iStratDE: GPUコンピューティング × 超大規模集団で差分進化の潜在能力を最大限に引き出す

差分進化(DE)は戦略選択に非常に敏感です。既存のDE変種の多くは、適応メカニズムやより精巧な制御構造を通じてより高い性能を追求しています。しかし、動的適応が広く研究されてきた一方で、静的な戦略多様性の構造的利点にはあまり注目されてきませんでした。
このギャップに対処するため、EvoXチームは個体レベルの戦略多様性がDEの探索ダイナミクスと最適化性能にどのように影響するかを調査し、ミニマリストな変種 iStratDE(Individual-Level Strategy Diversity Differential Evolution) を提案しました。中核となるアイデアはシンプルです:初期化時に各個体に独自の突然変異・交叉戦略を割り当て、その割り当ては進化の全過程を通じて固定されます。複雑な適応やフィードバックループを排除しつつ、個体レベルで多様性を導入することで、iStratDEは集団全体にわたる持続的な行動の異質性を生み出します。
この特性は大規模集団において特に強力になります。アルゴリズムは設計上通信不要であるため、効率的な並列実行を自然にサポートし、GPU環境にスムーズにスケーリングできます。チームはまた、標準的な到達可能性の仮定の下での収束解析を提供し、最良適応度のほぼ確実な収束を確立しました。CEC2022ベンチマークスイートおよびロボット制御タスクにおける広範な実験は、iStratDEが主要な適応型DE変種と同等かそれ以上の性能を達成できることを示しています。ソースコードはGitHub上で公開されています:https://github.com/EMI-Group/istratde
背景:複雑性の罠に陥る進化計算
DEは、そのシンプルなオペレータと強力な探索能力により、連続最適化において最も効果的なツールの一つであり続けてきました。しかし、その性能は突然変異戦略およびFやCRなどの制御パラメータの選択に大きく依存します。ノーフリーランチ定理によれば、あらゆる問題に対して支配的な単一の設定は存在しません。
過去20年間、主流の対応策はDEをますます適応的にすることでした。SaDEからLSHADEファミリーに至るまで、アルゴリズムは履歴アーカイブの維持、戦略成功率の推定、集団レベルでのパラメータ調整によって、より「知的」になってきました。しかし、この知能にはコストが伴います。中央集権的な制御ロジックは膨大な計算オーバーヘッドを引き起こし、さらに重要なことに、深刻な同期バリアをもたらします。GPU並列処理の時代において、このようなグローバル情報交換への依存は、ハードウェア利用率の低下を招き、利用可能な計算資源の十分な活用を妨げることが多いのです。
行き詰まりを打破する:ミニマリズムと構造的多様性
DEのミニマリストな本質を保ちつつ、複雑な適応型変種の堅牢性、あるいはそれ以上の性能を達成することは可能でしょうか?
EvoXチームはこの問いに対し、直感に反する提案で答えます:iStratDE。実行中にアルゴリズムを「より賢く」しようとする代わりに、iStratDEは最初から集団に最大限の多様性を与えます。分散型のGPU加速EvoXフレームワークに支えられ、iStratDEは、適応メカニズムを一切導入することなく、個体レベルの戦略のシンプルな割り当てによって大規模並列進化を劇的に強化できることを示しています。
iStratDEとは?
iStratDEの哲学は**「異なる個体、異なる役割」**と要約できます。
従来のDE変種では、戦略は通常、集団レベルで定義または適応されます。iStratDEでは、戦略の多様性が個体レベルで導入されます:
- 一度割り当て、生涯固定。 初期化時に、各個体に独立した突然変異・交叉戦略と制御パラメータのセットがランダムに割り当てられます。
- 分散実行。 一度割り当てられると、これらの戦略は進化過程全体を通じて変更されません。各個体は中央制御装置に報告したり、他の個体からのフィードバックを待つことなく、自身のルールセットに従って探索を行います。
- 本質的な並列性。 個体間に複雑な同期を介した依存関係がないため、iStratDEは通信オーバーヘッドを排除し、GPUのSIMTアーキテクチャに自然にマッピングされます。
従来の適応型DEが司令官によって戦術が中央集権的に調整される軍隊に例えられるとすれば、iStratDEは生態系に似ています。一部の個体は長距離の探索に自然に適しており、他の個体は局所的な探索に優れています。この異質性は早期収束に対する冗長性を提供するだけでなく、集団が着実により良い解に向かって進み続けることを可能にする非同期的な貢献をもたらします。
なぜiStratDEは機能するのか?
