
La programmation génétique est une méthode évolutionnaire qui combine la recherche structurelle et l’interprétabilité. Elle offre des avantages uniques dans des tâches telles que la régression symbolique, la classification et le contrôle — non seulement en optimisant des paramètres, mais aussi en recherchant et en produisant directement des expressions de programme analysables. Cependant, en raison de l’hétérogénéité des structures individuelles et des chemins d’exécution irréguliers, la plupart des implémentations existantes de programmation génétique restent confinées à l’exécution sur CPU et peinent depuis longtemps à s’adapter véritablement aux GPU. Cela limite directement l’efficacité de calcul et complique le traitement de jeux de données massifs ou d’environnements de simulation complexes dans les applications modernes.
Pour relever ce défi, nous proposons le framework EvoGP, en réorganisant de fond en comble la représentation des arbres, la logique des opérateurs génétiques et les mécanismes d’exécution parallèle. Les résultats expérimentaux montrent qu’EvoGP atteint un débit de calcul de pointe supérieur à 10^11 GPops/s, permettant l’évaluation rapide de populations de 500 000 individus en moins d’une seconde — jusqu’à 304× plus rapide que les implémentations GPU existantes. Cette étape marque une rupture définitive avec les barrières d’adaptation matérielle et fait entrer la programmation génétique dans l’ère du calcul haute performance accéléré par GPU.
Le défi de l’adaptation GPU en programmation génétique
Ces dernières années, les GPU sont devenus une infrastructure critique pour le calcul intelligent haute performance, grâce à leur parallélisme massif et à leur débit élevé. Pourtant, la programmation génétique n’a pas réussi à exploiter pleinement cet avantage matériel. L’obstacle principal réside dans l’absence de méthodes de représentation et d’exécution alignées sur les architectures matérielles modernes. Le modèle d’exécution Single Instruction, Multiple Threads (SIMT) des GPU excelle dans le traitement de données régulières, uniformes et traitables par lots. Les individus en programmation génétique, en revanche, présentent une hétérogénéité structurelle marquée — tailles d’arbres, topologies et logiques d’évaluation variables. Une fois placées sur un GPU, ces structures révèlent immédiatement des problèmes tels que l’accès mémoire non contigu, l’allocation dynamique inefficace et une forte divergence des threads.
Par ailleurs, pour exploiter pleinement la puissance de calcul des GPU, un système doit gérer à la fois le parallélisme au niveau des données au sein de chaque arbre et le parallélisme au niveau des individus à l’échelle de la population. Unifier ces deux modes sous une seule stratégie d’ordonnancement, optimiser la disposition mémoire et prévenir les conflits de ressources constituent un défi d’ingénierie système considérable. De nombreuses implémentations passées, en raison de failles de conception fondamentales, n’exploitaient que le parallélisme au niveau des données, laissant une grande partie de la capacité concurrente des GPU inutilisée. EvoGP répond à ce problème de fond : plutôt que de faire tourner la programmation génétique de justesse sur GPU, il fournit une architecture sous-jacente dédiée qui en fait un framework de calcul véritablement prêt pour l’ère GPU.
Représentation tensorisée des structures arborescentes
Pour faire entrer la programmation génétique dans l’ère GPU, la première tâche consiste à éliminer la barrière d’hétérogénéité des structures individuelles. Les structures arborescentes traditionnelles basées sur des pointeurs ou des listes chaînées produisent des dispositions mémoire très irrégulières qui bloquent complètement l’exécution par lots sur GPU. À cette fin, EvoGP introduit une représentation tensorisée innovante, utilisant un schéma d’encodage linéaire par préfixe pour encoder les structures arborescentes sous forme de tableaux contigus contenant les types de nœuds, les valeurs de nœuds et les tailles de sous-arbres.
Pour gérer des arbres de tailles variables, EvoGP introduit une contrainte de longueur maximale autorisée et utilise des valeurs NaN pour l’alignement par remplissage. Grâce à cette conversion, EvoGP transforme avec succès des individus morphologiquement divers au sein d’une population en matrices tensorielles de forme fixe et alignées en mémoire. Cette tensorisation élimine le coût de l’allocation mémoire dynamique et de l’indexation irrégulière, garantissant que le GPU peut effectuer un accès mémoire uniforme et un calcul concurrent à haut débit — posant les bases de l’entrée de l’ensemble du framework dans l’ère GPU.
