Faire le pont entre l’optimisation multiobjectif évolutionnaire et l’accélération GPU via la tensorisation
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun et Ran Cheng, Senior Member, IEEE
Avec la demande croissante de solutions d’optimisation complexes dans des domaines tels que la conception technique et la gestion de l’énergie, les algorithmes d’optimisation multiobjectif évolutionnaire (EMO) ont attiré une attention considérable en raison de leurs capacités robustes à résoudre des problèmes multiobjectifs. Cependant, à mesure que les tâches d’optimisation augmentent en échelle et en complexité, les algorithmes EMO traditionnels basés sur CPU rencontrent d’importants goulots d’étranglement en termes de performance.
Pour remédier à cette limitation, l’équipe EvoX a proposé de paralléliser les algorithmes EMO sur GPU via la méthodologie de tensorisation. En tirant parti de cette méthode, ils ont conçu et implémenté avec succès plusieurs algorithmes EMO accélérés par GPU. De plus, l’équipe a développé “MoRobtrol”, une suite de benchmarks pour le contrôle robotique multiobjectif construite sur le moteur physique Brax, visant à évaluer systématiquement les performances des algorithmes EMO accélérés par GPU.
Sur la base de ces avancées de recherche, l’équipe EvoX a publié EvoMO, une bibliothèque d’algorithmes EMO haute performance accélérée par GPU. Le code source correspondant est publiquement disponible sur GitHub : https://github.com/EMl-Group/evomo
Méthodologie de Tensorisation
Dans le domaine de l’optimisation computationnelle, un tenseur fait référence à une structure de données en tableau multidimensionnel capable de représenter des scalaires, des vecteurs, des matrices et des données d’ordre supérieur. La tensorisation est le processus de conversion des structures de données et des opérations au sein d’un algorithme sous forme tensorielle, permettant à l’algorithme d’exploiter pleinement les capacités de calcul parallèle des GPU.
Dans les algorithmes EMO, toutes les structures de données clés peuvent être exprimées dans un format tensorisé. Les individus d’une population peuvent être représentés par un tenseur de solution X, où chaque vecteur ligne correspond à un individu. Les valeurs de la fonction objectif forment un tenseur d’objectif F. De plus, les structures de données auxiliaires telles que les vecteurs de référence et les vecteurs de poids peuvent être exprimées respectivement comme des tenseurs R et W. Cette représentation tensorielle unifiée permet des opérations au niveau de la population dès le niveau de la représentation, posant une base solide pour le calcul parallèle à grande échelle.
La tensorisation des opérations des algorithmes EMO est cruciale pour améliorer l’efficacité computationnelle et peut être divisée en deux couches : les opérations tensorielles de base et la tensorisation du flux de contrôle. Les opérations tensorielles de base constituent le cœur de l’implémentation tensorisée des algorithmes EMO, comme détaillé dans le Tableau I.
Tableau I : Opérations tensorielles de base

La tensorisation du flux de contrôle remplace les boucles traditionnelles et la logique conditionnelle par des opérations tensorielles parallélisables. Par exemple, les boucles for/while peuvent être transformées en opérations par lots (batched operations) en utilisant des mécanismes de broadcasting ou des fonctions d’ordre supérieur telles que vmap. De même, les conditions if-else peuvent être remplacées par des techniques de masquage (masking), où les conditions logiques sont encodées sous forme de tenseurs booléens, permettant une commutation flexible entre différents chemins de calcul.
Comparée aux implémentations traditionnelles d’algorithmes EMO, l’approche par tensorisation offre des avantages significatifs. Premièrement, elle offre une plus grande flexibilité, gérant naturellement les données multidimensionnelles, alors que les méthodes conventionnelles sont souvent limitées aux opérations matricielles bidimensionnelles. Deuxièmement, la tensorisation améliore considérablement l’efficacité computationnelle grâce à l’exécution parallèle, évitant la surcharge associée aux boucles explicites et aux branches conditionnelles. Enfin, elle simplifie la structure du code, résultant en des programmes plus concis et maintenables.
Comme illustré dans la Fig. 1, par exemple, l’implémentation traditionnelle de la vérification de la dominance de Pareto repose sur des boucles imbriquées pour effectuer des comparaisons élément par élément. En revanche, la version tensorisée réalise la même fonctionnalité grâce à des opérations de broadcasting et de masquage, permettant une évaluation parallèle. Cela réduit non seulement la complexité du code, mais améliore aussi considérablement les performances d’exécution.

Fig.1 : Comparaison entre les implémentations conventionnelles et basées sur les tenseurs de la détection de dominance de Pareto.
D’un point de vue plus approfondi, la tensorisation est bien adaptée à l’accélération GPU car les GPU possèdent un grand nombre de cœurs parallèles, et leur architecture SIMT (single-instruction multiple-thread) s’aligne naturellement avec les calculs tensoriels, excellant particulièrement dans les opérations matricielles. Le matériel dédié tel que les Tensor Cores de NVIDIA améliore encore le débit des opérations tensorielles. En général, les algorithmes qui présentent un parallélisme élevé, contiennent des tâches de calcul indépendantes et ont un minimum de branchements conditionnels sont plus propices à la tensorisation. Pour des algorithmes comme MOEA/D, qui impliquent des dépendances séquentielles, la structure inhérente pose des défis à la tensorisation directe. Cependant, grâce à une refactorisation structurelle et au découplage des calculs critiques, il est toujours possible d’obtenir une accélération parallèle efficace.
