EvoGO : Calcul GPU × Apprentissage Génératif → Un Nouveau Paradigme pour les Algorithmes Évolutionnaires avec une Convergence en 10 Générations

Ces dernières années, les méthodes d’optimisation évolutionnaire pilotées par les données ont fait des progrès remarquables. Des algorithmes évolutionnaires assistés par des modèles de substitution (surrogate-assisted) aux algorithmes évolutionnaires génératifs, l’optimisation évolutionnaire est progressivement passée des paradigmes traditionnels pilotés par des opérateurs fixes à ceux pilotés par l’apprentissage. Cependant, la nature pilotée par les données des méthodes existantes reste incomplète à trois égards importants. Premièrement, la coordination entre le mécanisme génératif et le processus évolutionnaire dépend encore souvent de règles heuristiques conçues manuellement. Deuxièmement, les objectifs d’entraînement des modèles génératifs sont généralement hérités de tâches de génération d’ordre général et ne sont pas suffisamment alignés sur les objectifs d’optimisation. Troisièmement, les échantillons en ligne extrêmement limités mais très précieux disponibles dans l’optimisation en boîte noire n’ont pas encore été systématiquement organisés en une expérience d’optimisation apprenable et transférable. Pour résoudre ces problèmes, l’équipe EvoX a proposé l’Optimisation Générative Évolutionnaire (EvoGO), qui organise l’ensemble du processus d’optimisation en trois étapes unifiées : la préparation des données, l’entraînement du modèle et la génération de la population. L’objectif est de permettre aux algorithmes d’optimisation d’apprendre directement la loi d’amélioration permettant de passer de solutions inférieures à des solutions supérieures à partir de données historiques. Les résultats expérimentaux montrent qu’EvoGO démontre des avantages stables à travers trois catégories de tâches — l’optimisation numérique, le contrôle classique et le contrôle robotique à haute dimension — couvrant 25 tests de référence et des échelles de problèmes allant de 10 à 1000 dimensions, et convergeant sur la plupart des tâches à grande échelle en environ 10 générations. Dans les tâches complexes, lorsqu’il est combiné à l’inférence parallèle sur GPU, EvoGO montre également d’importants avantages pratiques en termes de temps d’exécution ; lorsque CMA-ES atteint ses performances de convergence, EvoGO peut atteindre les mêmes performances jusqu’à 134 fois plus rapidement. Ces résultats indiquent que l’optimisation évolutionnaire entièrement pilotée par les données peut non seulement obtenir des résultats compétitifs sur des benchmarks standard, mais commence également à démontrer sa capacité à fournir un support de conception efficace pour des problèmes d’ingénierie réels.
La Situation : L’Optimisation Pilotée par les Données N’a Toujours Pas Franchi l’Étape Finale
Ces dernières années, les méthodes d’optimisation évolutionnaire pilotées par les données se sont développées rapidement. Les méthodes assistées par des modèles de substitution et les méthodes basées sur des modèles génératifs ont déjà poussé l’optimisation évolutionnaire de la recherche pilotée par des opérateurs fixes vers la recherche pilotée par l’apprentissage. Cela signifie que les modèles d’apprentissage ont commencé à entrer dans de multiples étapes du pipeline, y compris l’évaluation, la modélisation et même la génération.
Pourtant, cette transformation est encore incomplète. Les méthodes existantes ont peut-être appris à « évaluer » ou à « générer » à différents niveaux, mais elles n’ont pas vraiment appris à « optimiser ». D’une part, la production de la prochaine génération de solutions candidates dépend encore souvent de règles heuristiques conçues manuellement pour la coordination. D’autre part, l’objectif de génération et l’objectif d’optimisation sont souvent insuffisamment alignés. Dans le même temps, les échantillons en ligne extrêmement limités disponibles dans l’optimisation en boîte noire n’ont pas encore été systématiquement transformés en une expérience d’optimisation apprenable et transférable.
