Объединение эволюционной многокритериальной оптимизации и ускорения на GPU с помощью тензоризации
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun и Ran Cheng, Senior Member, IEEE
В связи с постоянным ростом спроса на сложные оптимизационные решения в таких областях, как инженерное проектирование и управление энергопотреблением, алгоритмы эволюционной многокритериальной оптимизации (EMO) привлекли широкое внимание благодаря своим мощным возможностям в решении многокритериальных задач. Однако по мере роста масштаба и сложности задач оптимизации традиционные алгоритмы EMO на базе CPU сталкиваются со значительными узкими местами в производительности.
Чтобы преодолеть это ограничение, команда EvoX предложила распараллелить алгоритмы EMO на GPU с помощью методологии тензоризации. Используя этот метод, они успешно спроектировали и реализовали несколько алгоритмов EMO с ускорением на GPU. Кроме того, команда разработала «MoRobtrol» — набор бенчмарков для многокритериального управления роботами, построенный на физическом движке Brax и предназначенный для систематической оценки производительности алгоритмов EMO с ускорением на GPU.
Основываясь на этих исследовательских достижениях, команда EvoX выпустила EvoMO — высокопроизводительную библиотеку алгоритмов EMO с ускорением на GPU. Соответствующий исходный код общедоступен на GitHub: https://github.com/EMl-Group/evomo
Методология тензоризации
В области вычислительной оптимизации тензор (tensor) относится к многомерной структуре данных массива, способной представлять скаляры, векторы, матрицы и данные более высокого порядка. Тензоризация (tensorization) — это процесс преобразования структур данных и операций внутри алгоритма в тензорную форму, что позволяет алгоритму в полной мере использовать возможности параллельных вычислений GPU.
В алгоритмах EMO все ключевые структуры данных могут быть выражены в тензоризованном формате. Особи в популяции могут быть представлены тензором решений X, где каждый вектор-строка соответствует особи. Значения целевых функций образуют тензор целей F. Кроме того, вспомогательные структуры данных, такие как референсные векторы и векторы весов, могут быть выражены в виде тензоров R и W соответственно. Это унифицированное тензорное представление позволяет выполнять операции на уровне популяции на уровне представления, закладывая прочный фундамент для крупномасштабных параллельных вычислений.
Тензоризация операций алгоритма EMO имеет решающее значение для повышения эффективности вычислений и может быть разделена на два уровня: базовые тензорные операции и тензоризация потока управления. Базовые тензорные операции составляют ядро тензоризованной реализации алгоритмов EMO, как подробно описано в Таблице I.
Таблица I: Базовые тензорные операции

Тензоризация потока управления заменяет традиционную логику циклов и условий параллелизуемыми тензорными операциями. Например, циклы for/while могут быть преобразованы в пакетные операции с использованием механизмов трансляции (broadcasting) или функций высшего порядка, таких как vmap. Аналогично, условия if-else могут быть заменены методами маскирования, где логические условия кодируются как логические тензоры, что позволяет гибко переключаться между различными путями вычислений.
По сравнению с традиционными реализациями алгоритмов EMO, подход с тензоризацией предлагает значительные преимущества. Во-первых, он обеспечивает большую гибкость, естественным образом обрабатывая многомерные данные, в то время как обычные методы часто ограничиваются двумерными матричными операциями. Во-вторых, тензоризация значительно повышает эффективность вычислений за счет параллельного выполнения, избегая накладных расходов, связанных с явными циклами и условными ветвлениями. Наконец, это упрощает структуру кода, что приводит к созданию более лаконичных и удобных в обслуживании программ.
Как показано на Рис. 1, например, традиционная реализация проверки доминирования по Парето опирается на вложенные циклы для выполнения поэлементных сравнений. Напротив, тензоризованная версия достигает той же функциональности с помощью операций трансляции и маскирования, обеспечивая параллельную оценку. Это не только снижает сложность кода, но и резко повышает производительность во время выполнения.

Рис. 1: Сравнение традиционной и тензорной реализаций определения доминирования по Парето.
С более глубокой точки зрения, тензоризация хорошо подходит для ускорения на GPU, поскольку GPU обладают большим количеством параллельных ядер, а их архитектура SIMT (одна инструкция — много потоков) естественным образом согласуется с тензорными вычислениями, особенно преуспевая в матричных операциях. Специализированное оборудование, такое как Tensor Cores от NVIDIA, еще больше повышает пропускную способность тензорных операций. В целом, алгоритмы, обладающие высоким параллелизмом, содержащие независимые вычислительные задачи и имеющие минимальное количество условных ветвлений, более пригодны для тензоризации. Для таких алгоритмов, как MOEA/D, которые включают последовательные зависимости, внутренняя структура создает трудности для прямой тензоризации. Однако путем структурного рефакторинга и разделения критических вычислений все же можно достичь эффективного параллельного ускорения.
