ICML 2026 | EvoGM: Autonomous LLM Merging via Population Evolution Without Retraining

Abstract
As large language models grow more capable, an increasing number of expert models fine-tuned for different tasks are becoming available. A central challenge in model merging is how to efficiently reuse the capabilities of these expert models without retraining the participating large models or relying on additional large-scale training data. Existing methods typically depend on average merging, manual scaling, parameter pruning, or random search. While these approaches can combine multiple models to some extent, they struggle to continuously learn from historical evaluations and improve merging strategies over time.
To address this problem, the EvoX team, in collaboration with Peng Cheng Laboratory, proposes EvoGM (Evolutionary Generative Merging), a generative evolutionary model merging framework that reformulates coefficient search as a learnable generative optimization problem. EvoGM organizes different merging configurations into a candidate population and, through winner–loser pairing, dual-generator training, cycle-consistency constraints, and evolutionary expert-base updates, enables the population to evolve continuously in a closed loop of “generate–evaluate–select–relearn.” From limited validation feedback, it autonomously learns how to transform low-performing configurations into high-performing ones. Experimental results show that EvoGM delivers stronger model merging performance on both seen and unseen tasks.
I. Why Do We Need Model Merging?
In recent years, large language models have grown increasingly capable, but the cost of training and fine-tuning has also risen. A natural question arises: if we already have multiple expert models that perform well on different tasks, can we combine their capabilities into a stronger, more general model without retraining those large models?
This is precisely the problem that model merging aims to solve.
The core idea of model merging is straightforward: multiple expert models often share the same base model and differ only in the data or tasks used for fine-tuning. Each expert model’s parameter changes relative to the base model can therefore be viewed as a “capability direction,” and new merged models can be constructed by weighted combinations of these directions. The advantage is that there is no need to retrain or fine-tune the participating large models, nor to rely on additional large-scale training data—only to search for appropriate merging coefficients. It is worth noting that EvoGM trains lightweight generators to search for coefficients but does not update the parameters of the expert large models.
II. What Makes Model Merging Truly Difficult?
The real difficulty lies here: how should these coefficients be chosen?
Model merging may appear to be a simple weighted combination of multiple expert models, but the relationships among their capabilities are far from simple. Some task directions are complementary, while some parameter updates may conflict with one another. A set of merging coefficients that performs well on one class of tasks may cause performance loss on another. The relationship between merging coefficients and final model performance is therefore not an easily hand-crafted linear mapping.
Traditional methods typically rely on heuristic rules such as average merging, manual scaling, parameter pruning, or sparsification. These methods are simple and effective, but they also have clear limitations: they tend to be static and empirical, making it difficult to adaptively adjust based on validation feedback for different tasks.
Later, evolutionary search methods were introduced into model merging, organizing candidate merging configurations into a population and searching for better coefficients through random perturbation, fitness evaluation, and selection. These methods are more flexible than fixed rules, but a key problem remains: validation results are usually used only for ranking and filtering, rather than being further converted into learnable search experience. In other words, the algorithm knows “which candidate model is better,” but does not truly learn “how a weaker candidate model should be improved.”
This is the core problem EvoGM seeks to address: model merging should not merely involve continuous trial-and-error and filtering within a candidate population—it should learn improvement directions from historical evaluations and autonomously generate more promising merging configurations.