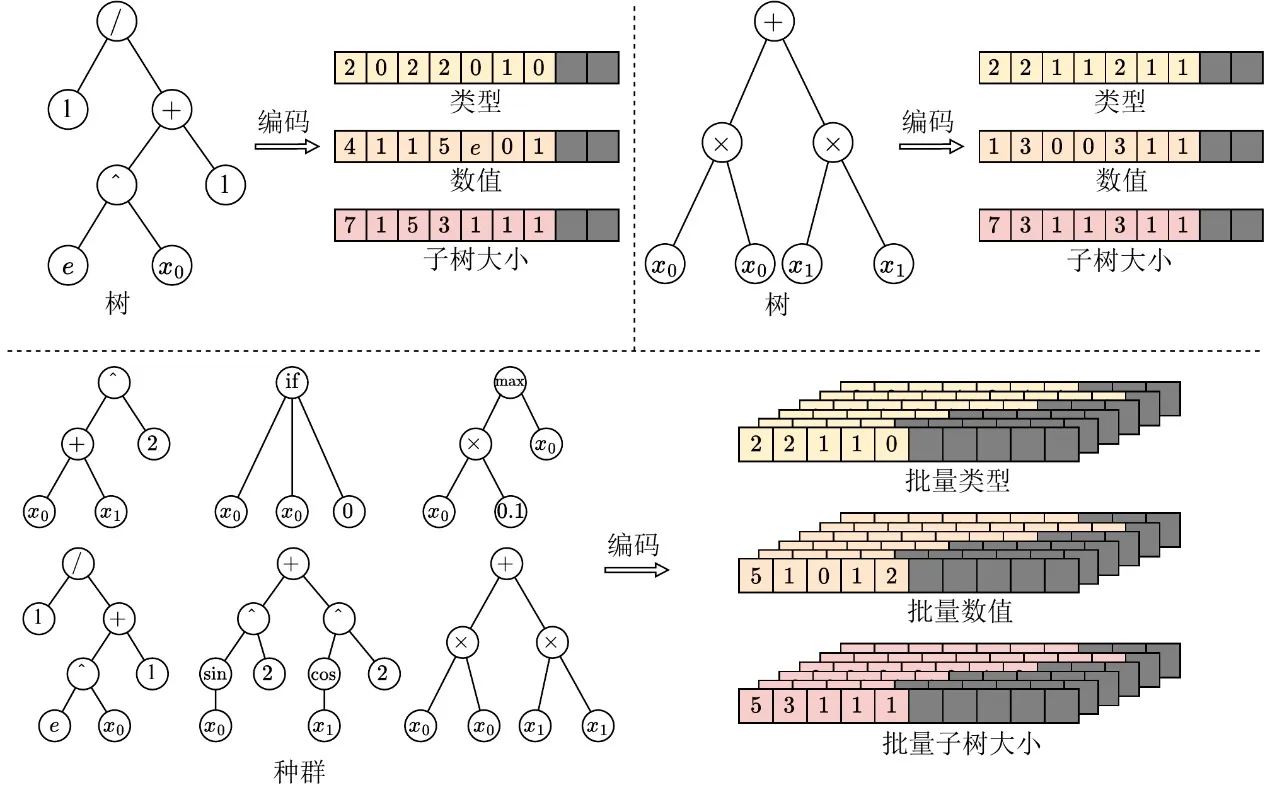
Figure 1 : Représentation tensorisée des structures arborescentes. EvoGP encode les arbres dans une représentation par lots unifiée, permettant un traitement efficace sur GPU d’individus de programme aux structures diverses.
Refactorisation unifiée des opérateurs génétiques
Après avoir achevé la représentation tensorisée des structures arborescentes, EvoGP refactorise davantage les opérateurs génétiques pour les aligner au niveau le plus bas sur l’architecture GPU. Dans les représentations arborescentes traditionnelles, les modifications structurelles telles que le croisement ou la mutation nécessitent généralement une analyse répétée des séquences pour déterminer les limites des sous-arbres, entraînant une complexité temporelle O(n) et rendant l’exécution sur GPU très inefficace. Grâce aux tableaux de tailles de sous-arbres explicitement conservés dans l’encodage tensorisé, le système peut désormais accéder directement aux limites des sous-arbres en O(1), éliminant complètement l’analyse structurelle coûteuse.