Par conséquent, ce qui manque vraiment aujourd’hui n’est pas davantage de modèles en soi, mais l’étape finale : permettre aux algorithmes d’optimisation d’apprendre directement le processus de passage de pires solutions à de meilleures solutions à partir de données historiques. C’est exactement l’étape qu’EvoGO cherche à faire avancer.
La Percée : Comment EvoGO Réécrit le Pipeline d’Optimisation
Pour résoudre les problèmes ci-dessus, EvoGO ne poursuit pas la voie traditionnelle consistant à améliorer les opérateurs locaux tels que le croisement et la mutation. Au lieu de cela, il tente de réécrire le pipeline d’optimisation à un niveau plus holistique. Son idée principale est de retirer le processus de « comment générer la prochaine génération de solutions candidates » des règles écrites manuellement pour le confier à un mécanisme génératif piloté par les données afin de l’apprendre. Plus précisément, EvoGO organise l’ensemble du processus d’optimisation en trois étapes unifiées — la préparation des données, l’entraînement du modèle et la génération de la population — de sorte que l’organisation de l’expérience, l’apprentissage directionnel et la mise à jour de la population ne soient plus fragmentés, mais plutôt intégrés dans une seule boucle d’optimisation.
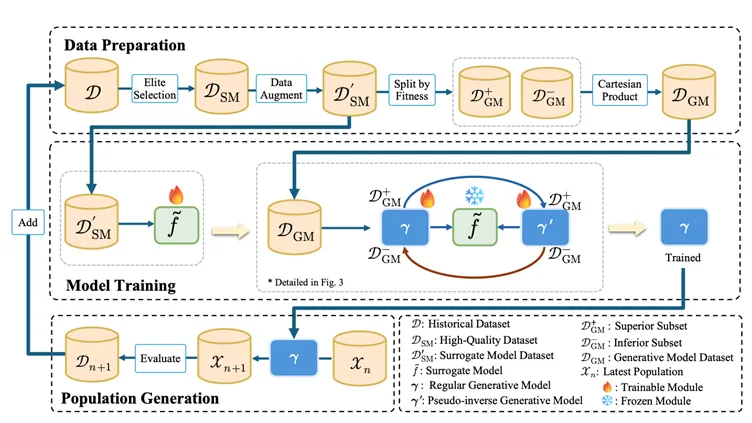
Lors de l’étape de préparation des données, EvoGO filtre d’abord des échantillons de haute qualité à partir des populations historiques pour construire une base d’entraînement plus fiable. Lorsque les échantillons sont rares, l’augmentation apprise (learned augmentation) peut également être utilisée pour atténuer la pénurie de données. Plus important encore, les échantillons sont ensuite divisés en solutions supérieures et inférieures et organisés en relations appariées. En conséquence, ce que le modèle apprend n’est plus seulement une distribution statique de solutions candidates, mais plutôt la relation directionnelle permettant de passer de solutions inférieures à des solutions supérieures.
Lors de l’étape d’entraînement du modèle, EvoGO adopte une structure appariée composée d’un modèle de substitution (surrogate model), d’un générateur direct (forward generator) et d’un générateur pseudo-inverse. Le modèle de substitution fournit une caractérisation approximative du paysage de l’objectif ; le générateur direct apprend la cartographie (mapping) des solutions inférieures vers les solutions supérieures ; et le générateur pseudo-inverse maintient la stabilité de l’entraînement via une contrainte de cohérence de reconstruction. Contrairement aux tâches de génération générales, l’objectif d’entraînement ici n’est pas simplement de s’ajuster à la distribution des données, mais de s’assurer que le processus de génération se dirige vers de meilleures régions sous la direction du paysage de l’objectif.
Lors de l’étape de génération de la population, le modèle génératif entraîné agit directement sur la population actuelle pour produire une nouvelle génération de solutions candidates en parallèle. Ces solutions sont ensuite évaluées par la véritable fonction objectif, et l’état de la population est mis à jour en conséquence avant d’entrer dans la prochaine itération. À ce stade, la façon dont les mises à jour de la population sont effectuées change fondamentalement. L’optimisation évolutionnaire traditionnelle repose principalement sur des règles de croisement, de mutation et de sélection spécifiées manuellement pour sonder progressivement l’espace de recherche, tandis qu’EvoGO transforme ce processus en un mécanisme de mise à jour parallèle piloté par des données historiques et implémenté par un modèle génératif.
