EvoGO:GPU運算 × 生成式學習 → 10代收斂的演化演算法新範式

近年來,數據驅動的演化最佳化方法取得了顯著進展。從代理輔助的演化演算法到生成式演化演算法,演化最佳化正逐漸從傳統的固定算子驅動範式向學習驅動範式轉變。然而,現有方法在數據驅動的程度上仍存在三個重要的局限性。首先,生成機制與演化過程之間的協調通常仍依賴於人工設計的啟發式規則。其次,生成模型的訓練目標通常繼承自通用的生成任務,與最佳化目標的一致性不足。第三,黑盒最佳化中極其有限卻極具價值的線上樣本尚未被系統地組織為可學習且可遷移的最佳化經驗。為了解決這些問題,EvoX 團隊提出了演化生成最佳化(EvoGO),將整個最佳化過程組織為三個統一的階段:數據準備、模型訓練和種群生成。其目的是使最佳化演算法能夠直接從歷史數據中學習從劣質解向優質解進化的改進規律。實驗結果表明,EvoGO 在數值最佳化、經典控制和高維機器人控制三大類任務中展現出穩定的優勢,涵蓋25個基準測試,問題規模從10維到1000維,在大部分大規模任務上大約10代即可收斂。在複雜任務中,結合 GPU 並行推理,EvoGO 還在實際運行時間上顯示出顯著優勢;當 CMA-ES 達到其收斂效能時,EvoGO 達到相同效能的速度可達134倍。這些結果表明,完全數據驅動的演化最佳化不僅能在標準基準測試中取得有競爭力的結果,而且開始在大型並行任務上展現出實際優勢。
困境:數據驅動最佳化仍未邁出最後一步
近年來,數據驅動的演化最佳化方法發展迅速。代理輔助方法和基於生成模型的方法已經將演化最佳化從固定算子驅動搜尋推向了學習驅動搜尋。這意味著學習模型已開始進入包括評估、建模甚至生成在內的多個流水線階段。
然而,這種轉變仍不徹底。現有方法可能在不同層面上學習了如何“評估”或“生成”,但並未真正學習如何“最佳化”。一方面,下一代候選解的產生通常仍依賴人工設計的啟發式規則進行協調。另一方面,生成目標與最佳化目標往往不夠一致。同時,黑盒最佳化中極其有限的線上樣本尚未被系統地轉化為可學習、可遷移的最佳化經驗。
因此,當前真正缺失的不是更多的模型本身,而是最後一步:使最佳化演算法能夠直接從歷史數據中學習從較差解向更好解演進的過程。這正是 EvoGO 試圖推動的一步。
突破:EvoGO 如何重寫最佳化流水線
