
A programação genética é um método evolutivo que combina pesquisa estrutural com interpretabilidade. Oferece vantagens únicas em tarefas como regressão simbólica, classificação e controlo — não só optimiza parâmetros, como também procura e produz directamente expressões de programa analisáveis. No entanto, devido à heterogeneidade das estruturas individuais e aos caminhos de execução irregulares, a maior parte das implementações existentes de programação genética permanece confinada à execução em CPU e há muito que não consegue adaptar-se verdadeiramente às GPU. Isto limita directamente a eficiência computacional e dificulta o tratamento de conjuntos de dados massivos ou ambientes de simulação complexos nas aplicações modernas.
Para responder a este desafio, propomos a framework EvoGP, reorganizando desde a base a representação em árvore, a lógica dos operadores genéticos e os mecanismos de execução paralela. Os resultados experimentais mostram que o EvoGP atinge um débito computacional de pico superior a 10^11 GPops/s, permitindo avaliar rapidamente populações de 500 000 indivíduos em menos de um segundo — até 304× mais rápido do que as implementações GPU existentes. Este marco assinala uma rutura definitiva com as barreiras de adaptação ao hardware, conduzindo a programação genética para a era da computação de alto desempenho acelerada por GPU.
O desafio da adaptação à GPU na programação genética
Nos últimos anos, as GPU tornaram-se uma infraestrutura crítica para a computação inteligente de alto desempenho, graças ao seu paralelismo massivo e elevado débito. Contudo, a programação genética tem falhado consistentemente em tirar pleno partido desta vantagem de hardware. O obstáculo central reside na ausência de métodos de representação e execução alinhados com as arquitecturas de hardware modernas. O modelo de execução Single Instruction, Multiple Threads (SIMT) da GPU destaca-se no processamento de dados regulares, uniformes e agrupáveis em lotes. Os indivíduos de programação genética, por contraste, apresentam heterogeneidade estrutural significativa — tamanhos de árvore, topologias e lógica de avaliação variáveis. Uma vez colocados numa GPU, estas estruturas expõem de imediato problemas como acesso à memória não contíguo, alocação dinâmica de memória ineficiente e divergência severa de threads.
Ao mesmo tempo, para libertar verdadeiramente a potência de computação da GPU, um sistema tem de lidar tanto com o paralelismo ao nível dos dados dentro de cada árvore individual como com o paralelismo ao nível dos indivíduos na população. Unificar estes dois modos numa única estratégia de escalonamento, optimizar o layout de memória e evitar contenção de recursos constitui um desafio de engenharia de sistemas considerável. Muitas implementações anteriores, devido a falhas de desenho fundamentais, exploraram apenas o paralelismo ao nível dos dados, deixando grande parte da capacidade concorrente da GPU ociosa. O EvoGP aborda esta questão de raiz: em vez de forçar a programação genética a correr a custo na GPU, disponibiliza uma arquitectura de base concebida para o efeito, tornando a programação genética uma framework de computação verdadeiramente preparada para a era da GPU.
Representação tensorizada de estruturas em árvore
Para levar a programação genética à era da GPU, a primeira tarefa é eliminar a barreira da heterogeneidade das estruturas individuais. As estruturas em árvore tradicionais baseadas em ponteiros ou listas ligadas produzem layouts de memória altamente irregulares que bloqueiam por completo a execução em lote na GPU. Para tal, o EvoGP introduz uma representação tensorizada inovadora, utilizando um esquema de codificação por prefixo linear para codificar estruturas em árvore como arrays contíguos que contêm tipos de nó, valores de nó e tamanhos de subárvore.
Para lidar com árvores de tamanhos variáveis, o EvoGP introduz uma restrição de comprimento máximo permitido e utiliza valores NaN para preenchimento e alinhamento. Através desta conversão, o EvoGP transforma com sucesso indivíduos morfologicamente diversos numa população em matrizes tensoriais de forma fixa e alinhadas em memória. Esta tensorização elimina a sobrecarga de alocação dinâmica de memória e de indexação irregular, garantindo que a GPU pode realizar acesso uniforme à memória e computação concorrente de elevado débito — formando a base para a entrada de toda a framework na era da GPU.
