透過張量化技術連結演化多目標最佳化與 GPU 加速
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun, and Ran Cheng, IEEE 資深會員
隨著工程設計和能源管理等領域對複雜最佳化解決方案的需求不斷增長,演化多目標最佳化(Evolutionary Multiobjective Optimization, EMO)演算法因其解決多目標問題的強大能力而受到廣泛關注。然而,隨著最佳化任務規模和複雜度的增加,傳統基於 CPU 的 EMO 演算法遇到了顯著的效能瓶頸。
為了解決這一限制,EvoX 團隊提出透過張量化(tensorization)方法在 GPU 上平行化 EMO 演算法。利用這種方法,他們成功設計並實作了多種 GPU 加速的 EMO 演算法。此外,團隊還開發了 「MoRobtrol」,這是一個基於 Brax 物理引擎構建的 多目標機器人控制基準測試套件,旨在系統性地評估 GPU 加速 EMO 演算法的效能。
基於這些研究進展,EvoX 團隊發布了 EvoMO,這是一個高效能 GPU 加速 EMO 演算法函式庫。相應的原始碼已在 GitHub 上公開:https://github.com/EMl-Group/evomo
張量化方法論
在計算最佳化領域,張量(tensor) 指的是一種能夠表示純量、向量、矩陣和高階資料的多維陣列資料結構。張量化(Tensorization) 是將演算法中的資料結構和運算轉換為張量形式的過程,使演算法能夠充分利用 GPU 的平行計算能力。
在 EMO 演算法中,所有關鍵資料結構都可以用張量化格式表示。族群中的個體可以用解張量 X 表示,其中每個列向量對應一個個體。目標函數值形成目標張量 F。此外,輔助資料結構如參考向量和權重向量可以分別表示為張量 R 和 W。這種統一的張量表示法實現了表示層級的族群級運算,為大規模平行計算奠定了堅實基礎。
EMO 演算法運算的張量化對於提升計算效率至關重要,可分為兩層:基本張量運算和控制流張量化。基本張量運算構成了 EMO 演算法張量化實作的核心,詳見表 I。
表 I:基本張量運算

控制流張量化用可平行化的張量運算取代了傳統的迴圈和條件邏輯。例如,for/while 迴圈可以利用廣播(broadcasting)機制或高階函數(如 vmap)轉換為批次運算。同樣地,if-else 條件判斷可以被遮罩(masking)技術取代,其中邏輯條件被編碼為布林張量,從而實現不同計算路徑之間的靈活切換。
與傳統 EMO 演算法實作相比,張量化方法具有顯著優勢。首先,它提供了更大的靈活性,能自然地處理多維資料,而傳統方法通常受限於二維矩陣運算。其次,張量化透過平行執行顯著提高了計算效率,避免了顯式迴圈和條件分支相關的開銷。最後,它簡化了程式碼結構,使程式更簡潔且易於維護。