Пример применения тензоризации алгоритма
На основе методологии тензоризованного представления команда EvoX спроектировала и реализовала тензоризованные версии трех классических алгоритмов EMO: NSGA-III на основе доминирования, MOEA/D на основе декомпозиции и HypE на основе индикаторов. В следующем разделе представлено подробное объяснение на примере MOEA/D. Тензоризованные реализации NSGA-III и HypE можно найти в упомянутой статье.
Как показано на Рис. 2, традиционный MOEA/D разбивает многокритериальную задачу на несколько подзадач, каждая из которых оптимизируется независимо. Алгоритм состоит из четырех основных этапов: скрещивание и мутация, оценка приспособленности, обновление идеальной точки и обновление окрестности. Эти шаги выполняются последовательно для каждой особи в рамках одного цикла. Такая последовательная обработка приводит к существенным вычислительным затратам при работе с большими популяциями, так как каждая особь должна пройти все этапы по порядку, что ограничивает потенциальные преимущества ускорения на GPU. В частности, обновление окрестности опирается на взаимодействие между особями, что еще больше усложняет распараллеливание.

Рис. 2: Псевдокод MOEA/D
Чтобы решить проблему последовательных зависимостей в традиционном MOEA/D, команда представила метод тензоризованного представления во внутреннем цикле селекции (environmental selection). Путем разделения скрещивания и мутации, оценки приспособленности, обновления идеальной точки и обновления окрестности, эти компоненты рассматриваются как независимые операции. Это позволяет осуществлять параллельную обработку всех особей, что ведет к созданию тензоризованного алгоритма MOEA/D, называемого TensorMOEA/D. В этом алгоритме селекция разделена на два основных этапа: сравнение и обновление популяции, а также выбор элитных решений. Эти два этапа в основном тензоризуются с помощью двух применений операции vmap. Подробный процесс показан на Рис. 3.
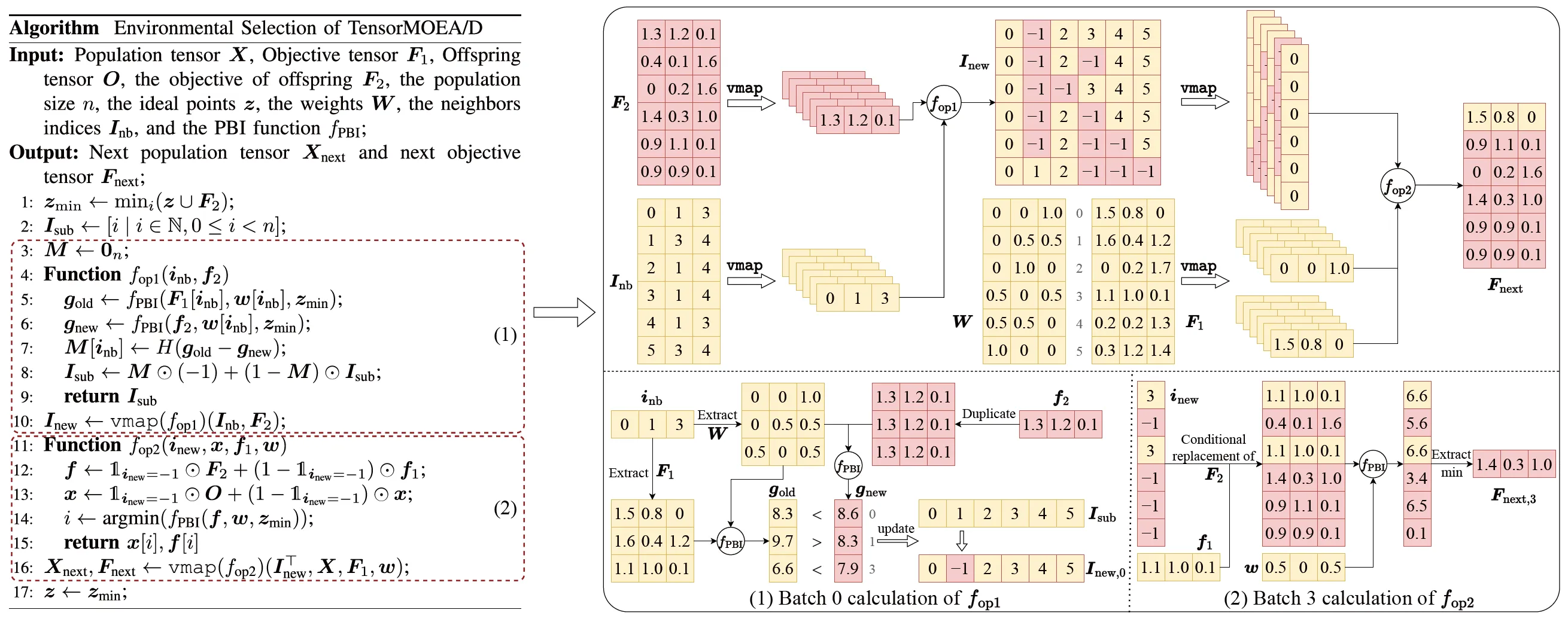

Рис. 3: Обзор селекции в алгоритме TensorMOEA/D. Слева: Псевдокод алгоритма. Справа: Тензорный поток данных модулей (1) и (2). Верхняя часть правого рисунка показывает общий тензорный поток данных для модулей (1) и (2), а нижняя часть представляет тензорный поток данных пакетных вычислений, с модулем (1) слева и модулем (2) справа.
