
遺傳程式設計是一種兼具結構搜尋能力與可解釋性的演化方法,在符號迴歸、分類與控制等任務中具有獨特優勢——它不僅能最佳化參數,還能直接搜尋並產出可分析的程式表達式。然而,由於個體結構的異質性以及執行路徑的不規則性,**大多數既有的遺傳程式設計實作仍侷限於以 CPU 為主的執行,長期難以真正適配 GPU。**這直接限制了運算效率的提升,使其難以因應現代應用中處理海量資料或複雜模擬環境的需求。
為因應這項挑戰,**我們提出了 EvoGP 框架,從底層重新組織樹狀表示、遺傳算子邏輯與並行執行機制。**實驗結果顯示,**EvoGP 的峰值運算吞吐量突破 10^11 GPops/s,能夠在 1 秒內完成 50 萬規模族群的快速評測,相較既有 GPU 實作最高可達 304 倍加速。**這項里程碑標誌著遺傳程式設計徹底打破硬體適配障礙,真正進入 GPU 加速的高效能運算時代。
遺傳程式設計的 GPU 適配難題
近年來,GPU 憑藉其海量並行性與高吞吐量,已成為高效能智慧運算的關鍵基礎設施。然而,遺傳程式設計始終未能充分利用這項硬體優勢。核心障礙在於缺乏與現代硬體架構相符的表示與執行方式。