EvoGO: GPUコンピューティング × 生成学習 → 10世代収束の進化計算の新パラダイム

近年、データ駆動型の進化最適化手法は目覚ましい進歩を遂げています。サロゲート支援進化計算から生成型進化計算まで、進化最適化は従来の固定オペレータ駆動のパラダイムから学習駆動のパラダイムへと徐々に移行しています。しかし、既存の手法のデータ駆動の性質は、3つの重要な点でまだ不完全です。第一に、生成メカニズムと進化プロセスの間の調整は、依然として手動で設計されたヒューリスティックなルールに依存することが多いです。第二に、生成モデルの学習目標は通常、汎用的な生成タスクから引き継がれており、最適化目標と十分に一致していません。第三に、ブラックボックス最適化で利用可能な、極めて限られているが価値の高いオンラインサンプルは、まだ学習可能で転移可能な最適化経験として体系的に整理されていません。これらの問題に対処するため、EvoX チームは進化的生成最適化(EvoGO)を提案しました。これは、最適化プロセス全体を「データ準備」「モデル学習」「集団生成」という3つの統一された段階に構成します。その目的は、最適化アルゴリズムが劣悪な解から優れた解へ移行するための改善法則を履歴データから直接学習できるようにすることです。実験結果によると、EvoGO は数値最適化、古典的制御、高次元ロボット制御の3つのタスクカテゴリ(25のベンチマークテスト、10次元から1000次元の問題規模をカバー)全体で安定した優位性を示し、ほとんどの大規模タスクで約10世代で収束しました。複雑なタスクでは、GPU並列推論と組み合わせることで、EvoGO は実用的な実行時間においても顕著な優位性を示します。CMA-ES が収束パフォーマンスに達したとき、EvoGO は最大134倍速く同じパフォーマンスを達成できます。これらの結果は、完全データ駆動型の進化最適化が、標準的なベンチマークテストで競争力のある結果を達成できるだけでなく、大規模な並列タスクでも実用的な優位性を示し始めていることを示しています。
課題:データ駆動型最適化はまだ最後の一歩を踏み出していない
近年、データ駆動型の進化最適化手法は急速に発展しています。サロゲート支援手法や生成モデルベースの手法により、進化最適化はすでに固定オペレータ駆動の探索から学習駆動の探索へと押し上げられています。これは、評価、モデリング、さらには生成を含むパイプラインの複数の段階に学習モデルが入り込み始めていることを意味します。
しかし、この変革はまだ不完全です。既存の手法は、異なるレベルで「評価」または「生成」する方法を学習しているかもしれませんが、「最適化」する方法を真に学習してはいません。一方で、次世代の候補解の生成は、依然として手動で設計されたヒューリスティックなルールによる調整に依存することが多いです。他方で、生成目標と最適化目標が十分に一致していないことがよくあります。同時に、ブラックボックス最適化で利用できる極めて限られたオンラインサンプルは、まだ学習可能で転移可能な最適化経験へと体系的に変換されていません。
したがって、現在本当に欠けているのは、単により多くのモデルではなく、最適化アルゴリズムが劣悪な解からより良い解へと向かうプロセスを履歴データから直接学習できるようにするという最後の一歩です。これこそが、EvoGO が推し進めようとしているステップです。
突破口:EvoGO はいかに最適化パイプラインを書き換えるか