そのシンプルさにもかかわらず、iStratDEはCEC2022ベンチマークスイートとBraxロボット制御タスクの両方で優れた性能を発揮します。特に2つのメカニズムが重要です:
- 暗黙的なエリート主義。 すべての戦略がすべての問題に適しているわけではありませんが、十分に大きな集団では、高い互換性のある設定を偶然受け取る個体が出現します。これらの「エリート」は急速に浮上し、探索を高品質な領域へと導きます。
- 非同期的な収束。 異なる戦略は異なる速度で収束します。初期に積極的な突破を果たす個体がいる一方、後半により着実に改善する個体もいます。この収束テンポの多様性は、集団が局所最適に早期に陥ることを防ぎます。
iStratDEの主要な利点
個体レベルの戦略多様性を導入することで、iStratDEはいくつかの大きな利点を提供します:
- 極めてシンプルな構造。 履歴アーカイブ、パラメータ学習モジュール、追加のハイパーパラメータを排除し、DEをクリーンで高い再現性を持つ形に戻します。
- 優れたGPU効率。 通信不要の設計により、iStratDEはGPU上でほぼ線形の加速を達成し、10万個体を超える集団を駆動できます。
- 集団が大きいほど性能向上。 多くの従来のDE変種が集団が大きくなると効率のボトルネックに悩まされるのに対し、iStratDEはスケールから直接恩恵を受けます:より多くの個体はより豊かな多様性、より広い戦略カバレッジ、そしてより強力な探索性能を意味します。
- 理論的裏付け。 ほぼ確実な収束の結果が、このミニマリストな設計に確固たる数学的基盤を提供します。