如圖 1 所示,以 Pareto 支配檢查為例,傳統實作依賴巢狀迴圈來執行逐元素比較。相比之下,張量化版本透過廣播和遮罩運算實現相同的功能,從而實現平行評估。這不僅降低了程式碼複雜度,還大幅提升了執行效能。

圖 1:Pareto 支配檢測的傳統實作與基於張量實作之比較。
從更深層次來看,張量化非常適合 GPU 加速,因為 GPU 擁有大量的平行核心,其單指令多執行緒(SIMT)架構與張量計算自然契合,特別是在矩陣運算方面表現出色。專用硬體如 NVIDIA 的 Tensor Cores 進一步提升了張量運算的吞吐量。一般而言,具有高平行度、包含獨立計算任務且條件分支極少的演算法更適合張量化。對於像 MOEA/D 這樣涉及順序依賴性的演算法,其固有結構對直接張量化構成了挑戰。然而,透過結構重構和關鍵計算的解耦,仍然可以實現有效的平行加速。
演算法張量化應用範例
基於張量化表示方法,EvoX 團隊設計並實作了三種經典 EMO 演算法的張量化版本:基於支配的 NSGA-III、基於分解的 MOEA/D 和基於指標的 HypE。下節將以 MOEA/D 為例進行詳細說明。NSGA-III 和 HypE 的張量化實作可在參考論文中找到。
如圖 2 所示,傳統 MOEA/D 將多目標問題分解為多個子問題,每個子問題獨立進行最佳化。該演算法包含四個核心步驟:交配與突變、適應度評估、理想點更新和鄰域更新。這些步驟在單個迴圈內針對每個個體順序執行。這種順序處理在處理大族群時會導致巨大的計算開銷,因為每個個體必須按順序完成所有步驟,限制了 GPU 加速的潛在效益。特別是鄰域更新依賴於個體之間的互動,這進一步增加了平行化的難度。