上記の問題に対処するため、EvoGO は交叉や突然変異などの局所的オペレータを改善するという従来のルートをたどりません。代わりに、最適化パイプラインをより全体的なレベルで書き換えることを試みます。その核となるアイデアは、「次世代の候補解をどのように生成するか」というプロセスを手書きのルールから取り除き、それをデータ駆動型の生成メカニズムに学習させることです。具体的には、EvoGO は最適化プロセス全体をデータ準備、モデル学習、集団生成という3つの統一された段階に構成し、経験の整理、方向性学習、および集団の更新が分断されることなく、単一の最適化ループに統合されるようにします。
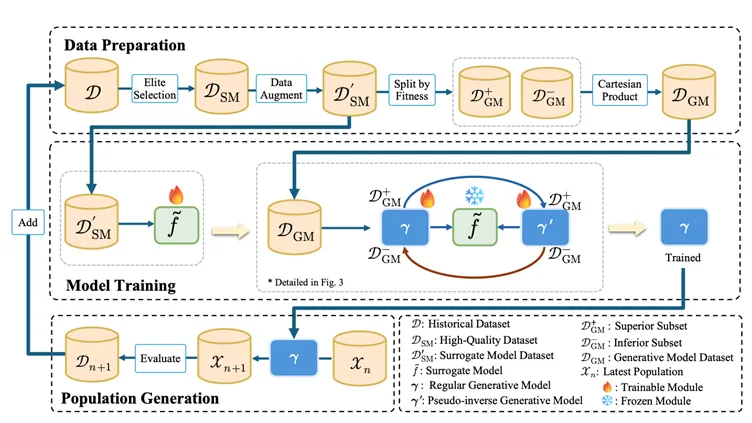
データ準備段階において、EvoGO はまず履歴集団から高品質なサンプルをフィルタリングし、より信頼性の高い学習基盤を構築します。サンプルが不足している場合は、学習されたデータ拡張を用いてデータ不足を緩和することもできます。さらに重要なことに、サンプルは優良解と劣悪解に分類され、ペアの関係として構成されます。結果として、モデルが学習するのはもはや候補解の静的な分布ではなく、劣悪な解から優れた解へ移行するという方向性を持った関係性です。
モデル学習段階では、EvoGO はサロゲートモデル、フォワード生成器、および擬似逆生成器からなるペア構造を採用しています。サロゲートモデルは目的関数の地形の近似表現を提供し、フォワード生成器は劣悪な解から優れた解へのマッピングを学習し、擬似逆生成器は再構成の一貫性制約によって学習の安定性を維持します。一般的な生成タスクとは異なり、ここでの学習目標は単にデータの分布に適合することではなく、目的関数の地形の導きの下で、生成プロセスがより良い領域に向かって進むことを確実にすることです。
集団生成段階では、学習済みの生成モデルが現在の集団に直接作用し、次世代の候補解を並列に生成します。これらの解は次に実際の目的関数によって評価され、集団の状態が更新されてから次の反復に入ります。この時点で、集団の更新が行われる方法が根本的に変わります。従来の進化最適化は、手動で指定された交叉、突然変異、および選択ルールに主に依存して探索空間を徐々に探っていましたが、EvoGO はこのプロセスを履歴データに駆動され生成モデルによって実装される並列更新メカニズムへと変えます。
EvoGO の並列性は2つのレベルで動作します。一方で、集団はテンソル化された形式で表現でき、個体の生成と評価を GPU 上で並列に実行できます。他方で、EvoGO は単一の GPU 上で複数の生成モデルを同時に実行することもでき、異なるランダムシードまたは異なる問題インスタンス間での並列最適化を可能にします。したがって、その並列能力は集団内と複数の集団間の両方に存在します。
この観点から見ると、EvoGO の重要な貢献は単なる生成モデルの導入ではなく、サンプル構成、目的の整合、および集団の更新を単一の方法論的枠組みの中に統合したことです。従来の進化最適化は事前に書かれたルールに基づく探索を強調しますが、EvoGO はさらに一歩進んで、システムが探索プロセス自体を履歴データから直接学習できるようにしようとします。
検証:パフォーマンスとメカニズムの分析
この新しい完全データ駆動型パラダイムの有効性を厳密に評価するために、論文では3つの重要な問題に焦点を当てています。EvoGO は十分に強力で効率的か?その成功の背後にある重要な設計上の選択は何か?どのようなインテリジェントな探索行動を示すか?
