差分進化(Differential Evolution, DE)作為演化計算的核心演算法之一,因其簡單高效而被廣泛應用於黑盒最佳化問題。然而,其效能嚴重依賴於超參數和策略的選擇,這一直是研究人員面臨的難題。為了解決這一挑戰,EvoX 團隊最近在 IEEE Transactions on Evolutionary Computation (IEEE TEVC) 上發表了一項題為「MetaDE: Evolving Differential Evolution by Differential Evolution」(MetaDE:通過差分進化演化差分進化)的研究。作為一種利用 DE 來演化其自身超參數和策略的元演化方法,MetaDE 能夠動態調整參數和策略,同時結合了 GPU 加速的平行運算。這種設計在大幅提升運算效率的同時,也顯著改善了最佳化效能。實驗結果顯示,MetaDE 在 CEC2022 基準測試套件和機器人控制任務上均表現出色。MetaDE 的原始碼已在 GitHub 上開源:https://github.com/EMI-Group/metade。
背景
在演化計算領域,演算法的效能往往受到超參數選擇的顯著影響。確定特定問題的最合適參數設定一直是一個長期的研究挑戰。差分進化(DE)作為一種經典的演化演算法,因其簡單性和強大的全域搜尋能力而廣受青睞;然而,其效能對超參數的選擇高度敏感。傳統方法通常依賴基於經驗的調整或自適應機制來提升效能。然而,面對多樣化的問題場景,這些方法往往難以在效率和廣泛適用性之間取得平衡。
「元演化」(Meta-Evolution)的概念早在上個世紀就已提出,旨在利用演化演算法本身來最佳化這些演算法的超參數配置。雖然元演化已存在多年,但其實際應用一直受到高運算需求的限制。近年來 GPU 運算的進步緩解了這些限制,為演化演算法提供了強大的硬體支援。特別是分散式 GPU 加速 EvoX 框架的推出,極大地促進了基於 GPU 的演化演算法的發展。在此背景下,我們的研究團隊提出了一種新穎的元演化方法,利用 DE 來演化其自身的超參數和策略,從而為解決演化演算法中長期存在的參數調整問題提供了一條新途徑。
什麼是元演化?
元演化的核心思想可以概括為「利用演化演算法來演化其自身」(Evolving an Evolutionary Algorithm by an Evolutionary Algorithm)。這個概念超越了傳統的演化計算方法,不僅利用演化演算法來搜尋問題的最佳解,還通過其自身的演化過程來調整演算法的超參數和策略。
換句話說,元演化引入了一種「自我演化」範式,使演算法在探索問題解的搜尋空間時能夠自我最佳化。通過在演化過程中不斷自我完善,演算法變得更具適應性,並能在各種問題場景中保持高效率。
以 MetaDE 為例,其設計植根於這一理念。在雙層結構中,下層(「執行者」,executor)使用參數化的 DE 解決給定的最佳化問題。上層(「演化者」,evolver)同時使用 DE 來最佳化執行者的超參數配置。這個框架讓 DE 不僅作為求解器,還能「探索」如何最好地調整自身的參數和策略,以更有效地解決不同問題。這樣過程類似於一個系統逐步理解和完善自身——從**「被動解決問題」轉變為「主動自我演化」**。因此,它可以更好地適應多樣化的任務。如果我們將 DE 視為一個複雜系統,MetaDE 實際上在這個系統內實現了一種「遞迴」式的自我理解和自我改進。
電腦科學中的「遞迴」(recursion)一詞通常描述一個呼叫自身的函數或過程。在 MetaDE 中,這個概念有了新的含義:它是一種內部遞迴的最佳化機制,利用 DE 來演化 DE 的超參數。這種自我參照方案不僅體現了強大的適應性,也為「沒有免費午餐」定理提供了一個新穎的視角。因為對於所有問題來說,不存在單一、通用的最佳參數集,允許演算法自主演化是找到特定任務最佳參數配置的關鍵。
通過這種遞迴元演化方法,MetaDE 實現了多項優勢:
1. 自動化參數調整
消除了勞力密集的依賴人工調整過程。演算法自身學習如何調整其超參數,減少了人為干預並提高了效率。2. 增強的適應性
MetaDE 能動態回應不斷變化的問題特徵和條件,即時修改策略以提升效能。這顯著增加了演算法的靈活性。3. 高效搜尋 利用內在的平行性,MetaDE 大幅加速了大規模最佳化問題的搜尋。它能在合理的時間範圍內為高維度、複雜問題提供可行的解決方案。
演算法實作
MetaDE 採用基於張量的技術和 GPU 加速來實現高效的平行運算。通過同時處理族群中的許多個體,整體運算效率顯著提高,使其在單目標黑盒最佳化和大規模最佳化問題中特別具優勢。通過對關鍵參數和資料結構(例如族群、適應度、策略參數)進行張量化,MetaDE 不僅實現了更高的運算效率,還增強了解決複雜最佳化挑戰的能力。與經典 DE 和其他演化演算法(EAs)相比,MetaDE 在解決大規模問題時表現出卓越的效能。歸功於基於張量的方法,MetaDE 能更有效地利用運算資源,產生比傳統方法更快的解決方案和更精確的最佳化結果。