圖 2:MOEA/D 的虛擬碼
為了解決傳統 MOEA/D 中的順序依賴問題,團隊在環境選擇的內部迴圈中引入了張量化表示方法。透過將交配與突變、適應度評估、理想點更新和鄰域更新解耦,這些組件被視為獨立的運算。這使得所有個體能夠被平行處理,從而構建了張量化的 MOEA/D 演算法,稱為 TensorMOEA/D。在此演算法中,環境選擇分為兩個主要階段:比較與族群更新,以及菁英解選擇。這兩個階段主要透過兩次應用 vmap 運算來實現張量化。詳細過程如圖 3 所示。
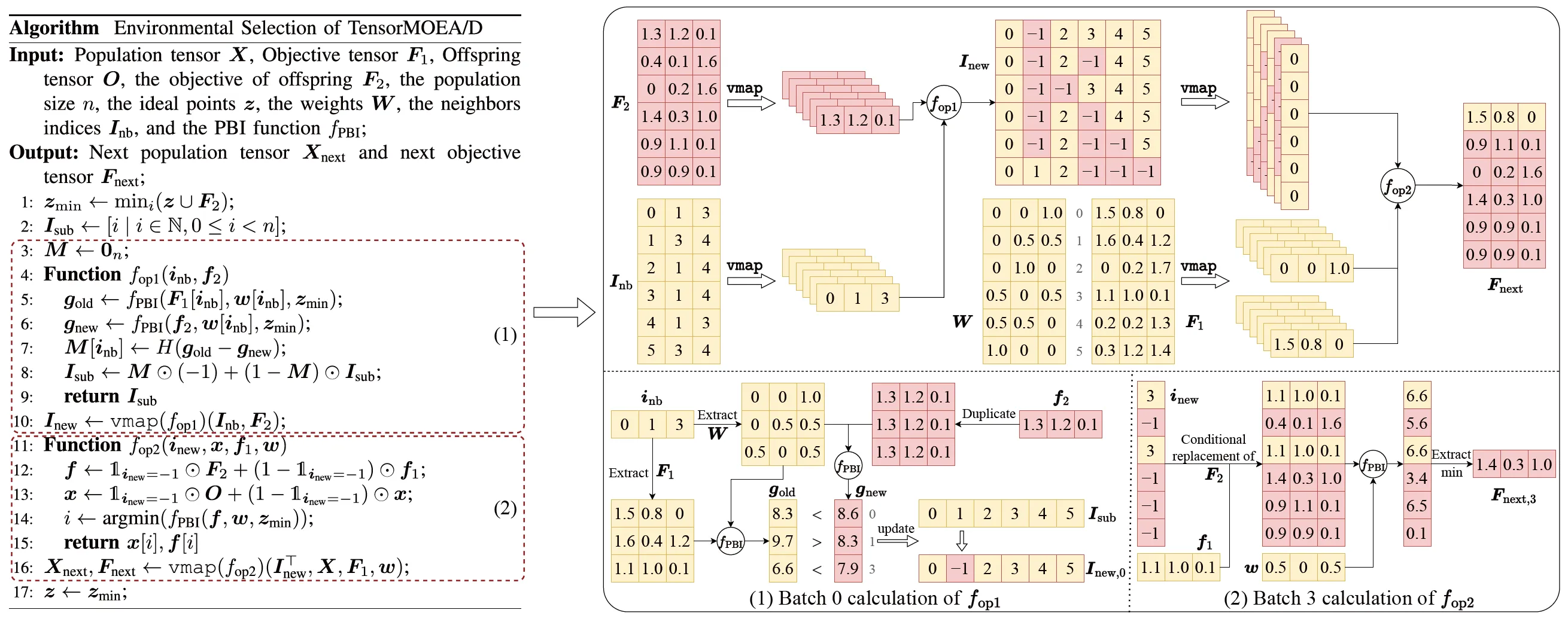

圖 3:TensorMOEA/D 演算法中環境選擇的概述。左:演算法虛擬碼。右:模組 (1) 和模組 (2) 的張量資料流。右圖上半部分顯示模組 (1) 和 (2) 的整體張量資料流,下半部分顯示批次計算張量資料流,模組 (1) 在左,模組 (2) 在右。
為了更全面地理解張量化在 EMO 演算法中的價值,可以從三個角度進行總結。首先,張量化實現了從數學公式到高效程式碼的直接轉換,縮小了演算法設計與實作之間的差距。例如,圖 4 展示了張量化的非支配排序過程如何從虛擬碼直接轉換為 Python 程式碼。