Чтобы получить более полное представление о ценности тензоризации в алгоритмах EMO, ее можно резюмировать с трех точек зрения. Во-первых, тензоризация позволяет напрямую преобразовывать математические формулировки в эффективный код, сокращая разрыв между проектированием и реализацией алгоритма. Например, на Рис. 4 показано, как процедура тензоризованной недоминируемой сортировки может быть переведена напрямую из псевдокода в код на Python. Во-вторых, тензоризация значительно упрощает структуру кода, объединяя операции на уровне популяции в единое тензорное представление. Это снижает зависимость от циклов и условных операторов, тем самым улучшая читаемость и поддерживаемость кода. В-третьих, тензоризация повышает воспроизводимость алгоритмов. Ее структурированное представление облегчает сравнительное тестирование и последовательное воспроизведение результатов.

Рис. 4: Плавный переход тензоризованной недоминируемой сортировки из псевдокода (слева) в код на Python (справа).
Демонстрация производительности
Для оценки производительности алгоритмов многокритериальной оптимизации с ускорением на GPU команда EvoX систематически провела три категории экспериментов, сосредоточившись на вычислительном ускорении, производительности численной оптимизации и эффективности в задачах многокритериального управления роботами.
Производительность вычислительного ускорения:
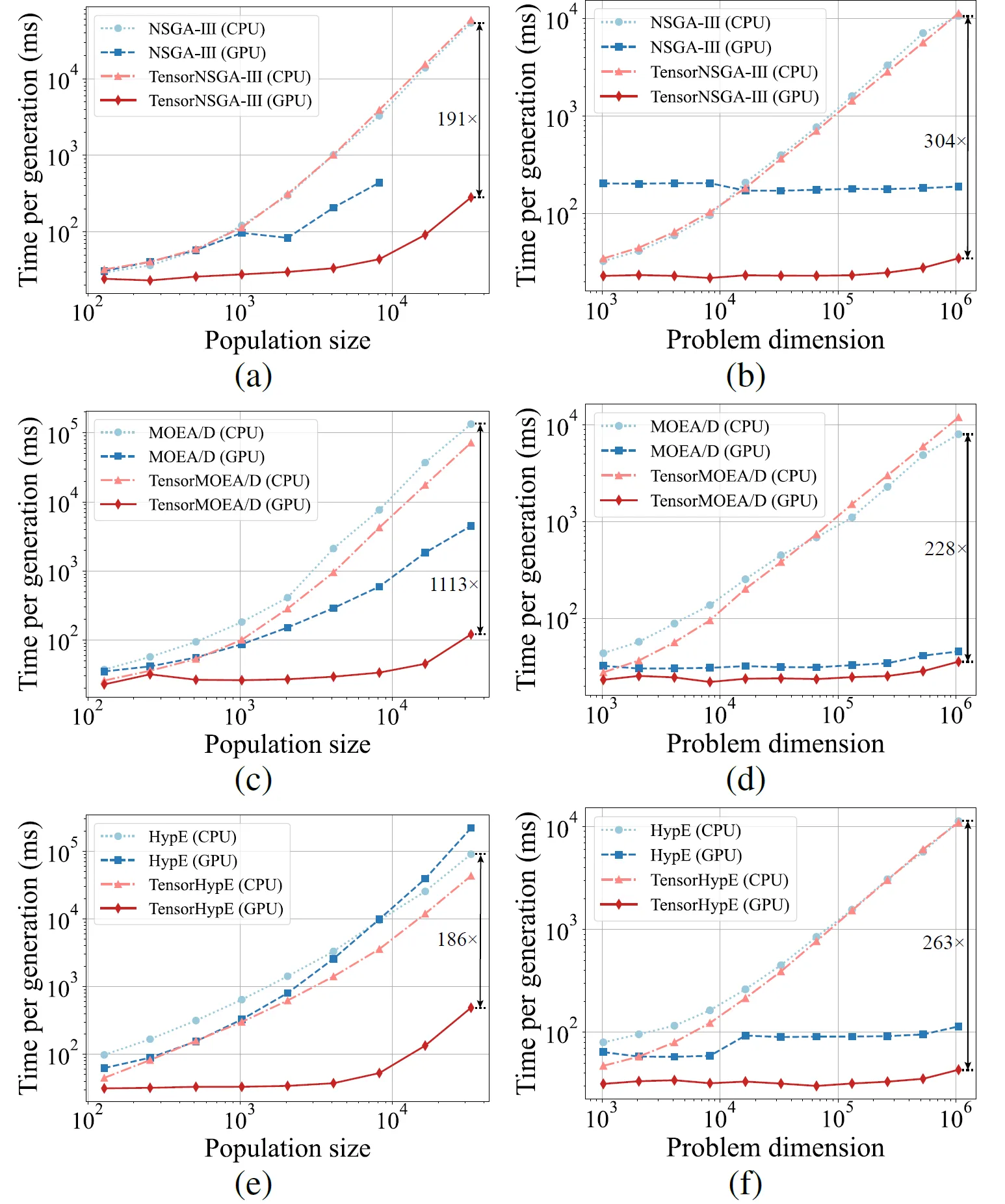
Рис. 5: Сравнительная производительность ускорения NSGA-III, MOEA/D и HypE с их тензоризованными аналогами на платформах CPU и GPU при различных размерах популяции и размерности задачи.