PDE 架構
研究團隊首先提出了一個參數化的 DE 演算法框架(PDE),完全支援參數和策略的修改。在這個框架中,F 和 CR 是連續參數,而其他參數是離散的。虛線框表示允許的參數值範圍。突變函數源自左側和右側的基向量,以及控制差分向量數量的參數。

MetaDE 架構
MetaDE 採用雙層結構,包含一個演化者(上層)和多個執行者(下層)。演化者是一個 DE(或可能是其他演化演算法),負責最佳化 PDE 的參數。演化者族群中的每個個體 ![]() x_i 對應一個唯一的參數配置 θ_i。這些配置被傳遞給 PDE 以實例化不同的 DE 變體,每個變體由一個執行者管理,並在給定的最佳化任務上獨立運行。每個執行者將其最佳適應度值 y^* 返回給演化者,演化者將該適應度值 y_i 分配給相應的個體 x_i。
x_i 對應一個唯一的參數配置 θ_i。這些配置被傳遞給 PDE 以實例化不同的 DE 變體,每個變體由一個執行者管理,並在給定的最佳化任務上獨立運行。每個執行者將其最佳適應度值 y^* 返回給演化者,演化者將該適應度值 y_i 分配給相應的個體 x_i。
實驗效能
為了全面評估 MetaDE 的有效性,研究團隊進行了涵蓋多個基準測試和現實世界場景的系統性實驗。每個實驗使用一個演化者(採用 rand/1/bin 策略的 DE)和執行者(族群大小為 100 的 PDE)。關鍵實驗部分包括:
CEC2022 基準測試
在單目標最佳化任務中將 MetaDE 與各種 DE 變體進行比較。
與 CEC2022 前四名演算法的比較
在相同的函數評估次數(FEs)預算下,評估 MetaDE 與 CEC2022 競賽中表現最好的四種演算法的效能。
固定實際執行時間下的函數評估次數(FEs)
分析 MetaDE 在 GPU 加速下的運算效率。
機器人控制任務
將 MetaDE 應用於 Brax 平台環境中的機器人控制任務,以驗證其實際效用。
CEC2022 基準測試:與主流 DE 變體的比較
團隊在 CEC2022 基準測試套件上將 MetaDE 與幾種具代表性的 DE 變體進行了比較,包括:
- 標準 DE (rand/1/bin)
- SaDE 和 JaDE (自適應 DE 演算法)
- CoDE (策略整合 DE)
- SHADE 和 LSHADE-RSP (基於成功歷史的自適應 DE)
- EDEV (整合 DE 變體)
所有演算法均在 EvoX 平台上實作,利用 GPU 加速,族群大小為 100 以確保公平性。實驗在不同維度(10D 和 20D)下進行,並受到相同的運算時間限制(60 秒)。

10D CEC2022 最佳化結果

20D CEC2022 最佳化結果
MetaDE 在大多數測試函數上通常能實現更快速且穩定的收斂。其參數化 DE(PDE)結合上層最佳化,使其能夠動態適應不同的問題空間,從而提高整體的穩健性和搜尋效能。
與 CEC2022 前四名演算法的比較(在相同 FEs 下)
為了進一步評估 MetaDE 的最佳化能力,我們在相同的函數評估預算內,將其與 CEC2022 競賽的前四名演算法進行了比較:
- EA4eig:一種整合多種 EA 的混合方法
- NL-SHADE-LBC:一種改進的自適應 DE
- NL-SHADE-RSP-MID:一種帶有中點估計的增強型 SHADE
- S-LSHADE-DP:一種通過動態擾動維持族群多樣性的 DE 變體
這些演算法均使用其官方參數設定和原始碼在相同的 FE 限制下運行。我們在 CEC2022 測試套件上對 MetaDE 和每個基準演算法進行了統計比較(Wilcoxon 秩和檢定,顯著水準 0.05)。
表格的最後一行顯示了每種演算法在不同測試函數上與 MetaDE 相比的表現:+(顯著較好),≈(無顯著差異),和 −(顯著較差)。

10D CEC2022 競賽演算法比較(相同 FEs)