実装の詳細
iStratDEはテンソル化とGPU加速を緊密に統合しています。その効率は独特な通信遮断設計に由来します:中央集権的な統計に依存する適応アルゴリズムとは異なり、iStratDEの個体の戦略は完全に独立しており、同期要件を排除し、GPU SIMTモデルと完全に適合します。
EvoXフレームワークのサポートにより、iStratDEは10万個体以上の集団を効率的に並列で進化させることができます。このテンソル化された独立性は、大規模最適化のスループットを向上させるだけでなく、大規模な並行探索を通じて探索空間の広範なカバレッジを可能にします。
戦略プールの構成
集団全体に多様性を生み出すため、チームは192の設定からなる戦略プールを構築します。各戦略はDE/bl-to-br/dn/csの形式に従い、モジュラーな要素で構成されます:
- 左基底ベクトル:
rand、best、pbest、currentから選択 - 右基底ベクトル:同様に
rand、best、pbest、currentから選択 - 差分ベクトルの数:
{1, 2, 3, 4}から選択 - 交叉方式:二項交叉、指数交叉、算術交叉を含む
さらに、各個体のスケーリング因子Fと交叉率CRは**U(0, 1)**から独立にサンプリングされます。これらの要素の異なる組み合わせにより、iStratDEは高度に探索的なものから強力に搾取的なものまで、幅広い探索行動を生成します。
アーキテクチャ概要
iStratDEは極めてシンプルな分散ワークフローに従います:
- 初期割り当て。 システムは集団の位置を初期化し、各個体に専用の戦略とパラメータセットをランダムに割り当てます。
- 持続的進化。 最適化ループの間、各個体は常に割り当てられた設定に従って突然変異と交叉を実行します。解は進化しますが、戦略は変化しません。
- 暗黙的統合。 集団が大規模かつ異質であるため、iStratDEは明示的な適応調整を必要としません。探索指向の個体が新しい領域を発見し、搾取指向の個体が有望な解を洗練するという、自然な分業が出現します。
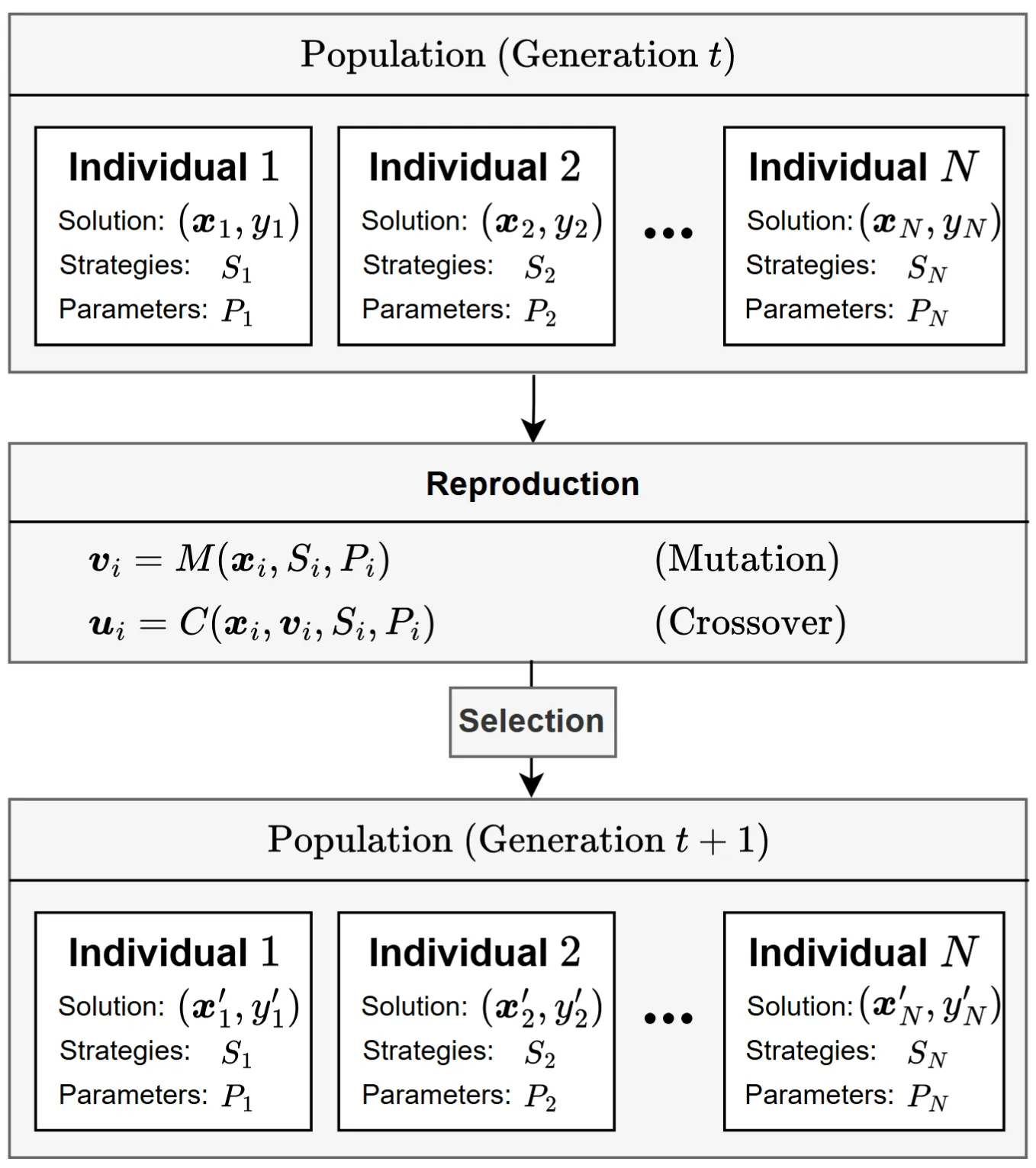 図1. iStratDEのフレームワーク。初期化、分散型戦略割り当て、持続的進化を示す。
図1. iStratDEのフレームワーク。初期化、分散型戦略割り当て、持続的進化を示す。
実験のハイライト
真の大規模並列環境でiStratDEを評価するため、EvoXチームは固定時間予算の下で体系的な実験を行いました。これは、従来の固定FE評価よりも、実際の高性能コンピューティング環境をより適切に反映しています。
実験内容:
- 超大規模集団ストレステスト:10万個体までスケーリング
- CEC2022ベンチマーク:60秒以内で主要な適応型DE変種およびトップコンペティション手法とiStratDEを比較
- 集団スケーラビリティ分析:iStratDEが集団の増加に伴い継続的に改善する一方、従来手法がスケールボトルネックに達することを示す
- ロボット制御タスク:Braxにおいて大規模集団で高次元ニューラルコントローラを最適化
1. 固定時間予算下のCEC2022ベンチマーク