為了解決上述問題,EvoGO 沒有繼續沿著改進交叉和變異等局部算子的傳統路線走下去。相反,它試圖在更整體的層面上重寫最佳化流水線。其核心思想是將“如何生成下一代候選解”的過程從人工編寫的規則中剝離出來,交給數據驅動的生成機制去學習。具體而言,EvoGO 將整個最佳化過程組織為三個統一的階段——數據準備、模型訓練和種群生成——從而使經驗組織、方向學習和種群更新不再割裂,而是被整合到一個單一的最佳化循環中。
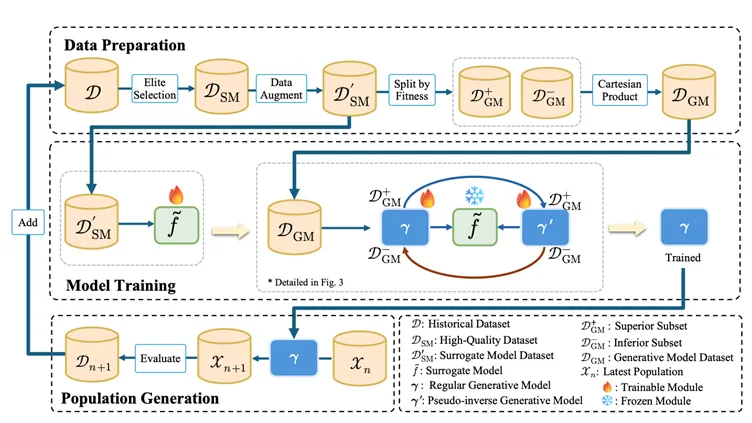
在數據準備階段,EvoGO 首先從歷史種群中篩選出高品質樣本,以構建更可靠的訓練基礎。當樣本稀缺時,還可以利用學習到的數據增強方法來緩解數據不足的問題。更重要的是,樣本被進一步劃分為優勢解和劣勢解,並組織成配對關係。結果,模型學習的不再僅僅是候選解的靜態分布,而是從劣質解向優質解移動的方向關係。
在模型訓練階段,EvoGO 採用由代理模型、前向生成器和偽逆向生成器組成的配對結構。代理模型提供目標地形的近似表徵;前向生成器學習從劣質解到優質解的映射;而偽逆向生成器通過重建一致性約束來保持訓練的穩定性。與一般的生成任務不同,這裡的訓練目標不僅僅是擬合數據分布,而是在目標地形的引導下,確保生成過程向更好的區域移動。
在種群生成階段,訓練好的生成模型直接作用於當前種群,並行產生新一代的候選解。這些解隨後由真實目標函數進行評估,並在進入下一次迭代之前更新種群狀態。此時,種群更新的方式發生了根本性變化。傳統的演化最佳化主要依賴人工指定的交叉、變異和選擇規則來逐步探測搜尋空間,而 EvoGO 則將這一過程轉變為由歷史數據驅動、由生成模型實現的並行更新機制。
EvoGO 的並行性體現在兩個層面。一方面,種群可以用張量化形式表示,允許個體的生成和評估在 GPU 上並行運行。另一方面,EvoGO 也可以在單個 GPU 上同時運行多個生成模型,從而實現跨不同隨機種子或不同問題實例的並行最佳化。因此,它的並行能力既存在於種群內部,也存在於多個種群之間。
從這個角度來看,EvoGO 的關鍵貢獻不僅在於引入了生成模型,更在於將樣本組織、目標對齊和種群更新統一在一個單一的方法論框架內。傳統的演化最佳化強調由預寫規則驅動的搜尋,而 EvoGO 更進一步,試圖讓系統直接從歷史數據中學習搜尋過程本身。
驗證:效能與機制分析
為了嚴格評估這種新的完全數據驅動範式的有效性,論文聚焦於三個關鍵問題:EvoGO 是否足夠強大和高效?其成功背後的關鍵設計選擇是什麼?它展現出怎樣的智能搜尋行為?