Exemple d’Application de la Tensorisation d’Algorithme
Sur la base de la méthodologie de représentation tensorisée, l’équipe EvoX a conçu et implémenté des versions tensorisées de trois algorithmes EMO classiques : NSGA-III basé sur la dominance, MOEA/D basé sur la décomposition et HypE basé sur les indicateurs. La section suivante fournit une explication détaillée en utilisant MOEA/D comme exemple. Les implémentations tensorisées de NSGA-III et HypE peuvent être trouvées dans l’article référencé.
Comme illustré dans la Fig. 2, le MOEA/D traditionnel décompose un problème multiobjectif en plusieurs sous-problèmes, chacun étant optimisé indépendamment. L’algorithme comprend quatre étapes principales : croisement et mutation, évaluation de la fitness, mise à jour du point idéal et mise à jour du voisinage. Ces étapes sont exécutées séquentiellement pour chaque individu au sein d’une boucle unique. Ce traitement séquentiel entraîne une surcharge de calcul substantielle lors du traitement de grandes populations, car chaque individu doit compléter toutes les étapes dans l’ordre, limitant les avantages potentiels de l’accélération GPU. En particulier, la mise à jour du voisinage repose sur des interactions entre individus, ce qui complique davantage la parallélisation.

Fig.2 : Pseudocode de MOEA/D
Pour résoudre le problème des dépendances séquentielles dans le MOEA/D traditionnel, l’équipe a introduit une méthode de représentation tensorisée au sein de la boucle interne de sélection environnementale. En découplant le croisement et la mutation, l’évaluation de la fitness, la mise à jour du point idéal et la mise à jour du voisinage, ces composants sont traités comme des opérations indépendantes. Cela permet le traitement parallèle de tous les individus, conduisant à la construction d’un algorithme MOEA/D tensorisé, appelé TensorMOEA/D. Dans cet algorithme, la sélection environnementale est divisée en deux étapes principales : comparaison et mise à jour de la population, et sélection des solutions élites. Ces deux étapes sont principalement tensorisées via deux applications de l’opération vmap. Le processus détaillé est illustré dans la Fig. 3.
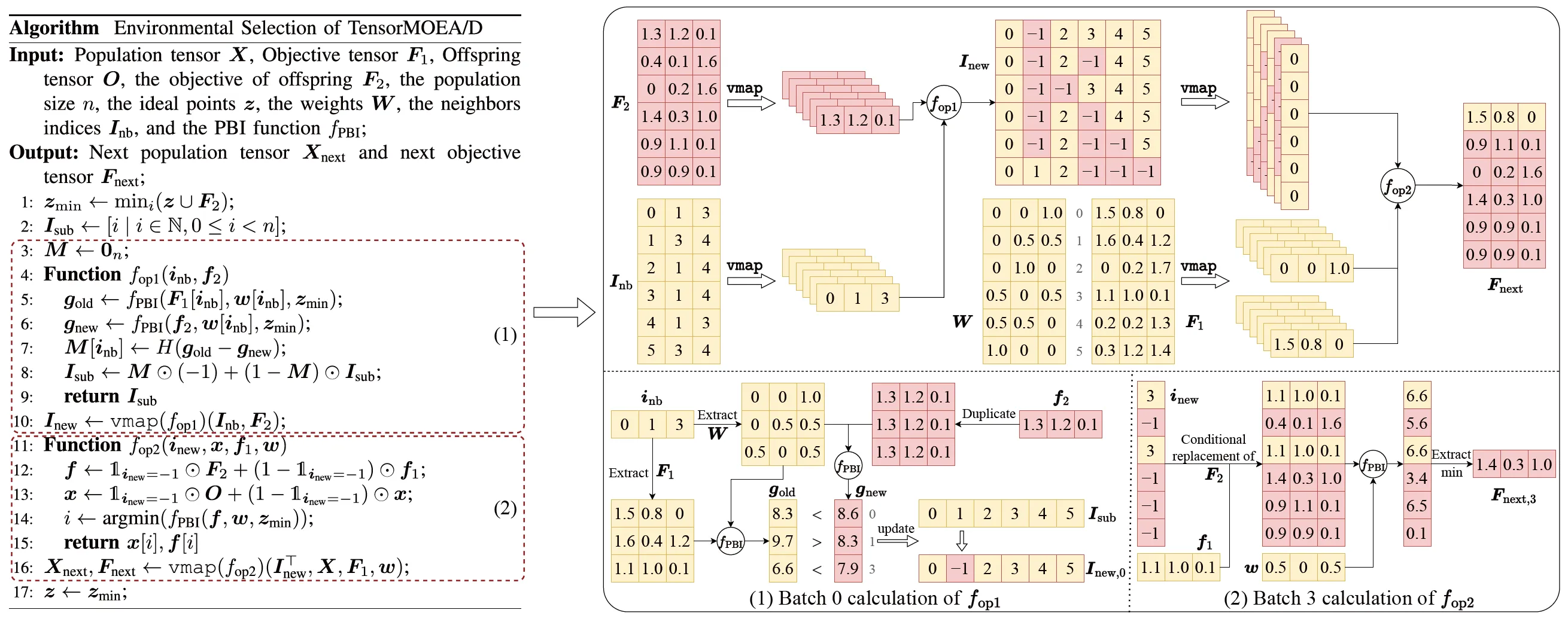

Fig.3 : Aperçu de la sélection environnementale dans l’algorithme TensorMOEA/D. Gauche : Pseudocode de l’algorithme. Droite : Flux de données tensoriel du module (1) et du module (2). La partie supérieure de la figure de droite montre le flux de données tensoriel global pour les modules (1) et (2), tandis que la partie inférieure présente le flux de données tensoriel du calcul par lots, avec le module (1) à gauche et le module (2) à droite.