1. パフォーマンス比較:「10世代収束」がベンチマーク全体をリード
論文では、数値最適化、古典的制御、および高次元ロボット制御の3つのタスクカテゴリについて体系的な評価を実施し、10から1000の範囲の問題次元を持つ25のベンチマークテストをカバーしています。EvoGO は、ベイズ最適化、古典的な進化戦略、ヒューリスティック手法、および高度なサロゲート支援手法と包括的に比較されています。
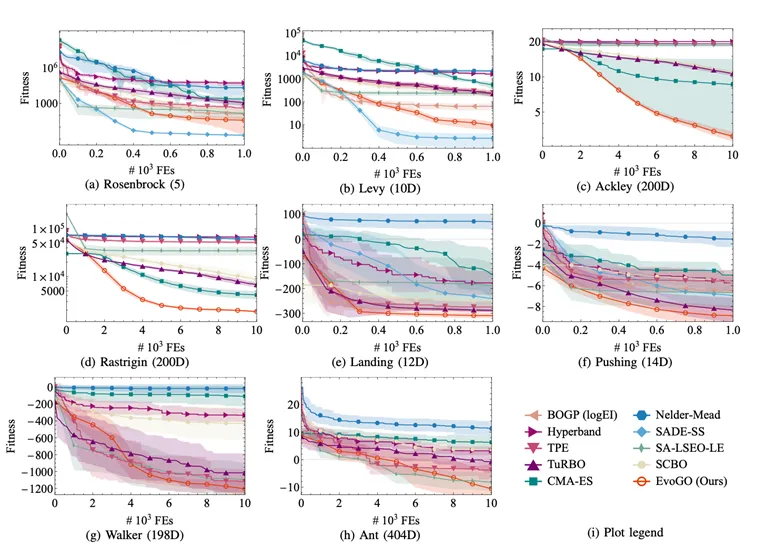

全体として、EvoGO はほとんどのタスクで明確な優位性を示しています。特に、この優位性は低次元または比較的規則的な問題に限定されません。逆に、問題の次元とタスクの複雑さが増すにつれて、EvoGO の優位性はさらに顕著になることがよくあります。低次元かつ小サンプルの条件下では、いくつかの最強のサロゲート支援手法が依然として高い競争力を維持しています。しかし、問題が高次元で複雑になり、並列計算に依存するようになると、EvoGO の生成メカニズムがより十分に展開され、ほとんどの大規模タスクにおいて約10世代で収束することができます。これは、EvoGO の価値が単一のタイプの問題で局所的な優位性を達成することにあるのではなく、複雑なブラックボックス最適化で必要とされる大規模な経験の活用と並列探索により適していることにあることを示唆しています。
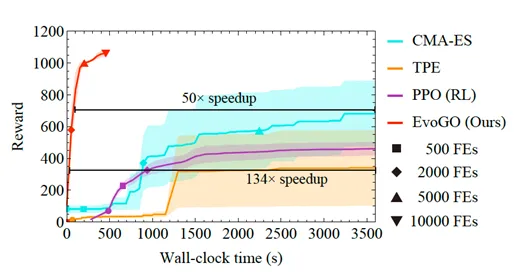
これは、Brax の高次元ロボット制御環境 Hopper で特に顕著です。同じ関数評価バジェットと実行時間バジェットの下で、EvoGO は CMA-ES や TPE などの従来の最適化アルゴリズムを大幅に上回り、環境とのオンラインインタラクションを必要とする PPO 強化学習アルゴリズムも凌駕します。さらに重要なことに、GPU などの最新のハードウェアの並列計算能力のおかげで、EvoGO は約500秒で高い報酬レベルに達することができます。CMA-ES が最終的に最高のパフォーマンスレベルに収束したとき、EvoGO が同じパフォーマンスに達するために必要な実際の実行時間ははるかに短く、最大134倍のスピードアップとなります。この結果は、EvoGO の優位性が単に世代数を減らすことにあるのではなく、その探索プロセス自体が並列計算リソースにより良く適合しており、多くの世代に分散される最適化アクションを高スループットの生成更新プロセスに圧縮している点にあることを示しています。
2. アブレーション調査:成功の鍵を解剖する
EvoGO の「完全データ駆動型」設計におけるコアコンポーネントの必要性を検証するために、研究チームはペア生成アーキテクチャ、サロゲートガイダンスメカニズム、および最適化指向の目的設計を中心とした体系的なアブレーションを実施しました。単一生成器バージョン、サロゲートなしバージョン、敵対的目的バージョン、MLPサロゲートバージョン、およびヒューリスティックサロゲートバージョンの5つのバリアントが構築されました。