S’appuyant sur cet avantage, EvoGP extrait les points communs structurels de divers opérateurs génétiques arborescents — tels que le croisement à un point et la mutation de sous-arbre — et les unifie en une seule primitive de calcul fondamentale : l’échange de sous-arbres. Cela transforme l’évolution structurelle complexe en opérations hautement régulières de découpage mémoire et de concaténation de tenseurs. Cette refactorisation réduit considérablement la surcharge de flux de contrôle lors de l’exécution parallèle, faisant du processus évolutif central de la programmation génétique une forme de calcul bien adaptée au matériel haute performance moderne.
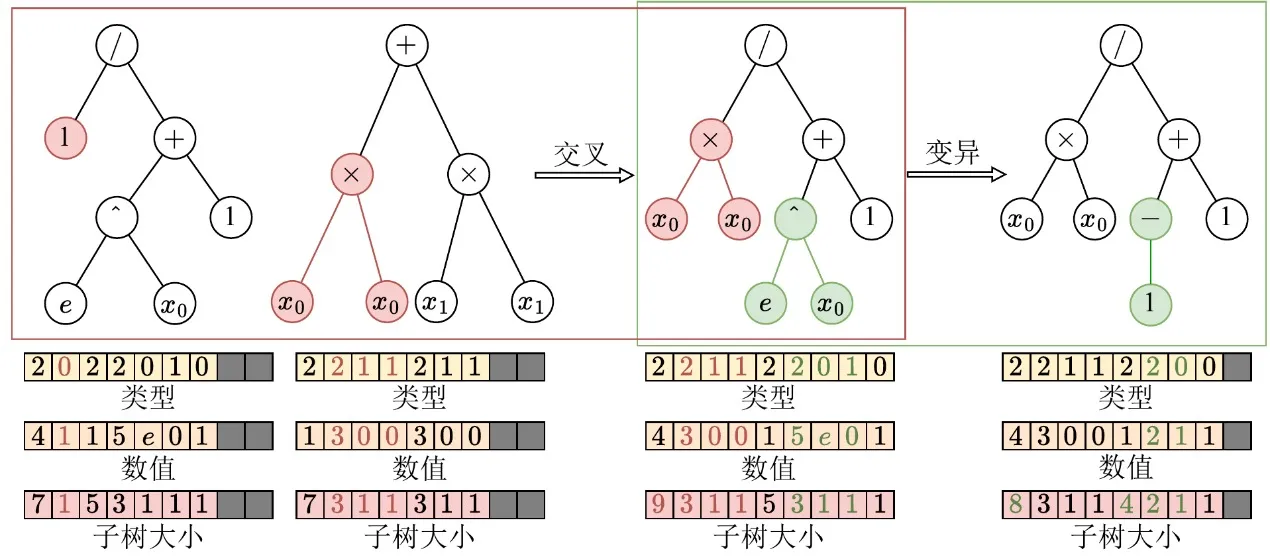
Figure 2 : Opérations unifiées de croisement/mutation. EvoGP unifie plusieurs opérateurs génétiques arborescents sous un mécanisme sous-jacent unique, rendant le processus évolutif central mieux adapté à l’exécution parallèle sur GPU.
Commutation adaptative des stratégies parallèles
Pour prospérer dans l’ère GPU, un algorithme doit être capable d’extraire la puissance de calcul matérielle maximale. Les échelles de données varient considérablement selon les tâches, et une stratégie parallèle unique ne peut pas maintenir une utilisation stable du dispositif. À cette fin, EvoGP conçoit et met en œuvre une stratégie parallèle adaptative qui combine dynamiquement le parallélisme intra-individu et inter-individu en fonction de la taille du jeu de données.
Lors du traitement de jeux de données de petite à moyenne taille, le système adopte un mode parallèle hybride, combinant le parallélisme au niveau des données et au niveau de la population au sein d’un même noyau de calcul — garantissant que lorsque les charges de travail individuelles sont insuffisantes, la concurrence au niveau de la population occupe les cœurs GPU inactifs. Pour les jeux de données à grande échelle, une seule tâche d’évaluation peut saturer le matériel, et le système bascule automatiquement en mode purement data-parallèle, lançant des noyaux de calcul indépendants pour l’évaluation de chaque individu et chargeant les structures arborescentes en mémoire constante en lecture seule — maximisant l’efficacité de diffusion mémoire et améliorant significativement le débit d’accès mémoire. Ce mécanisme adaptatif garantit que le système maintient une efficacité de calcul extrêmement élevée sur des charges de travail diverses, servant de garantie centrale du framework d’accélération GPU.
