Unindo a Otimização Multiobjetivo Evolucionária e a Aceleração por GPU via Tensorização
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun e Ran Cheng, Membro Sênior, IEEE
Com o aumento contínuo na demanda por soluções de otimização complexas em domínios como design de engenharia e gestão de energia, os algoritmos de otimização multiobjetivo evolucionária (EMO) ganharam ampla atenção devido às suas capacidades robustas na resolução de problemas multiobjetivo. No entanto, à medida que as tarefas de otimização crescem em escala e complexidade, os algoritmos EMO tradicionais baseados em CPU encontram gargalos de desempenho significativos.
Para enfrentar essa limitação, a equipe do EvoX propôs a paralelização de algoritmos EMO em GPUs por meio da metodologia de tensorização. Aproveitando este método, eles projetaram e implementaram com sucesso vários algoritmos EMO acelerados por GPU. Além disso, a equipe desenvolveu o “MoRobtrol”, uma suíte de benchmark para controle de robôs multiobjetivo construída sobre o motor de física Brax, com o objetivo de avaliar sistematicamente o desempenho de algoritmos EMO acelerados por GPU.
Com base nesses avanços de pesquisa, a equipe do EvoX lançou o EvoMO, uma biblioteca de algoritmos EMO de alto desempenho acelerada por GPU. O código-fonte correspondente está disponível publicamente no GitHub: https://github.com/EMl-Group/evomo
Metodologia de Tensorização
No campo da otimização computacional, um tensor refere-se a uma estrutura de dados de array multidimensional capaz de representar escalares, vetores, matrizes e dados de ordem superior. A tensorização é o processo de converter estruturas de dados e operações dentro de um algoritmo para a forma de tensor, permitindo que o algoritmo aproveite totalmente as capacidades de computação paralela das GPUs.
Em algoritmos EMO, todas as estruturas de dados principais podem ser expressas em um formato tensorizado. Os indivíduos em uma população podem ser representados por um tensor de solução X, onde cada vetor de linha corresponde a um indivíduo. Os valores da função objetivo formam um tensor de objetivo F. Além disso, estruturas de dados auxiliares, como vetores de referência e vetores de peso, podem ser expressas como tensores R e W, respectivamente. Esta representação unificada de tensores permite operações em nível de população no nível de representação, estabelecendo uma base sólida para computação paralela em larga escala.
A tensorização das operações do algoritmo EMO é crucial para aumentar a eficiência computacional e pode ser dividida em duas camadas: operações básicas de tensor e tensorização do fluxo de controle. As operações básicas de tensor constituem o núcleo da implementação tensorizada dos algoritmos EMO, conforme detalhado na Tabela I.
Tabela I: Operações Básicas de Tensores

A tensorização do fluxo de controle substitui a lógica tradicional de loops e condicionais por operações de tensor paralelizáveis. Por exemplo, loops for/while podem ser transformados em operações em lote (batched) usando mecanismos de broadcasting ou funções de ordem superior como vmap. Da mesma forma, condicionais if-else podem ser substituídas por técnicas de masking, onde as condições lógicas são codificadas como tensores Boolean, permitindo a alternância flexível entre diferentes caminhos de computação.
Comparada às implementações tradicionais de algoritmos EMO, a abordagem de tensorização oferece vantagens significativas. Primeiro, proporciona maior flexibilidade, lidando naturalmente com dados multidimensionais, enquanto os métodos convencionais são frequentemente restritos a operações de matriz bidimensionais. Segundo, a tensorização melhora significativamente a eficiência computacional por meio da execução paralela, evitando a sobrecarga associada a loops explícitos e ramificações condicionais. Por fim, simplifica a estrutura do código, resultando em programas mais concisos e fáceis de manter.
Como ilustrado na Fig. 1, por exemplo, a implementação tradicional da verificação de dominância de Pareto depende de loops aninhados para realizar comparações elemento a elemento. Em contraste, a versão tensorizada alcança a mesma funcionalidade por meio de operações de broadcasting e masking, permitindo a avaliação paralela. Isso não apenas reduz a complexidade do código, mas também melhora drasticamente o desempenho em tempo de execução.

Fig.1: Comparação entre implementações convencionais e baseadas em tensores da detecção de dominância de Pareto.
De uma perspectiva mais profunda, a tensorização é bem adequada para a aceleração por GPU porque as GPUs possuem um grande número de núcleos paralelos, e sua arquitetura SIMT (single-instruction multiple-thread) se alinha naturalmente com computações de tensores, destacando-se particularmente em operações de matriz. Hardwares dedicados, como os Tensor Cores da NVIDIA, aumentam ainda mais o rendimento das operações de tensor. Em geral, algoritmos que exibem alto paralelismo, contêm tarefas computacionais independentes e possuem ramificações condicionais mínimas são mais propensos à tensorização. Para algoritmos como o MOEA/D, que envolvem dependências sequenciais, a estrutura inerente apresenta desafios para a tensorização direta. No entanto, por meio da refatoração estrutural e do desacoplamento de computações críticas, ainda é possível alcançar uma aceleração paralela eficaz.