実験結果は、ペア生成アーキテクチャ、サロゲートガイダンスメカニズム、および最適化指向の目的設計がすべて、EvoGO の有効性にとって重要であることを示しています。擬似逆生成器を削除すると、収束の安定性が顕著に悪化し、集団の多様性が減少します。これは、フォワード生成と逆制約によって形成されるペア構造が、学習の安定性を維持しモード崩壊を回避するために必要であることを示しています。サロゲートモデルを削除したり、元の最適化目標を一般的な敵対的目標に置き換えたりした場合も、大幅なパフォーマンスの低下を引き起こし、サロゲートガイダンスと目的の整合がこの手法の優位性の核心であることを示しています。ガウス過程を多層パーセプトロンやヒューリスティックなルールに置き換えても手法は機能しますが、全体的にわずかな低下が見られます。これは、EvoGO が特定のサロゲート形式に依存しているわけではないものの、明示的な不確実性モデリングがパフォーマンスに有利であることを示しています。全体として、EvoGO のパフォーマンス向上は単一のモジュールによるものではなく、ペア生成アーキテクチャ、サロゲートガイダンスメカニズム、および最適化指向の目的設計の間の相乗効果から生じています。
3. 行動の可視化:データ駆動の動的プロセスを明らかにする
EvoGO の探索のダイナミクスをより直感的に分析するために、論文では2次元の Ackley 関数での可視化実験が提示されており、集団サイズは100に設定されています。具体的には、さまざまな進化の世代において、学習済みのフォワード生成器による入力解の変換結果、つまり入力解から出力解へのマッピングプロセスが記録されています。図では、矢印は入力解から出力解へのベクトルを表し、その色はベクトルの長さに対応しています。星印はグローバル最適解を示し、破線のボックスはさまざまな世代で生成された解がカバーする領域を示しています。わかりやすくするために、この可視化では関数の地形の平行移動と回転の構成は省略されています。
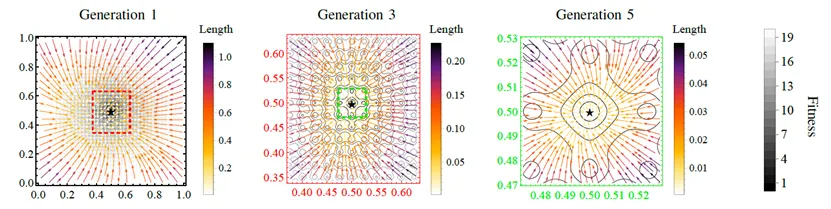
可視化の結果は、EvoGO が学習したのが方向性のないランダムな摂動ではなく、探索の段階に適応する更新パターンであることを示しています。初期段階では生成されるベクトルが全体的に長く、アルゴリズムが振幅の大きい大域的な探索に向かう傾向があることを示しています。進化が進むにつれてベクトルの長さは徐々に減少し、生成される領域は収縮し続け、探索がより細かい局所的な活用へと移行していることを示しています。同時に、ベクトル全体が最適領域に向かって集まっており、フォワード生成器がすでに履歴サンプルから実用的な意味のある探索方向を抽出していることを示しています。行動レベルにおいて、この現象は EvoGO の中心的な特性を裏付けています。つまり、候補解の分布だけでなく、現在の状態からより良い状態へ移行する更新法則を学習しているということです。
応用:ワイドボディ旅客機の超臨界翼におけるエンジニアリング検証
C919 の引き渡し成功は、中国の国産大型航空機開発における重要な一歩となりました。しかし、単通路のナローボディ旅客機である C919 は主に短中距離路線で運航されており、ワイドボディ旅客機分野でのブレークスルーが依然として必要とされています。次世代の国産ワイドボディ機の開発ニーズに応えるため、超臨界翼の設計は空力最適化における重要な課題となっており、巡航抵抗の低減、燃料効率の向上、および飛行安定性の強化に重要な役割を果たしています。したがって、効率的で信頼性の高い超臨界翼の最適化をどのように実現するかが、中国のワイドボディ機開発プロセスにおける中核的な技術的課題となっています。