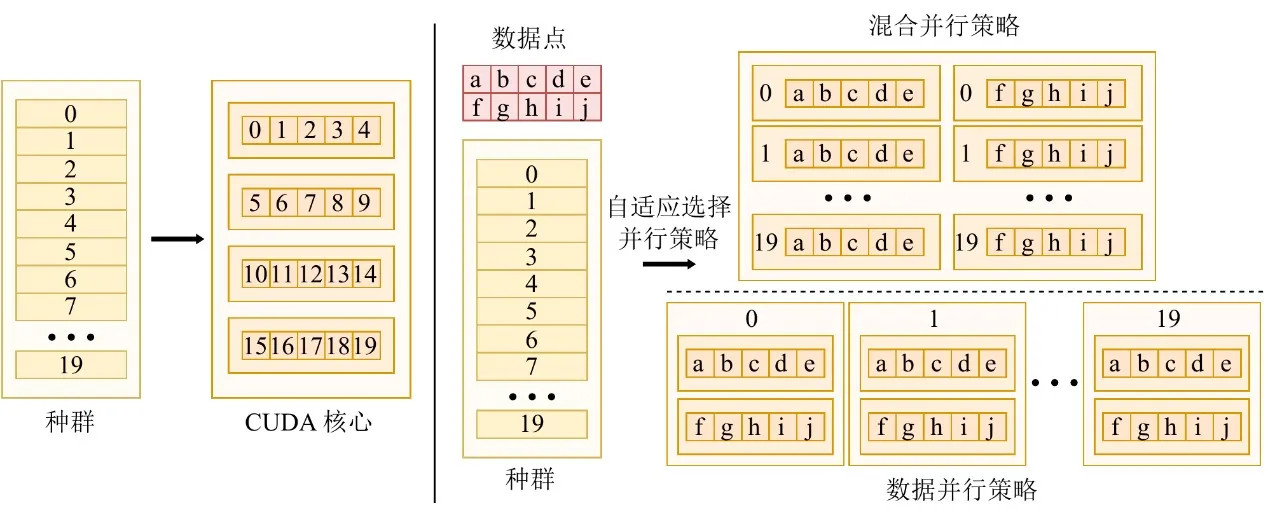
Figure 3 : Mécanisme parallèle adaptatif. EvoGP bascule automatiquement entre différents modes parallèles en fonction de l’échelle de la tâche pour maintenir une efficacité de calcul plus élevée.
Unifier haute performance et facilité d’utilisation
La vitalité d’un framework de calcul haute performance réside non seulement dans la vitesse sous-jacente, mais aussi dans la compatibilité avec l’écosystème et la facilité d’utilisation. De nombreuses applications pratiques sont déployées dans des écosystèmes basés sur Python tels qu’OpenAI Gym, MuJoCo, Brax et Genesis. Tout en visant une accélération GPU extrême, EvoGP parvient à une intégration transparente avec les écosystèmes de développement existants en intégrant des noyaux de calcul CUDA haute performance personnalisés comme opérateurs personnalisés au sein du runtime PyTorch.
De plus, pour exploiter pleinement les avantages de l’architecture GPU, EvoGP adopte un modèle entièrement résident sur GPU, garantissant que les données de population et les contextes d’évaluation sont maintenus intégralement sur le GPU — éliminant complètement la coûteuse surcharge de transfert de données hôte-périphérique courante dans les frameworks traditionnels. Cette philosophie de conception zero-copy permet à EvoGP de s’intégrer naturellement et efficacement aux environnements modernes d’apprentissage par renforcement accélérés par GPU, offrant des capacités de simulation parallèle bout en bout efficaces en tant que système complet équilibrant performance extrême et haute évolutivité.