GPU 的單一指令多執行緒(SIMT)執行模型最擅長處理規則、統一、可批次化的資料;而遺傳程式設計個體則呈現顯著的結構異質性——樹的大小、拓撲結構以及評估邏輯各不相同。一旦將這些結構放到 GPU 上,立刻暴露出不連續的記憶體存取、動態記憶體配置效率低落,以及嚴重的執行緒分歧等問題。
同時,要真正釋放 GPU 算力,系統需要同時處理單一個體內部的資料級並行與族群層面的個體級並行。在單一排程策略下統一這兩種模式、最佳化記憶體配置並防止資源爭用,是一項極具挑戰性的系統工程。許多過往實作由於底層設計缺陷,往往只利用了資料級並行,導致 GPU 的大量並行能力處於閒置狀態。EvoGP 要解決的正是這項根本問題:不是讓遺傳程式設計勉強能在 GPU 上執行,而是提供一套專門客製的底層架構,使遺傳程式設計成為真正為 GPU 時代準備好的運算框架。
樹狀結構的張量化表示
要讓遺傳程式設計進入 GPU 時代,首要任務是消除個體結構的異質性障礙。傳統以指標或鏈結為基礎的樹狀結構會產生極不規則的記憶體配置,完全阻礙 GPU 的批次執行。為此,EvoGP 引入了一種創新的張量化表示方法,採用線性前置編碼方案,將樹狀結構編碼為包含節點類型、節點數值與子樹大小的連續陣列。