其次,張量化透過將族群級運算統一為單一張量表示,顯著簡化了程式碼結構。這減少了對迴圈和條件語句的依賴,從而提高了程式碼的可讀性和可維護性。第三,張量化增強了演算法的可重現性。其結構化表示便於進行比較測試和結果的一致性重現。

圖 4:張量化非支配排序從虛擬碼(左)到 Python 程式碼(右)的無縫轉換。
效能展示
為了評估 GPU 加速多目標最佳化演算法的效能,EvoX 團隊系統性地進行了三類實驗,重點關注計算加速、數值最佳化效能以及在多目標機器人控制任務中的有效性。
計算加速效能:
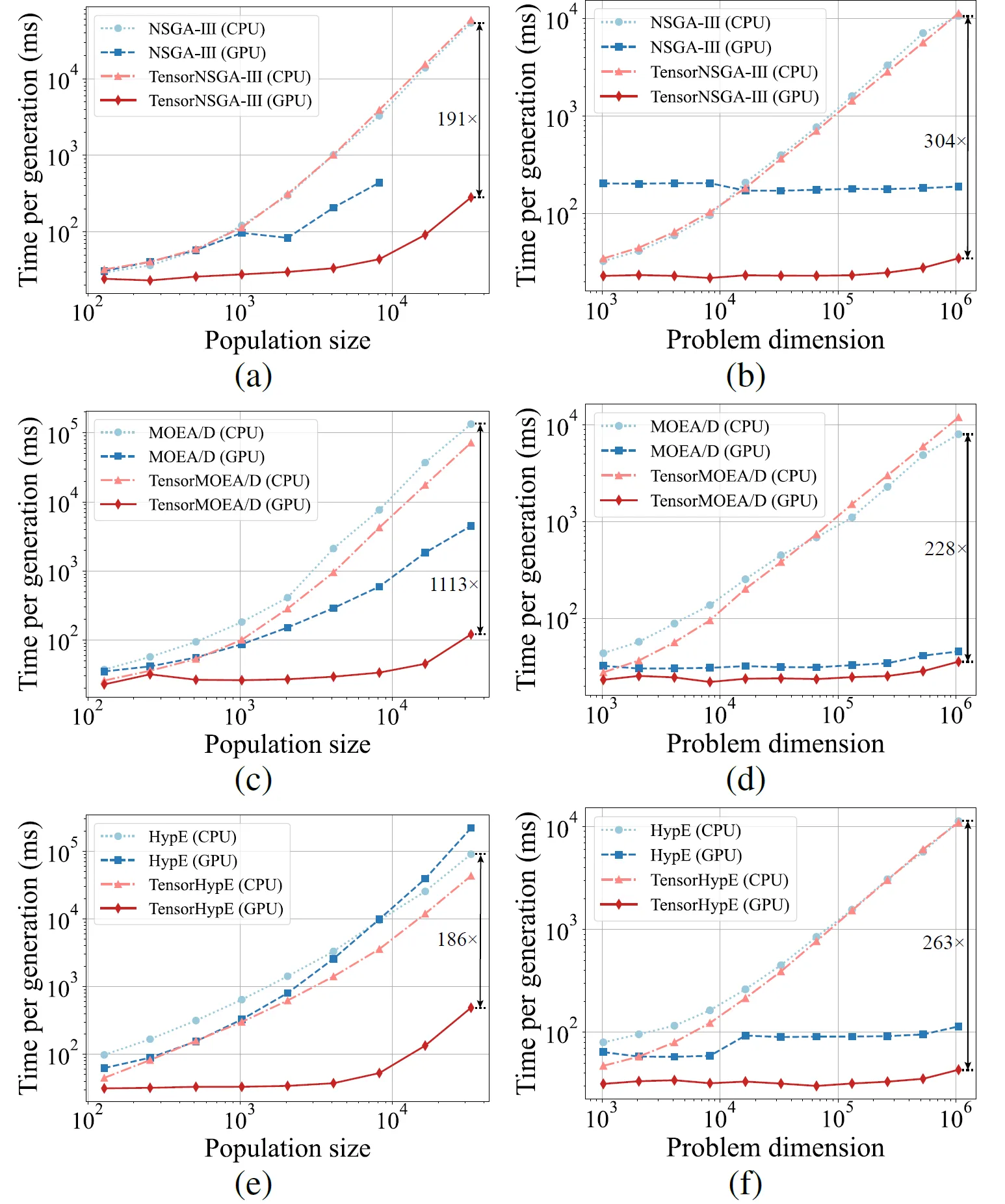
圖 5:NSGA-III、MOEA/D 和 HypE 及其張量化版本在 CPU 和 GPU 平台上,針對不同族群大小和問題維度的加速效能比較。
實驗結果顯示,與非張量化的 CPU 版本相比,TensorNSGA-III、TensorMOEA/D 和 TensorHypE 在 GPU 上實現了顯著更高的執行速度。隨著族群大小和問題維度的增加,觀察到的最大加速比高達 1113 倍。張量化演算法在處理大規模計算任務時展現了極佳的可擴展性和穩定性——其執行時間僅略微增加,同時保持了一致的高效能。這些發現凸顯了張量化在多目標最佳化 GPU 加速方面的巨大優勢。
LSMOP 測試套件表現:
表 II:非張量化與張量化 EMO 演算法在 LSMOP1–LSMOP9 中的 IGD 和執行時間(秒)統計結果(平均值與標準差)。所有實驗均在 RTX 4090 GPU 上進行,最佳結果已標示。
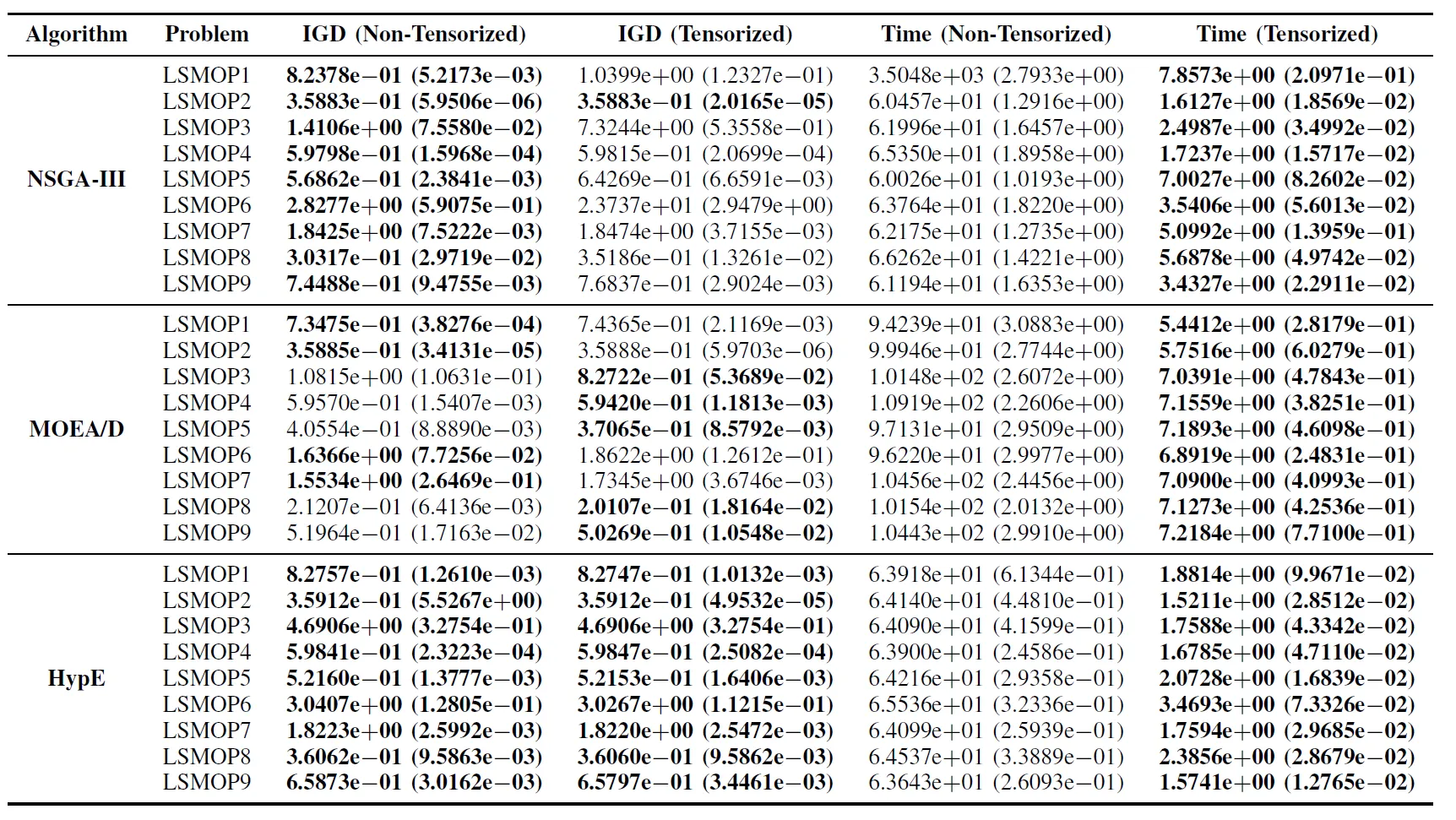
實驗結果表明,基於張量化表示的 GPU 加速 EMO 演算法顯著提高了計算效率,同時保持甚至在某些情況下超越了原始版本的最佳化精度。
多目標機器人控制任務:
為了全面評估 GPU 加速 EMO 演算法的實際效能,團隊開發了一個名為 MoRobtrol 的多目標機器人控制基準測試套件。該套件包含的任務列於表 III。
表 III:所提出的 MoRobtrol 基準測試套件中多目標機器人控制問題概述
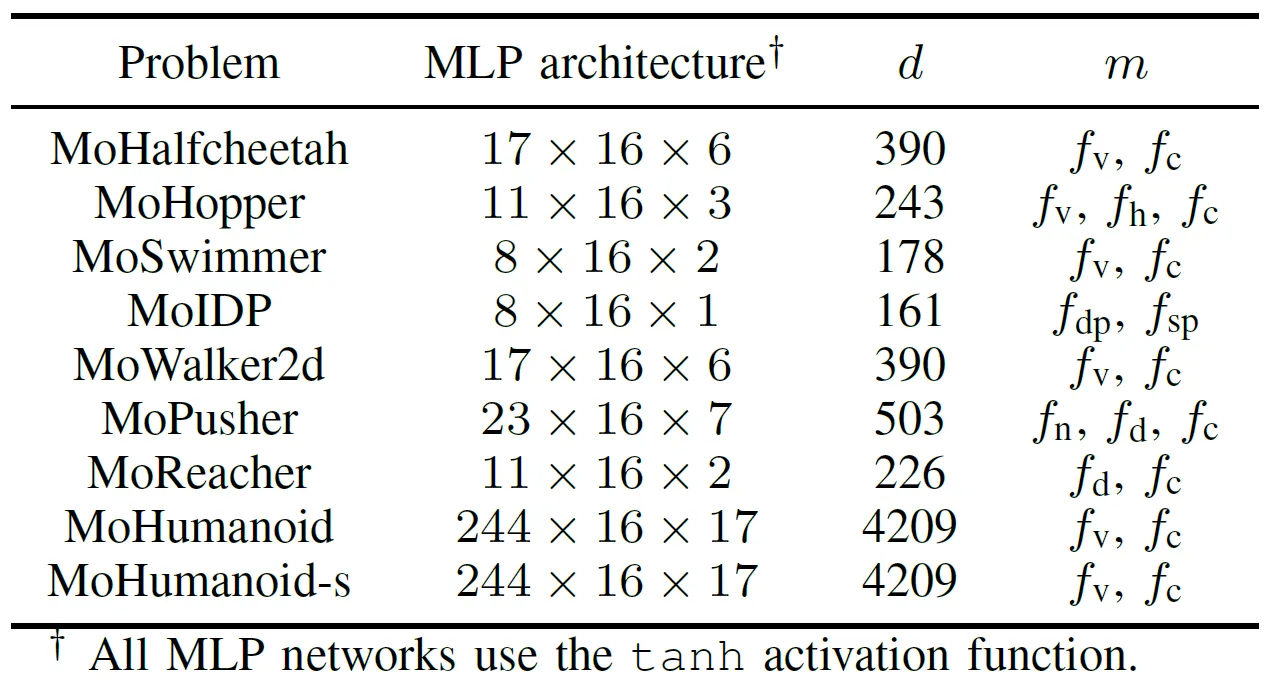
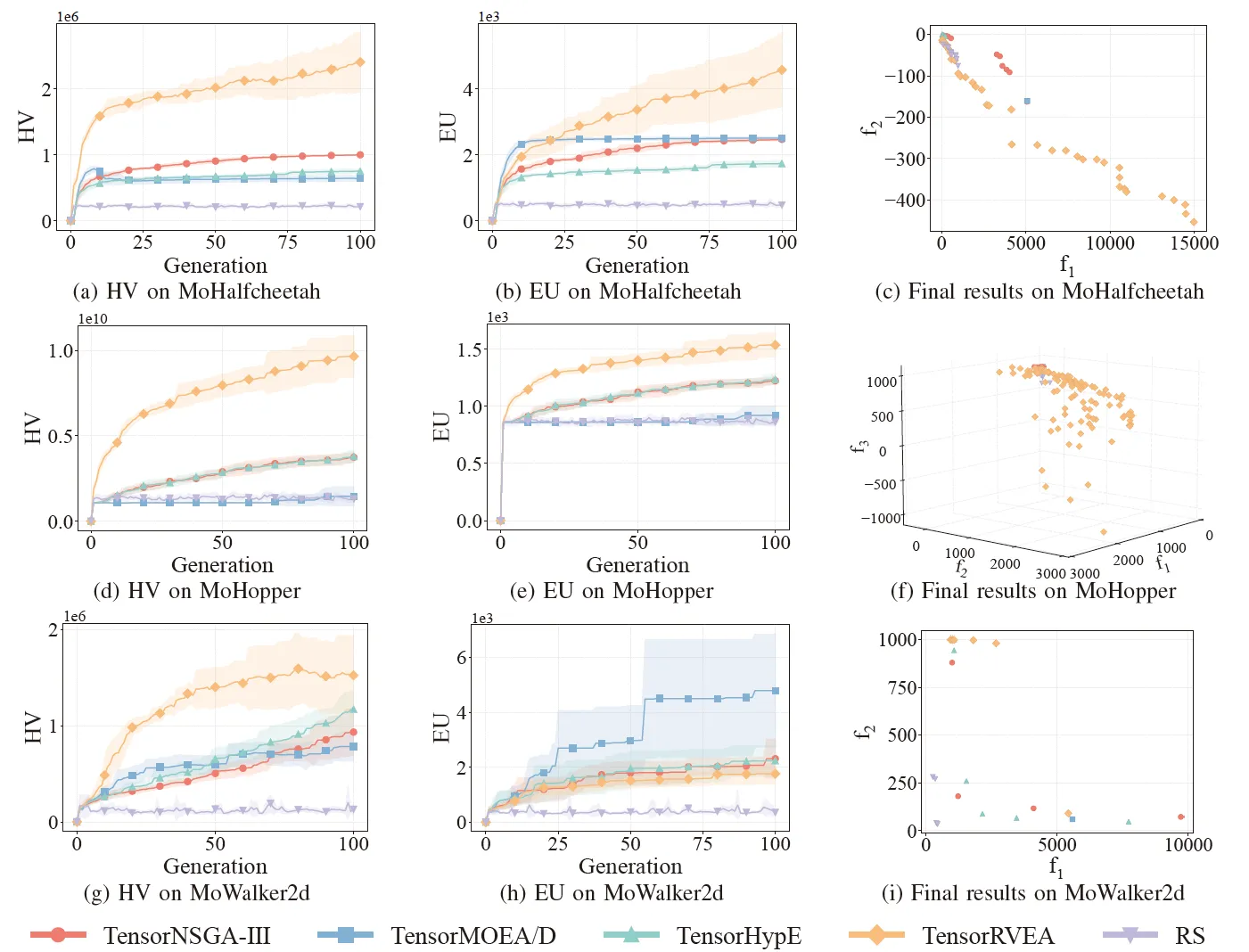
圖 6:TensorNSGA-III、TensorMOEA/D、TensorHypE、TensorRVEA 和隨機搜尋 (RS) 在不同問題上的效能比較(HV、EU 和最終結果視覺化):MoHalfcheetah (390D)、MoHopper (243D) 和 MoWalker2d (390D)。註:所有指標數值越高表示效能越好。
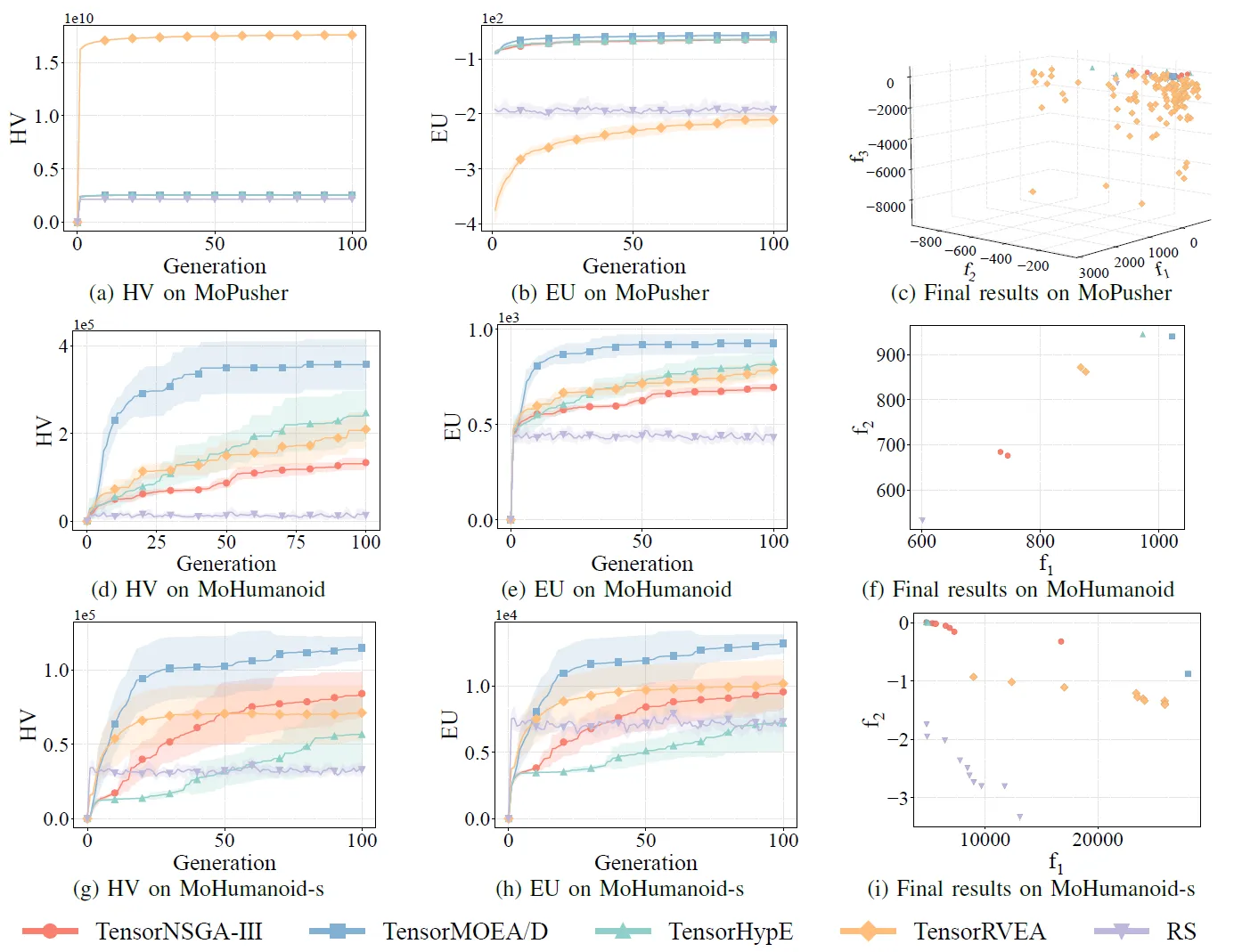