1. 效能對比:“10代收斂”領跑基準測試
論文在數值最佳化、經典控制和高維機器人控制三大類任務上進行了系統評估,涵蓋25個基準測試,問題維度從10到1000不等。EvoGO 與貝葉斯最佳化、經典演化策略、啟發式方法以及先進的代理輔助方法進行了全面比較。
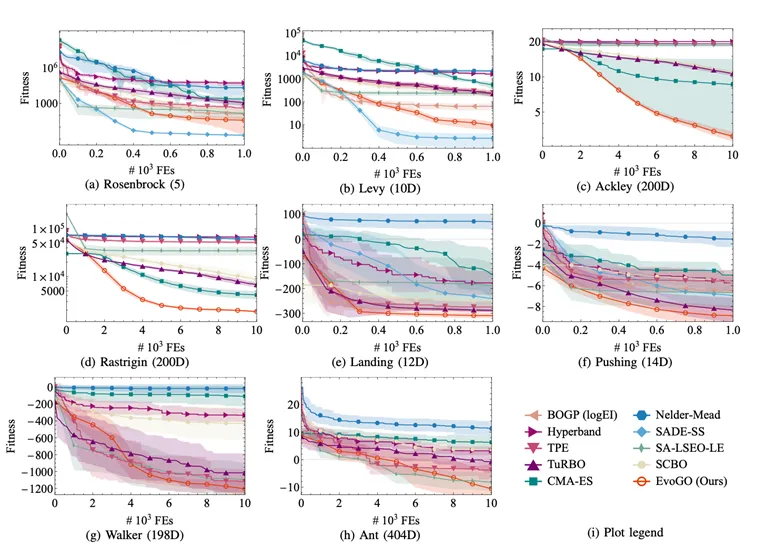

總體而言,EvoGO 在絕大多數任務上都展現出了明顯的優勢。值得注意的是,這種優勢並不侷限於低維或相對規則的問題。相反,隨著問題維度和任務複雜度的增加,EvoGO 的優勢往往變得更加明顯。在低維和小樣本條件下,一些最強的代理輔助方法仍然極具競爭力。但一旦問題變成高維、複雜且依賴於並行計算,EvoGO 的生成機制就能更充分地發揮作用,在大多數大規模任務上它可以在大約10代內收斂。這表明 EvoGO 的價值並不在於在某一種題型上取得局部優勢,而在於更適合複雜黑盒最佳化所需的大規模經驗利用和並行搜尋。
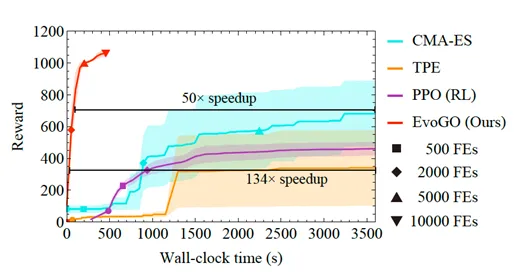
這在 Brax 中的高維機器人控制環境 Hopper 中表現得尤為明顯。在相同的函數評估預算和運行時間預算下,EvoGO 顯著優於 CMA-ES 和 TPE 等傳統最佳化演算法,同時也超越了需要與環境進行線上交互的 PPO 強化學習演算法。更重要的是,得益於 GPU 等現代硬體的並行計算能力,EvoGO 可以在大約 500 秒內達到很高的獎勵水準。當 CMA-ES 最終收斂到其最佳效能水準時,EvoGO 達到相同效能所需的實際時鐘時間要短得多——最多可實現134倍的加速。這一結果表明,EvoGO 的優勢不僅在於減少了迭代代數,更在於其搜尋過程本身能更好地匹配並行計算資源,將原本分散在許多代中的最佳化動作壓縮為高吞吐量的生成更新過程。
2. 消融實驗:剖析成功的關鍵
為了驗證 EvoGO“完全數據驅動”設計中核心組件的必要性,研究團隊圍繞配對生成架構、代理引導機制和面向最佳化的目標設計進行了系統的消融實驗。構建了五個變體:單生成器版本、無代理版本、對抗目標版本、MLP代理版本和啟發式代理版本。
實驗結果表明,配對生成架構、代理引導機制和面向最佳化的目標設計對 EvoGO 的有效性都至關重要。移除偽逆向生成器會導致收斂穩定性明顯變差、種群多樣性降低,這表明由前向生成和逆向約束形成的配對結構對於保持訓練穩定性和避免模式崩潰是必要的。移除代理模型,或將原始最佳化目標替換為通用對抗目標,也會導致顯著的效能下降,說明代理引導和目標對齊是該方法優勢的核心。將高斯過程替換為多層感知機或啟發式規則後,方法仍能發揮作用,但整體效能略有下降,這表明 EvoGO 並不依賴特定的代理形式,儘管顯式的不確定性建模對效能更有利。總體而言,EvoGO 的效能提升並非來自任何單一模組,而是源於配對生成架構、代理引導機制和面向最佳化的目標設計之間的協同作用。