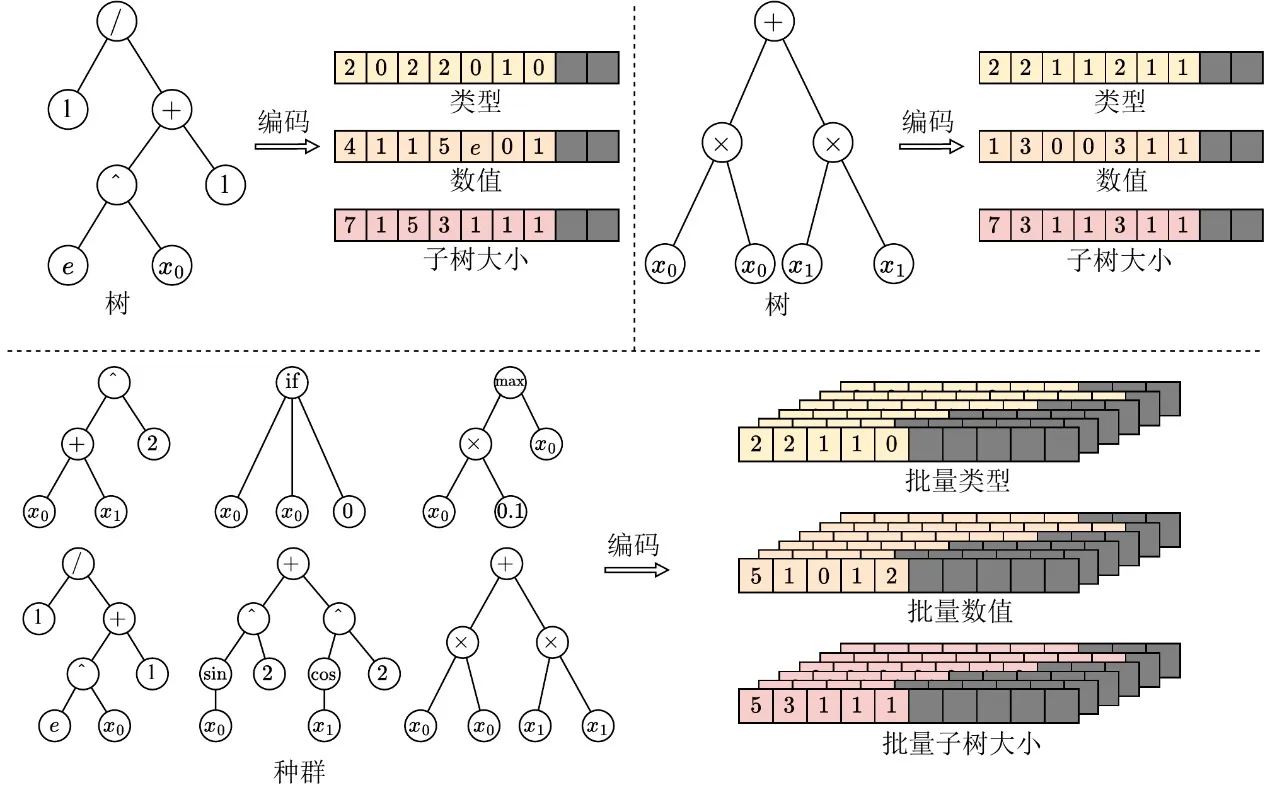
Figura 1: Representação tensorizada de estruturas em árvore. O EvoGP codifica árvores numa representação em lote unificada, permitindo que a GPU processe de forma eficiente indivíduos de programa com estruturas diversas.
Refactorização unificada dos operadores genéticos
Após concluir a representação tensorizada das estruturas em árvore, o EvoGP refactoriza ainda mais os operadores genéticos para se alinharem com a arquitectura GPU ao nível mais baixo. Nas representações em árvore tradicionais, modificações estruturais como crossover ou mutação exigem tipicamente análise repetida de sequências para determinar limites de subárvore, com complexidade temporal O(n), tornando a execução na GPU altamente ineficiente. Graças aos arrays de tamanho de subárvore explicitamente preservados na codificação tensorizada, o sistema pode agora aceder directamente aos limites das subárvores em tempo O(1), eliminando por completo a dispendiosa análise estrutural.