Le parallélisme d’EvoGO opère à deux niveaux. D’une part, la population peut être représentée sous une forme tensorisée, ce qui permet de générer et d’évaluer les individus en parallèle sur le GPU. D’autre part, EvoGO peut également exécuter plusieurs modèles génératifs simultanément sur un seul GPU, permettant une optimisation parallèle à travers différentes graines aléatoires (random seeds) ou différentes instances de problèmes. Sa capacité parallèle existe donc à la fois au sein des populations et à travers de multiples populations.
De ce point de vue, la contribution clé d’EvoGO n’est pas simplement l’introduction d’un modèle génératif, mais l’unification de l’organisation des échantillons, de l’alignement des objectifs et de la mise à jour de la population au sein d’un cadre méthodologique unique. L’optimisation évolutionnaire traditionnelle met l’accent sur la recherche pilotée par des règles pré-écrites, tandis qu’EvoGO va un pas plus loin en tentant de laisser le système apprendre le processus de recherche lui-même directement à partir de données historiques.
Validation : Analyse des Performances et des Mécanismes
Pour évaluer rigoureusement l’efficacité de ce nouveau paradigme entièrement piloté par les données, l’article se concentre sur trois questions clés : EvoGO est-il suffisamment puissant et efficace ? Quels sont les choix de conception cruciaux derrière son succès ? Quel comportement de recherche intelligent présente-t-il ?
1. Comparaison des Performances : La « Convergence en 10 Générations » en Tête des Benchmarks
L’article mène une évaluation systématique sur trois catégories de tâches — l’optimisation numérique, le contrôle classique et le contrôle robotique à haute dimension — couvrant 25 tests de référence avec des dimensions de problèmes allant de 10 à 1000. EvoGO est comparé de manière exhaustive avec l’optimisation bayésienne, les stratégies d’évolution classiques, les méthodes heuristiques et les méthodes avancées assistées par des modèles de substitution.
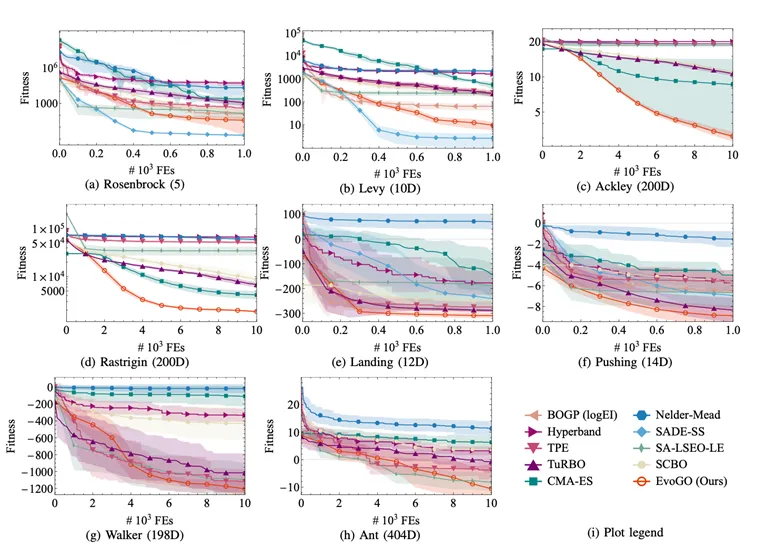

Dans l’ensemble, EvoGO montre des avantages évidents sur la plupart des tâches. Fait notable, cet avantage ne se limite pas aux problèmes de faible dimension ou relativement réguliers. Au contraire, à mesure que la dimensionnalité du problème et la complexité de la tâche augmentent, l’avantage d’EvoGO devient souvent plus prononcé. Dans des conditions de faible dimension et de petits échantillons, certaines des méthodes assistées par des modèles de substitution les plus solides restent très compétitives. Mais une fois que les problèmes deviennent hautement dimensionnels, complexes et dépendants du calcul parallèle, le mécanisme génératif d’EvoGO est capable de se déployer plus pleinement, et sur la plupart des tâches à grande échelle, il peut converger en environ 10 générations. Cela suggère que la valeur d’EvoGO ne réside pas dans l’obtention d’une supériorité locale sur un seul type de problème, mais dans le fait qu’il est mieux adapté à l’utilisation d’expériences à grande échelle et à la recherche parallèle requises par l’optimisation en boîte noire complexe.