圖 7:TensorNSGA-III、TensorMOEA/D、TensorHypE、TensorRVEA 和隨機搜尋 (RS) 在不同問題上的效能比較(HV、EU 和最終結果視覺化):MoPusher (503D)、MoHumanoid (4209D) 和 MoHumanoid-s (4209D)。註:所有指標數值越高表示效能越好。
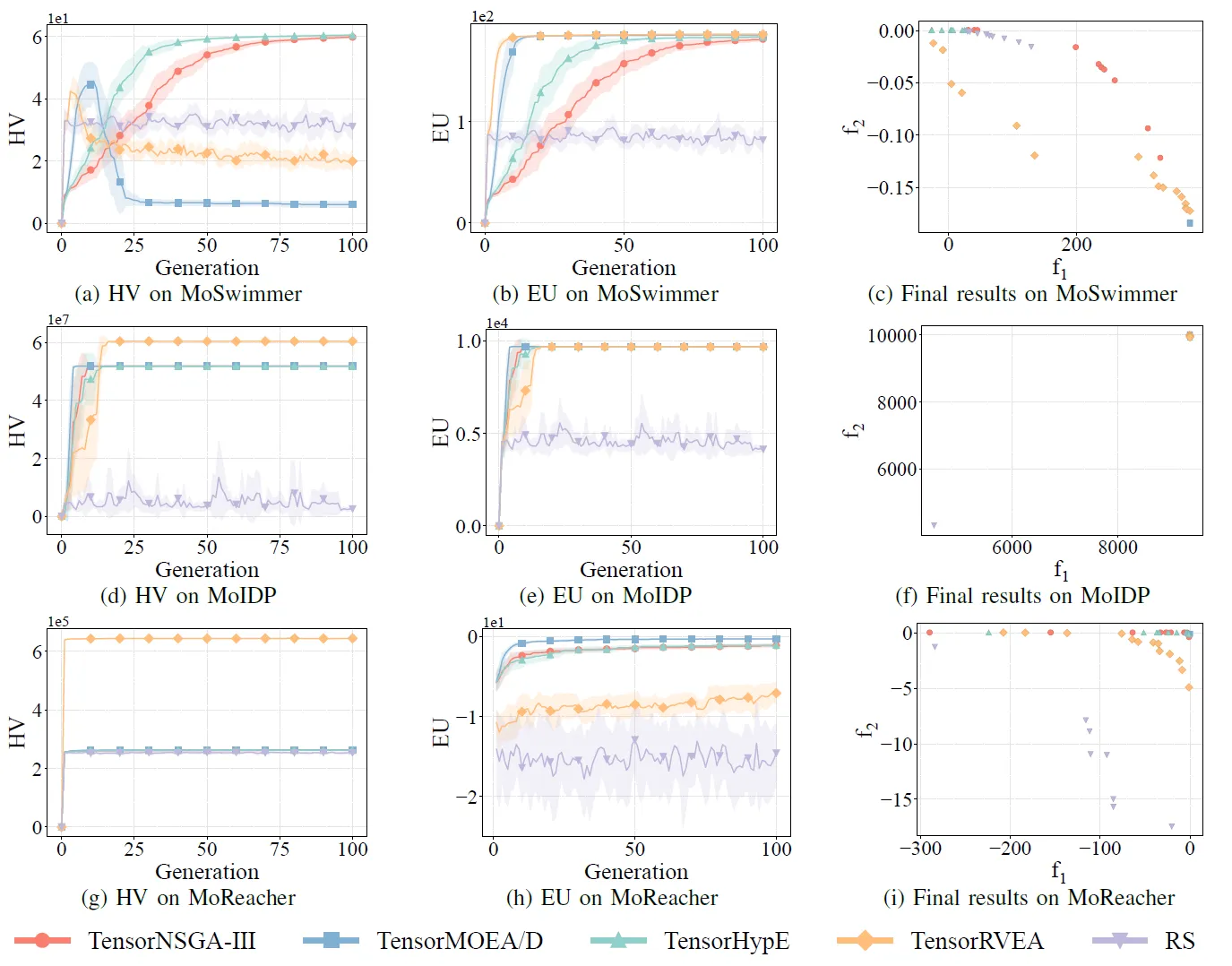
圖 8:TensorNSGA-III、TensorMOEA/D、TensorHypE、TensorRVEA 和隨機搜尋 (RS) 在不同問題上的效能比較(HV、EU 和最終結果視覺化):MoSwimmer (178D)、MoIDP (161D) 和 MoReacher (226D)。註:所有指標數值越高表示效能越好。
實驗比較了 TensorNSGA-III、TensorMOEA/D、TensorHypE、TensorRVEA 和隨機搜尋 (RS) 在 MoRobtrol 基準測試中的表現。結果顯示,TensorRVEA 取得了最佳的整體效能,獲得了最高的 HV 值,並在多個環境中展現了良好的解多樣性。TensorMOEA/D 在大規模任務中表現出強大的適應性,特別是在解的偏好一致性方面表現出色。TensorNSGA-III 和 TensorHypE 表現相似,在多個任務上具有競爭力。總體而言,基於分解的張量化演算法在解決大規模和複雜問題方面展現了卓越的優勢。