Результаты экспериментов показывают, что TensorNSGA-III, TensorMOEA/D и TensorHypE достигают значительно более высоких скоростей выполнения на GPU по сравнению с их нетензоризованными аналогами на базе CPU. По мере увеличения размера популяции и размерности задачи максимальное наблюдаемое ускорение достигает 1113x. Тензоризованные алгоритмы демонстрируют отличную масштабируемость и стабильность при обработке крупномасштабных вычислительных задач — время их выполнения увеличивается лишь незначительно, при этом сохраняется неизменно высокая производительность. Эти результаты подчеркивают существенные преимущества тензоризации для ускорения на GPU в многокритериальной оптимизации.
Производительность на наборе тестов LSMOP:
Таблица II: Статистические результаты (среднее значение и стандартное отклонение) IGD и времени выполнения (с) для нетензоризованных и тензоризованных алгоритмов EMO в задачах LSMOP1–LSMOP9. Все эксперименты проводились на GPU RTX 4090, лучшие результаты выделены жирным шрифтом.
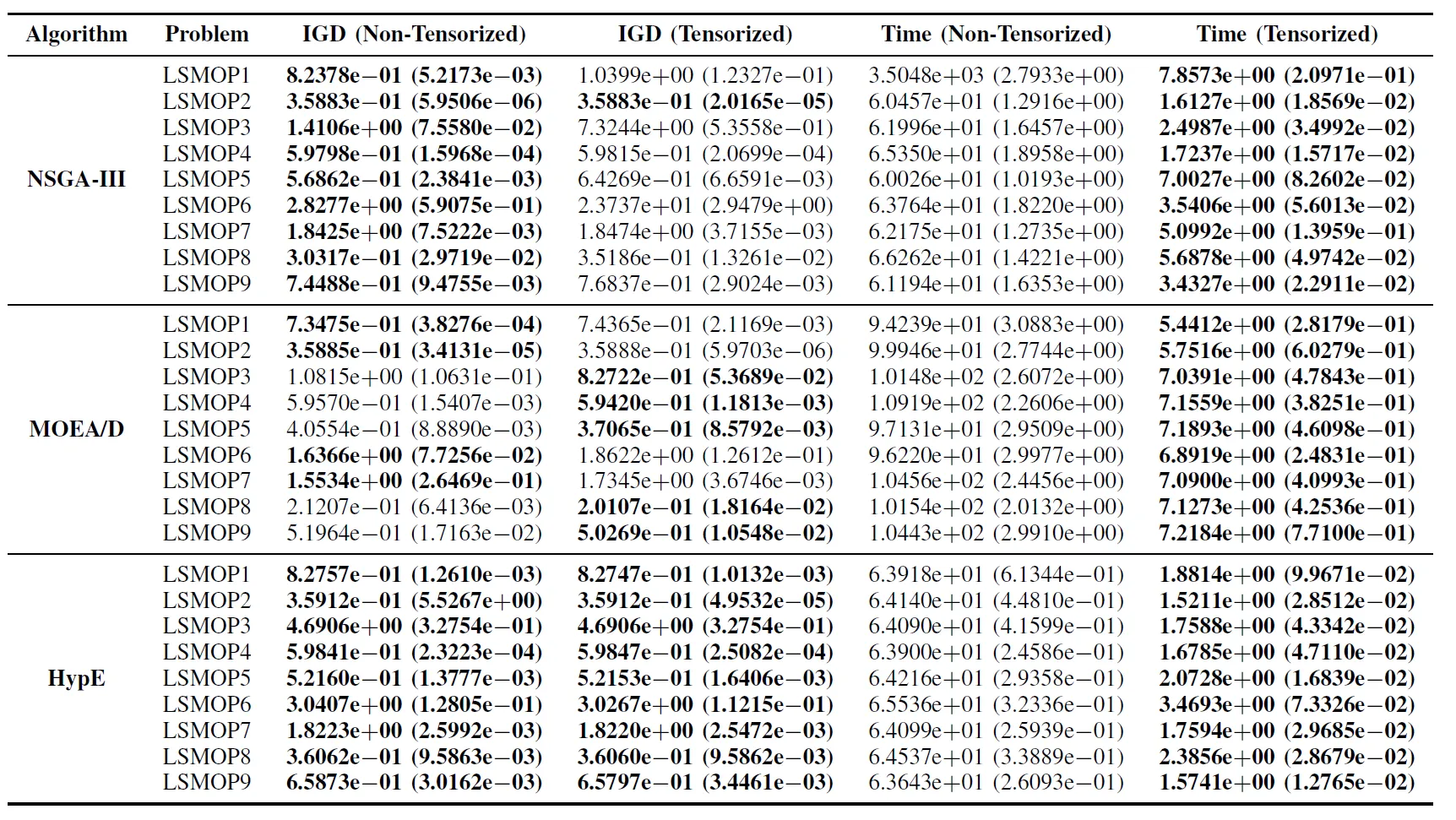
Результаты экспериментов показывают, что алгоритмы EMO с ускорением на GPU, основанные на тензоризованных представлениях, значительно повышают эффективность вычислений, сохраняя, а в некоторых случаях даже превосходя точность оптимизации своих оригинальных аналогов.