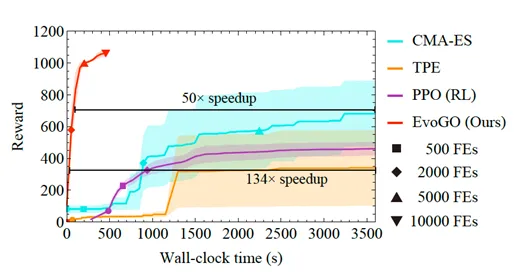
Ceci est particulièrement évident dans l’environnement de contrôle robotique à haute dimension Hopper dans Brax. Sous le même budget d’évaluation de fonction et le même budget de temps d’exécution, EvoGO surpasse de manière significative les algorithmes d’optimisation traditionnels tels que CMA-ES et TPE, et surpasse également l’algorithme d’apprentissage par renforcement PPO, qui nécessite une interaction en ligne avec l’environnement. Plus important encore, grâce à la puissance de calcul parallèle du matériel moderne tel que les GPU, EvoGO peut atteindre un niveau de récompense élevé en environ 500 secondes. Lorsque CMA-ES finit par converger vers son meilleur niveau de performance, le temps réel (wall-clock time) nécessaire pour qu’EvoGO atteigne la même performance est beaucoup plus court — jusqu’à 134 fois plus rapide. Ce résultat montre que l’avantage d’EvoGO n’est pas seulement de réduire le nombre de générations, mais réside dans le fait que son processus de recherche lui-même est mieux adapté aux ressources de calcul parallèle, compressant les actions d’optimisation qui seraient autrement réparties sur de nombreuses générations en un processus de mise à jour génératif à haut débit.
2. Étude d’Ablation : Décrypter les Clés du Succès
Afin de vérifier la nécessité des composants de base dans la conception « entièrement pilotée par les données » d’EvoGO, l’équipe de recherche a mené des études d’ablation systématiques centrées sur l’architecture générative appariée, le mécanisme de guidage par modèle de substitution et la conception de l’objectif orientée vers l’optimisation. Cinq variantes ont été construites : une version à générateur unique, une version sans modèle de substitution, une version à objectif antagoniste, une version de modèle de substitution basé sur MLP, et une version de modèle de substitution heuristique.
Les résultats expérimentaux montrent que l’architecture générative appariée, le mécanisme de guidage par modèle de substitution et la conception de l’objectif orientée vers l’optimisation sont tous cruciaux pour l’efficacité d’EvoGO. La suppression du générateur pseudo-inverse entraîne une stabilité de convergence nettement pire et une diversité de population réduite, ce qui indique que la structure appariée formée par la génération directe et les contraintes inverses est nécessaire pour maintenir la stabilité de l’entraînement et éviter l’effondrement de mode (mode collapse). La suppression du modèle de substitution, ou le remplacement de l’objectif d’optimisation d’origine par un objectif antagoniste général, entraîne également une dégradation significative des performances, montrant que le guidage par le modèle de substitution et l’alignement des objectifs sont au cœur de l’avantage de la méthode. Le remplacement du processus gaussien par un perceptron multicouche (MLP) ou des règles heuristiques laisse toujours la méthode fonctionnelle, mais avec un léger déclin global, ce qui indique qu’EvoGO ne dépend pas d’une forme spécifique de modèle de substitution, bien qu’une modélisation explicite de l’incertitude soit plus bénéfique pour les performances. Dans l’ensemble, les gains de performance d’EvoGO ne proviennent d’aucun module unique, mais de la synergie entre l’architecture générative appariée, le mécanisme de guidage par modèle de substitution et la conception de l’objectif orientée vers l’optimisation.