Exemplo de Aplicação da Tensorização de Algoritmos
Com base na metodologia de representação tensorizada, a equipe do EvoX projetou e implementou versões tensorizadas de três algoritmos EMO clássicos: o NSGA-III baseado em dominância, o MOEA/D baseado em decomposição e o HypE baseado em indicadores. A seção a seguir fornece uma explicação detalhada usando o MOEA/D como exemplo. As implementações tensorizadas do NSGA-III e HypE podem ser encontradas no artigo referenciado.
Como ilustrado na Fig. 2, o MOEA/D tradicional decompõe um problema multiobjetivo em múltiplos subproblemas, cada um dos quais é otimizado de forma independente. O algoritmo compreende quatro etapas principais: crossover e mutação, avaliação de fitness, atualização do ponto ideal e atualização de vizinhança. Essas etapas são executadas sequencialmente para cada indivíduo dentro de um único loop. Esse processamento sequencial leva a uma sobrecarga computacional substancial ao lidar com grandes populações, pois cada indivíduo deve completar todas as etapas em ordem, limitando os benefícios potenciais da aceleração por GPU. Em particular, a atualização de vizinhança depende de interações entre indivíduos, o que complica ainda mais a paralelização.

Fig.2: Pseudocódigo do MOEA/D
Para resolver a questão das dependências sequenciais no MOEA/D tradicional, a equipe introduziu um método de representação tensorizada dentro do loop interno de seleção ambiental. Ao desacoplar o crossover e mutação, a avaliação de fitness, a atualização do ponto ideal e a atualização de vizinhança, esses componentes são tratados como operações independentes. Isso permite o processamento paralelo de todos os indivíduos, levando à construção de um algoritmo MOEA/D tensorizado, referido como TensorMOEA/D. Neste algoritmo, a seleção ambiental é dividida em dois estágios principais: comparação e atualização da população, e seleção de soluções de elite. Esses dois estágios são primariamente tensorizados através de duas aplicações da operação vmap. O processo detalhado é ilustrado na Fig. 3.
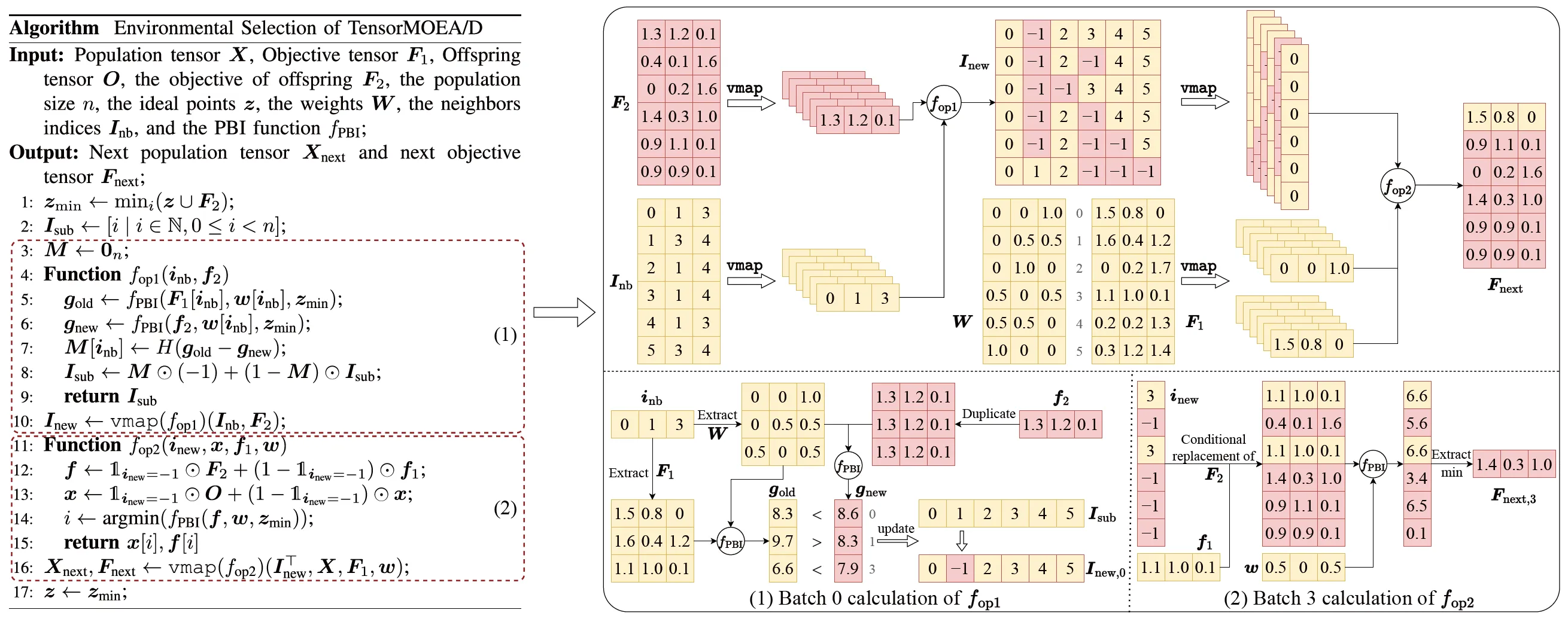

Fig.3: Visão geral da seleção ambiental no algoritmo TensorMOEA/D. Esquerda: Pseudocódigo do algoritmo. Direita: Fluxo de dados de tensores do módulo (1) e módulo (2). A parte superior da figura à direita mostra o fluxo de dados de tensores geral para os módulos (1) e (2), enquanto a parte inferior apresenta o fluxo de dados de tensores de cálculo em lote, com o módulo (1) à esquerda e o módulo (2) à direita.