為處理大小不一的樹,**EvoGP 引入最大允許長度限制,並使用 NaN 值進行填充對齊。**透過這項轉換,EvoGP 成功將族群中形態各異的個體統一轉化為形狀固定、記憶體對齊的張量矩陣。這種張量化處理徹底消除了動態記憶體配置的開銷與不規則索引,確保 GPU 能夠進行統一的記憶體存取與高吞吐量的並行運算——構成整個框架進入 GPU 時代的基礎。
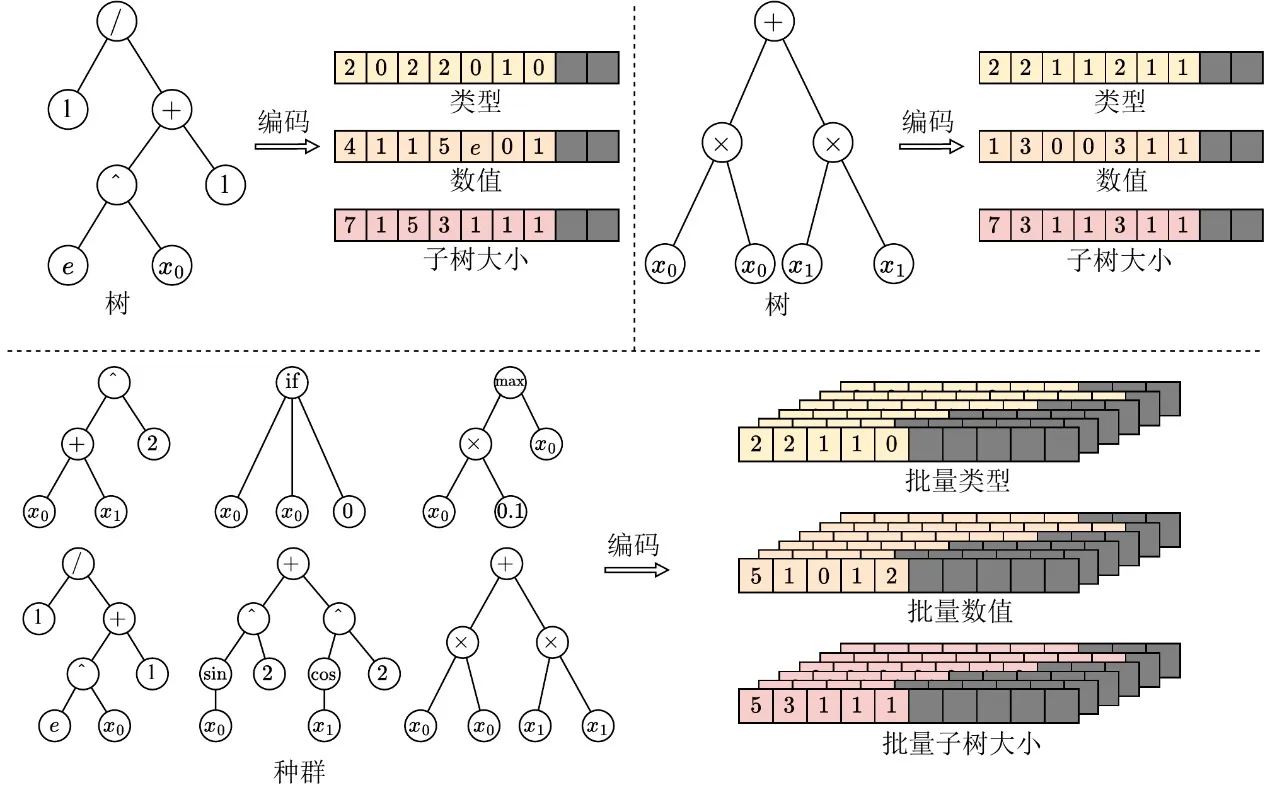
圖 1:樹狀結構的張量化表示。EvoGP 將樹編碼為統一的批次表示,使 GPU 能夠高效處理結構各異的程式個體。
遺傳算子的統一重構
在完成樹狀結構的張量化表示之後,EvoGP 進一步在底層對遺傳算子進行重構,使其與 GPU 架構對齊。在傳統樹狀表示中,交叉或突變等結構修改通常需要反覆解析序列以確定子樹邊界,帶來 O(n) 的時間複雜度,使 GPU 執行效率極低。得益於張量化編碼中明確保留的子樹大小陣列,系統現在可以在 O(1) 時間內直接存取子樹邊界,徹底消除了代價高昂的結構解析。