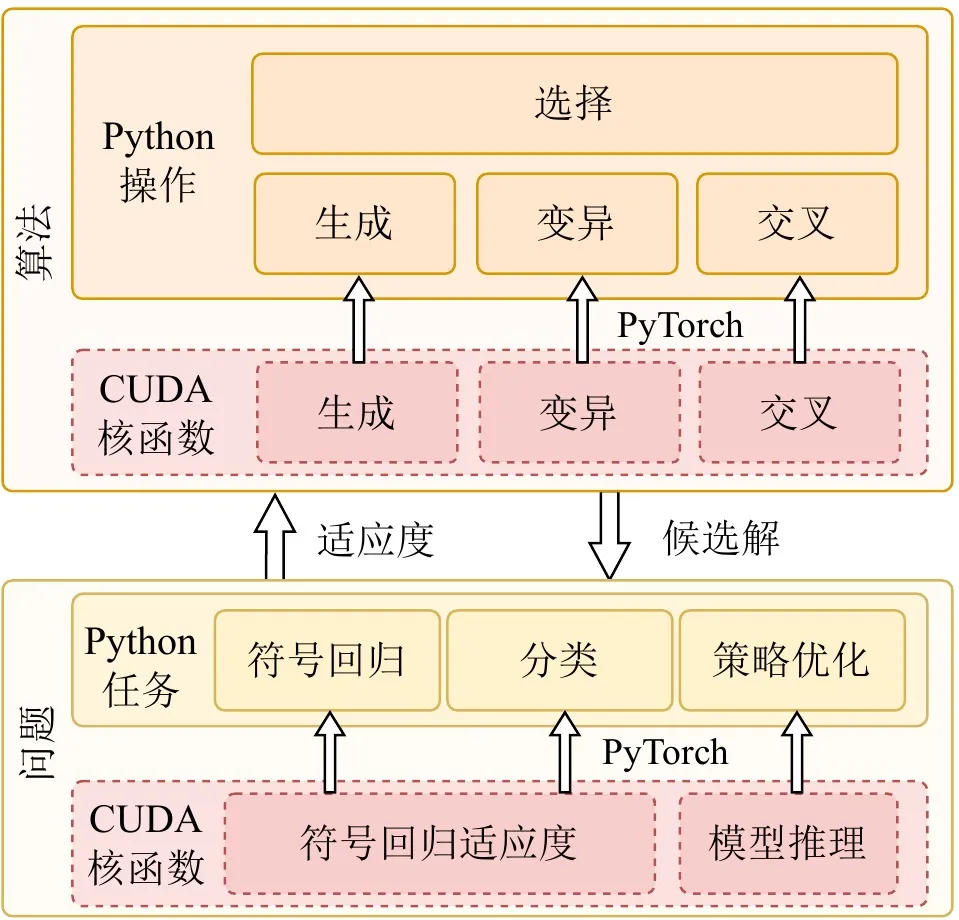
Figure 4 : Architecture globale. EvoGP n’est pas un module d’accélération isolé, mais un framework complet qui équilibre la performance sous-jacente et la facilité d’utilisation de la couche supérieure.
Libérer les performances à grande échelle de population
Franchir les goulots d’étranglement de calcul élargit directement les frontières de recherche des algorithmes évolutionnaires, permettant à la programmation génétique de bénéficier véritablement de l’ère GPU. Par le passé, les configurations de population ultra-large étaient souvent impraticables en raison de coûts de calcul prohibitifs. Sous le mécanisme parallèle au niveau de la population à débit extrêmement élevé d’EvoGP, le traitement de nombres massifs d’individus est devenu véritablement réalisable en pratique.
Les tests de référence principaux montrent que le débit de pointe d’EvoGP dépasse 10^11 GPops/s, démontrant une vitesse remarquable sous une concurrence massive — accomplissant l’évaluation complète de populations jusqu’à 500 000 individus en une seule seconde. En temps d’exécution, il établit une avance décisive sur les implémentations GPU existantes. Plus crucial encore, dans les tests à grande échelle de population, l’algorithme présente une excellente évolutivité : sur la convergence d’erreur en régression symbolique, l’amélioration de la précision en classification et les récompenses cumulées dans les tâches de contrôle robotique, des populations plus importantes produisent systématiquement de meilleures performances finales. Cela prouve qu’EvoGP libère non seulement la vitesse de calcul — il permet à des populations plus importantes d’atteindre des solutions de meilleure qualité en un temps d’exécution plus court, élevant fondamentalement le potentiel de recherche et le plafond de capacité des méthodes de programmation génétique.