3. Visualisation du Comportement : Révéler un Processus Dynamique Piloté par les Données
Afin d’analyser plus intuitivement la dynamique de recherche d’EvoGO, l’article présente une expérience de visualisation sur la fonction bidimensionnelle de Ackley, avec une taille de population fixée à 100. Plus précisément, à différentes générations évolutives, les résultats de la transformation du générateur direct entraîné sur les solutions d’entrée sont enregistrés — c’est-à-dire que le processus de cartographie des solutions d’entrée vers les solutions de sortie est suivi. Sur la figure, les flèches représentent des vecteurs allant des solutions d’entrée aux solutions de sortie, et leurs couleurs correspondent aux longueurs de vecteur. L’étoile marque l’optimum global, et les boîtes en pointillés indiquent les régions couvertes par les solutions générées à différentes générations. Par souci de clarté, les paramètres de translation et de rotation du paysage de la fonction sont omis dans cette visualisation.
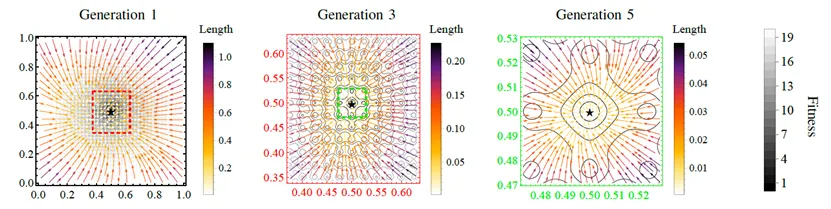
Les résultats de la visualisation montrent que ce qu’EvoGO apprend n’est pas une perturbation aléatoire sans direction, mais un modèle de mise à jour qui s’adapte en fonction de l’étape de recherche. Au stade initial, les vecteurs générés sont généralement plus longs, ce qui indique que l’algorithme tend vers une exploration globale à grande amplitude. À mesure que l’évolution progresse, la longueur des vecteurs diminue progressivement et les régions générées continuent de se contracter, ce qui montre que la recherche se déplace vers une exploitation (exploitation) locale plus fine. Dans le même temps, les vecteurs dans leur ensemble se rassemblent vers la région optimale, ce qui indique que le générateur direct a déjà extrait une direction de recherche concrètement significative à partir des échantillons historiques. Au niveau comportemental, ce phénomène soutient la propriété centrale d’EvoGO : il n’apprend pas seulement la distribution des solutions candidates, mais la loi de mise à jour qui fait passer de l’état actuel vers un meilleur état.
Application : Validation en Ingénierie sur une Aile Supercritique d’Avion de Ligne Gros-Porteur
La livraison réussie du C919 marque une étape cruciale pour la Chine dans le développement de gros avions de ligne produits au niveau national. Cependant, en tant qu’avion monocouloir, le C919 dessert principalement des liaisons court et moyen-courriers, et des avancées dans le domaine des gros-porteurs sont encore nécessaires. Pour répondre aux besoins de développement de la prochaine génération d’avions gros-porteurs nationaux, la conception d’ailes supercritiques est devenue un enjeu clé de l’optimisation aérodynamique, jouant un rôle important dans la réduction de la traînée de croisière, l’amélioration de l’efficacité énergétique et l’amélioration de la stabilité en vol. Par conséquent, comment réaliser une optimisation efficace et fiable de l’aile supercritique est devenu un défi technique central dans le processus de développement des avions gros-porteurs de la Chine.