III. EvoGM: Letting Merging Strategies Learn Autonomously Through Population Evolution
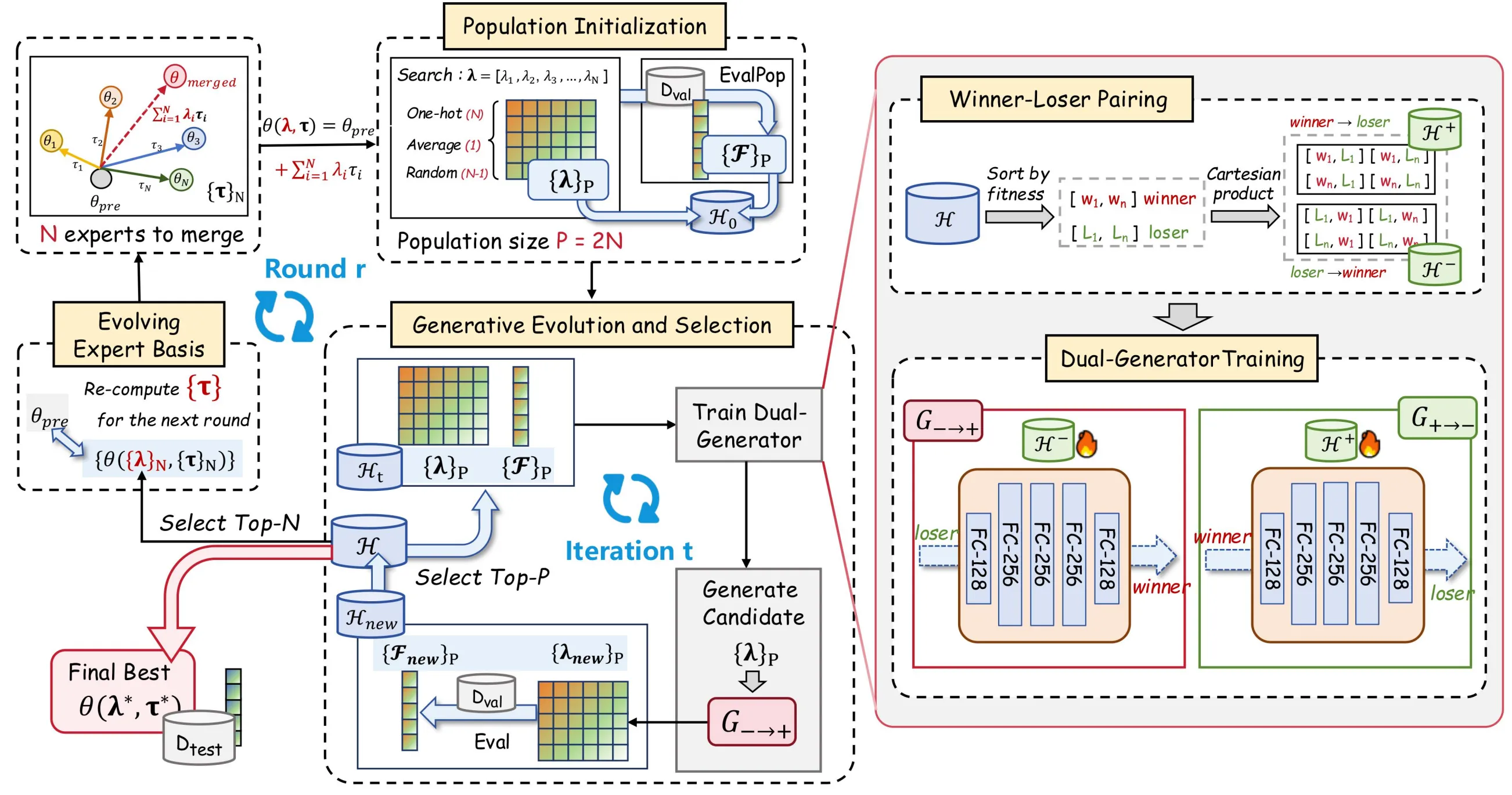
To address the above challenges, we propose EvoGM (Evolutionary Generative Merging). The code is open source: https://github.com/JiangTao97/evogm.
The core idea of EvoGM is to organize candidate merging configurations as a population and reformulate the search for merging coefficients as a generative learning problem.
The key insight is that the generative model does not directly learn “what the optimal merging coefficients are,” but rather “how to transform weaker configurations into stronger ones.” In model merging, different configurations are often difficult to rank reliably on a global scale; by contrast, pairwise comparisons provide more stable superiority signals.
EvoGM uses historical validation results to construct winner–loser pairing data, enabling the generator to learn improvement directions from loser to winner. For each pair of candidate merging configurations, the algorithm records not only their corresponding performance differences but also converts this “from worse to better” relationship into training samples. Through continuous accumulation and learning, the generator gradually captures which coefficient adjustments are more likely to yield performance gains, forming an implicit understanding of the search space structure. In other words, it learns not the excellent solutions themselves, but the patterns of performance improvement.