Com base nesta vantagem, o EvoGP extrai as semelhanças estruturais de vários operadores genéticos baseados em árvore — como crossover de um ponto e mutação de subárvore — e unifica-os num único primitivo computacional: troca de subárvore. Isto transforma a evolução estrutural complexa em operações altamente regulares de fatiamento de memória e concatenação de tensores. Esta refactorização reduz significativamente a sobrecarga de fluxo de controlo durante a execução paralela, tornando o processo evolutivo central da programação genética uma forma de computação bem adaptada ao hardware moderno de elevado débito.
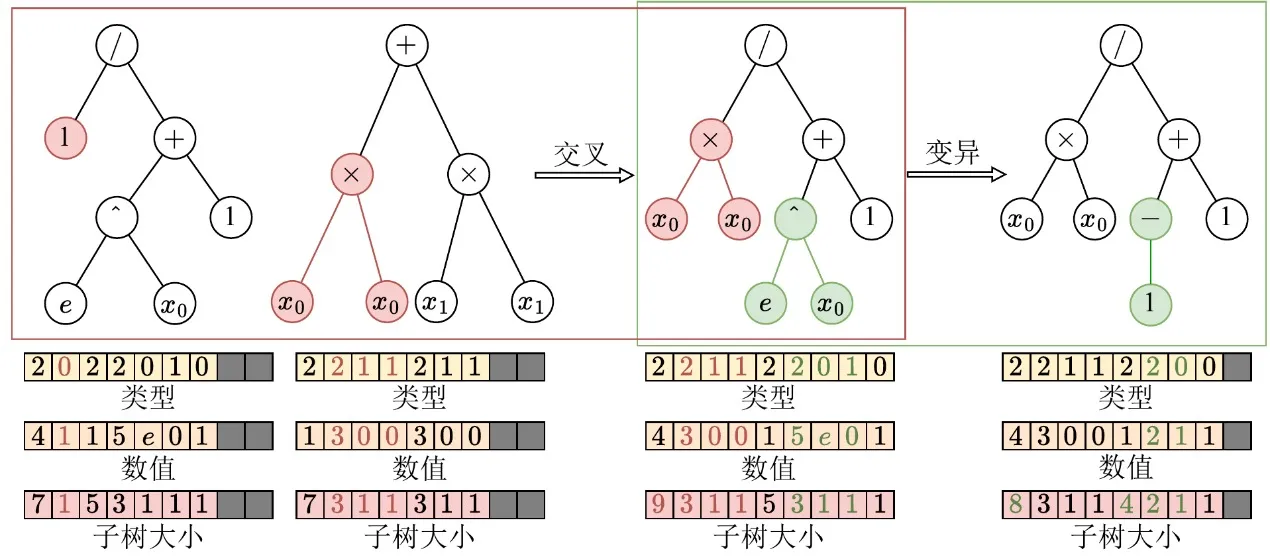
Figura 2: Operações unificadas de crossover/mutação. O EvoGP unifica vários operadores genéticos baseados em árvore num único mecanismo subjacente, tornando o processo evolutivo central mais adequado à execução paralela na GPU.
Comutação adaptativa de estratégias paralelas
Para prosperar na era da GPU, um algoritmo tem de ser capaz de extrair a máxima potência de computação do hardware. As escalas de dados variam drasticamente entre tarefas, e uma única estratégia paralela não consegue manter utilização estável do dispositivo. Para tal, o EvoGP concebe e implementa uma estratégia paralela adaptativa que combina dinamicamente paralelismo intra-indivíduo e inter-indivíduo consoante o tamanho do conjunto de dados.
Ao processar conjuntos de dados de pequena a média dimensão, o sistema adopta um modo paralelo híbrido, combinando paralelismo ao nível dos dados e ao nível da população num único kernel de computação — garantindo que, quando a carga de trabalho por indivíduo é insuficiente, a concorrência ao nível da população preenche os núcleos GPU ociosos. Para conjuntos de dados em grande escala, uma única tarefa de avaliação pode saturar o hardware, e o sistema comuta automaticamente para modo puramente paralelo ao nível dos dados, lançando kernels de computação independentes para a avaliação de cada indivíduo e carregando estruturas em árvore na memória constante só de leitura — maximizando a eficiência de broadcast de memória e melhorando significativamente o débito de acesso à memória. Este mecanismo adaptativo garante que o sistema mantém eficiência computacional extremamente elevada em cargas de trabalho diversas, servindo de garantia central da framework de aceleração GPU.