在此基礎上,**EvoGP 萃取了各類以樹為基礎的遺傳算子(如單點交叉與子樹突變)的結構共性,並將其統一為單一核心運算原語:子樹交換。**這將複雜的結構演化轉化為高度規則的記憶體切片與張量串接操作。這項重構顯著降低了並行執行過程中的控制流開銷,使遺傳程式設計的核心演化過程成為更適合現代高吞吐硬體的運算形式。
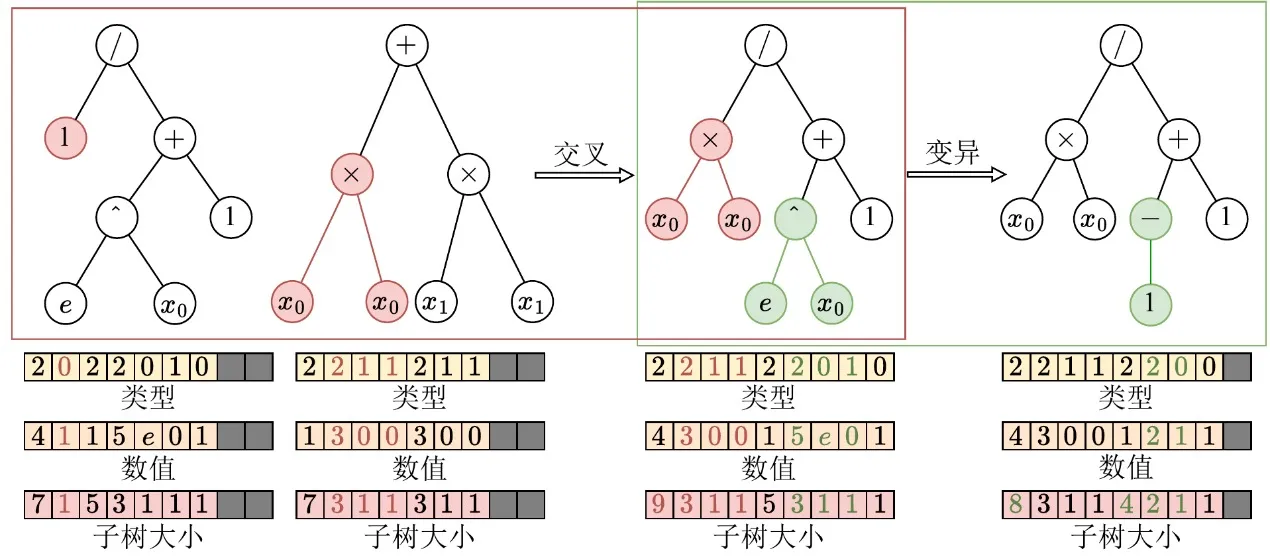
圖 2:統一的交叉/突變操作。EvoGP 將多種以樹為基礎的遺傳算子統一在單一底層機制之下,使核心演化過程更適合 GPU 並行執行。
並行策略的自適應切換
要在 GPU 時代蓬勃發展,演算法必須能夠充分挖掘硬體算力。不同任務的資料規模差異巨大,單一並行策略無法維持穩定的裝置利用率。為此,EvoGP 設計並實作了自適應並行策略,根據資料集規模動態組合個體內部與個體之間的並行。
在處理中小規模資料集時,系統採用混合並行模式,在單一運算核心中結合資料級與族群級並行——當個體工作負載不足時,族群級並行填補閒置的 GPU 核心。對於大規模資料集,單次評估任務即可飽和硬體,系統自動切換為純資料並行模式,為每個個體的評估啟動獨立運算核心,並將樹狀結構載入唯讀常數記憶體——最大化記憶體廣播效率,顯著提升存取吞吐量。這項自適應機制確保系統在各種工作負載下都能維持極高的運算效率,是 GPU 加速框架的核心保障。