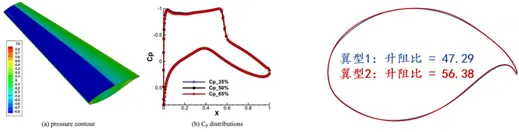
Comme le montre l’article original, en optimisant des caractéristiques géométriques telles qu’une corde plus longue, une surface supérieure plus plate et une cambrure du bord de fuite augmentée, une aile supercritique peut réguler la distribution de la pression transsonique, supprimer la formation d’ondes de choc, réduire la traînée d’onde et améliorer l’efficacité de la portance. Cependant, sa conception optimale fait face à de multiples défis. D’une part, dans les conditions de nombre de Reynolds élevé des avions gros-porteurs, la conception doit satisfaire simultanément à des contraintes aérodynamiques strictes telles que la finesse, le coefficient de portance et l’angle d’attaque de croisière, ce qui impose des exigences de précision extrêmement élevées sur les paramètres de forme. D’autre part, il existe une relation de couplage fortement non linéaire entre la géométrie du profil aérodynamique (airfoil) et les performances aérodynamiques, qu’il est difficile de caractériser avec précision par les méthodes de modélisation traditionnelles. De plus, le processus de conception existant dépend fortement de l’expérience, de simulations CFD répétées et d’expériences en soufflerie, ce qui entraîne un coût de calcul élevé, de longs cycles de développement et une difficulté à s’approcher efficacement de l’optimum global dans un espace de conception de grande dimension.
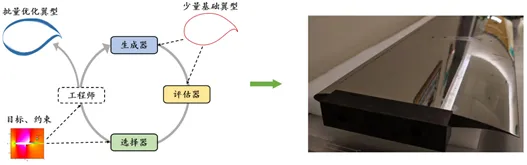
Pour résoudre ce problème, l’équipe EvoX a construit un pipeline de conception intégré basé sur EvoGO, comprenant l’évaluation des performances, la génération de profils aérodynamiques et la sélection des candidats. Sur la base d’un petit nombre d’échantillons historiques de profils aérodynamiques, la méthode construit un modèle d’évaluation des performances, un modèle de génération de profils aérodynamiques et un modèle de sélection, et améliore continuellement la conception des profils par évolution itérative. Un modèle de substitution est utilisé pour prédire avec précision des paramètres clés tels que la finesse, le coefficient de portance et l’angle d’attaque de croisière. Parallèlement, un mécanisme génératif est introduit pour remplacer la recherche heuristique traditionnelle, permettant une approximation efficace de l’optimum dans un espace de conception de grande dimension. Combinée à une stratégie de sélection des candidats, cette méthode peut identifier rapidement les profils aérodynamiques candidats qui satisfont à la fois aux contraintes physiques et aux exigences de performances aérodynamiques dans un vaste espace de recherche, améliorant ainsi l’efficacité de la conception.
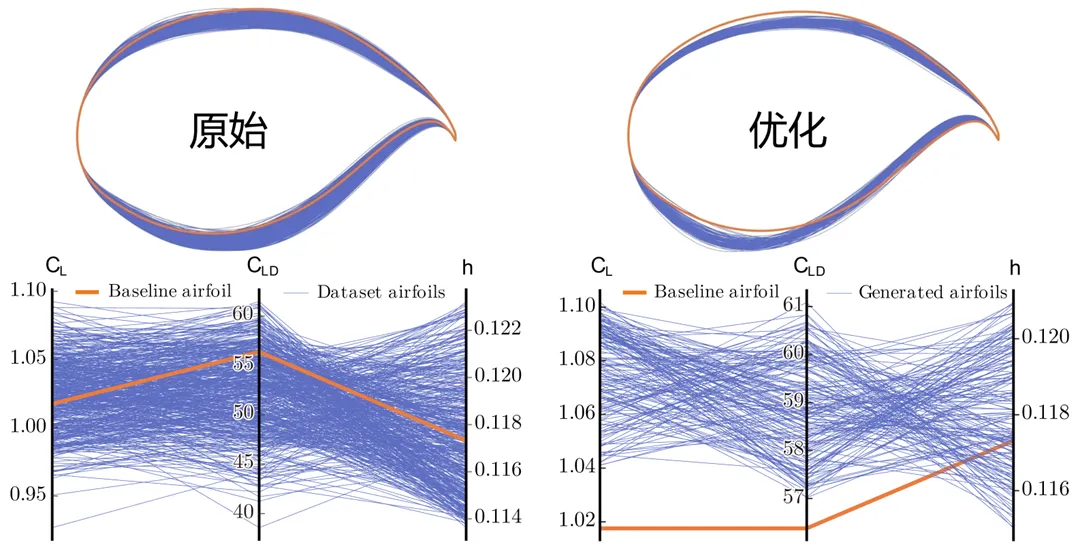
En utilisant seulement 500 échantillons historiques de profils aérodynamiques, la méthode atteint plus de 99,5 % de précision de prédiction sur trois indicateurs aérodynamiques clés — la finesse, le coefficient de portance et l’angle d’attaque de croisière — et le taux de qualification des profils générés automatiquement dépasse 95 %. Ces résultats indiquent que les méthodes d’optimisation évolutionnaire entièrement pilotées par les données telles qu’EvoGO peuvent non seulement obtenir de bons résultats lors de tests de référence standard, mais commencent également à démontrer leur capacité à fournir un support de conception efficace pour des problèmes d’ingénierie réels.