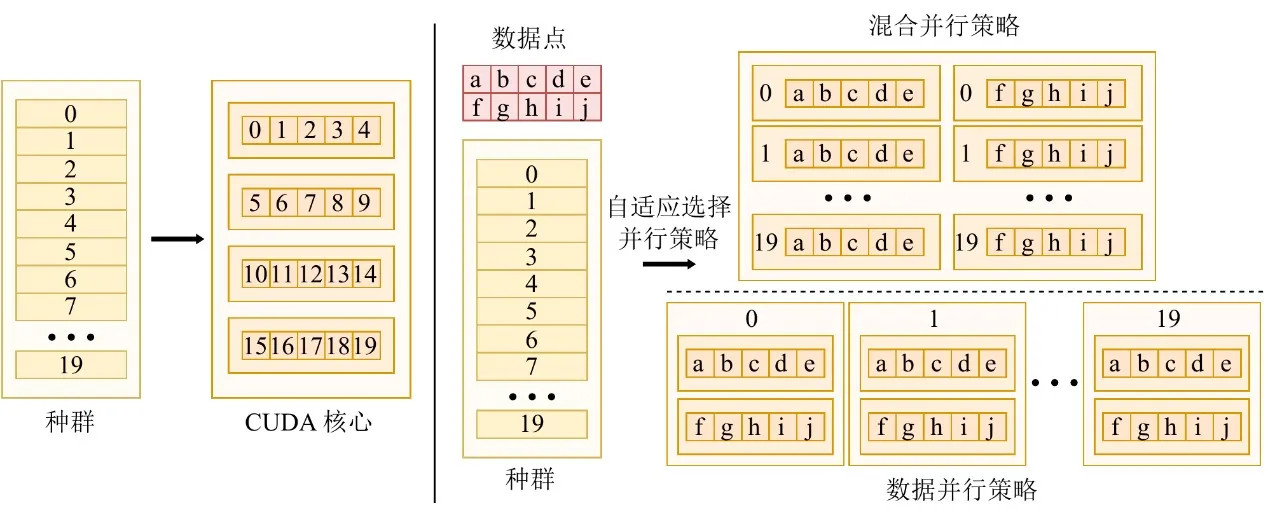
Figura 3: Mecanismo paralelo adaptativo. O EvoGP comuta automaticamente entre diferentes modos paralelos consoante a escala da tarefa para manter maior eficiência computacional.
Unificar alto desempenho e usabilidade
A vitalidade de uma framework de computação de alto desempenho reside não só na velocidade subjacente, mas também na compatibilidade com o ecossistema e na facilidade de utilização. Muitas aplicações práticas são implementadas em ecossistemas baseados em Python, como OpenAI Gym, MuJoCo, Brax e Genesis. Ao perseguir aceleração GPU extrema, o EvoGP alcança integração transparente com os ecossistemas de desenvolvimento existentes, incorporando kernels CUDA de alto desempenho personalizados como operadores personalizados no runtime PyTorch.
Além disso, para tirar pleno partido das vantagens da arquitectura GPU, o EvoGP adopta um modelo totalmente residente na GPU, garantindo que os dados da população e os contextos de avaliação permanecem inteiramente na GPU — eliminando por completo a dispendiosa sobrecarga de transferência de dados entre host e dispositivo comum nas frameworks tradicionais. Esta filosofia de desenho zero-copy permite que o EvoGP se integre de forma natural e eficiente com ambientes modernos de reinforcement learning acelerados por GPU, fornecendo capacidades de simulação paralela eficientes de ponta a ponta como um sistema completo que equilibra desempenho extremo com elevada escalabilidade.