Pour avoir une compréhension plus complète de la valeur de la tensorisation dans les algorithmes EMO, on peut la résumer sous trois perspectives. Premièrement, la tensorisation permet une transformation directe des formulations mathématiques en code efficace, réduisant l’écart entre la conception de l’algorithme et son implémentation. Par exemple, la Fig. 4 illustre comment la procédure de tri non dominé tensorisée peut être traduite directement du pseudocode en code Python. Deuxièmement, la tensorisation simplifie considérablement la structure du code en unifiant les opérations au niveau de la population en une seule représentation tensorielle. Cela réduit la dépendance aux boucles et aux instructions conditionnelles, améliorant ainsi la lisibilité et la maintenabilité du code. Troisièmement, la tensorisation améliore la reproductibilité des algorithmes. Sa représentation structurée facilite les tests comparatifs et la reproduction cohérente des résultats.

Fig.4 : La transformation fluide du tri non dominé tensorisé du pseudocode (Gauche) au code Python (Droite).
Démonstration de Performance
Pour évaluer les performances des algorithmes d’optimisation multiobjectif accélérés par GPU, l’équipe EvoX a mené systématiquement trois catégories d’expériences, se concentrant sur l’accélération computationnelle, la performance d’optimisation numérique et l’efficacité dans les tâches de contrôle robotique multiobjectif.
Performance d’Accélération Computationnelle :
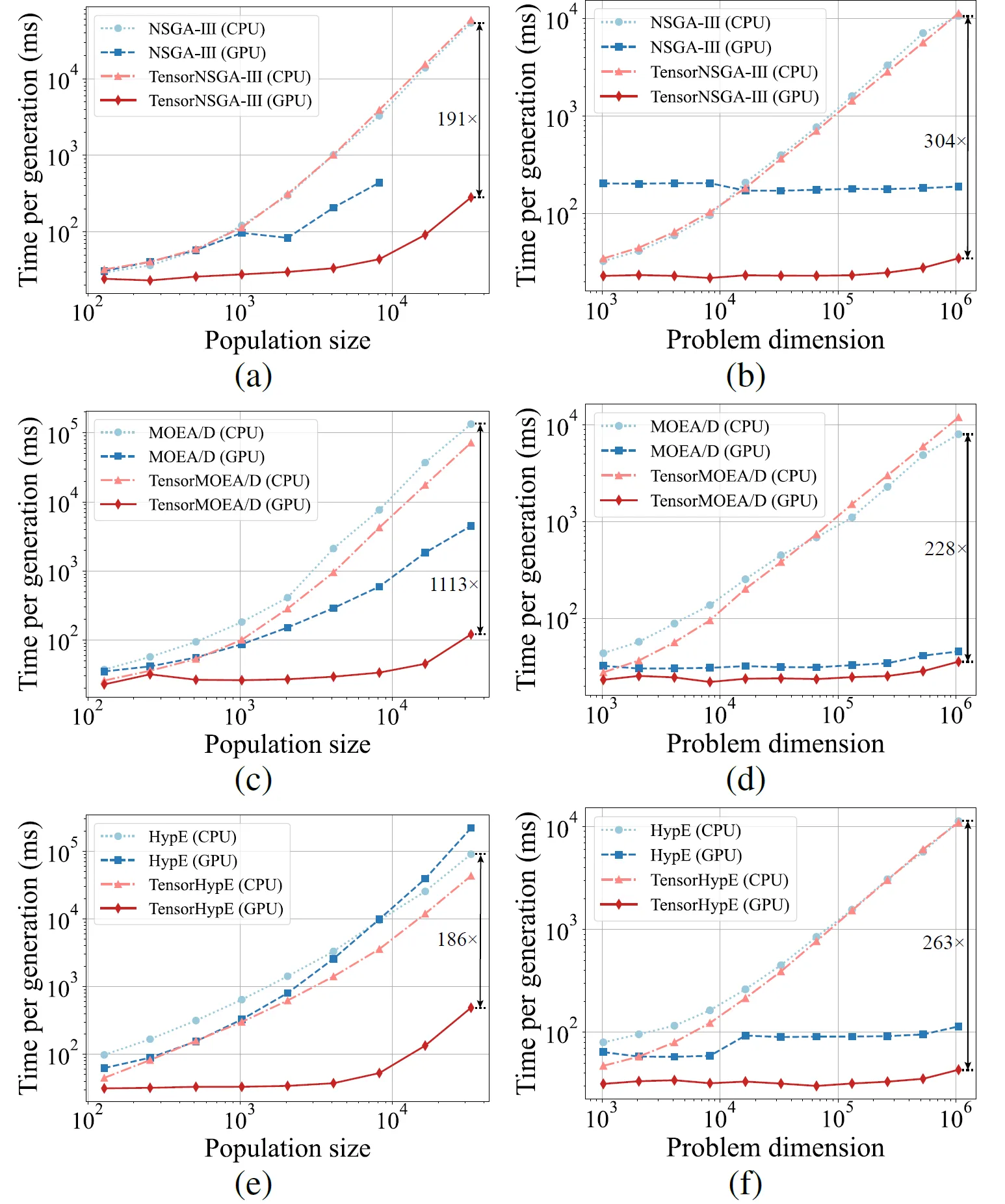
Fig.5 : Performance d’accélération comparative de NSGA-III, MOEA/D et HypE avec leurs homologues tensorisés sur les plateformes CPU et GPU à travers différentes tailles de population et dimensions de problème.
Les résultats expérimentaux montrent que TensorNSGA-III, TensorMOEA/D et TensorHypE atteignent des vitesses d’exécution significativement plus élevées sur GPU par rapport à leurs homologues non tensorisés basés sur CPU. À mesure que la taille de la population et la