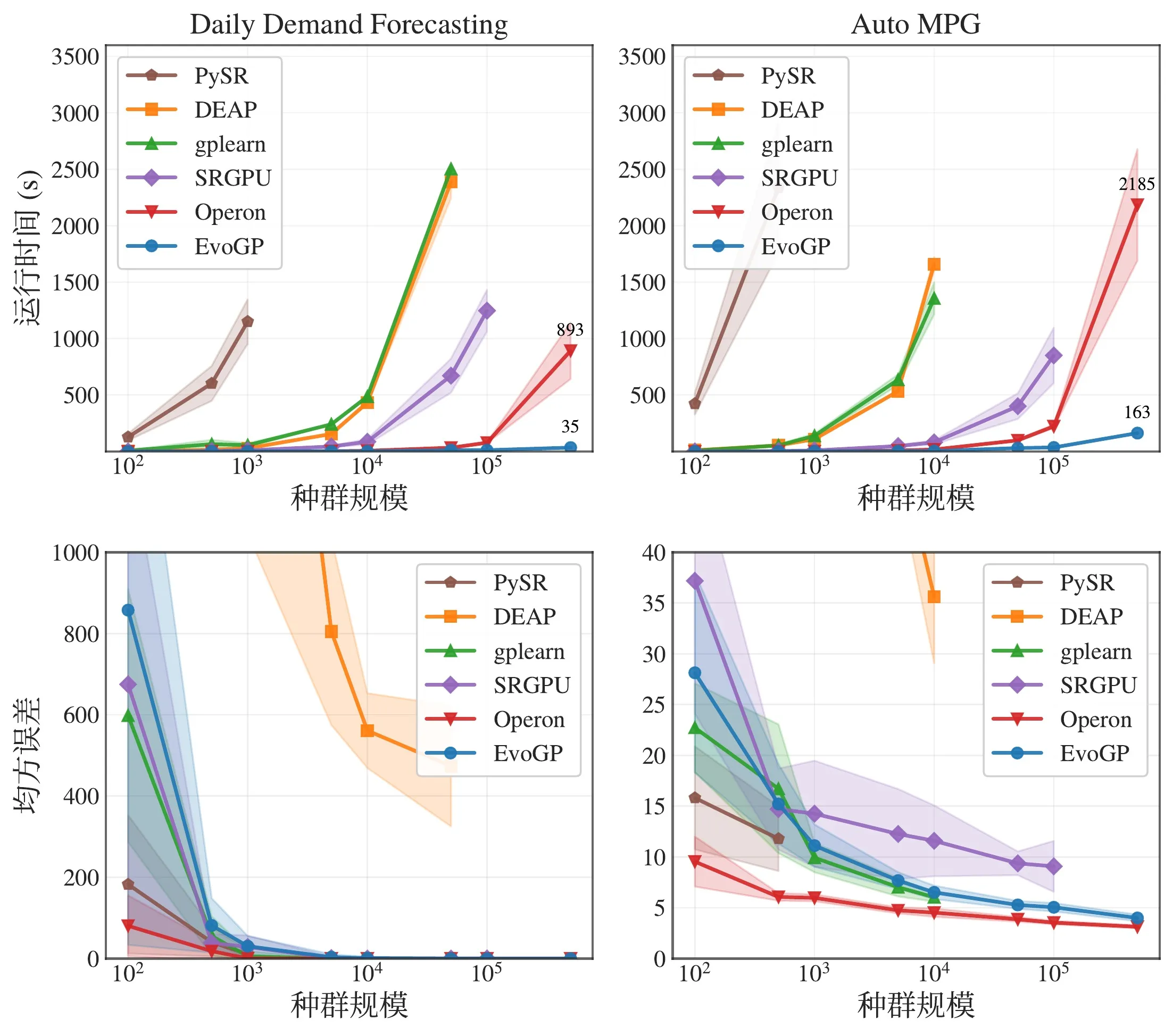
Figure 5 : Comparaison globale des performances. EvoGP obtient des avantages de performance significatifs sur plusieurs configurations de tâches tout en maintenant une qualité de résultats stable.