This approach is aligned with competitive learning mechanisms in evolutionary optimization. It can be traced back to CSO (Competitive Swarm Optimizer), which drives individual updates through winner–loser competition, moving weaker individuals toward stronger ones; EvoGO (Evolutionary Generative Optimization) further uses generative models to learn improvement directions from historical search data, replacing some manually designed search operators with a data-driven approach. EvoGM brings this idea into the model merging setting, training generators through validation feedback to guide subsequent search. As a result, validation results are no longer used only for filtering and eliminating candidate solutions—they are continuously converted into reusable search experience, allowing the search process to accumulate knowledge and improve efficiency over iterations.
IV. How Does EvoGM Work?
The overall workflow of EvoGM can be divided into five steps: constructing candidate configurations, forming winner–loser training pairs, training generators, generating and selecting new coefficients, and updating the expert base. Given expert models and validation tasks, these steps can be executed automatically in a loop without manually designing merging rules or tuning coefficients round by round.
- Population initialization: building candidate merging configurations
EvoGM first constructs a batch of initial candidate solutions. Each candidate corresponds to a set of merging coefficients—that is, a different way of combining multiple expert models.
Specifically, the initial population typically includes several types of configurations: coefficients corresponding to average merging, one-hot coefficients corresponding to individual expert models, and randomly sampled merging coefficients. This covers common baseline merging methods while providing sufficient diversity for subsequent search.
For each set of candidate coefficients, EvoGM constructs a merged model and evaluates its performance on the validation set. After this step, the algorithm obtains not just several candidate models, but a batch of historical records of “merging coefficients–validation performance.” All subsequent generative learning and evolutionary selection are built on these records.
- Winner–loser pairing: converting validation results into training data
After obtaining candidate solutions and their validation performance, EvoGM partitions historical candidate configurations into winners and losers based on performance. Winners represent relatively better merging configurations; losers represent relatively weaker ones.
The key here is not simply keeping high-scoring configurations and discarding low-scoring ones, but pairing them into training pairs. For the generator, each winner–loser pair provides useful information: starting from a weaker configuration, which stronger configuration should it move toward?
Low-performing candidates are therefore not useless samples. On the contrary, they provide “starting points” in the search process, while high-performing candidates provide “improvement directions.” Through this pairing strategy, EvoGM converts limited validation evaluation results into more learnable supervisory signals, improving data utilization efficiency under small-sample feedback.
- Dual-generator training: learning transformations from weak to strong configurations
After constructing winner–loser training pairs, EvoGM uses a dual-generator architecture for training.
The forward generator learns the mapping from loser to winner—that is, transforming low-performing merging configurations into more promising high-performing ones. The backward generator learns the reverse mapping from winner back to loser, constraining the structural consistency of the generation process.
The purpose of this design is not to let the generator simply memorize existing high-scoring configurations, but to learn the patterns of improvement within the merging coefficient space. Through cycle-consistency constraints, EvoGM reduces the risk of the generator collapsing to a few high-scoring points, ensuring that generated candidate configurations move toward high-performance regions while preserving structural information in the search space.
- Generative evolution and selection: replacing random perturbation with learned operators
After generator training is complete, EvoGM uses the forward generator to transform current candidate configurations and generate a batch of new merging coefficients. This step corresponds to “producing new individuals” in traditional evolutionary algorithms, but new individuals no longer come mainly from random perturbation—they come from improvement directions learned by the generative model.
These newly generated merging coefficients are then used to construct new merged models and evaluated again on the validation set. The evaluation results are added to the historical records and participate in selection together with existing candidates.
Through this loop, EvoGM undergoes a “generate–evaluate–select–relearn” process in each round. This closed loop constitutes population evolution of candidate merging configurations: historical validation results accumulate continuously, and the generator continuously receives new training signals, progressively improving its ability to autonomously generate high-quality merging configurations.
- Evolutionary expert base: continuously updating the search space
Beyond optimizing merging coefficients, EvoGM further introduces an evolutionary expert-base mechanism.
Traditional model merging typically treats expert models as fixed inputs, searching only for merging coefficients among fixed expert models. EvoGM differs: after each round, the best-performing merged models are selected to serve as the new expert base for the next round of search.
The significance of this approach is that excellent merged models already contain certain effective capability combinations. By incorporating them into the new expert base, subsequent search is no longer limited to linear combinations among the original expert models—it can continue evolving on intermediate models that have already been validated as effective.
EvoGM’s search space is therefore not fixed, but updates continuously as the search progresses. It not only seeks better merging coefficients, but also progressively constructs an expert representation basis better suited to the current task.