Задачи многокритериального управления роботами:
Для всесторонней оценки практической производительности алгоритмов EMO с ускорением на GPU команда разработала набор бенчмарков под названием MoRobtrol для многокритериального управления роботами. Задачи, включенные в этот набор, перечислены в Таблице III.
Таблица III: Обзор задач многокритериального управления роботами в предлагаемом наборе бенчмарков MoRobtrol
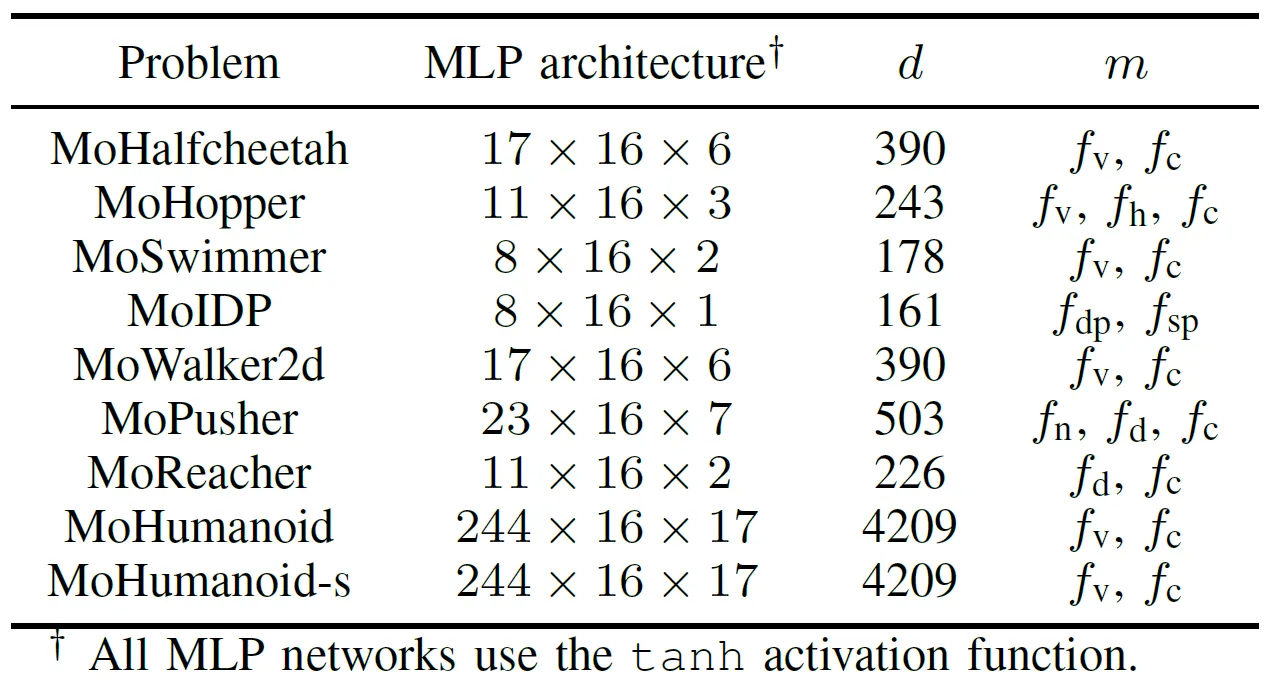
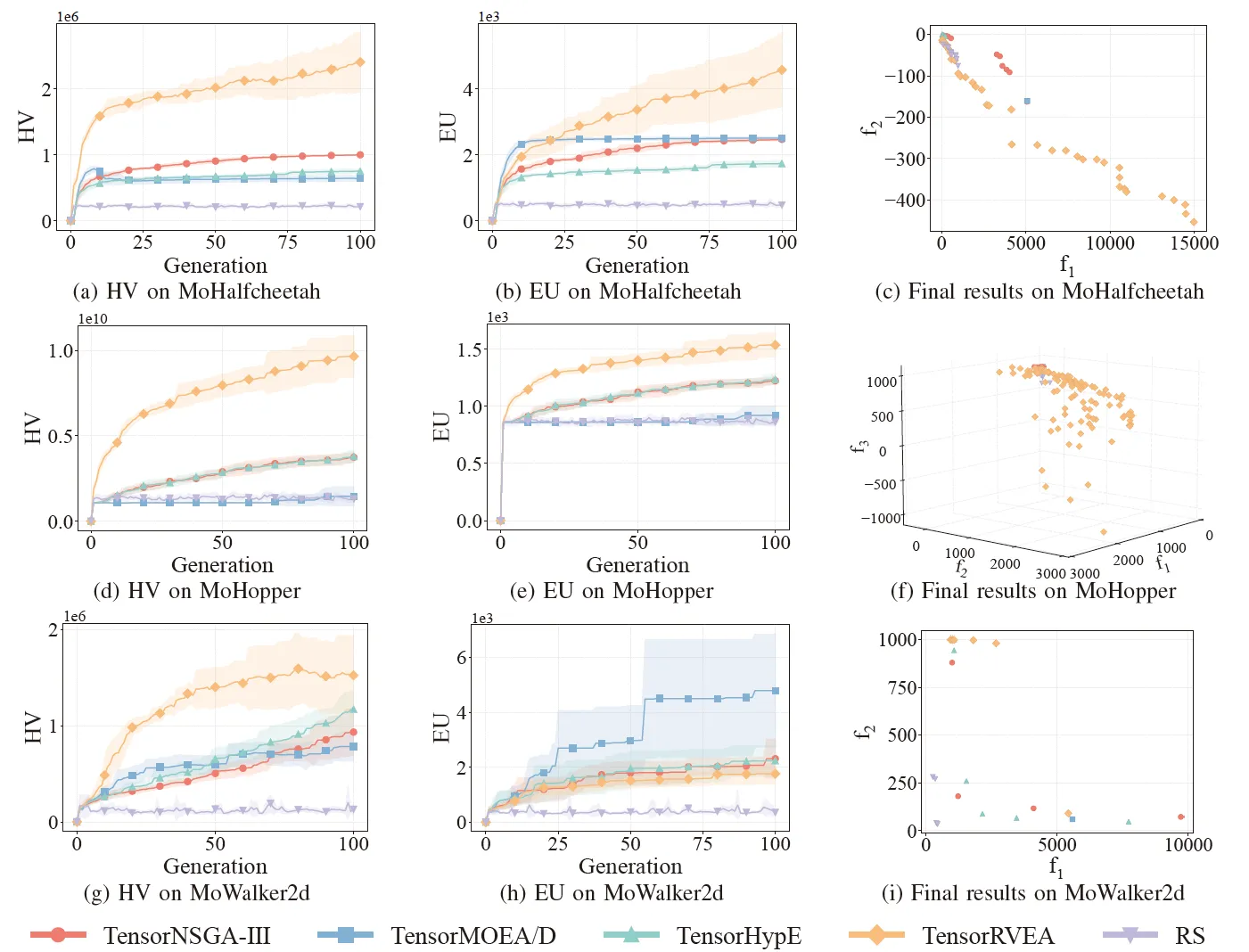
Рис. 6: Сравнительная производительность (HV, EU и визуализация конечных результатов) TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA и случайного поиска (RS) в различных задачах: MoHalfcheetah (390D), MoHopper (243D) и MoWalker2d (390D). Примечание: Более высокие значения для всех метрик указывают на лучшую производительность.