Para obter uma compreensão mais abrangente do valor da tensorização em algoritmos EMO, ela pode ser resumida sob três perspectivas. Primeiro, a tensorização permite uma transformação direta de formulações matemáticas para código eficiente, diminuindo a lacuna entre o design do algoritmo e a implementação. Por exemplo, a Fig. 4 ilustra como o procedimento de ordenação não-dominada tensorizado pode ser traduzido diretamente do pseudocódigo para o código Python. Segundo, a tensorização simplifica significativamente a estrutura do código ao unificar as operações em nível de população em uma única representação de tensor. Isso reduz a dependência de loops e declarações condicionais, melhorando assim a legibilidade e a manutenção do código. Terceiro, a tensorização aumenta a reprodutibilidade dos algoritmos. Sua representação estruturada facilita testes comparativos e a reprodução consistente de resultados.

Fig.4: A transformação contínua da ordenação não-dominada tensorizada do pseudocódigo (Esquerda) para o código Python (Direita).
Demonstração de Desempenho
Para avaliar o desempenho dos algoritmos de otimização multiobjetivo acelerados por GPU, a equipe do EvoX conduziu sistematicamente três categorias de experimentos, focando na aceleração computacional, no desempenho de otimização numérica e na eficácia em tarefas de controle robótico multiobjetivo.
Desempenho de Aceleração Computacional:
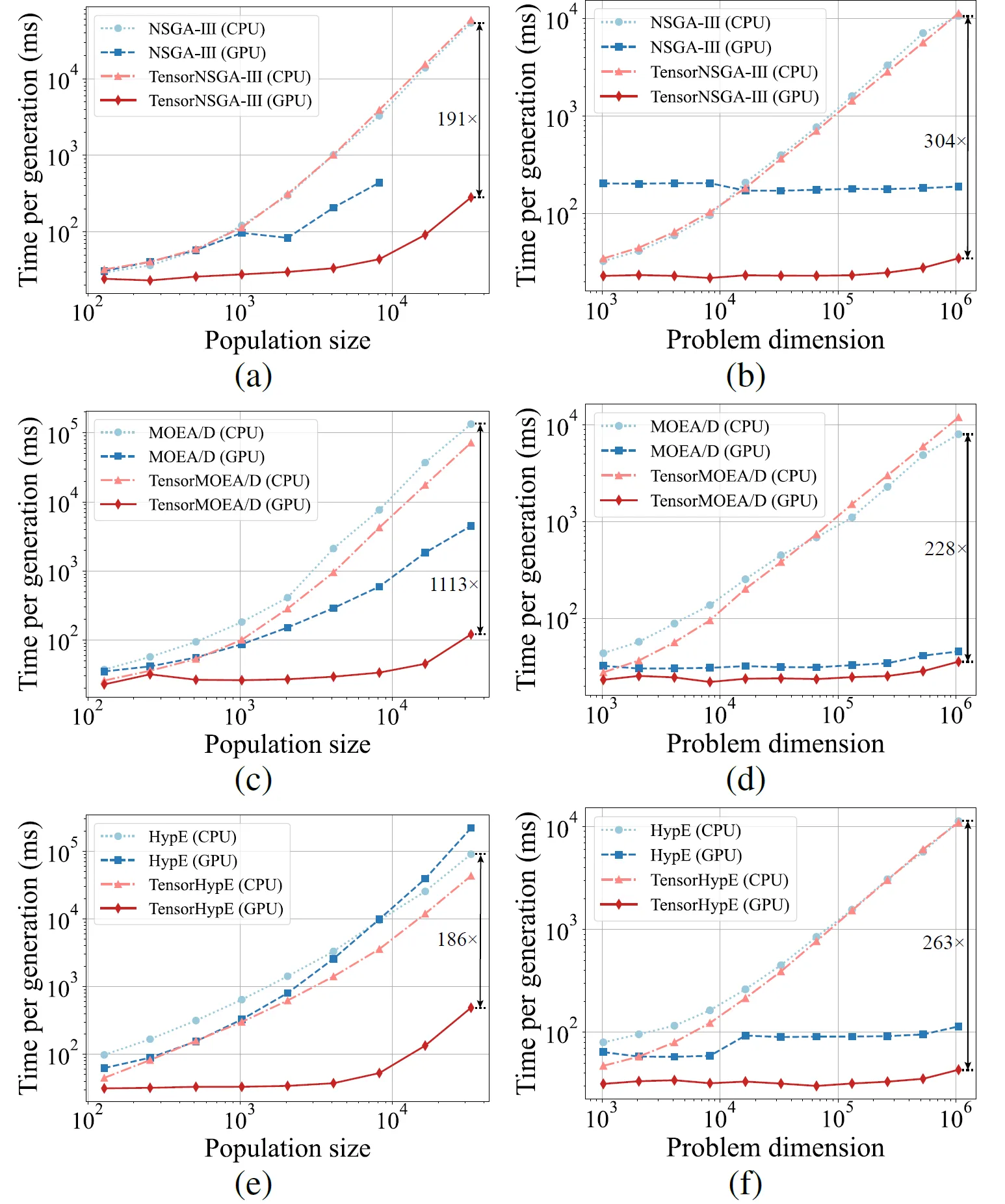
Fig.5: Desempenho de aceleração comparativo do NSGA-III, MOEA/D e HypE com suas contrapartes tensorizadas em plataformas CPU e GPU em vários tamanhos de população e dimensões de problemas.