同じ60秒の予算下で、従来の適応アルゴリズムはその逐次的ロジックと同期オーバーヘッドにより、約100の古典的な集団サイズに制約されたままです。対照的に、iStratDEはGPU SIMT実行のために特別に設計されており、10万個体の集団を効率的に駆動できます。
その結果、iStratDEは同じ時間枠内で最大10^9の関数評価を実行し、従来手法の約100倍の計算スループットに達すると報告されています。ほとんどのベンチマーク関数において、このミニマリストな構造と大規模並列処理の組み合わせは、より強力な収束速度と最終精度をもたらします。
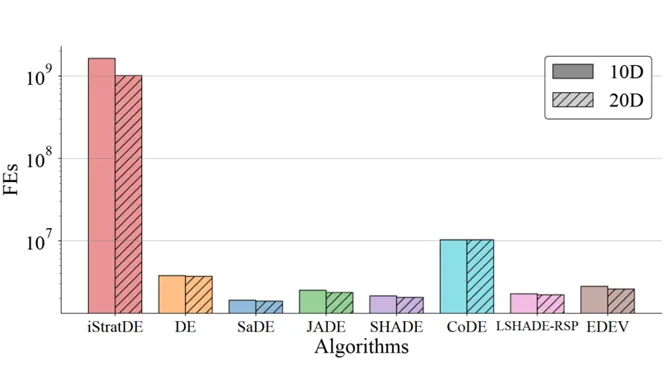 図2. 固定時間予算下での関数評価スループットの比較。
図2. 固定時間予算下での関数評価スループットの比較。
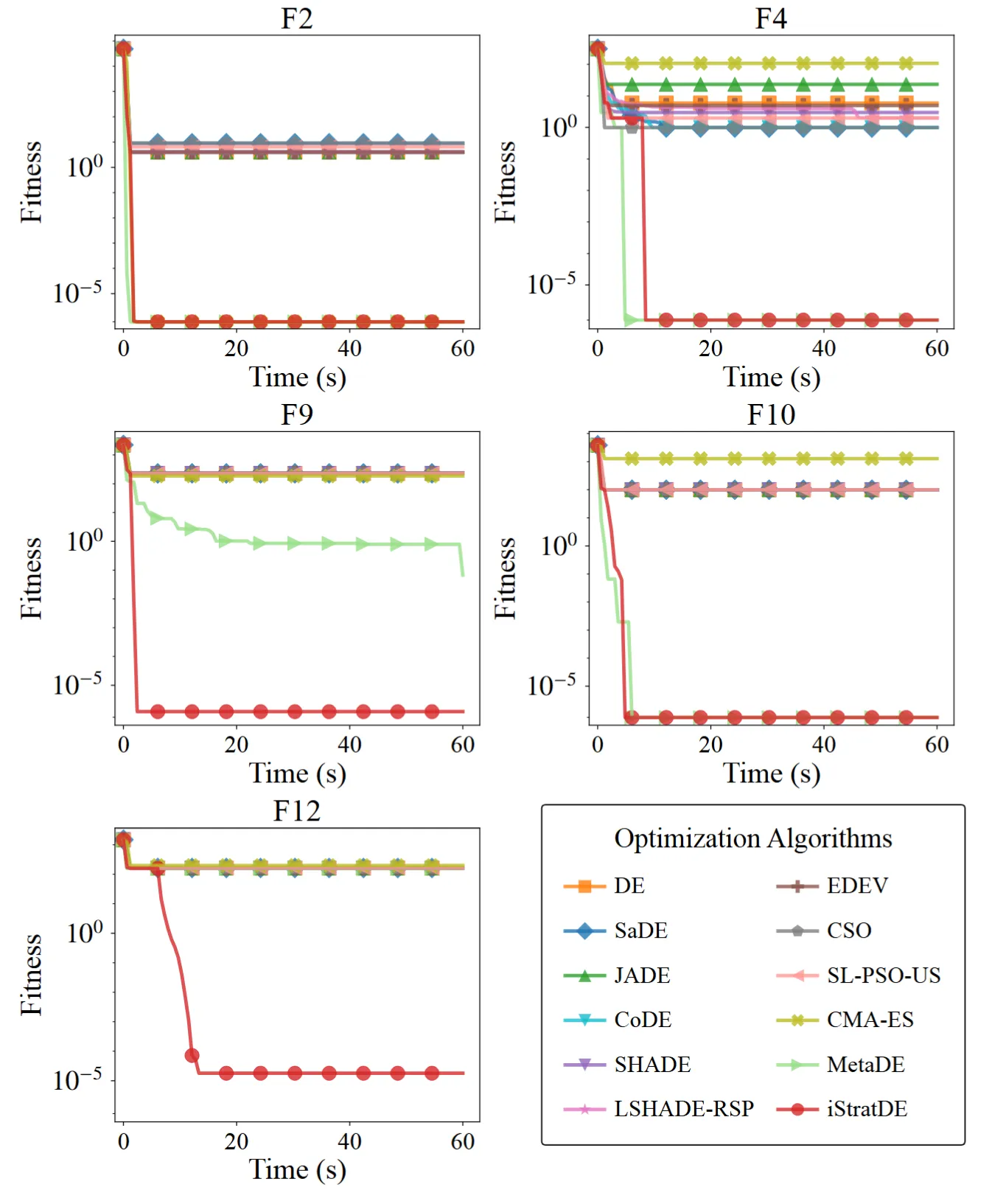 図3. 10次元CEC2022ベンチマークスイートにおける最適化性能の比較。
図3. 10次元CEC2022ベンチマークスイートにおける最適化性能の比較。
2. 高次元ランドスケープにおける堅牢性
チームはさらに、Schwefel、Rastrigin、Ackleyの困難な200次元の回転・シフト版でiStratDEを評価しています。JADEやSHADEなどの従来の適応型DE手法やCMA-ESは、次元の呪いの影響を強く受け、早期に停滞することが多くあります。