dimensionnalité du problème augmentent, l’accélération maximale observée atteint jusqu’à 1113x. Les algorithmes tensorisés démontrent une excellente scalabilité et stabilité lors du traitement de tâches de calcul à grande échelle — leur temps d’exécution n’augmente que marginalement, tout en maintenant une performance constamment élevée. Ces résultats soulignent les avantages substantiels de la tensorisation pour l’accélération GPU dans l’optimisation multiobjectif.
Performance sur la Suite de Tests LSMOP :
Tableau II : Résultats statistiques (Moyenne et Écart-type) de l’IGD et du Temps d’exécution (s) pour les algorithmes EMO non tensorisés et tensorisés dans LSMOP1—LSMOP9. Toutes les expériences sont sur un GPU RTX 4090 et les meilleurs résultats sont mis en évidence.
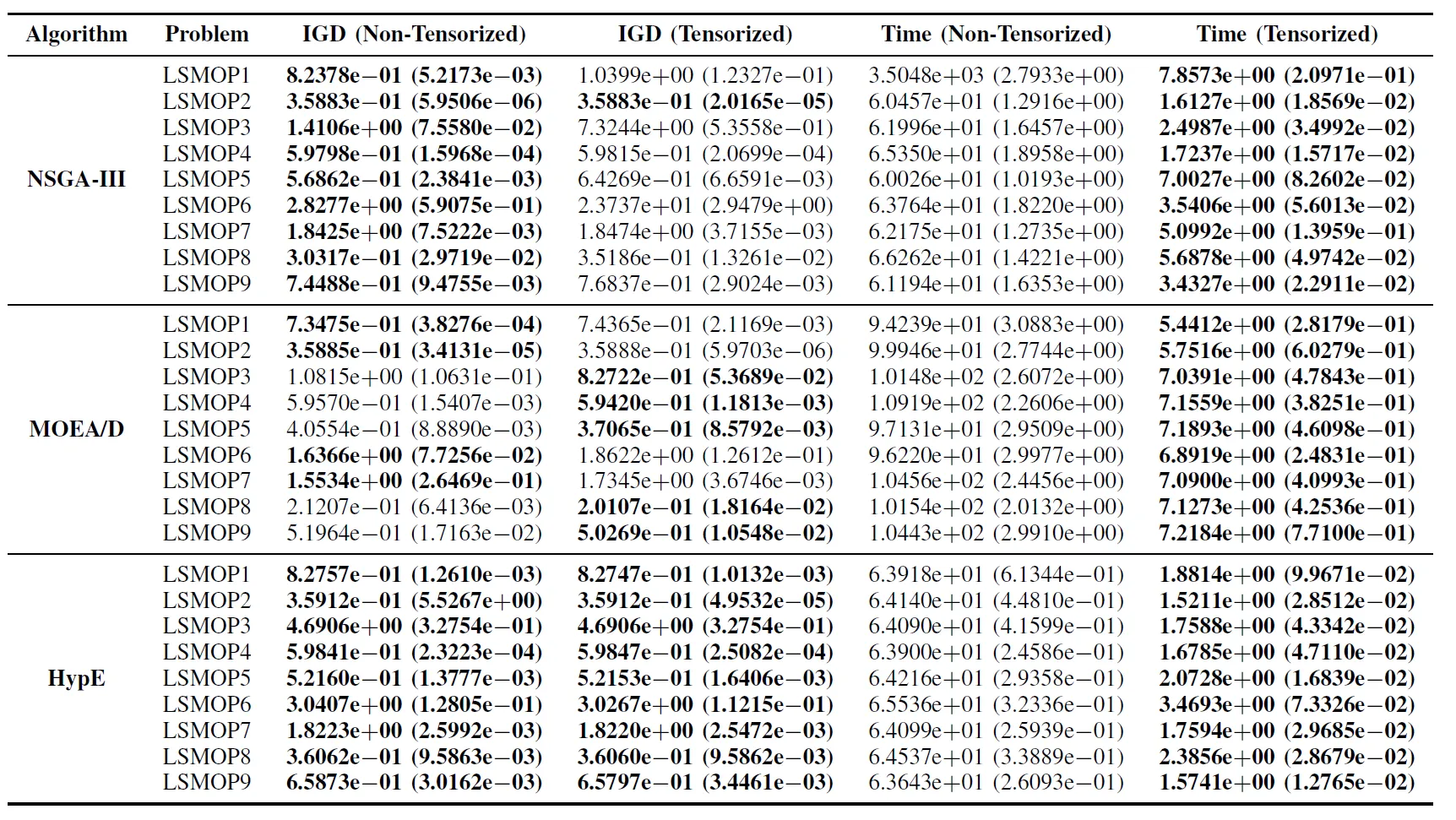
Les résultats expérimentaux indiquent que les algorithmes EMO accélérés par GPU basés sur des représentations tensorisées améliorent considérablement l’efficacité computationnelle tout en maintenant, et dans certains cas en surpassant, la précision d’optimisation de leurs homologues originaux.