Approfondissement : De la Physique à la Philosophie, Réinterpréter EvoGO
Perspective Physique : De l’Essai et Erreur Désordonné à l’Évolution Ordonnée
D’un point de vue physique, l’optimisation en boîte noire peut être comprise comme un processus de recherche progressive d’un état plus stable au sein d’un champ de potentiel réel mais incomplètement observable. Pour l’optimiseur, la fonction objectif et son paysage d’adaptation (fitness landscape) existent objectivement à tout moment, mais au moment initial, le système ne peut acquérir des connaissances locales que par un échantillonnage et une évaluation limités. La recherche comporte donc naturellement une grande incertitude.
L’optimisation évolutionnaire traditionnelle s’appuie davantage sur des perturbations locales et des essais et erreurs aléatoires. Bien qu’elle puisse progressivement s’approcher de meilleures régions grâce à des échantillonnages et des sélections répétés, le processus de recherche se manifeste encore largement par une exploration locale à haute entropie, et il est difficile d’accumuler systématiquement l’expérience historique. Ce qui distingue EvoGO, c’est qu’il organise davantage les échantillons historiques en une base d’informations qui encode la direction et la structure. Le modèle de substitution fournit une compréhension approximative du paysage local de l’objectif ; l’appariement des solutions supérieures et inférieures extrait des informations directionnelles sur le passage de régions plus mauvaises à de meilleures régions ; et la boucle formée par la génération directe et les contraintes inverses permet à ce processus de mise à jour directionnelle de se dérouler en continu tout en restant stable.
En termes physiques, EvoGO s’apparente davantage à un processus dans lequel une structure ordonnée se forme progressivement sous la direction d’un champ de potentiel efficace. Ce qu’il fait ne consiste pas simplement à accélérer la recherche, mais à réduire progressivement l’incertitude de recherche sous une observabilité limitée, transformant la mise à jour de la population d’un processus d’essais et erreurs désordonné en un flux évolutif organisé. La vitesse n’est que le résultat ; le changement plus profond est que l’expérience historique commence à être transformée en informations structurelles qui peuvent être accumulées, transmises et réutilisées.
Perspective Philosophique : Du « Dao Engendre Toutes Choses » à la Génération de Lois
D’un point de vue philosophique, ce qui est encore plus digne d’être souligné à propos d’EvoGO, c’est qu’il incarne un processus génératif passant de l’expérience à l’ordre, et du local au global. Ce processus peut être résumé par la phrase classique : « Le Dao engendre le Un, le Un engendre le Deux, le Deux engendre le Trois, et le Trois engendre toutes choses. »
Le « Dao » correspond à la véritable loi objectivement existante, mais pas entièrement saisissable, du problème ciblé. En optimisation, la solution optimale n’est pas prescrite subjectivement par l’algorithme ; elle est plutôt toujours latente dans la véritable fonction objectif et son paysage d’adaptation. Ce que l’algorithme peut faire, ce n’est pas de créer le Dao, mais seulement de s’en approcher continuellement.