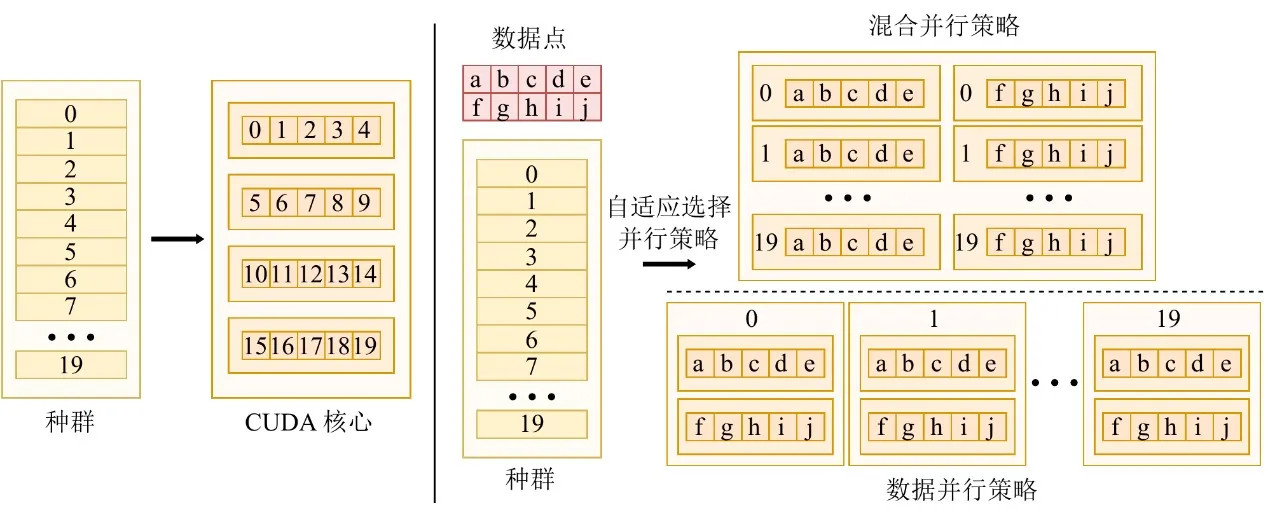
圖 3:自適應並行機制。EvoGP 根據任務規模自動切換不同並行模式,以維持更高的運算效率。
高效能與易用性的統一
高效能運算框架的生命力不僅在於底層速度,還在於生態相容性與易用性。許多實際應用部署在 OpenAI Gym、MuJoCo、Brax、Genesis 等以 Python 為基礎的生態中。在追求極致 GPU 加速的同時,EvoGP 透過在 PyTorch 執行階段中嵌入自訂高效能 CUDA 運算核心作為自訂算子,實現了與既有開發生態的無縫整合。
此外,為充分發揮 GPU 架構優勢,**EvoGP 採用完全駐留 GPU 的模型,確保族群資料與評估上下文全程保留在 GPU 上——徹底消除傳統框架中常見的高代價主機-裝置資料傳輸開銷。**這項零拷貝設計理念使 EvoGP 能夠自然、高效地與現代 GPU 加速強化學習環境整合,在極致效能與高可擴展性之間取得平衡,提供端對端的高效並行模擬能力。
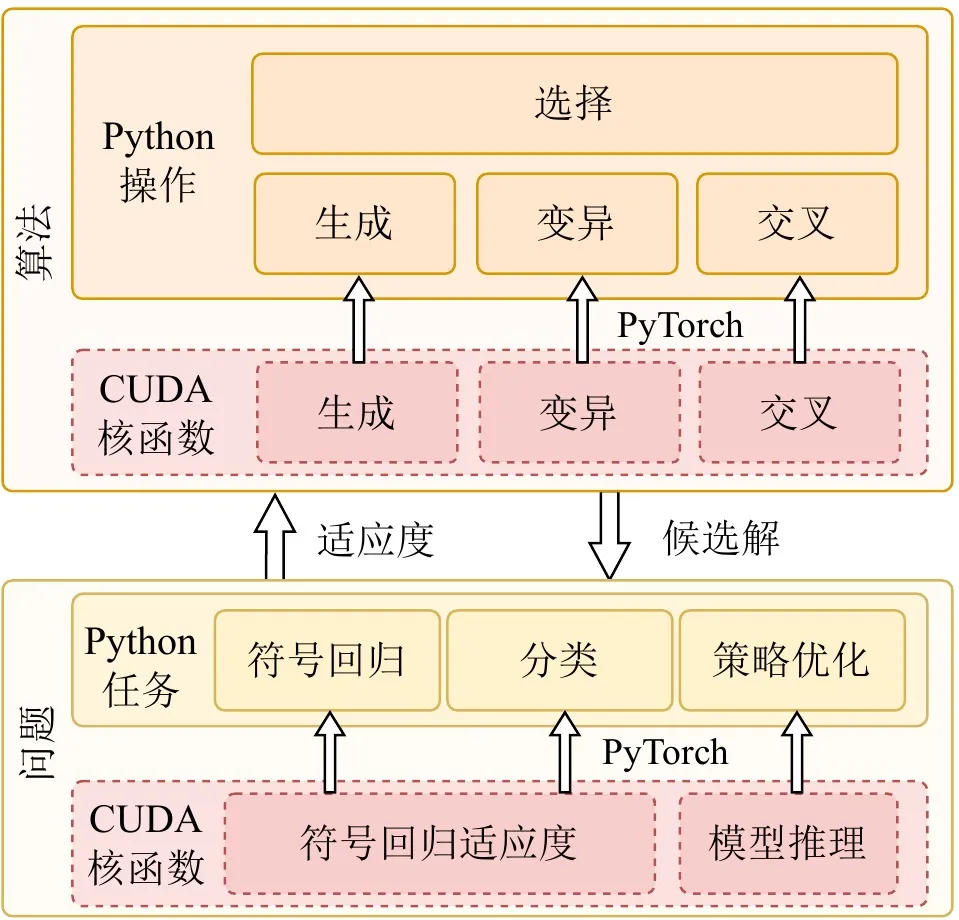