Tâches de Contrôle Robotique Multiobjectif :
Pour évaluer de manière exhaustive la performance pratique des algorithmes EMO accélérés par GPU, l’équipe a développé une suite de benchmarks nommée MoRobtrol pour le contrôle robotique multiobjectif. Les tâches incluses dans cette suite sont listées dans le Tableau III.
Tableau III : Aperçu des problèmes de contrôle robotique multiobjectif dans la suite de tests de benchmark MoRobtrol proposée
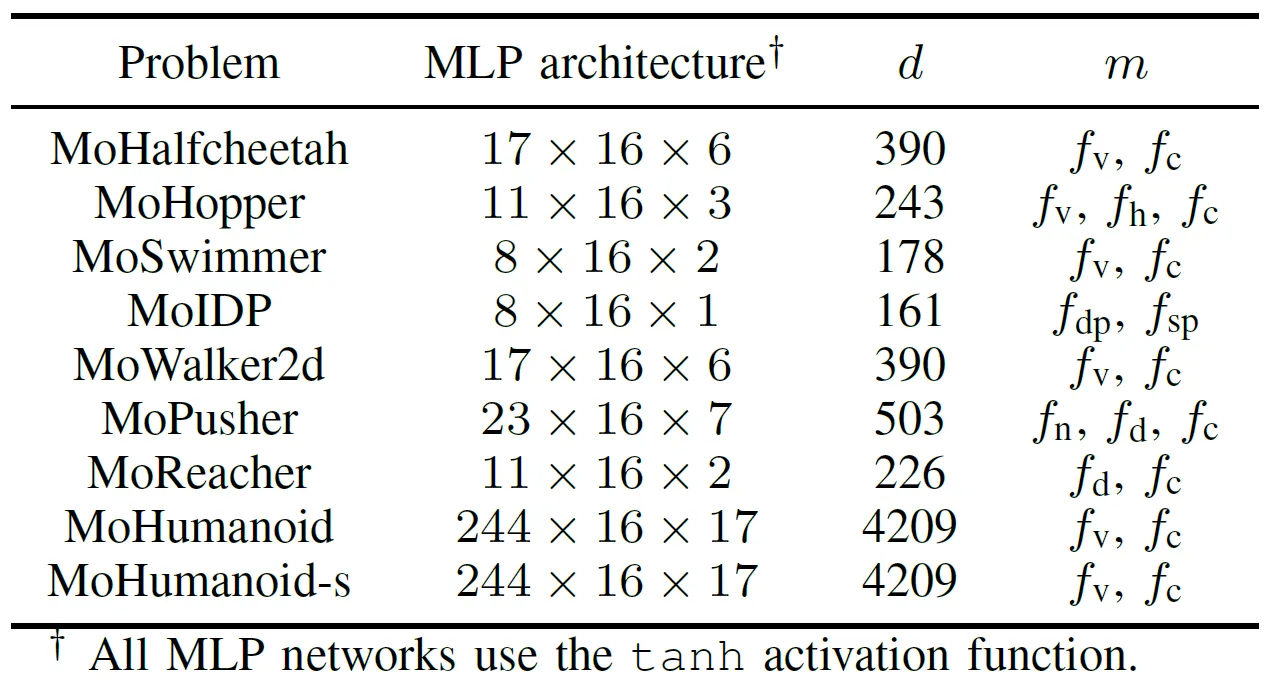
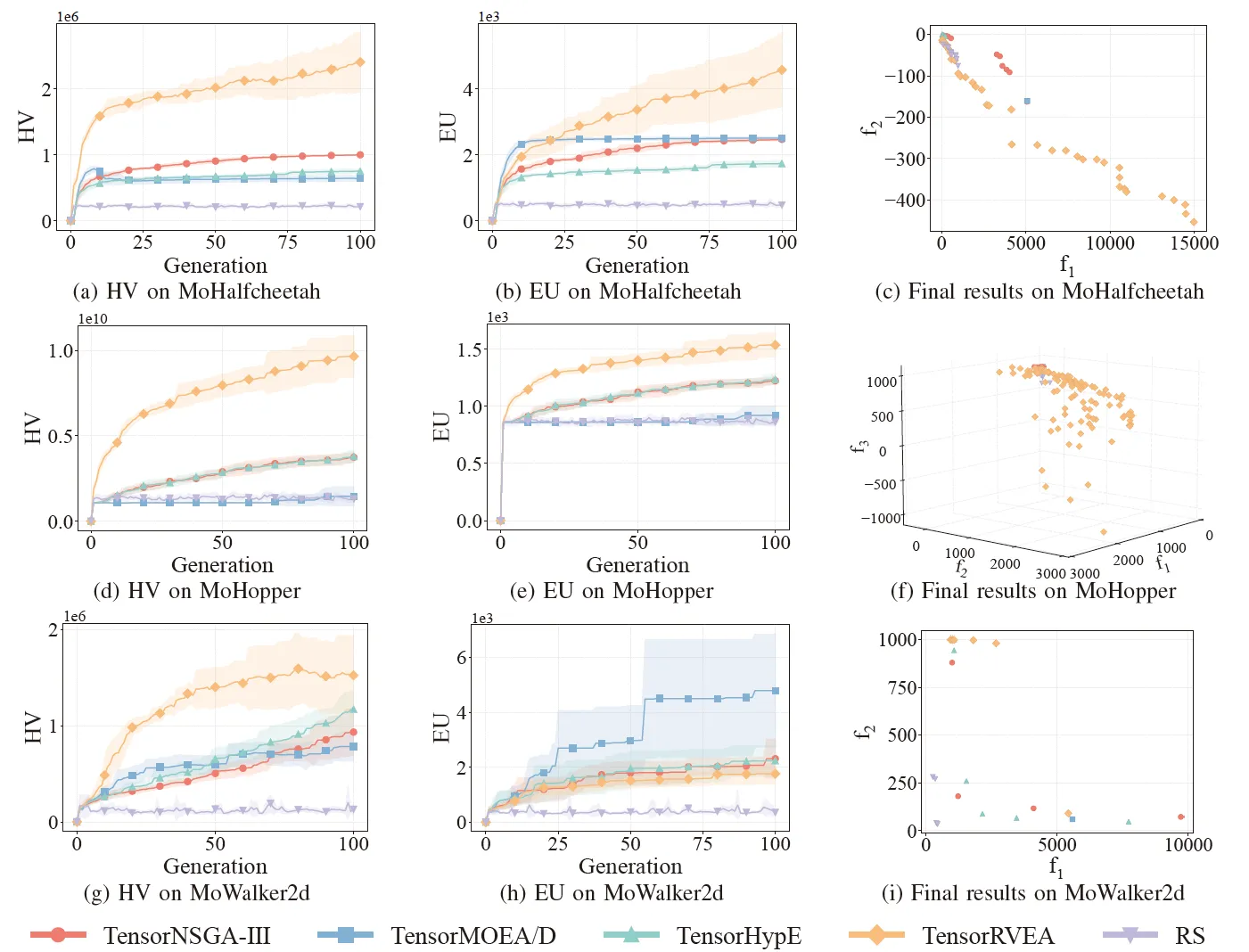
Fig.6 : Performance comparative (HV, EU et visualisation des résultats finaux) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA et de la recherche aléatoire (RS) à travers différents problèmes : MoHalfcheetah (390D), MoHopper (243D) et MoWalker2d (390D). Note : Des valeurs plus élevées pour toutes les métriques indiquent une meilleure performance.