Os resultados experimentais mostram que o TensorNSGA-III, TensorMOEA/D e TensorHypE alcançam velocidades de execução significativamente maiores em GPUs em comparação com suas contrapartes baseadas em CPU não tensorizadas. À medida que o tamanho da população e a dimensionalidade do problema aumentam, o speedup máximo observado chega a 1113x. Os algoritmos tensorizados demonstram excelente escalabilidade e estabilidade ao lidar com tarefas computacionais de larga escala — seu tempo de execução aumenta apenas marginalmente, mantendo um desempenho consistentemente alto. Essas descobertas destacam as vantagens substanciais da tensorização para a aceleração por GPU na otimização multiobjetivo.
Desempenho na Suíte de Testes LSMOP:
Tabela II: Resultados Estatísticos (Média e Desvio Padrão) do IGD e Tempo de Execução (s) para Algoritmos EMO Não Tensorizados e Tensorizados em LSMOP1–LSMOP9. Todos os Experimentos Foram Realizados em uma GPU RTX 4090 e os Melhores Resultados Estão em Destaque.
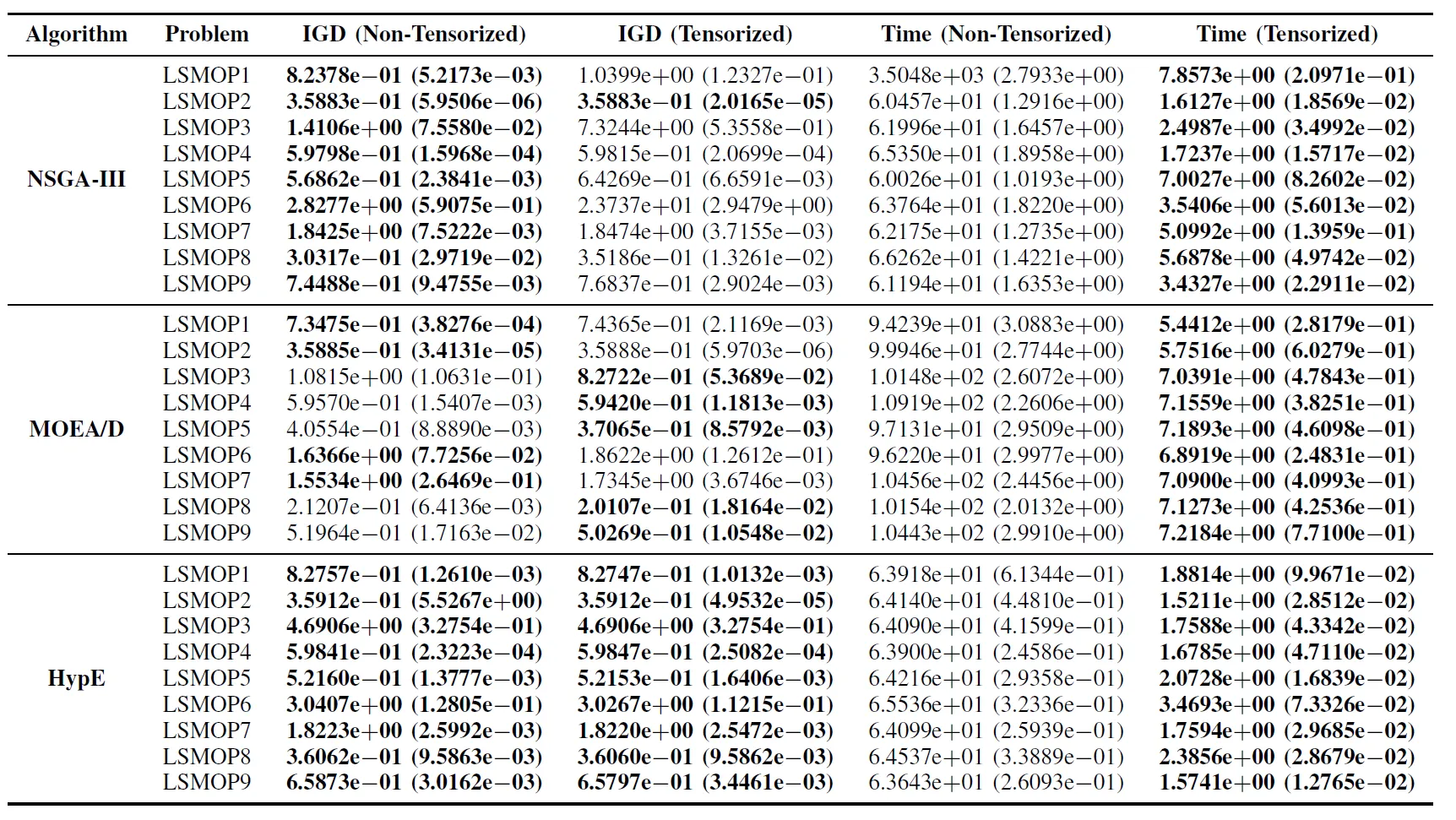
Os resultados experimentais indicam que os algoritmos EMO acelerados por GPU baseados em representações tensorizadas melhoram significativamente a eficiência computacional, mantendo e, em alguns casos, até superando a precisão de otimização de suas contrapartes originais.
Tarefas de Controle de Robôs Multiobjetivo:
Para avaliar de forma abrangente o desempenho prático dos algoritmos EMO acelerados por GPU, a equipe desenvolveu uma suíte de benchmark chamada MoRobtrol para controle de robôs multiobjetivo. As tarefas incluídas nesta suíte estão listadas na Tabela III.
Tabela III: Visão Geral dos Problemas de Controle de Robôs Multiobjetivo na Suíte de Testes de Benchmark MoRobtrol Proposta
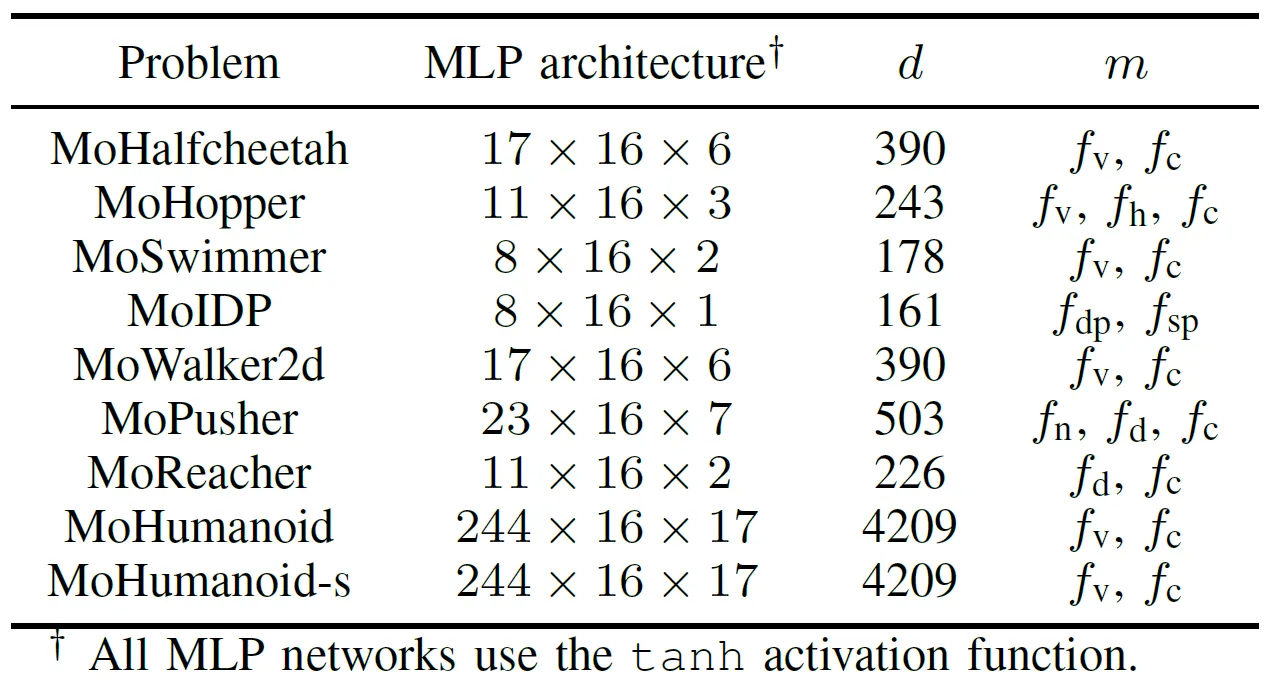
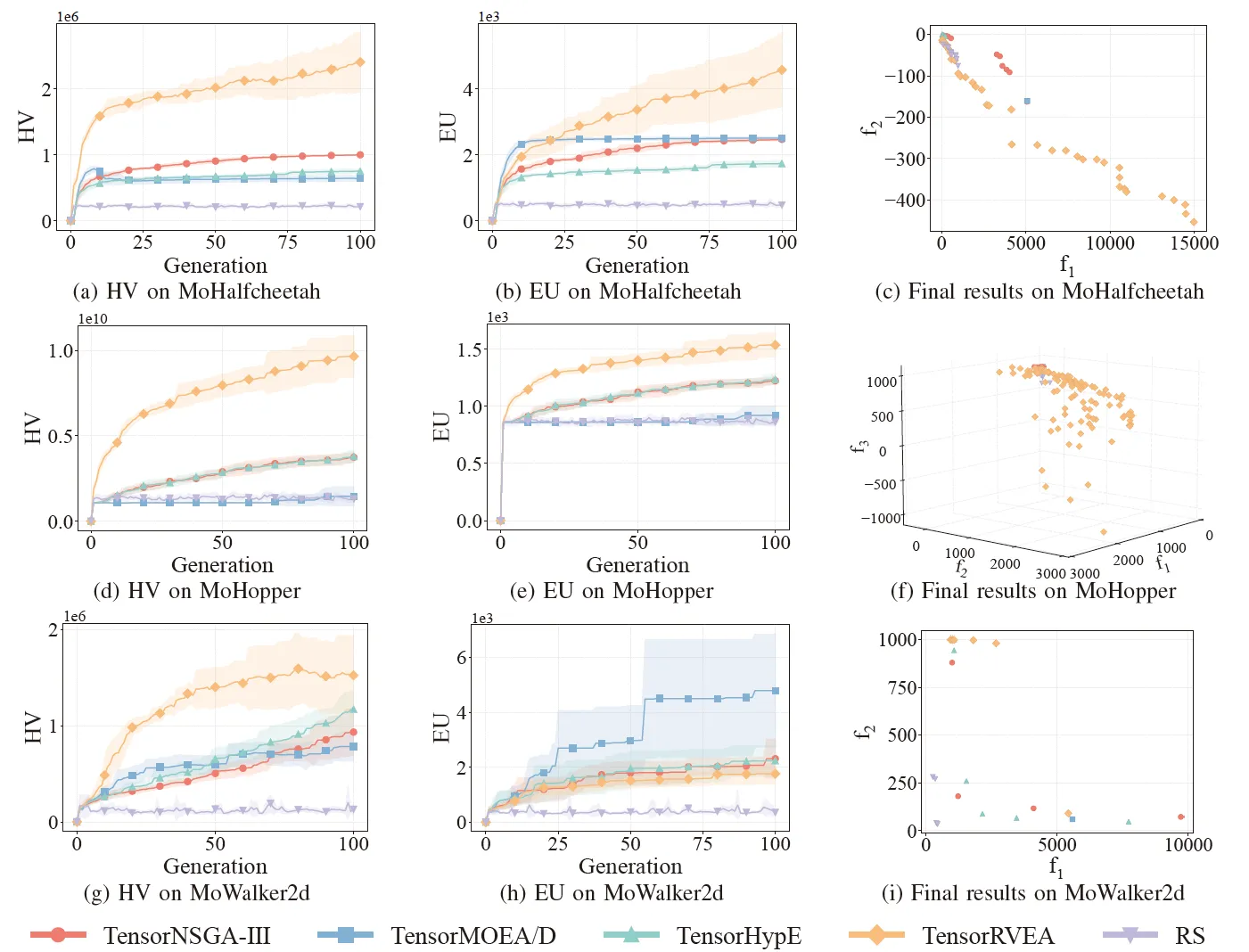
Fig.6: Desempenho comparativo (HV, EU e visualização dos resultados finais) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA e busca aleatória (RS) em vários problemas: MoHalfcheetah (390D), MoHopper (243D) e MoWalker2d (390D). Nota: Valores mais altos para todas as métricas indicam melhor desempenho.