V. What Are the Key Advantages of EvoGM?
Compared with traditional model merging methods, EvoGM’s advantages are mainly reflected in three aspects.
First, EvoGM advances model merging from static heuristic rules to feedback-driven autonomous search. Traditional methods often rely on average merging, manual scaling, or random perturbation, while EvoGM can continuously adjust search directions based on historical validation results, freeing the merging process from manually designed rules and coefficient tuning round by round.
Second, EvoGM improves data utilization efficiency under a limited evaluation budget. In model merging, each candidate configuration evaluation requires actually constructing a merged model and running validation tasks, which is not inexpensive. EvoGM further converts these evaluation results into learnable training signals, so that every trial provides information for subsequent search.
Finally, EvoGM does not merely search for a better set of merging coefficients—it also progressively learns the patterns of capability combination among expert models. Through generative search of the candidate population and expert-base updates, it can continuously recombine and expand the search space on top of existing expert models, more effectively discovering high-performance merged models autonomously.
VI. Experimental Results: Does EvoGM Really Work?
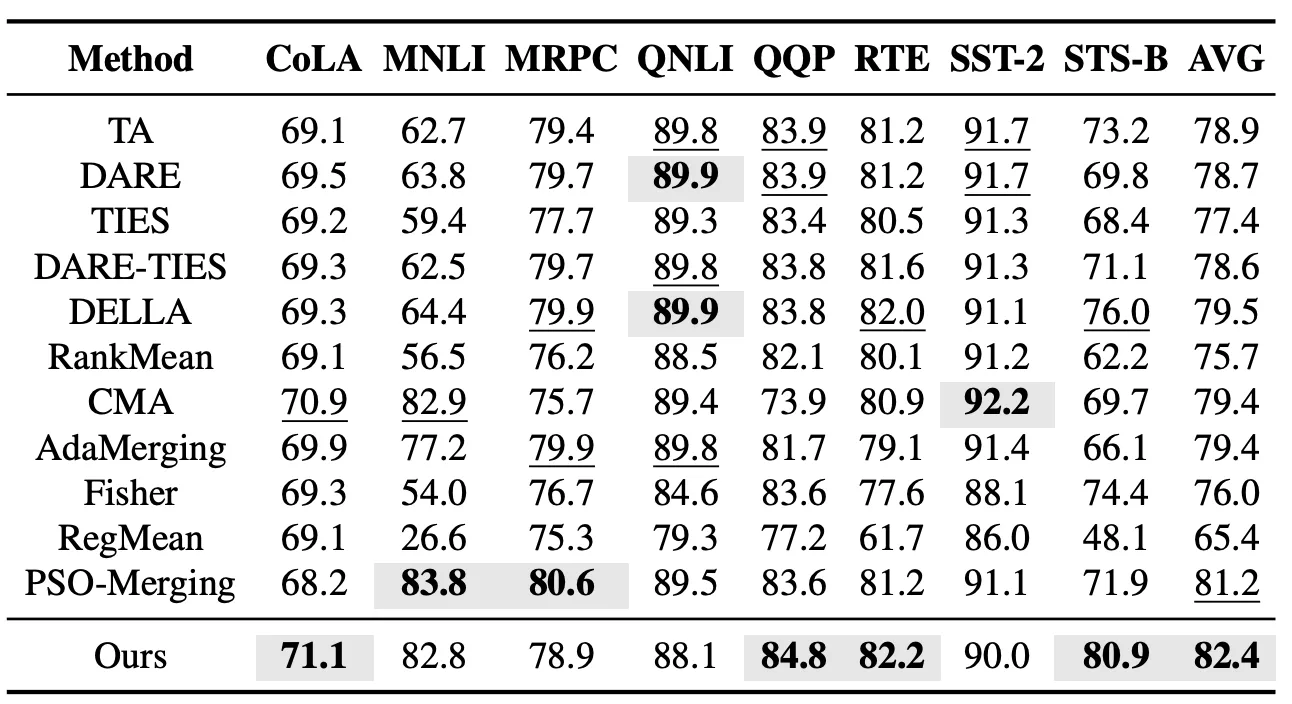
In the seen-task setting, we first evaluate EvoGM’s model merging performance on the GLUE benchmark suite. This experiment covers 8 language understanding tasks—CoLA, MNLI, MRPC, QNLI, QQP, RTE, SST-2, and STS-B—and compares against representative model merging methods including Task Arithmetic, TIES, DARE-TIES, DELLA, RankMean, CMA, AdaMerging, and PSO-Merging. Results show that EvoGM achieves higher average performance across all 8 tasks than the previously best-performing PSO-Merging.