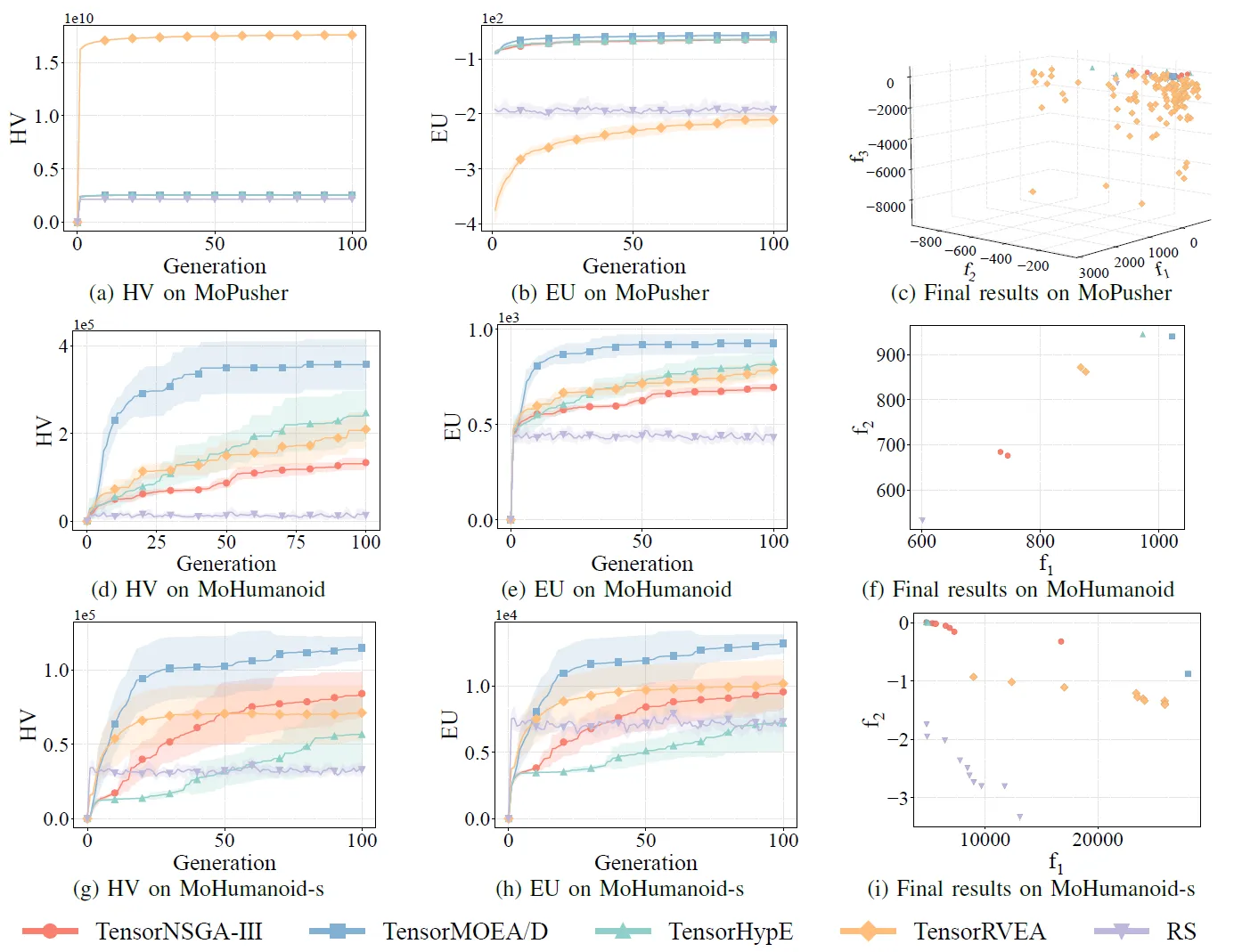
Рис. 7: Сравнительная производительность (HV, EU и визуализация конечных результатов) TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA и случайного поиска (RS) в различных задачах: MoPusher (503D), MoHumanoid (4209D) и MoHumanoid-s (4209D). Примечание: Более высокие значения для всех метрик указывают на лучшую производительность.
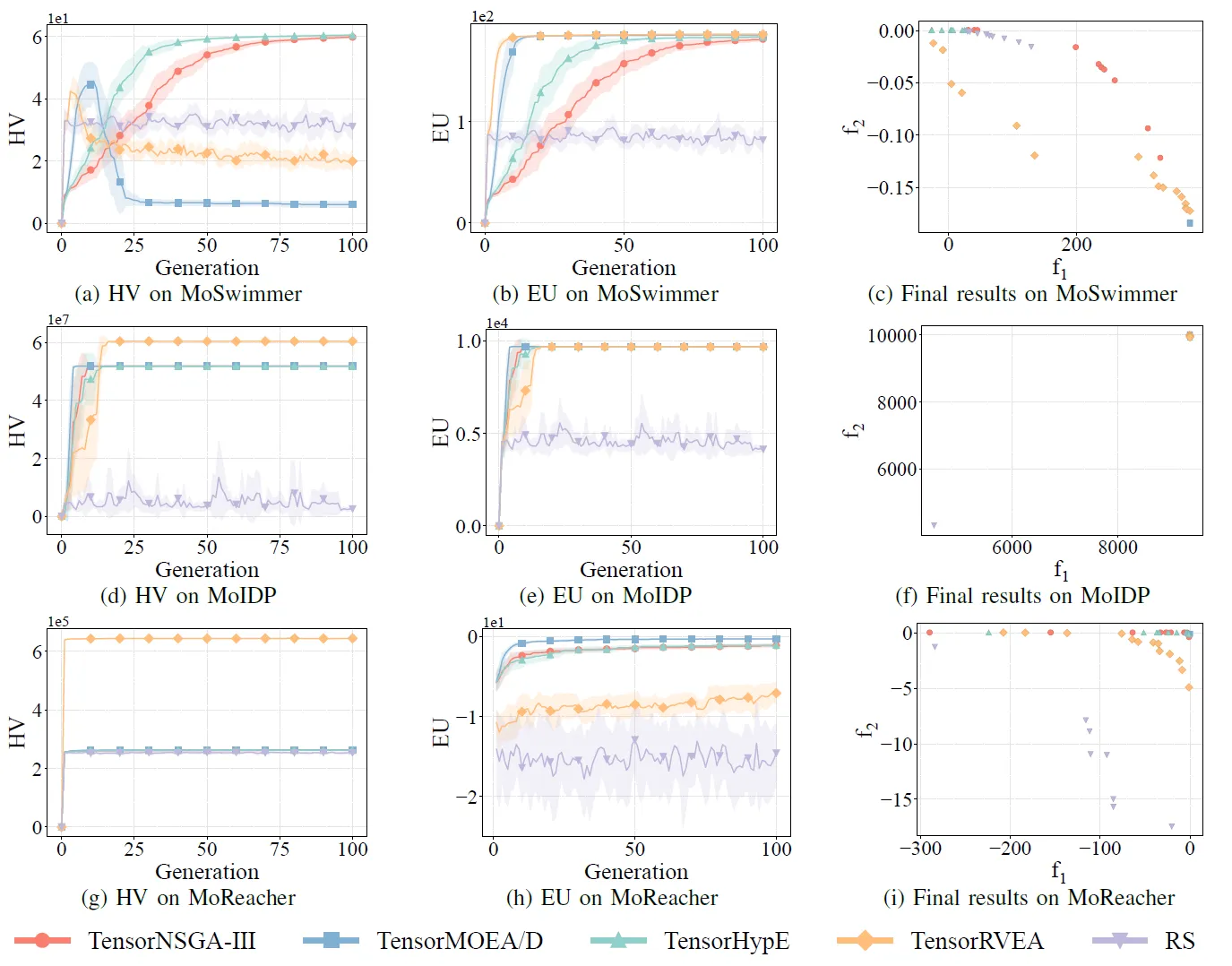
Рис. 8: Сравнительная производительность (HV, EU и визуализация конечных результатов) TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA и случайного поиска (RS) в различных задачах: MoSwimmer (178D), MoIDP (161D) и MoReacher (226D). Примечание: Более высокие значения для всех метрик указывают на лучшую производительность.
В экспериментах сравнивалась производительность TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA и случайного поиска (RS) в рамках бенчмарка MoRobtrol. Результаты показывают, что TensorRVEA достиг наилучшей общей производительности, получив самые высокие значения HV и продемонстрировав хорошее разнообразие решений в различных средах. TensorMOEA/D проявил сильную адаптивность в крупномасштабных задачах, особенно преуспев в согласованности предпочтений решений. TensorNSGA-III и TensorHypE показали схожую производительность и были конкурентоспособны в нескольких задачах. В целом, тензоризованные алгоритмы на основе декомпозиции продемонстрировали превосходные преимущества в решении крупномасштабных и сложных задач.
Заключение и будущая работа