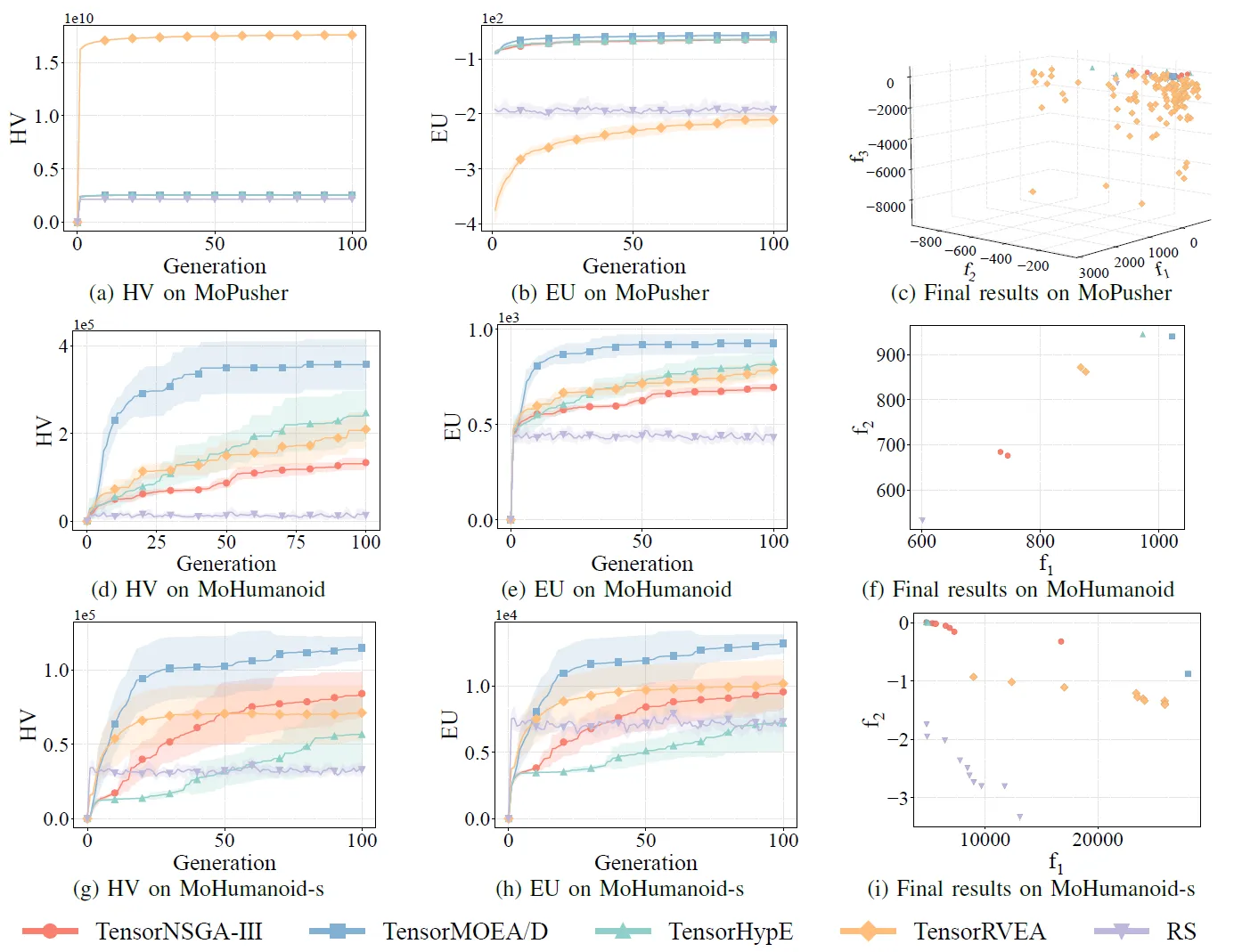
Fig.7: Desempenho comparativo (HV, EU e visualização dos resultados finais) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA e busca aleatória (RS) em vários problemas: MoPusher (503D), MoHumanoid (4209D) e MoHumanoid-s (4209D). Nota: Valores mais altos para todas as métricas indicam melhor desempenho.
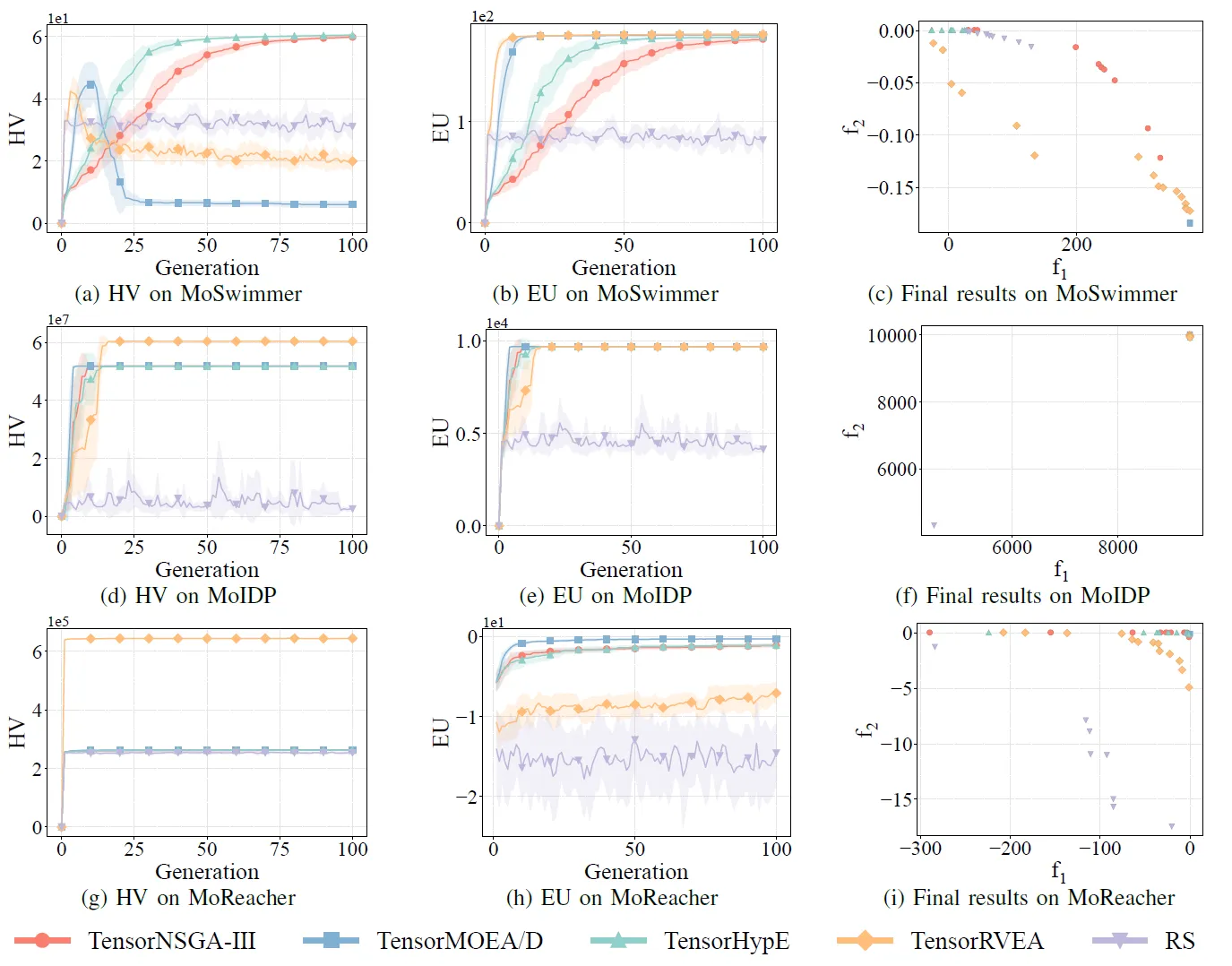
Fig.8: Desempenho comparativo (HV, EU e visualização dos resultados finais) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA e busca aleatória (RS) em vários problemas: MoSwimmer (178D), MoIDP (161D) e MoReacher (226D). Nota: Valores mais altos para todas as métricas indicam melhor desempenho.
Os experimentos compararam o desempenho de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA e Busca Aleatória (RS) dentro do benchmark MoRobtrol. Os resultados mostram que o TensorRVEA alcançou o melhor desempenho geral, obtendo os maiores valores de HV e demonstrando boa diversidade de soluções em múltiplos ambientes. O TensorMOEA/D exibiu forte adaptabilidade em tarefas de larga escala, destacando-se particularmente na consistência de preferência das soluções. O TensorNSGA-III e o TensorHypE mostraram desempenho semelhante e foram competitivos em várias tarefas. No geral, os algoritmos baseados em decomposição tensorizados demonstraram vantagens superiores na resolução de problemas complexos e de larga escala.
Conclusão e Trabalhos Futuros