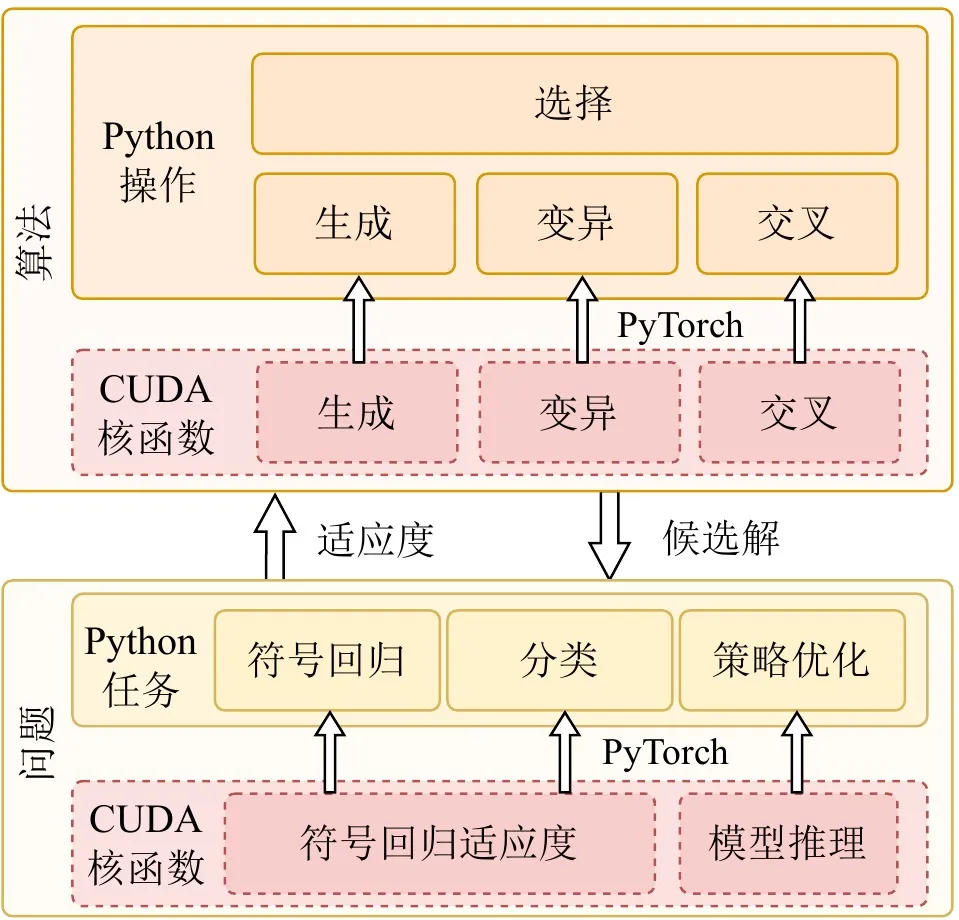
Figura 4: Arquitectura global. O EvoGP não é um módulo de aceleração isolado, mas uma framework completa que equilibra desempenho subjacente com usabilidade na camada superior.
Desbloquear desempenho em escalas de população elevadas
Ultrapassar os estrangulamentos de computação expande directamente os limites de pesquisa dos algoritmos evolutivos, permitindo que a programação genética beneficie verdadeiramente da era da GPU. No passado, configurações de população ultra-elevadas eram frequentemente impraticáveis devido aos custos computacionais proibitivos. Com o mecanismo de paralelismo ao nível da população de débito extremamente elevado do EvoGP, processar um número massivo de indivíduos tornou-se genuinamente viável na prática.
Os testes de referência centrais mostram que o débito de pico do EvoGP excede 10^11 GPops/s, demonstrando velocidade surpreendente sob concorrência massiva — concluindo a avaliação abrangente de populações até 500 000 indivíduos em apenas um segundo. Em tempo de execução, estabelece uma vantagem decisiva face às implementações GPU existentes. Mais criticamente, em testes de população em grande escala, o algoritmo exibe excelente escalabilidade: na convergência de erro em regressão simbólica, na melhoria de precisão em classificação e nas recompensas acumuladas em tarefas de controlo robótico, populações maiores produzem consistentemente melhor desempenho final. Isto prova que o EvoGP liberta não só velocidade computacional — permite que populações maiores atinjam soluções de maior qualidade em menos tempo de relógio, elevando fundamentalmente o potencial de pesquisa e o tecto de capacidade dos métodos de programação genética.