対照的に、iStratDEは大規模並列処理と戦略多様性の組み合わせにより、強力な探索の勢いを維持します。CSOなどの特化したベースラインを上回るだけでなく、最近のGPU学習ベースの最適化手法であるMetaDEに対しても競争力のある堅牢性を示します。Ackleyのような困難な関数では、iStratDEは大域最適解の発見に成功しています。
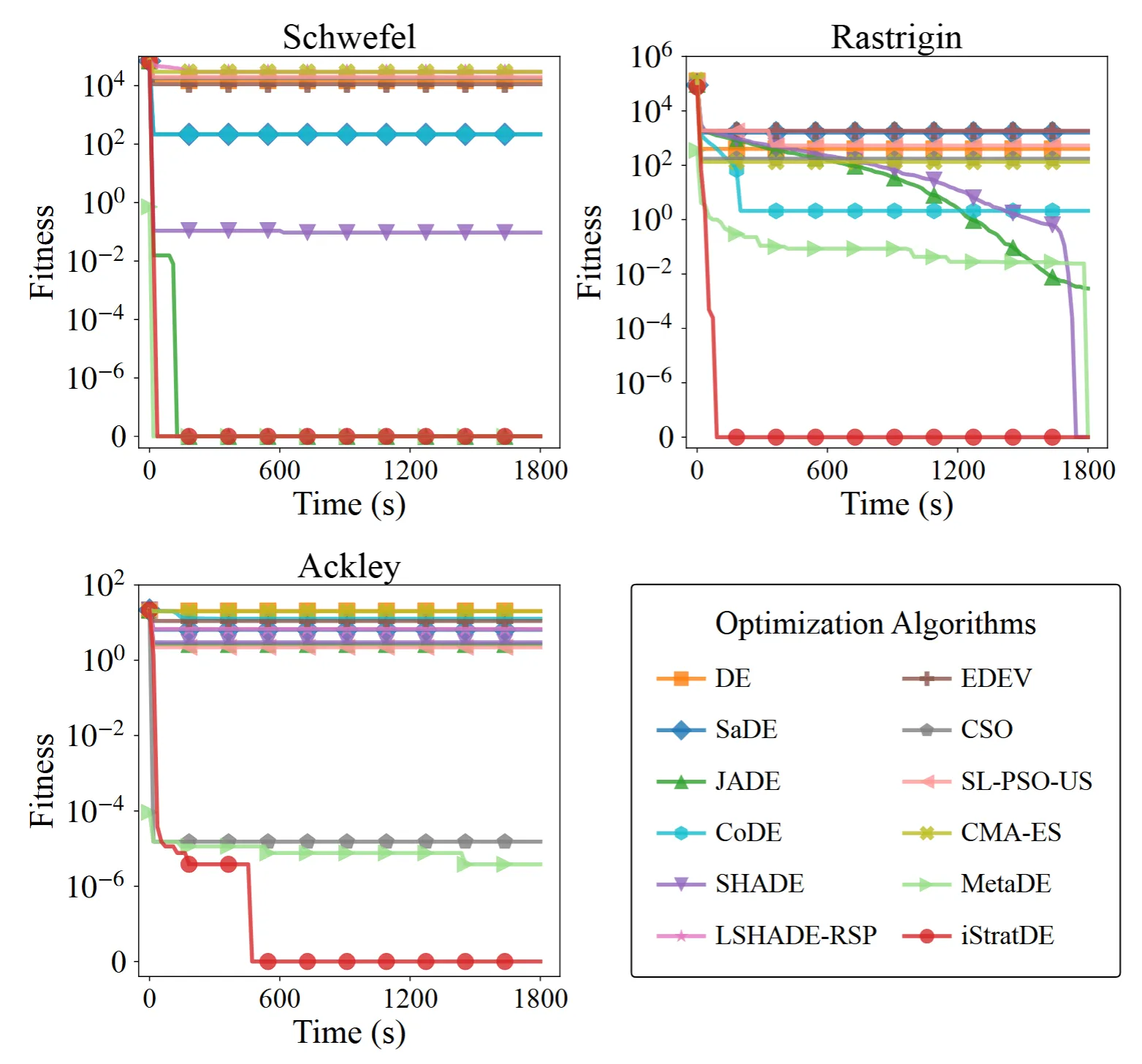 図4. 200次元のシフト・回転ベンチマーク問題における性能比較。
図4. 200次元のシフト・回転ベンチマーク問題における性能比較。
3. 集団スケーラビリティ
最も注目すべき発見の一つは、iStratDEが「集団を単純に拡大してもDEの改善が続かない」という古典的な仮定を覆すことです。集団サイズが10^2から4 x 10^5に増加しても、iStratDEは着実に改善を続け、飽和の明確な兆候は見られません。
対照的に、従来の適応型DEアルゴリズムは通常、集団が中程度の閾値を超えると恩恵を受けなくなり、同期オーバーヘッドにより性能が低下することさえあります。この結果は、iStratDEが追加の計算資源をより良い最適化性能に直接変換できることを示唆しています。
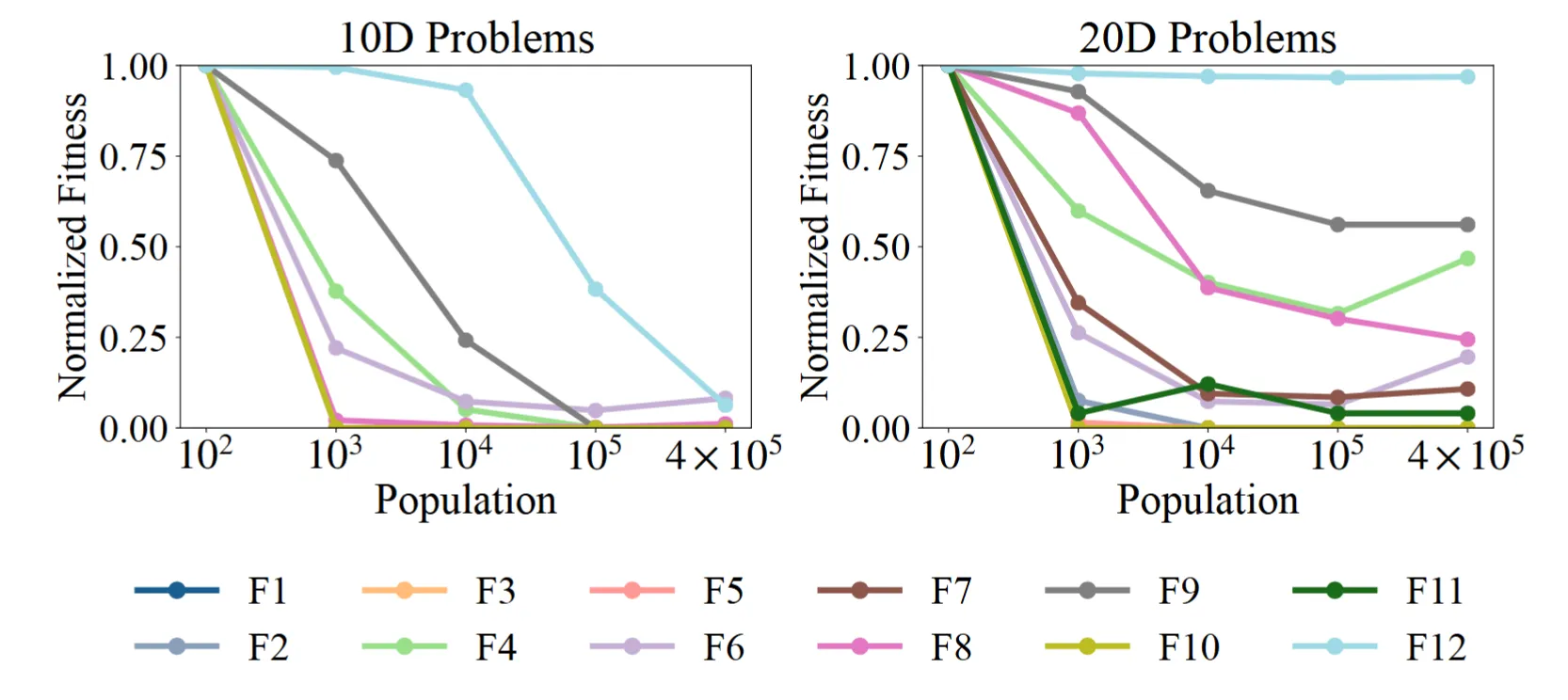 図5. 集団サイズの増加に伴うiStratDEの集団スケーラビリティ分析。
図5. 集団サイズの増加に伴うiStratDEの集団スケーラビリティ分析。
4. CEC2022コンペティション上位手法との比較