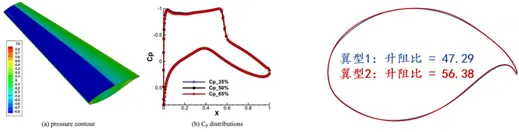
元の記事に示されているように、長い翼弦長、平坦な上面、後縁キャンバーの増加などの幾何学的特徴を最適化することにより、超臨界翼は遷音速の圧力分布を調整し、衝撃波の形成を抑制し、造波抵抗を減らし、揚力効率を向上させることができます。しかし、その最適設計は複数の課題に直面しています。第一に、ワイドボディ機の高レイノルズ数条件下では、設計は揚抗比、揚力係数、巡航迎え角などの厳格な空力制約を同時に満たす必要があり、形状パラメータに極めて高い精度が要求されます。第二に、翼型の幾何形状と空力性能の間には強い非線形のカップリング関係があり、従来のモデリング手法で正確に特徴づけることは困難です。さらに、既存の設計プロセスは経験、繰り返しの CFD シミュレーション、および風洞実験に大きく依存しているため、計算コストが高く、開発サイクルが長くなり、高次元の設計空間でグローバル最適解に効果的にアプローチすることが難しくなっています。
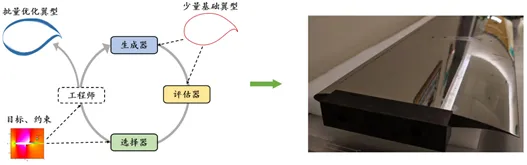
この問題に対処するため、EvoX チームは性能評価、翼型生成、および候補スクリーニングから構成される、EvoGO に基づく統合設計パイプラインを構築しました。この手法は、少数の履歴翼型サンプルに基づいて性能評価モデル、翼型生成モデル、およびスクリーニングモデルを構築し、反復的な進化を通じて翼型の設計を継続的に改善します。サロゲートモデルは、揚抗比、揚力係数、巡航迎え角などの重要な指標を正確に予測するために使用されます。同時に、従来のヒューリスティックな探索を置き換えるために生成メカニズムが導入され、高次元の設計空間でグローバル最適解への効率的な近似が可能になります。候補スクリーニング戦略と組み合わせることで、この手法は広大な探索空間から物理的制約と空力性能要件の両方を満たす候補翼型を迅速に特定でき、設計効率を向上させます。
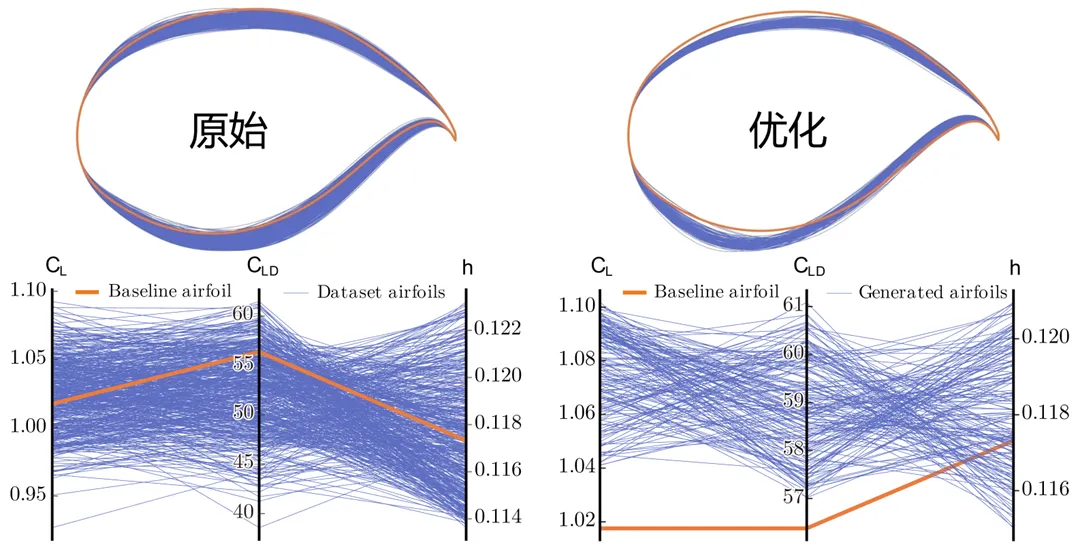
わずか500個の履歴翼型サンプルを使用するだけで、この手法は揚抗比、揚力係数、および巡航迎え角という3つの重要な空力指標で99.5%を超える予測精度を達成し、自動生成された翼型の合格率は95%を超えました。これらの結果は、EvoGO のような完全データ駆動型の進化最適化手法が標準的なベンチマークテストで優れたパフォーマンスを発揮できるだけでなく、複雑な実際のエンジニアリング問題に対して効果的な設計サポートを提供する能力を示し始めていることを示しています。
視野を深める:物理学から哲学まで、EvoGO の再解釈
物理的視点:無秩序な試行錯誤から秩序ある進化へ
物理的な観点から見ると、ブラックボックス最適化は、現実には存在するが完全には観測できないポテンシャル場の中で、より安定した状態を徐々に探索するプロセスとして理解できます。オプティマイザーにとって、目的関数とその適応度地形は常に客観的に存在しますが、初期段階ではシステムは限られたサンプリングと評価を通じて局所的な知識しか得ることができません。したがって、探索は当然のことながら高い不確実性を伴います。