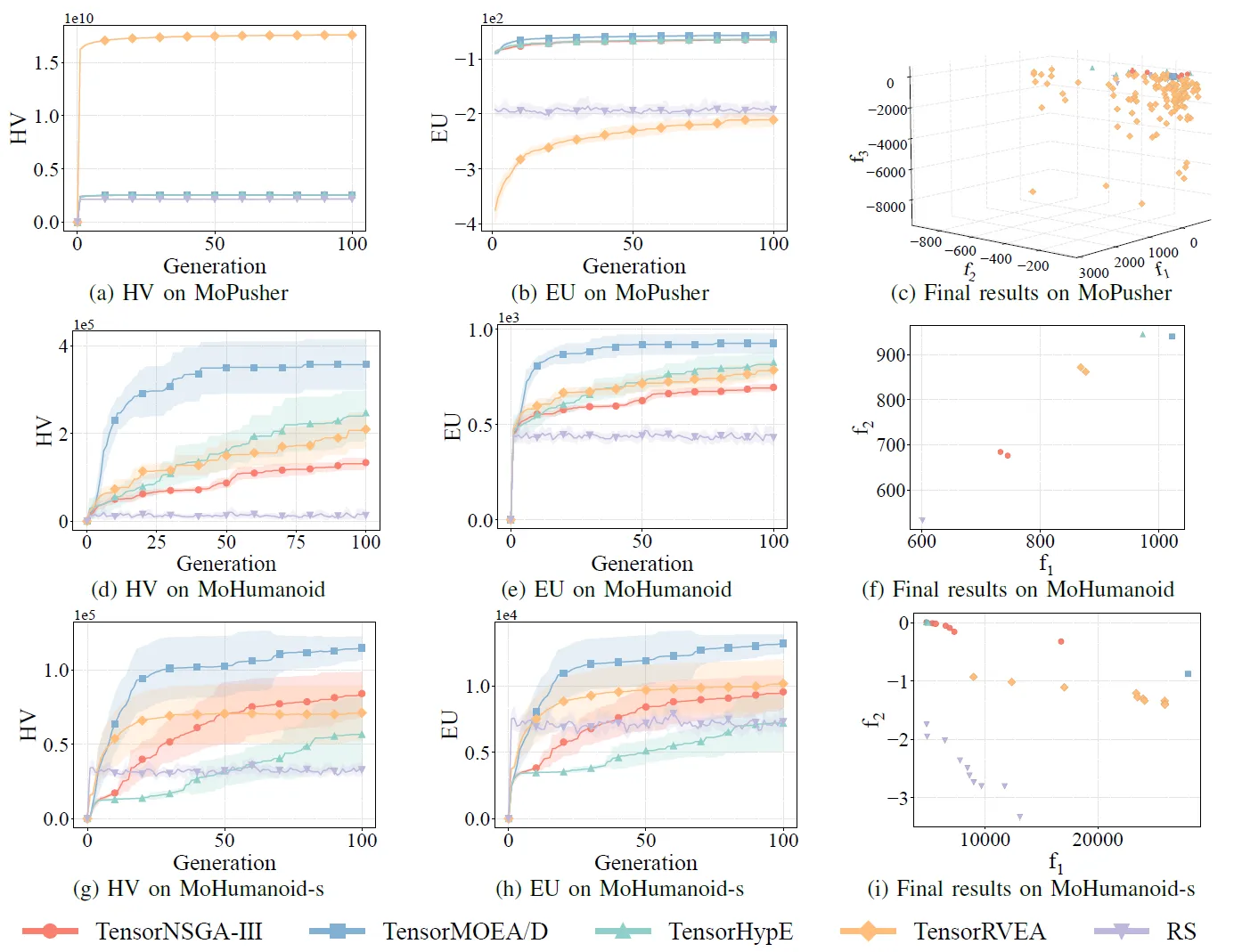
Fig.7 : Performance comparative (HV, EU et visualisation des résultats finaux) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA et de la recherche aléatoire (RS) à travers différents problèmes : MoPusher (503D), MoHumanoid (4209D) et MoHumanoid-s (4209D). Note : Des valeurs plus élevées pour toutes les métriques indiquent une meilleure performance.
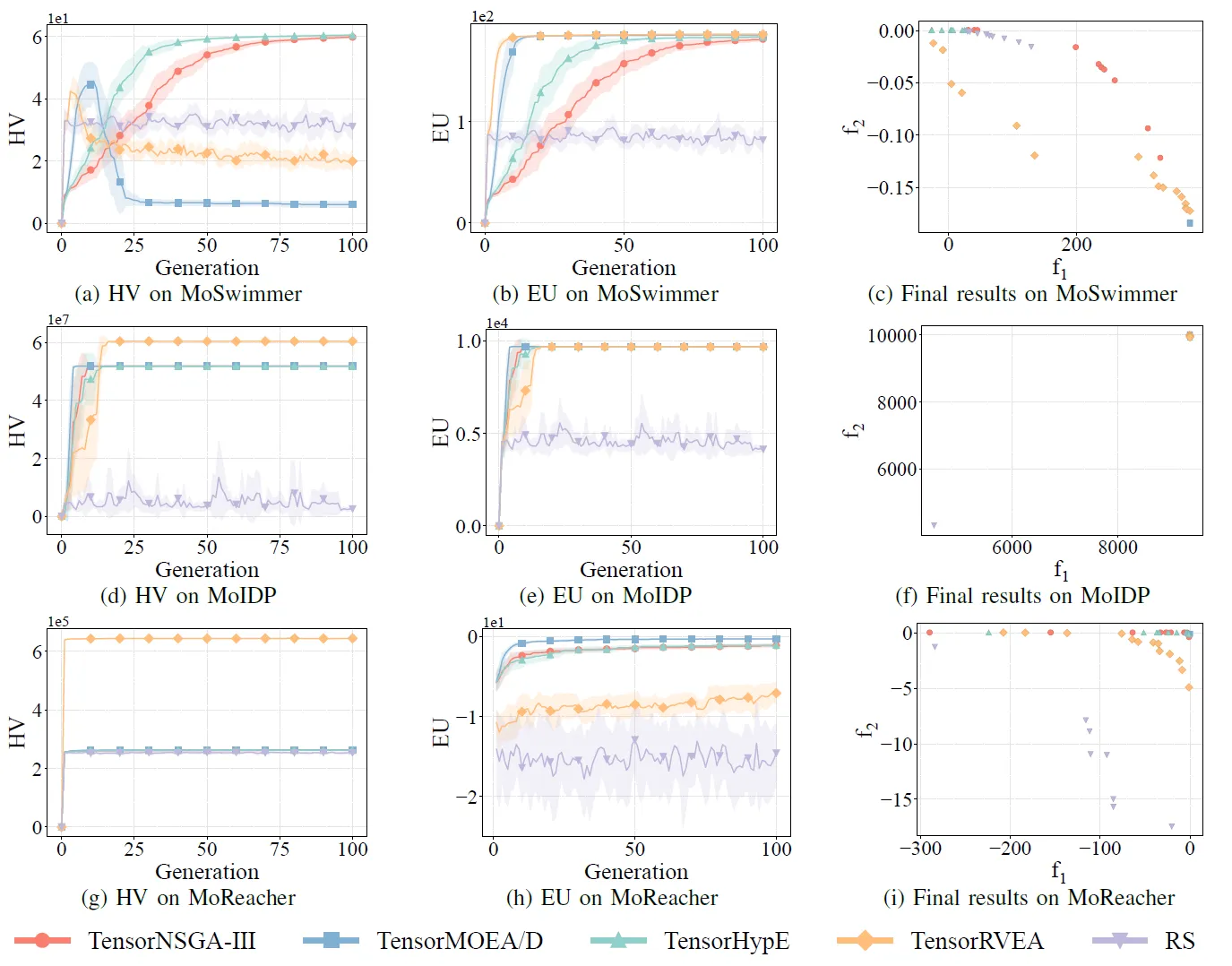
Fig.8 : Performance comparative (HV, EU et visualisation des résultats finaux) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA et de la recherche aléatoire (RS) à travers différents problèmes : MoSwimmer (178D), MoIDP (161D) et MoReacher (226D). Note : Des valeurs plus élevées pour toutes les métriques indiquent une meilleure performance.
Les expériences ont comparé les performances de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA et de la Recherche Aléatoire (RS) au sein du benchmark MoRobtrol. Les résultats montrent que TensorRVEA a obtenu la meilleure performance globale, obtenant les valeurs HV les plus élevées et démontrant une bonne diversité de solutions dans de multiples environnements. TensorMOEA/D a montré une forte adaptabilité dans les tâches à grande échelle, excellant particulièrement dans la cohérence des préférences des solutions. TensorNSGA-III et TensorHypE ont montré des performances similaires et étaient compétitifs sur plusieurs tâches. Dans l’ensemble, les algorithmes tensorisés basés sur la décomposition ont démontré des avantages supérieurs dans la résolution de problèmes complexes et à grande échelle.
Conclusion et Travaux Futurs