Este estudo propõe uma metodologia de representação tensorizada para abordar as limitações dos algoritmos EMO tradicionais baseados em CPU em termos de eficiência computacional e escalabilidade. A abordagem foi aplicada a vários algoritmos representativos, incluindo NSGA-III, MOEA/D e HypE, alcançando melhorias significativas de desempenho em GPUs enquanto mantém a qualidade da solução. Para validar sua aplicabilidade prática, a equipe também desenvolveu o MoRobtrol, uma suíte de benchmark de controle robótico multiobjetivo que reformula tarefas de controle robótico em ambientes de simulação física como problemas de otimização multiobjetivo. Os resultados demonstram o potencial dos algoritmos tensorizados em cenários computacionalmente intensivos, como a inteligência incorporada (embodied intelligence). Embora o método de tensorização tenha melhorado substancialmente a eficiência algorítmica, ainda há espaço para melhorias adicionais. Direções futuras incluem o aprimoramento de operadores principais, como a ordenação não-dominada, o design de novas operações tensorizadas para sistemas multi-GPU e a integração de dados em larga escala e técnicas de deep learning para aumentar ainda mais o desempenho em problemas de otimização de larga escala.
Código de Código Aberto / Recursos da Comunidade
Artigo:
https://arxiv.org/abs/2503.20286
GitHub:
https://github.com/EMI-Group/evomo
Projeto Upstream (EvoX):
https://github.com/EMI-Group/evox
Grupo QQ: 297969717

O EvoMO é construído sobre o framework EvoX. Se você estiver interessado em saber mais sobre o EvoX, sinta-se à vontade para conferir o artigo oficial sobre o EvoX 1.0 publicado em nossa conta pública do WeChat para mais detalhes.