結論與未來工作
本研究提出了一種張量化表示方法,以解決傳統基於 CPU 的 EMO 演算法在計算效率和可擴展性方面的限制。該方法已應用於多種代表性演算法,包括 NSGA-III、MOEA/D 和 HypE,在 GPU 上實現了顯著的效能提升,同時保持了解的品質。為了驗證其實際應用性,團隊還開發了 MoRobtrol,這是一個多目標機器人控制基準測試套件,將物理模擬環境中的機器人控制任務重新表述為多目標最佳化問題。結果證明了張量化演算法在具身智慧(embodied intelligence)等計算密集型場景中的潛力。儘管張量化方法已大幅提升了演算法效率,但仍有進一步增強的空間。未來的方向包括改進核心運算子(如非支配排序)、設計適用於多 GPU 系統的新型張量化運算,以及整合大規模資料和深度學習技術,以進一步提升在大規模最佳化問題上的效能。
開源程式碼 / 社群資源
論文:
https://arxiv.org/abs/2503.20286
GitHub:
https://github.com/EMI-Group/evomo
上游專案 (EvoX):
https://github.com/EMI-Group/evox
QQ 群:297969717

EvoMO 建立在 EvoX 框架之上。如果您有興趣深入了解 EvoX,歡迎查看我們微信公眾號上發布的關於 EvoX 1.0 的官方文章以獲取更多詳情。