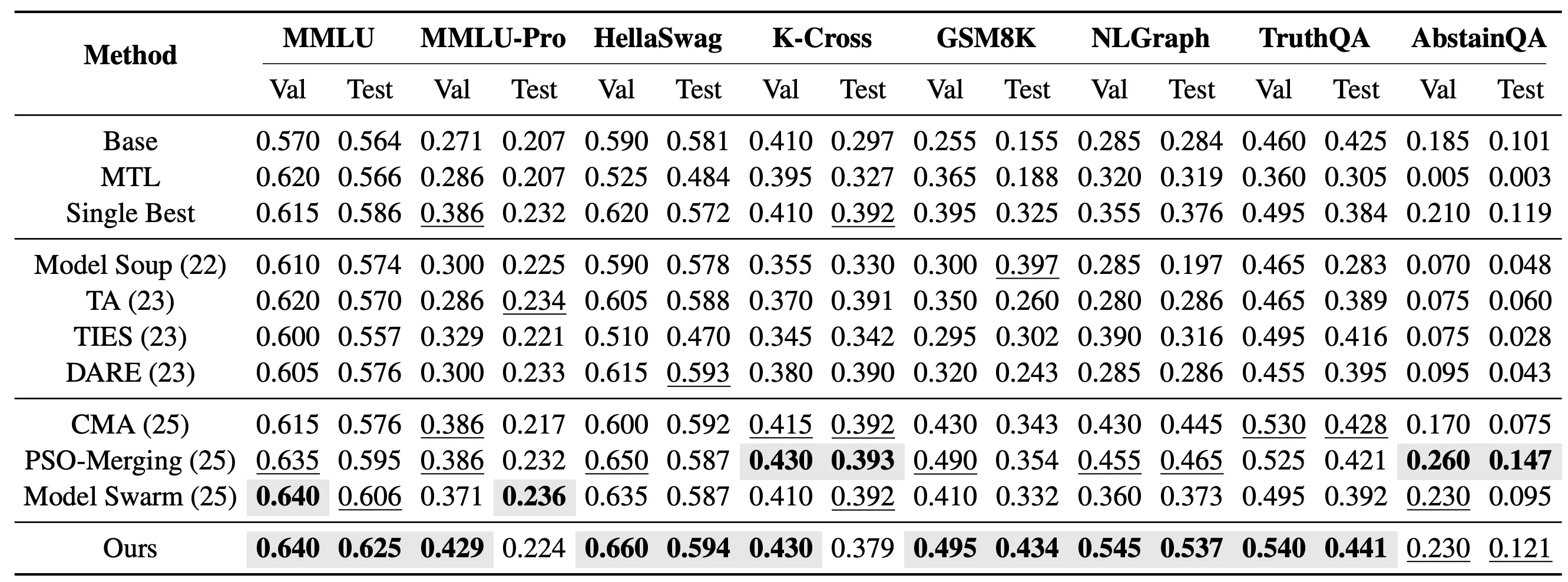
In the more challenging unseen-task setting, we further evaluate whether EvoGM can transfer the capabilities of existing expert models to new tasks that were not involved in expert fine-tuning. Specifically, we merge 10 LoRA expert models based on Qwen2.5-1.5B and test on 8 unseen tasks: MMLU, MMLU-Pro, HellaSwag, Knowledge Crosswords, GSM8K, NLGraph, TruthfulQA, and AbstainQA. These tasks span different capability dimensions including knowledge understanding, complex reasoning, and safety reliability, making them better indicators of model merging generalization than seen tasks.
In the single-task unseen merging setting, EvoGM searches for a separate set of merging coefficients for each target task. Results show that EvoGM achieves the highest test performance on 5 out of 8 test tasks.
Beyond single-task merging, we further examine the multi-task unseen merging setting. In this setting, the goal is no longer to find the optimal model for each task individually, but to obtain a unified merged model that simultaneously covers all 8 unseen tasks. Results show that in multi-task unseen merging, EvoGM achieves the highest average test performance among all merging methods.