性能の上限をテストするため、チームはiStratDEをEA4eig、NL-SHADE-LBC、NL-SHADE-RSPなどのCEC2022コンペティション上位手法と比較しています。同一の関数評価予算の下で、iStratDEはそのはるかにシンプルな構造にもかかわらず、高い競争力を維持しています。いくつかの困難な10次元および20次元の関数では、これらの洗練されたベースラインと同等か、それ以上の結果を達成しています。
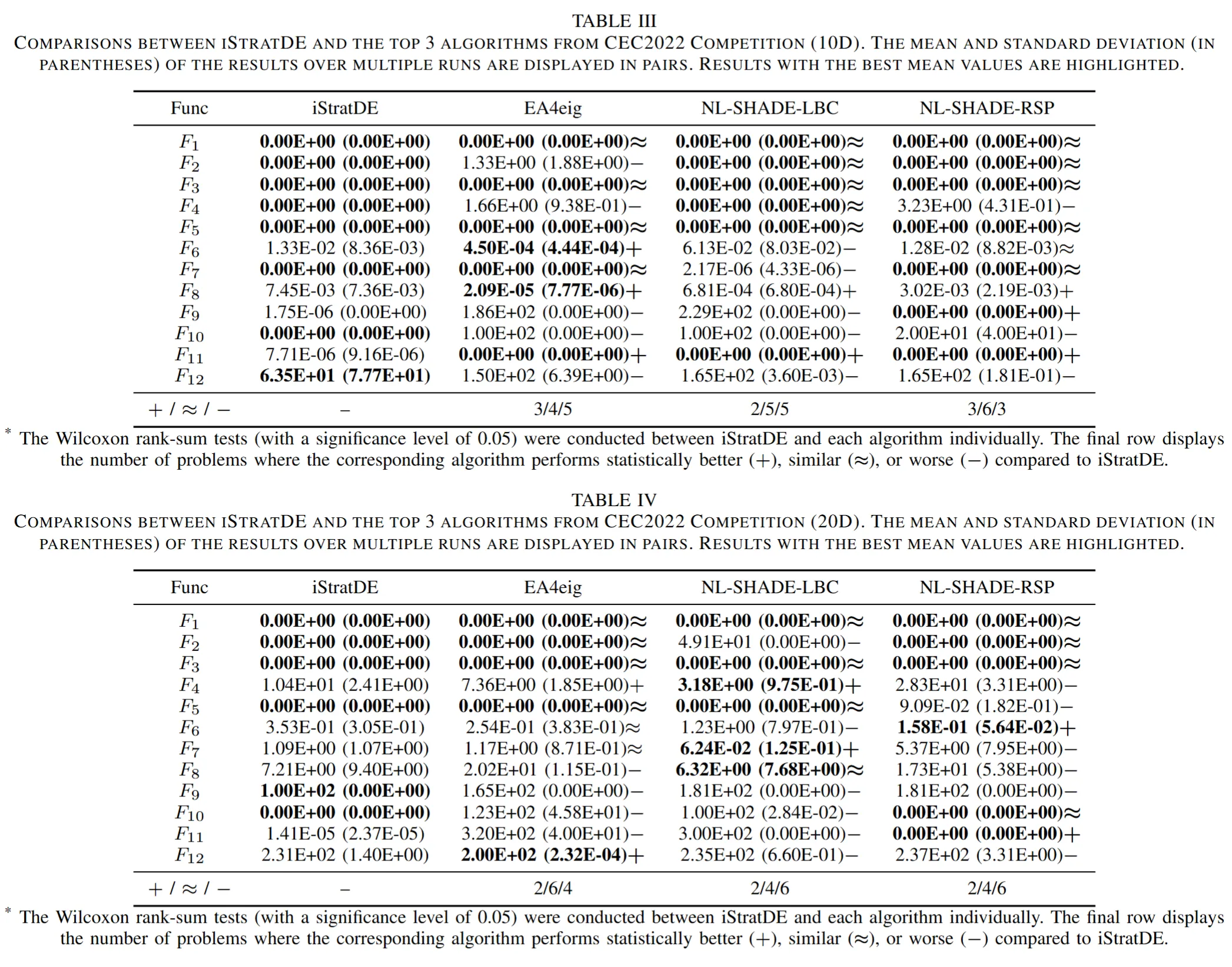 図6. CEC2022コンペティション上位手法とiStratDEの比較。
図6. CEC2022コンペティション上位手法とiStratDEの比較。
5. 実世界応用:Braxロボット制御
最後に、チームはiStratDEをBraxのロボット制御タスク(Swimmer、Reacher、Hopper)に適用しています。ここでの目的は、約1,500パラメータのニューラルネットワークコントローラを最適化することです。
1万個体の集団を使用して、iStratDEをCMA-ES、CSO、および従来のDE変種と比較しています。SwimmerやHopperなどのタスクでは、iStratDEは高報酬の方策を迅速に発見し、CMA-ESやLSHADEなどの手法よりも強力な収束を示しています。これは、iStratDEが理論的にエレガントなだけでなく、高次元ブラックボックス最適化において実践的にも有効であることを実証しています。
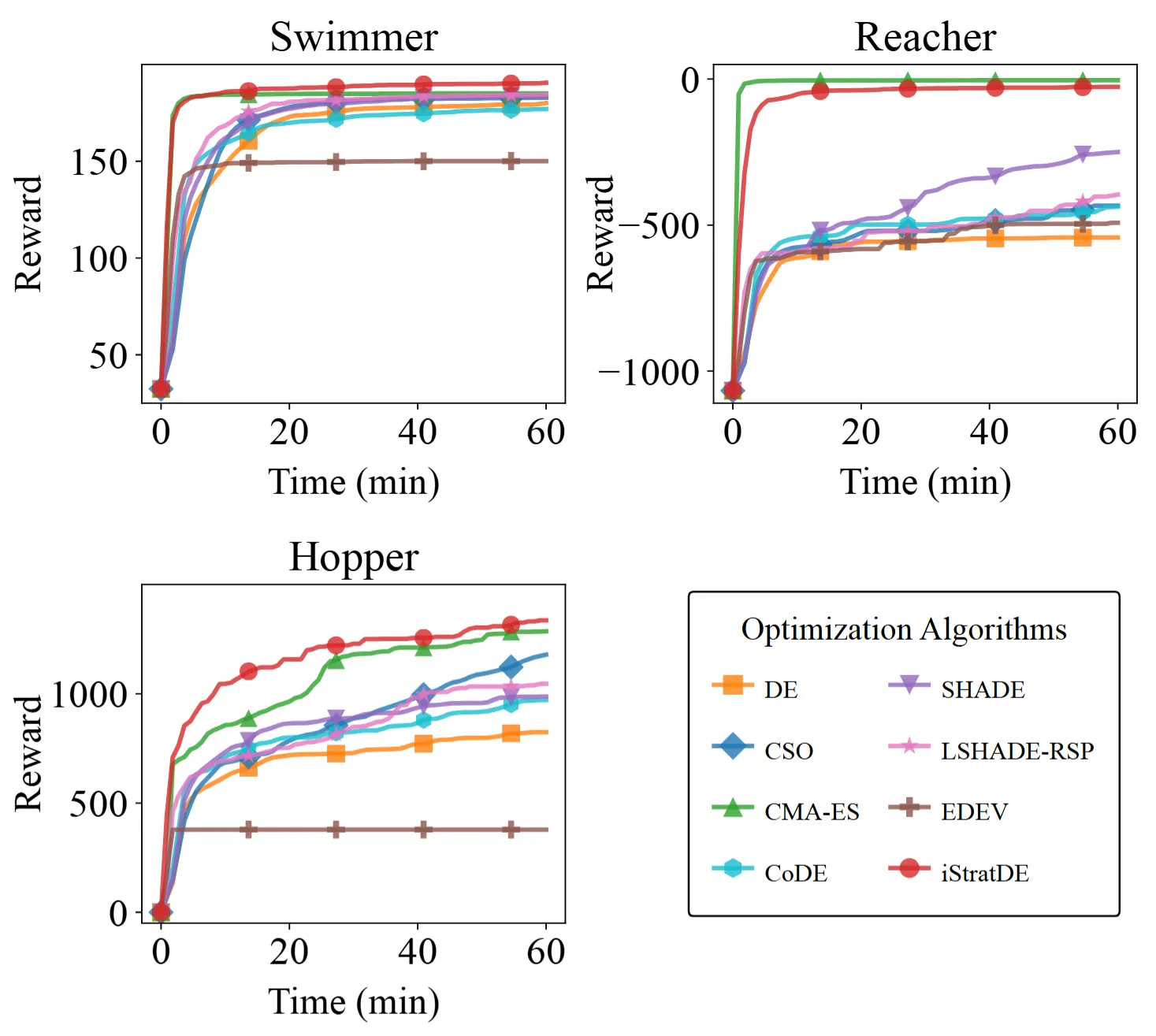 図7. 3つのBrax制御環境におけるiStratDEの収束曲線。