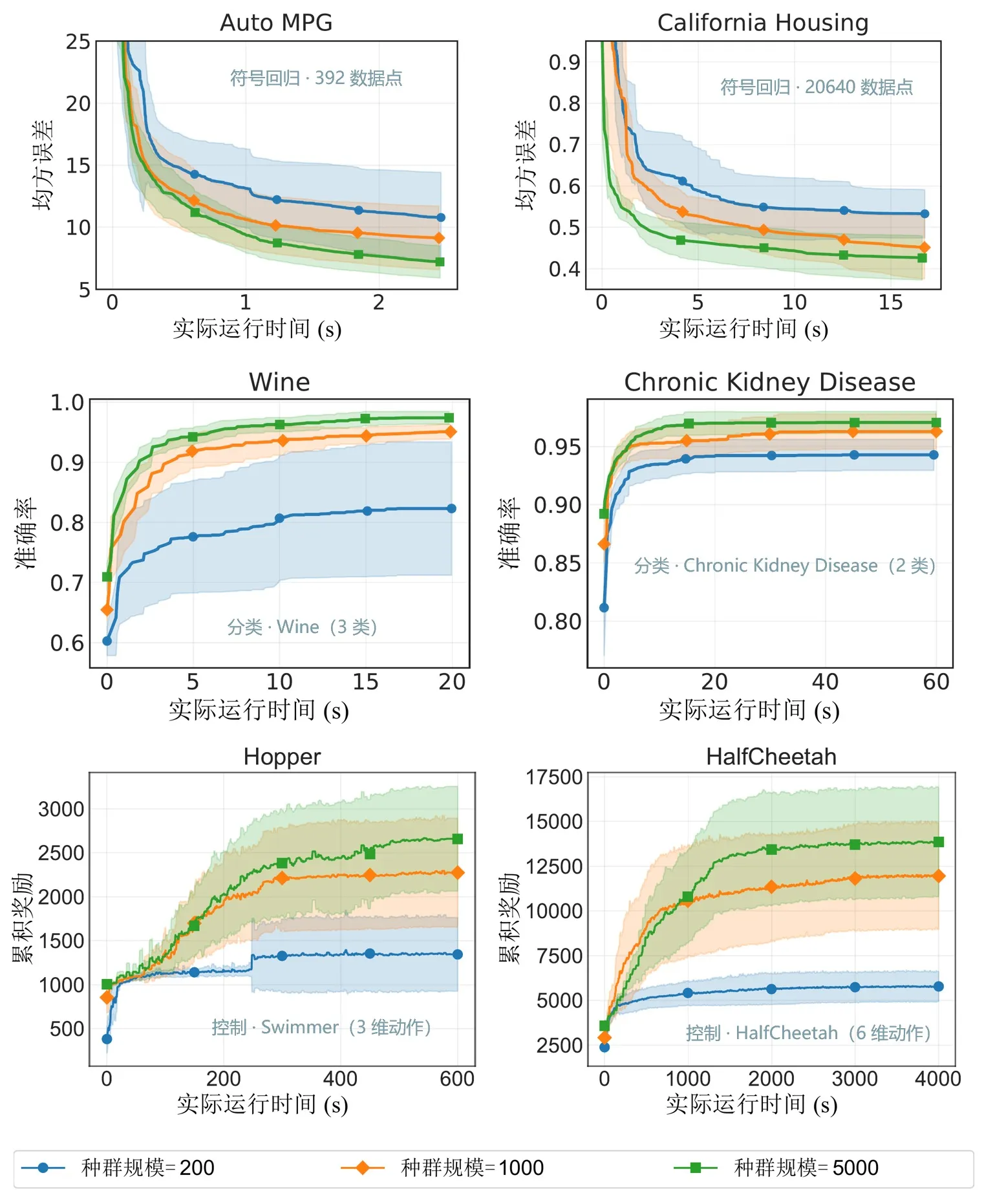
Figure 6 : Performances selon différentes échelles de population. EvoGP rend les tailles de population plus importantes pratiquement utilisables dans un délai acceptable et libère un potentiel de recherche plus fort.
Conclusion
Le framework EvoGP répond systématiquement à la question de savoir comment la programmation génétique peut utiliser efficacement les architectures GPU modernes. Il ne s’agit pas d’un simple correctif aux implémentations existantes, mais d’innovations fondamentales dans la conception sous-jacente grâce à la représentation tensorisée, la refactorisation des opérateurs et le parallélisme adaptatif — ouvrant complètement la voie à l’entrée de la programmation génétique dans les systèmes de calcul haute performance. Ce travail démontre non seulement la vitalité durable des méthodes évolutionnaires classiques à l’ère du calcul, mais fournit également une solution au niveau système hautement évolutive pour l’apprentissage automatique interprétable et la prise de décision des agents autonomes — marquant la véritable entrée de la programmation génétique dans l’ère accélérée par GPU.
Open Source / Communauté
📄 Paper :
https://ieeexplore.ieee.org/document/11390710
🔗 GitHub :
https://github.com/EMI-Group/evogp
🔼 Upstream Project (EvoX) :
https://github.com/EMI-Group/evox
🌐 QQ Group : 297969717

QQ Group | Evolutionary Machine Intelligence