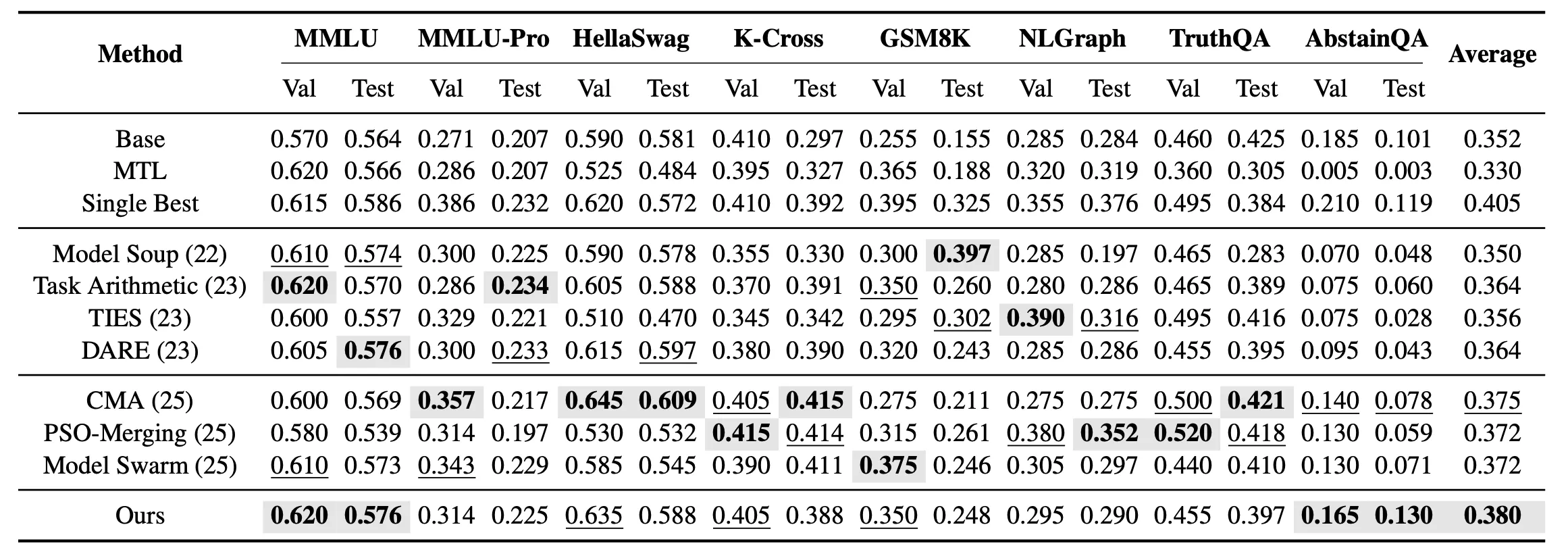
Results demonstrate that EvoGM achieves stronger overall generalization in both single-task and multi-task settings, outperforming existing model merging methods on multiple knowledge, reasoning, and safety-related tasks.