圖 4:整體架構。EvoGP 並非孤立的加速模組,而是一個在底層效能與上層易用性之間取得平衡的完整框架。
在大族群規模下釋放效能
突破運算瓶頸直接拓展了演化演算法的搜尋邊界,使遺傳程式設計真正受益於 GPU 時代。過去,超大規模族群設定往往因運算成本過高而難以實用。在 EvoGP 極高吞吐的族群級並行機制下,處理海量個體已在實務中切實可行。
核心基準測試顯示,EvoGP 的峰值吞吐量突破 10^11 GPops/s,在海量並行下展現出驚人的速度——僅用 1 秒即可完成最多 50 萬規模族群的全面評測。在執行時間上,它對既有 GPU 實作建立了決定性優勢。更關鍵的是,在大規模族群測試中,演算法展現出優秀的可擴展性:在符號迴歸誤差收斂、分類精度提升以及機器人控制任務的累積獎勵等方面,更大的族群始終帶來更優的最終效能。這證明 EvoGP 釋放的不僅是運算速度——它使更大族群能夠在更短的牆鐘時間內達到更高品質的解,從根本上提升了遺傳程式設計方法的搜尋潛力與能力上限。
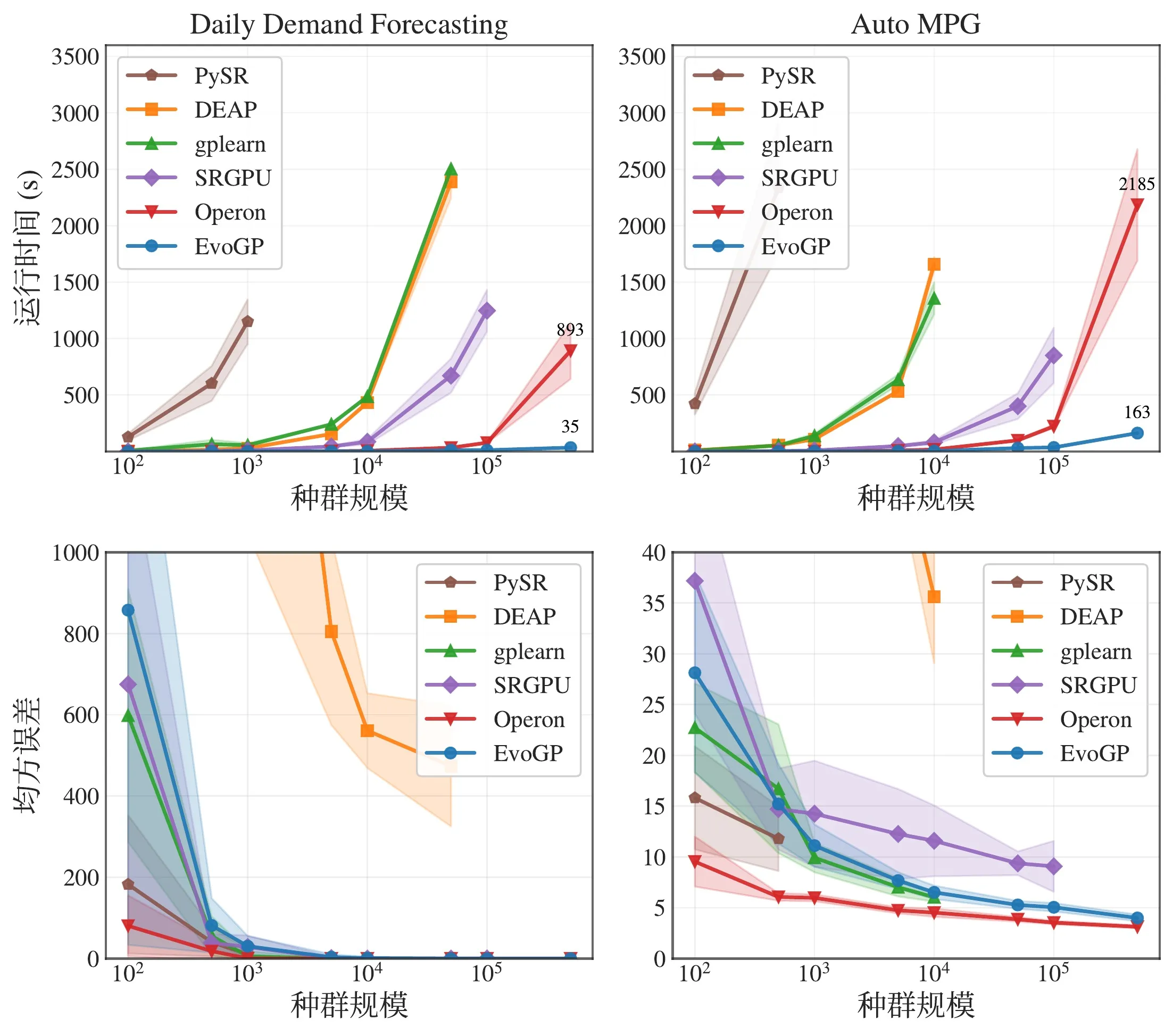
圖 5:整體效能比較。EvoGP 在多種任務設定下均取得顯著效能優勢,同時維持穩定的結果品質。