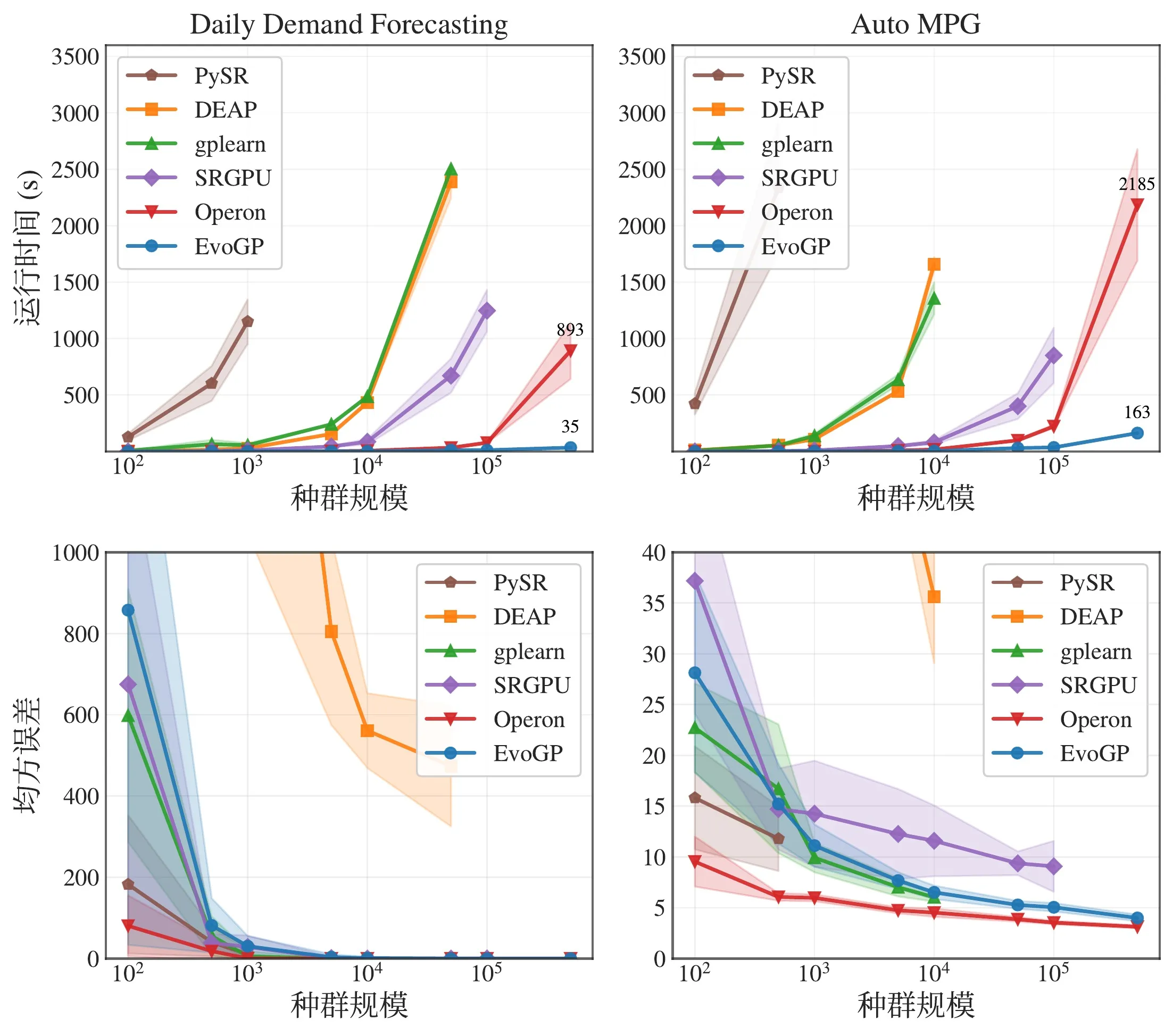
Figura 5: Comparação global de desempenho. O EvoGP alcança vantagens de desempenho significativas em múltiplas configurações de tarefas, mantendo qualidade de resultados estável.