Le « Un » correspond à la structure unifiée extraite d’une expérience désordonnée. Les échantillons historiques ne sont initialement rien de plus que des traces de recherche dispersées ; ils ne constituent pas automatiquement des connaissances. Ce n’est que lorsque ces échantillons sont triés, filtrés et organisés que l’expérience commence à passer du désordre à un tout apprenable. C’est le sens de « engendrer le Un ».
Le « Deux » correspond à la différenciation — à l’émergence de la direction. La division entre les solutions supérieures et inférieures ne représente pas simplement la distinction entre le bon et le mauvais ; plus important encore, elle marque la première fois que le système acquiert un sens de la direction à partir de l’expérience. Sans cette différenciation, l’expérience est simplement accumulée ; avec elle, l’expérience acquiert une tension évolutive.
Le « Trois » correspond à la fermeture — à la génération de relations. Lorsque la cognition objective, la progression directe et la contrainte inverse forment conjointement un système auto-cohérent, l’optimisation n’est plus un collage d’opérations locales, mais commence à prendre forme en tant que mécanisme intégral capable de s’auto-maintenir et de s’auto-corriger. À ce stade, la méthode acquiert véritablement la capacité de générer en permanence de nouvelles solutions.
Toutes les « choses » correspondent alors aux nouvelles populations et aux nouvelles solutions candidates qui émergent continuellement au-dessus de cet ordre génératif. Elles ne sont pas produites aveuglément, mais surviennent en permanence sous des directions, des structures et des contraintes en boucle fermée déjà formées. C’est précisément pour cette raison que ce qu’EvoGO fait avancer n’est pas simplement la capacité de « trouver de meilleures solutions plus rapidement », mais une nouvelle capacité de l’optimisation évolutionnaire à générer des lois à partir de l’expérience, puis à générer en permanence des solutions à partir de ces lois.
La signification philosophique d’EvoGO ne réside pas dans le simple remplacement des opérateurs traditionnels. Elle réside plutôt dans le fait de montrer plus clairement que l’optimisation n’a pas besoin de progresser uniquement par des règles pré-écrites ; par l’accumulation, la différenciation et l’organisation de l’expérience, elle peut progressivement former son propre ordre génératif.
Conclusion et Perspectives
Ce sur quoi EvoGO se concentre n’est pas seulement une amélioration locale du pipeline d’optimisation évolutionnaire traditionnel, mais une reconstruction plus fondamentale de la façon dont l’optimisation elle-même se produit. En organisant l’optimisation dans les trois étapes unifiées de la préparation des données, de l’entraînement du modèle et de la génération de la population, et en introduisant la construction de données directionnelles basée sur l’appariement supérieur-inférieur, une architecture générative appariée guidée par un modèle de substitution, et un mécanisme de génération de population parallèle, EvoGO démontre des avantages stables tant en performances qu’en efficacité sur les tests de référence standard. Parallèlement, il a également validé son potentiel pour des problèmes d’ingénierie complexes réels par la conception d’optimisation d’ailes supercritiques pour avions de ligne gros-porteurs de nouvelle génération. À un niveau supérieur, l’importance de ce travail réside dans le fait de montrer que l’optimisation évolutionnaire ne doit pas nécessairement rester confinée à des règles heuristiques spécifiées manuellement. Le processus d’optimisation lui-même peut être progressivement distillé à partir de l’expérience historique en tant que loi apprenable.
Code Open-Source / Communauté
- Article :
https://arxiv.org/abs/2602.01147 - GitHub :
https://github.com/EMI-Group/evogo - Projet en Amont (EvoX) :
https://github.com/EMI-Group/evox - Groupe QQ :
297969717 - Compte Officiel WeChat : Intelligence Artificielle Évolutionnaire (Evolutionary Machine Intelligence)
EvoGO est construit sur le framework EvoX. Si vous êtes intéressé(e) par EvoX, vous êtes invité(e) à consulter les articles (https://mp.weixin.qq.com/s/uT6qSqiWiqevPRRTAVIusQ) sur le compte public EvoX pour plus de détails.