Cette étude propose une méthodologie de représentation tensorisée pour remédier aux limitations des algorithmes EMO traditionnels basés sur CPU en termes d’efficacité computationnelle et de scalabilité. L’approche a été appliquée à plusieurs algorithmes représentatifs, notamment NSGA-III, MOEA/D et HypE, obtenant des améliorations de performance significatives sur GPU tout en maintenant la qualité des solutions. Pour valider son applicabilité pratique, l’équipe a également développé MoRobtrol, une suite de benchmarks de contrôle robotique multiobjectif qui reformule les tâches de contrôle robotique dans des environnements de simulation physique en problèmes d’optimisation multiobjectif. Les résultats démontrent le potentiel des algorithmes tensorisés dans des scénarios gourmands en calcul tels que l’intelligence incarnée. Bien que la méthode de tensorisation ait considérablement amélioré l’efficacité algorithmique, il reste de la place pour d’autres améliorations. Les directions futures incluent l’amélioration des opérateurs de base tels que le tri non dominé, la conception de nouvelles opérations tensorisées pour les systèmes multi-GPU et l’intégration de données à grande échelle et de techniques de deep learning pour améliorer encore les performances sur les problèmes d’optimisation à grande échelle.
Code Open Source / Ressources Communautaires
Article :
https://arxiv.org/abs/2503.20286
GitHub :
https://github.com/EMI-Group/evomo
Projet en amont (EvoX) :
https://github.com/EMI-Group/evox
Groupe QQ : 297969717

EvoMO est construit sur le framework EvoX. Si vous souhaitez en savoir plus sur EvoX, n’hésitez pas à consulter l’article officiel sur EvoX 1.0 publié sur notre compte public WeChat pour plus de détails.