3. 行為視覺化:揭示數據驅動的動態過程
為了更直觀地分析 EvoGO 的搜尋動態,論文在二維 Ackley 函數上進行了視覺化實驗,種群規模設為 100。具體來說,在不同的演化代數中,記錄了訓練好的前向生成器對輸入解的變換結果——即追蹤了從輸入解到輸出解的映射過程。圖中,箭頭表示從輸入解到輸出解的向量,其顏色對應於向量長度。星號標記全域最佳解,虛線框指示不同代數中生成的解所覆蓋的區域。為了清晰起見,此視覺化中省略了函數地形的平移和旋轉設置。
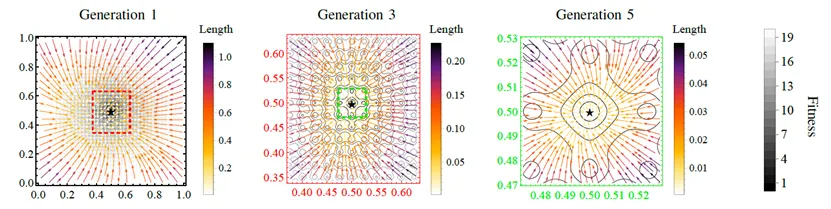
視覺化結果顯示,EvoGO 學到的並不是無方向的隨機擾動,而是隨搜尋階段自適應變化的更新模式。在早期階段,生成的向量通常較長,表明演算法傾向於大幅度的全域探索。隨著演化的進行,向量長度逐漸減小,生成的區域繼續收縮,表明搜尋轉向更精細的局部利用。與此同時,向量整體上向最佳區域聚集,這表明前向生成器已經從歷史樣本中提取出了具有實際意義的搜尋方向。在行為層面上,這一現象支持了 EvoGO 的核心屬性:它學習的不僅是候選解的分布,而是從當前狀態向更好狀態移動的更新規律。
應用:寬體客機超臨界機翼工程驗證
C919 的成功交付標誌著中國在國產大飛機研製上邁出了關鍵一步。然而,作為單通道窄體客機,C919 主要服務於中短途航線,寬體客機領域仍需突破。為滿足下一代國產寬體客機的研製需求,超臨界機翼設計已成為氣動最佳化中的關鍵問題,在降低巡航阻力、提高燃油效率和增強飛行穩定性方面發揮著重要作用。因此,如何實現高效可靠的超臨界機翼最佳化已成為我國寬體客機研製過程中的核心技術挑戰。
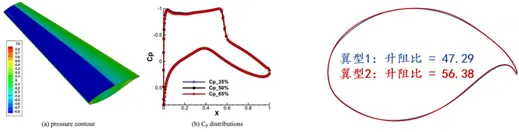
如原文獻所示,通過最佳化更長的弦長、更平坦的上表面和增加的後緣彎度等幾何特徵,超臨界機翼可以調節跨音速壓力分布、抑制激波形成、降低波阻並提高升力效率。然而,其最佳化設計面臨多重挑戰。一方面,在寬體客機的高雷諾數條件下,設計必須同時滿足升阻比、升力係數和巡航迎角等嚴格的氣動約束,這對形狀參數提出了極高的精度要求。另一方面,翼型幾何形狀與氣動效能之間存在強非線性耦合關係,傳統的建模方法難以準確表徵。此外,現有的設計過程嚴重依賴經驗、反覆的 CFD 模擬和風洞實驗,導致計算成本高、開發週期長,且難以在高維設計空間中有效逼近全域最佳。
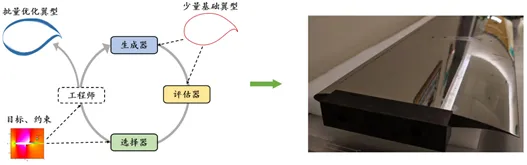