В данном исследовании предлагается методология тензоризованного представления для решения ограничений традиционных алгоритмов EMO на базе CPU в плане вычислительной эффективности и масштабируемости. Подход был применен к нескольким репрезентативным алгоритмам, включая NSGA-III, MOEA/D и HypE, что позволило добиться значительного повышения производительности на GPU при сохранении качества решений. Чтобы подтвердить его практическую применимость, команда также разработала MoRobtrol — набор бенчмарков для многокритериального управления роботами, который переформулирует задачи управления роботами в средах физического моделирования как задачи многокритериальной оптимизации. Результаты демонстрируют потенциал тензоризованных алгоритмов в вычислительно емких сценариях, таких как воплощенный интеллект (embodied intelligence). Хотя метод тензоризации существенно повысил эффективность алгоритмов, все еще остается пространство для дальнейшего совершенствования. Будущие направления включают улучшение основных операторов, таких как недоминируемая сортировка, разработку новых тензоризованных операций для систем с несколькими GPU, а также интеграцию крупномасштабных данных и методов глубокого обучения для дальнейшего повышения производительности в задачах крупномасштабной оптимизации.
Исходный код / Ресурсы сообщества
Статья:
https://arxiv.org/abs/2503.20286
GitHub:
https://github.com/EMI-Group/evomo
Основной проект (EvoX):
https://github.com/EMI-Group/evox
Группа QQ: 297969717

EvoMO построен на базе фреймворка EvoX. Если вы хотите узнать больше об EvoX, ознакомьтесь с официальной статьей об EvoX 1.0, опубликованной в нашем публичном аккаунте WeChat, для получения более подробной информации.