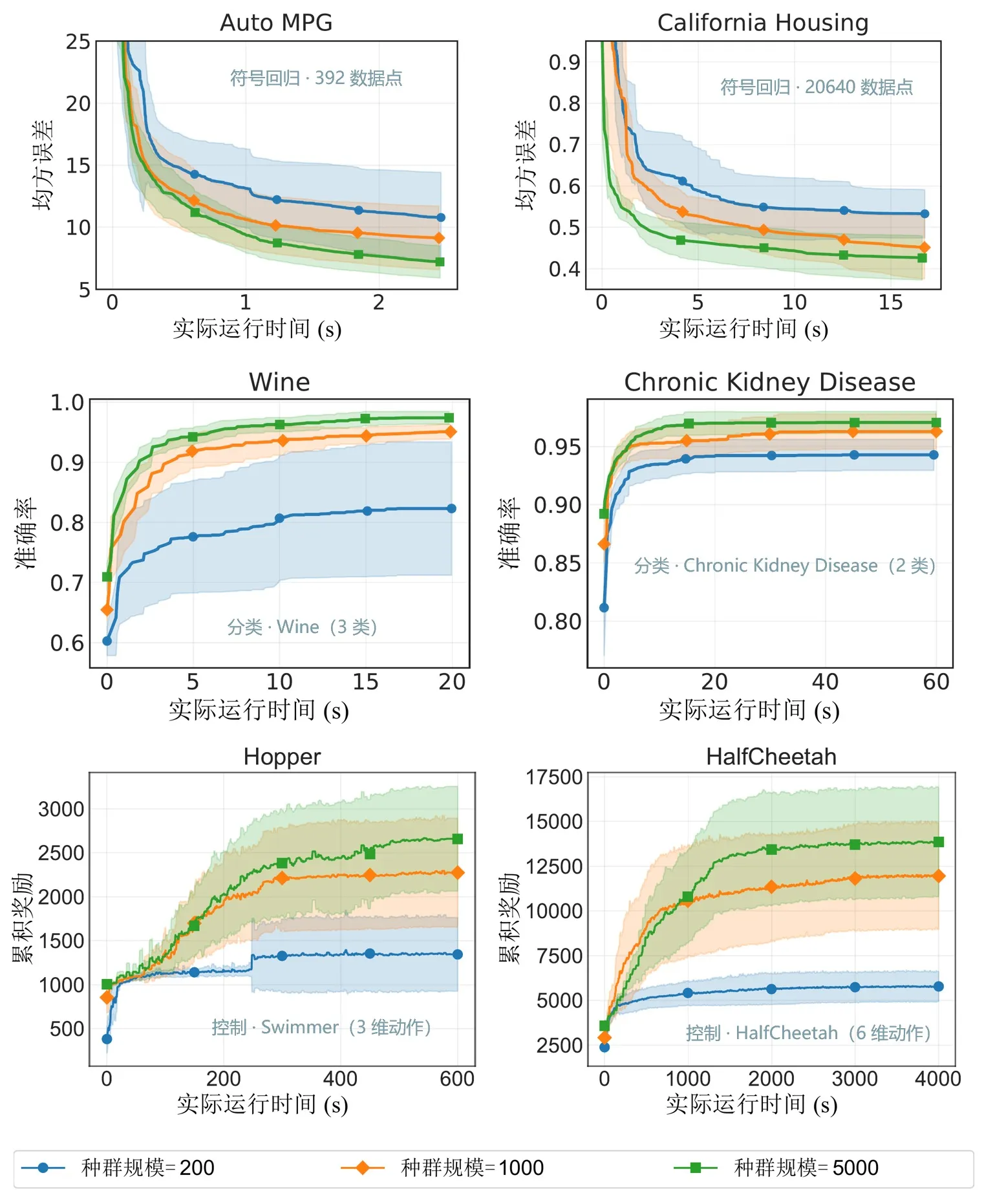
圖 6:不同族群規模下的效能。EvoGP 使更大族群規模在可接受時間內切實可用,並釋放更強的搜尋潛力。
結論
**EvoGP 框架系統性地回答了遺傳程式設計如何有效利用現代 GPU 架構這一問題。**它並非對既有實作的簡單修補,而是透過張量化表示、算子重構與自適應並行,在底層設計上實現了根本性創新——徹底為遺傳程式設計進入高效能運算系統開闢了道路。這項工作不僅展示了經典演化方法在運算時代的持久活力,也為可解釋機器學習與自主智慧代理決策提供了高度可擴展的系統級解決方案——標誌著遺傳程式設計真正進入 GPU 加速時代。
開源 / 社群
📄 論文:
https://ieeexplore.ieee.org/document/11390710
🔗 GitHub:
https://github.com/EMI-Group/evogp
🔼 上游專案(EvoX):
https://github.com/EMI-Group/evox
🌐 QQ 群:297969717

QQ 群 | Evolutionary Machine Intelligence