為了解決這一問題,EvoX 團隊構建了一個基於 EvoGO 的集成設計流水線,包括效能評估、翼型生成和候選篩選。基於少量的歷史翼型樣本,該方法構建了效能評估模型、翼型生成模型和篩選模型,並通過迭代演化不斷改進翼型設計。使用代理模型來準確預測升阻比、升力係數和巡航迎角等關鍵指標。同時,引入生成機制來取代傳統的啟發式搜尋,從而能夠在高維設計空間中高效逼近最佳解。結合候選篩選策略,該方法可以從龐大的搜尋空間中快速識別出既滿足物理約束又符合氣動效能要求的候選翼型,從而提高設計效率。
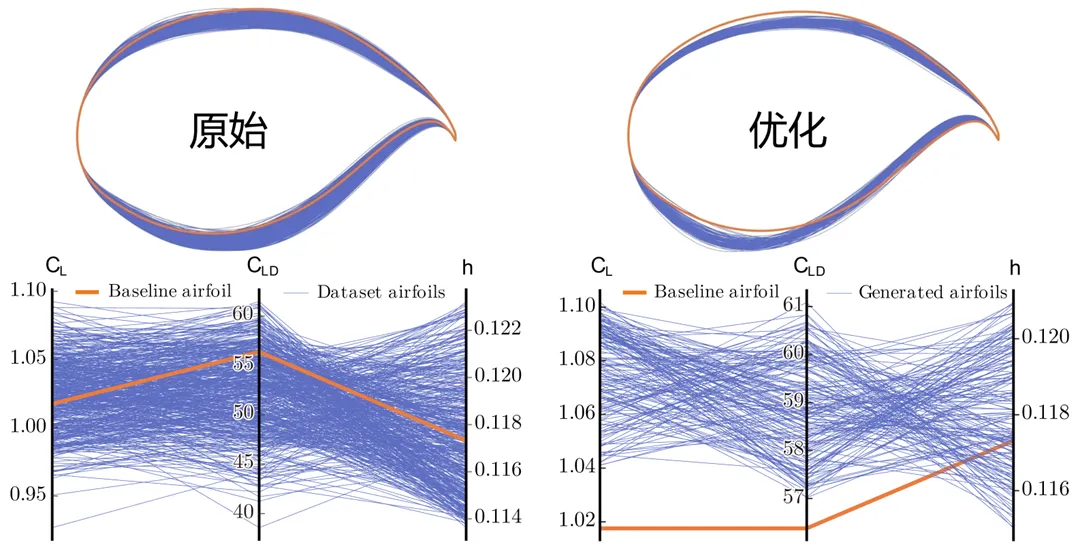
僅使用 500 個歷史翼型樣本,該方法在升阻比、升力係數和巡航迎角三個關鍵氣動指標上的預測精度就達到了 99.5% 以上,自動生成的翼型的合格率超過 95%。這些結果表明,完全數據驅動的演化最佳化方法(如 EvoGO)不僅能在標準基準測試中表現出色,而且開始展現出為複雜實際工程問題提供有效設計支持的能力。
深化視野:從物理到哲學,重新解讀 EvoGO
物理視角:從無序試錯到有序演化
從物理的角度來看,黑盒最佳化可以理解為一個在真實但不可完全觀測的勢場中,逐步尋找更穩定狀態的過程。對於最佳化器而言,目標函數及其適應度地形始終客觀存在,但在初始時刻,系統只能通過有限的採樣和評估獲取局部知識。因此,搜尋自然帶有很高的不確定性。
傳統的演化最佳化更多地依賴於局部擾動和隨機試錯。雖然它可以通過反覆採樣和選擇逐漸逼近更好的區域,但搜尋過程在很大程度上仍表現為高熵的局部探索,歷史經驗難以被系統地積累。EvoGO 的與眾不同之處在於,它進一步將歷史樣本組織為編碼了方向和結構的資訊基礎。代理模型提供了對局部目標地形的近似理解;優勢解和劣勢解的配對提取了從較差區域向更好區域移動的方向資訊;而前向生成和逆向約束形成的循環使得這一方向性更新過程在保持穩定的同時能夠持續展開。
用物理學術語來說,EvoGO 更像是一個在有效勢場引導下有序結構逐漸形成的過程。它所做的不僅是加速搜尋,而是在有限的觀測能力下逐步降低搜尋的不確定性,將種群更新從無序的試錯轉變為有組織的演化流。速度僅僅是結果;更深層的改變在於,歷史經驗開始被轉化為可以積累、傳遞和重用的結構化資訊。
哲學視角:從“道生萬物”到規律生成
從哲學的角度來看,EvoGO 更值得強調的一點是,它體現了一個從經驗到秩序、從局部到整體的生成過程。這個過程可以用經典的一句話來概括:“道生一,一生二,二生三,三生萬物。”