図7. 3つのBrax制御環境におけるiStratDEの収束曲線。
結論と展望
iStratDEはアルゴリズムの本質への回帰です。ますます複雑な適応ロジックを積み重ねるのではなく、個体レベルの戦略多様性から強力な探索能力を構築します。現代のGPUの並列ポテンシャルを最大限に解放することで、iStratDEは多峰性および高次元最適化における構造化された多様性の力を明らかにしています。
結果は、iStratDEがベンチマークと実世界の制御タスクの両方において、主要な適応型DE変種と競合し、一部の設定では上回ることができることを示しています。より広く見れば、この研究は重要な設計原則を浮き彫りにしています:複雑さだけが性能への道ではない。集団の異質性それ自体が、進化の強力なエンジンとなり得るのです。
この分散型ミニマリストパラダイムは、進化アルゴリズム設計の新しい方向性を開きます。精巧な中央集権的調整に頼るのではなく、多様な探索行動を持つ独立した個体が、知的でスケーラブルな最適化ダイナミクスを集合的に生み出せることを実証しています。
オープンソースコード / コミュニティリソース
論文: https://arxiv.org/abs/2602.01147
GitHub: https://github.com/EMI-Group/istratde
上流プロジェクト(EvoX): https://github.com/EMI-Group/evox
QQグループ: 297969717
 EvoX QQコミュニティグループのQRコード。
EvoX QQコミュニティグループのQRコード。