個個體的族群,iStratDE 與 CMA-ES、CSO 和傳統 DE 變體進行比較。在 Swimmer 和 Hopper 等任務上,iStratDE 快速發現高回報策略,展現出比 CMA-ES 和 LSHADE 等方法更強的收斂性。這證明 iStratDE 不僅在理論上優雅,在高維黑箱最佳化的實際應用中也同樣有效。
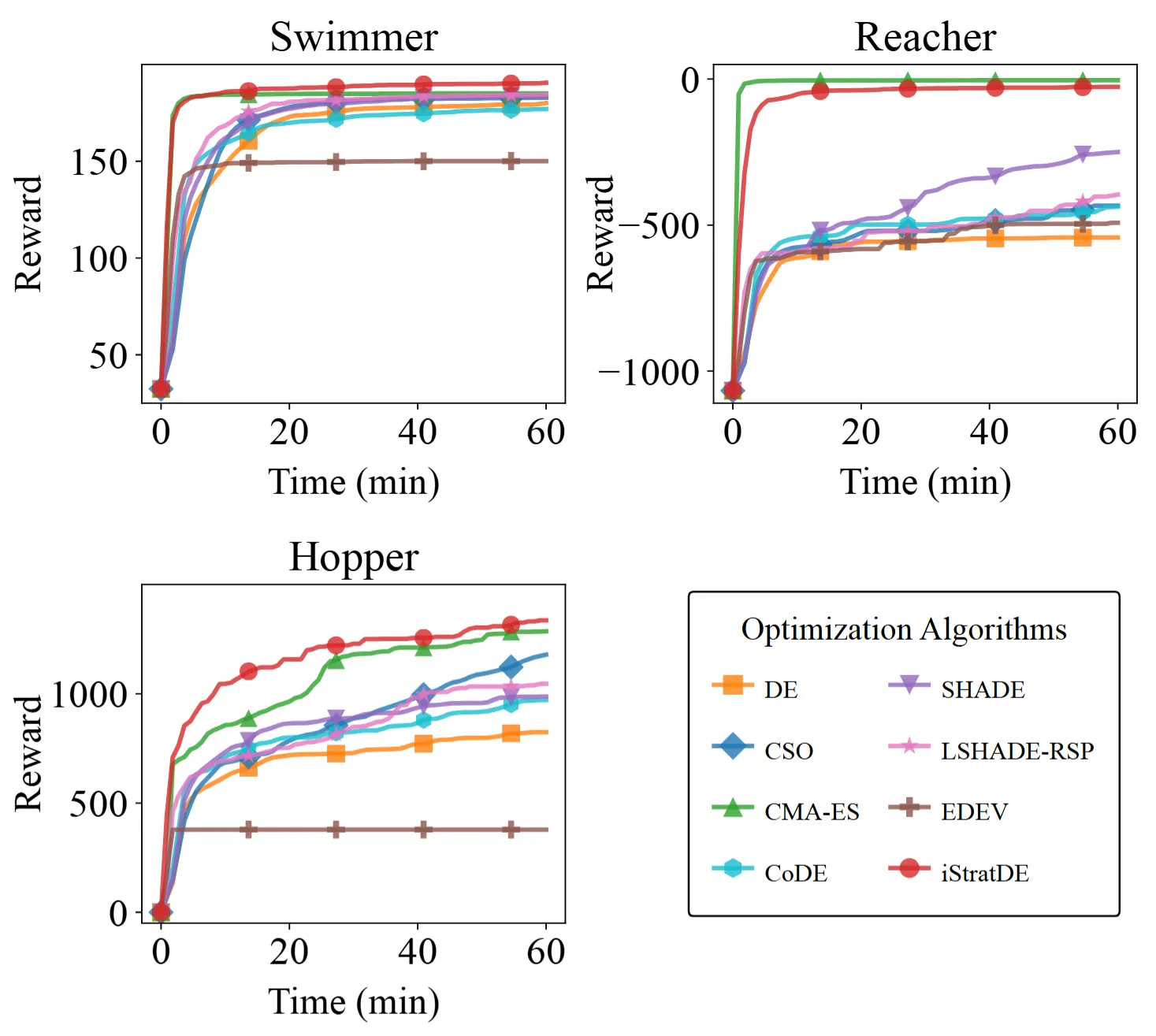 圖 7. iStratDE 在三個 Brax 控制環境中的收斂曲線。
圖 7. iStratDE 在三個 Brax 控制環境中的收斂曲線。
結論與展望
iStratDE 是對演算法本質的回歸。它不是堆疊越來越複雜的自適應邏輯,而是從個體層級的策略多樣性中建構強大的搜尋能力。透過充分釋放現代 GPU 的平行潛力,iStratDE 揭示了結構多樣性在多峰和高維最佳化中的力量。
結果顯示,iStratDE 在基準測試和真實控制任務上都能與領先的自適應 DE 變體競爭,甚至在某些場景下超越它們。更廣泛地說,這項工作突顯了一個重要的設計原則:複雜性不是通往高效能的唯一路徑;族群異質性本身就可以成為演化的強大引擎。
這種去中心化的極簡範式為演化演算法設計開闢了新方向。它不依賴精密的集中式協調,而是展示了具有多樣搜尋行為的獨立個體如何能夠共同產生智慧且可擴展的最佳化動態。
開源程式碼 / 社群資源
論文: https://arxiv.org/abs/2602.01147
GitHub: https://github.com/EMI-Group/istratde
上游專案(EvoX): https://github.com/EMI-Group/evox
QQ 群: 297969717
 EvoX QQ 社群群組 QR code。
EvoX QQ 社群群組 QR code。