**“道”**對應於目標問題中客觀存在但無法被完全掌握的真實規律。在最佳化中,最佳解不是由演算法主觀規定的;相反,它始終潛藏在真實的目標函數及其適應度地形中。演算法能做的不是創造道,而是不斷逼近它。
**“一”**對應於從雜亂的經驗中提取出的統一結構。歷史樣本起初不過是散亂的搜尋痕跡;它們並不會自動構成知識。只有當這些樣本被分類、篩選和組織時,經驗才開始從無序走向可學習的整體。這就是“生一”的含義。
**“二”**對應於分化——方向的出現。優勢解和劣勢解的劃分不僅代表了好壞的區分;更重要的是,它標誌著系統第一次從經驗中獲得了方向感。沒有這種分化,經驗只是堆積;有了它,經驗就獲得了演化的張力。
**“三”**對應於閉環——關係的生成。當目標認知、前向推進和逆向約束共同形成一個自洽的系統時,最佳化不再是局部操作的拼湊,而是開始形成一個能夠自我維護和自我修正的完整機制。至此,該方法才真正具備了持續生成新解的能力。
**“萬物”**則對應於在這個生成秩序之上不斷湧現的新種群和新候選解。它們不是盲目產生的,而是在已經形成的方向、結構和閉環約束下持續生成的。正因如此,EvoGO 所推進的不僅僅是“更快地找到更好的解”的能力,而是演化最佳化從經驗中生成規律,然後再不斷從這些規律中生成解的新能力。
EvoGO 的哲學意義不在於簡單地替換傳統算子。相反,它在於更清晰地表明,最佳化不一定只靠預寫規則來推進;通過經驗的積累、分化和組織,它可以逐漸形成自身的生成秩序。
結論與展望
EvoGO 關注的不僅是對傳統演化最佳化流水線的局部改進,更是對最佳化過程本身的根本性重構。通過將最佳化組織為數據準備、模型訓練和種群生成三個統一的階段,並引入基於優劣配對的方向性數據構建、代理引導的配對生成架構以及並行種群生成機制,EvoGO 在標準基準測試中展現出效能和效率兩方面的穩定優勢。同時,它也通過新一代寬體客機超臨界機翼最佳化設計驗證了其在複雜實際工程問題上的潛力。在更高的層面上,這項工作的意義在於表明,演化最佳化不一定必須侷限於人工指定的啟發式規則。最佳化過程本身可以作為一種可學習的規律,從歷史經驗中逐步提煉出來。
開源代碼/社區
- 論文:
https://arxiv.org/abs/2602.01147 - GitHub:
https://github.com/EMI-Group/evogo - 上游項目(EvoX):
https://github.com/EMI-Group/evox - QQ群:
297969717 - 微信公眾號: 進化智能(Evolutionary Machine Intelligence)
EvoGO 建立在 EvoX 框架之上。如果你對 EvoX 感興趣,歡迎在 EvoX 公眾號中查看相關文章(https://mp.weixin.qq.com/s/uT6qSqiWiqevPRRTAVIusQ)以獲取更多詳細資訊。