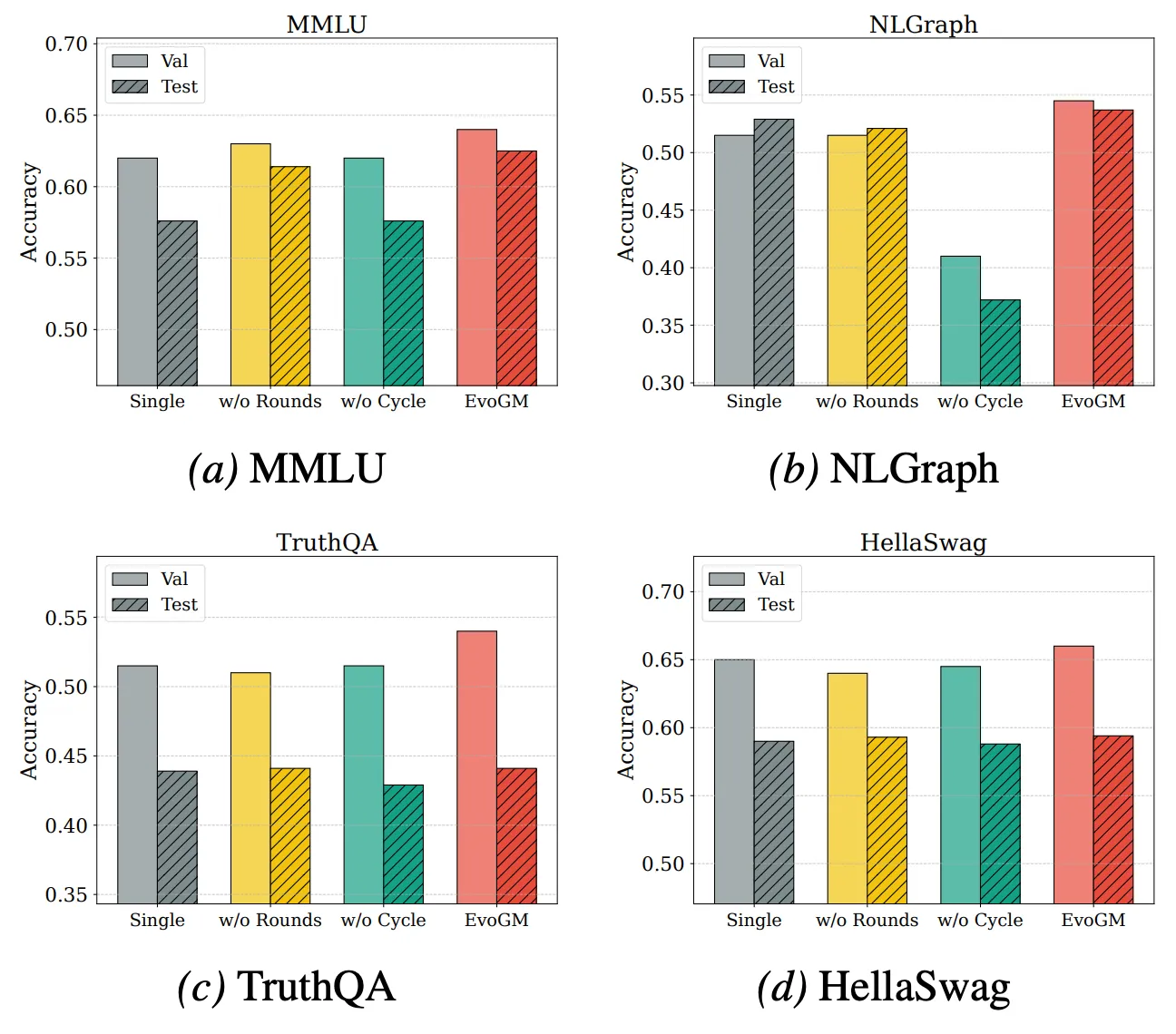
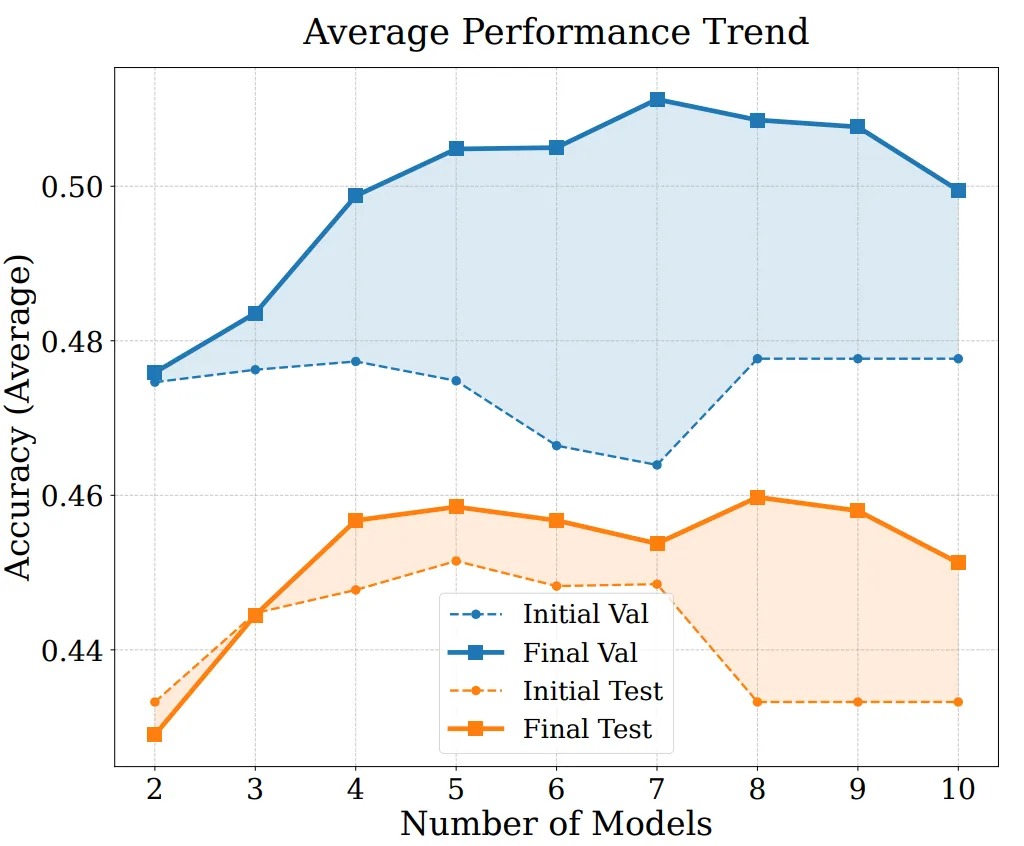
To further analyze the sources of EvoGM’s performance and its scalability, we conduct ablation studies and merging experiments with varying numbers of models. Results show that the full EvoGM consistently achieves the best or most stable performance, while removing key components leads to varying degrees of performance degradation—indicating that its advantages stem primarily from the generative evolutionary mechanism rather than simple random search or more search rounds. Meanwhile, as the number of participating expert models increases, EvoGM maintains strong performance and exhibits a stable upward trend, demonstrating its ability to handle larger-scale, more complex merging spaces, fully leverage complementary capabilities among different expert models, and scale effectively.
VII. From EvoGO to EvoGM: Extending Generative Evolutionary Ideas
From a broader perspective, EvoGM can be understood as an extension of EvoGO ideas into large model merging. EvoGO focuses on how evolutionary optimization can shift from relying on manually designed crossover, mutation, and perturbation operators to having generative models automatically learn how to generate new solutions from historical search data. In other words, evolutionary search no longer merely “randomly generates candidate solutions and filters them”—it begins to learn “how to generate more promising candidate solutions.”
EvoGM applies this idea to the large model merging setting. Here, candidate solutions are no longer numerical variables in a general optimization problem, but sets of merging coefficients; an evaluation is no longer a simple objective function computation, but constructing a merged model and validating its performance on downstream tasks. EvoGM therefore effectively reformulates model merging as a generative optimization problem: how to learn the patterns of capability combination among expert models from historical evaluation results and generate better merging configurations.