20D CEC2022 競賽演算法比較(相同 FEs)
MetaDE 持續展現出強大的效能,特別是在需要穩健收斂的複雜問題上。歸功於其自適應機制,MetaDE 能針對不同的搜尋地貌有效地調整其策略,從而提高搜尋效率和全域最佳化能力。這些結果表明,MetaDE 不僅優於主流 DE 變體,而且與頂級競賽演算法相比也表現出強大的競爭力。
運算效率:固定時間(60 秒)內的 FEs
研究團隊進一步記錄了不同演算法在相同固定執行時間(60 秒)內完成的函數評估次數(FEs)。
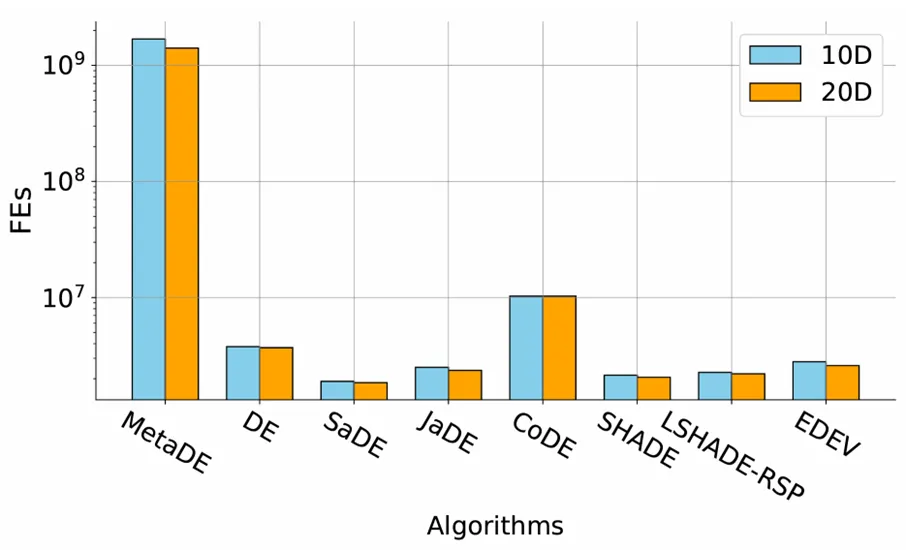
各演算法在 60 秒內達到的 FEs在相同的 EvoX 框架下,利用 GPU 加速平行運算,MetaDE 平均達到了 10****⁹ 等級的 FEs,而傳統 DE 變體僅達到約 10^6 FEs。這一優勢源於 MetaDE 的參數化方法,該方法對個體進行大規模平行評估,實現了更高效的硬體資源利用。因此,該演算法能在相同的時間視窗內探索更多解,同時提高了解的品質和穩定性。
演化強化學習:機器人控制任務
在強化學習(RL)中,策略最佳化的效率和穩定性至關重要。基於梯度的方法(如 PPO 和 SAC)在高維環境中可能會遇到梯度消失或爆炸的問題。相比之下,演化強化學習(EvoRL)通過使用無梯度搜尋直接最佳化策略參數,從而規避了這些問題。

演化強化學習流程
在 EvoRL 框架內,MetaDE:
- 自動最佳化神經網路參數,增加策略模型的適應性。
- 動態調整超參數,提高訓練穩定性。
- 利用 GPU 加速來加速策略最佳化。
為了評估 MetaDE 在複雜最佳化任務上的效能,我們將其應用於機器人控制問題,在 Brax 模擬平台中使用 GPU 加速最佳化。研究包括三個任務——Swimmer、Hopper 和 Reacher——每個任務都由一個三層全連接神經網路(MLP)建模,目標是最大化獎勵。值得注意的是,每個 MLP 包含約 1,500 個參數,這對演化演算法(EAs)構成了 1,500 維的最佳化挑戰。這對搜尋能力和運算效率都提出了嚴格的要求。

三個 Brax 環境的收斂曲線
如圖所示,MetaDE 在基於 Brax 的機器人控制任務中表現出強大的效能,在 Swimmer 任務上取得了最佳結果,在 Hopper 和 Reacher 上也取得了接近最佳的結果。其主要優勢在於初始族群的高品質,能夠實現快速的早期收斂並產生高品質的解。這些發現表明 MetaDE 可以高效地最佳化神經網路策略,使其非常適合具有複雜物理模擬的機器人控制任務,並具有廣泛的實際應用潛力。
結論與未來方向
MetaDE 是一種創新的元演化方法,不僅在解決最佳化任務方面表現出色,還能自主調整和完善其自身的策略。利用差分進化的優勢,MetaDE 在自適應參數配置和策略演化方面展現出強大的潛力。實驗結果顯示其在多種基準測試中具有卓越的穩健性,其在現實世界中的適用性也通過演化強化學習在機器人控制任務中的成功得到了強調。一個核心挑戰在於保持泛化與專用化之間的最佳平衡——確保演算法既能適應多樣化的任務,又能針對特定問題進行有效最佳化。這項研究為自適應演化演算法提供了新的視角,並可能激發複雜系統元演化的進一步發展。
開源程式碼與社群
論文: https://arxiv.org/abs/2502.10470
GitHub: https://github.com/EMI-Group/metade
上游專案 (EvoX): https://github.com/EMI-Group/evox
QQ 群: 297969717

QQ 群 | 演化機器智能
MetaDE 建立在 EvoX 框架之上。如果您對 EvoX 感興趣,請查看關於 EvoX 1.0 的文章以獲取更多詳情。

(https://mp.weixin.qq.com/s/uT6qSqiWiqevPRRTAVIusQ)