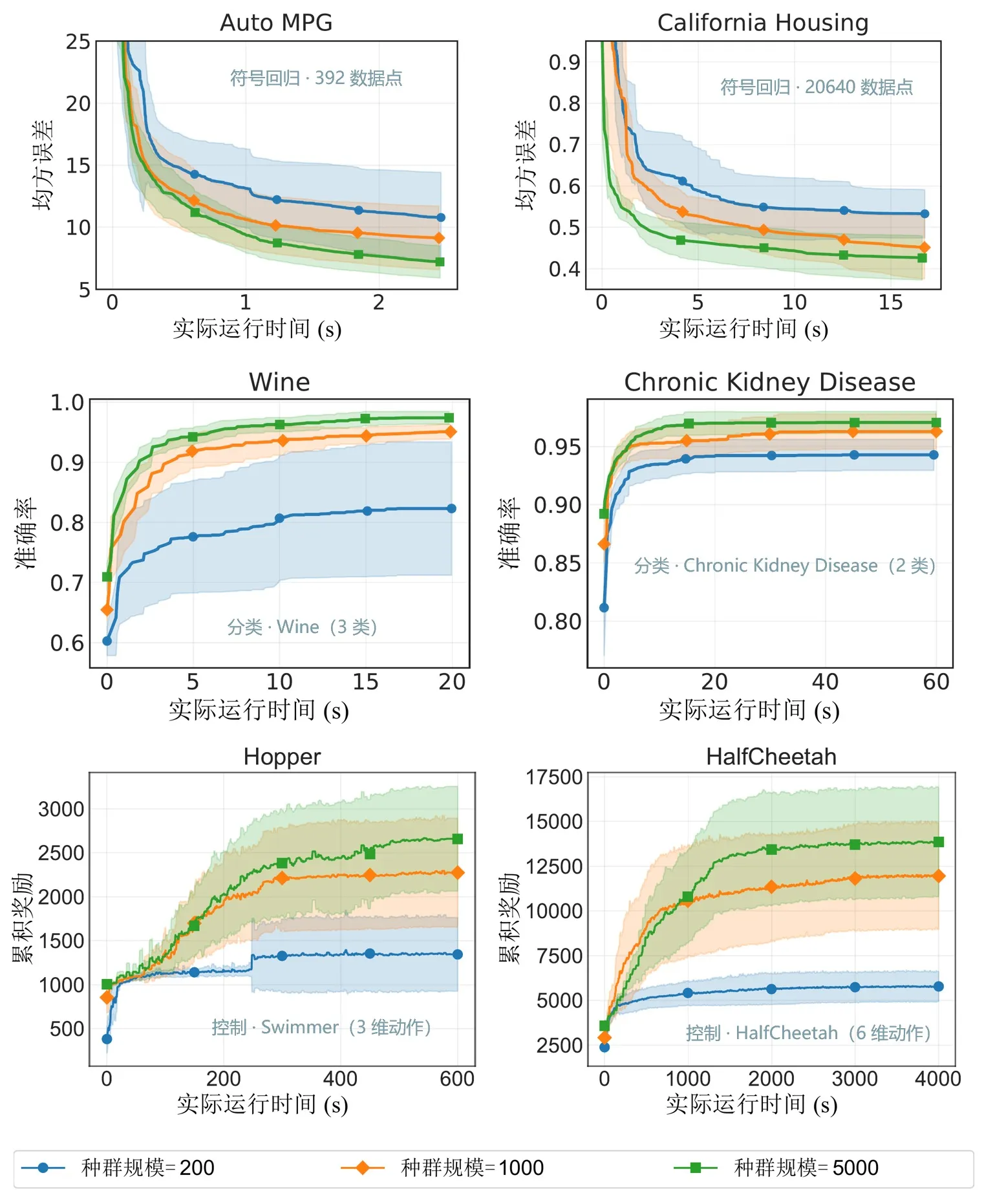
Figura 6: Desempenho em diferentes escalas de população. O EvoGP torna tamanhos de população maiores praticamente utilizáveis em tempo aceitável e desbloqueia maior potencial de pesquisa.
Conclusão
A framework EvoGP responde de forma sistemática à questão de como a programação genética pode utilizar eficazmente arquitecturas GPU modernas. Não é um simples remendo às implementações existentes, mas alcança inovações fundamentais no desenho subjacente através de representação tensorizada, refactorização de operadores e paralelismo adaptativo — abrindo por completo o caminho para a programação genética entrar em sistemas de computação de alto desempenho. Este trabalho não só demonstra a vitalidade duradoura dos métodos evolutivos clássicos na era da computação, como também fornece uma solução ao nível de sistema altamente escalável para machine learning interpretável e tomada de decisão de agentes autónomos — marcando a verdadeira entrada da programação genética na era acelerada por GPU.
Código aberto / Comunidade
📄 Artigo:
https://ieeexplore.ieee.org/document/11390710
🔗 GitHub:
https://github.com/EMI-Group/evogp
🔼 Projeto upstream (EvoX):
https://github.com/EMI-Group/evox
🌐 Grupo QQ: 297969717

Grupo QQ | Evolutionary Machine Intelligence