This distinction sets EvoGM apart from traditional search-based model merging. Traditional methods typically use validation results only for ranking and filtering, while EvoGM further converts validation results into training signals. Low-performing configurations are not simply discarded—they are paired with high-performing configurations as winner–loser pairs to train the generator to learn evolutionary directions from weak to strong configurations.
From EvoGO to EvoGM, the progression is essentially from “learning how to optimize candidate solutions” to “letting large model merging strategies evolve autonomously within a population.” This not only frees model merging from empirical rules and random perturbation, but also offers a new perspective: large model capabilities can be merged, and merging strategies themselves can continuously learn from population feedback.
VIII. Conclusion and Outlook
As expert models, LoRA models, and task-specific models proliferate in the open-source ecosystem, the key question of the future may no longer be “how to train a new model,” but “how to efficiently combine existing model capabilities.” EvoGM offers a new answer: without retraining the participating large models, it leverages generative evolutionary learning with limited validation feedback to autonomously complete candidate population construction, merging configuration generation, evaluation and selection, and expert-base updates. In short, EvoGM moves model merging from “tuning coefficients by experience” to “letting merging strategies learn and evolve on their own.” This also suggests that large model capability reuse may enter a new phase: rather than retraining a model for every new task, existing expert models can continuously combine into models better suited to new tasks through population evolution and autonomous merging.
Open Source / Community
📄 Paper: https://arxiv.org/pdf/2605.29295 🔗 GitHub:
https://github.com/JiangTao97/evogm 🔼 Upstream Project (EvoX):
https://github.com/EMI-Group/evox 🌐 QQ Group: 297969717