従来の進化最適化は、局所的な摂動とランダムな試行錯誤に大きく依存しています。サンプリングと選択を繰り返すことでより良い領域に徐々に近づくことはできますが、探索プロセスは依然として高エントロピーな局所的探索として大きく表れ、過去の経験を体系的に蓄積することは困難です。EvoGO の特徴は、履歴サンプルを方向性と構造をエンコードした情報の基盤としてさらに構成している点です。サロゲートモデルは局所的な目的関数の地形の近似的な理解を提供します。優良解と劣悪解のペアリングは、劣った領域からより良い領域に向かって移動することに関する方向情報を抽出します。そして、フォワード生成と逆制約によって形成されるループにより、この方向性のある更新プロセスが安定性を保ちながら継続的に展開できるようになります。
物理学的な観点から言えば、EvoGO は有効なポテンシャル場の導きの下で秩序ある構造が徐々に形成されるプロセスに似ています。これが行うのは単に探索を加速することではなく、限られた観測可能性の下で探索の不確実性を徐々に減らし、集団の更新を無秩序な試行錯誤から組織化された進化の流れへと変換することです。速度は単なる結果にすぎません。より深い変化は、履歴の経験が、蓄積、伝達、および再利用できる構造化された情報へと変換され始めているということです。
哲学的視点:「道生万物」から法則の生成へ
哲学的な観点から見ると、EvoGO についてさらに強調する価値があるのは、それが経験から秩序へ、そして局所から全体へと向かう生成プロセスを体現していることです。このプロセスは、「道生一、一生二、二生三、三生万物(道は一を生じ、一は二を生じ、二は三を生じ、三は万物を生ず)」という古典的な言葉で要約されるかもしれません。
**「道」**は、客観的に存在するが完全には把握できない対象問題の真の法則に相当します。最適化において、最適解はアルゴリズムによって主観的に規定されるものではありません。むしろ、それは常に実際の目的関数とその適応度地形の中に潜んでいます。アルゴリズムができることは、道を創造することではなく、ただ絶えずそれに近づくことだけです。
**「一」**は、乱雑な経験から抽出された統一された構造に相当します。履歴サンプルは最初は単なる探索の散乱した痕跡にすぎず、自動的に知識を構成するわけではありません。これらのサンプルが分類され、フィルタリングされ、組織化されたときにのみ、経験は無秩序から学習可能な全体へと移行し始めます。これが「一を生ずる」の意味です。
**「二」**は分化、つまり方向性の出現に相当します。優良解と劣悪解の区別は、単なる良し悪しの区別を表すだけではありません。より重要なことに、それはシステムが経験から初めて方向性を獲得することを示しています。この分化がなければ、経験は単に蓄積されるだけです。分化があることで、経験は進化の張力を獲得します。
**「三」**は閉ループ、つまり関係性の生成に相当します。目的の認知、前進、および後退の制約が共同で自己矛盾のないシステムを形成するとき、最適化はもはや局所的な操作の寄せ集めではなく、自己維持と自己修正が可能な完全なメカニズムとして形を作り始めます。この時点で、手法は真に新しい解を継続的に生成する能力を獲得します。
そして**「万物」**は、この生成の秩序の上に絶えず出現する新しい集団と新しい候補解に相当します。それらは盲目的に生み出されるのではなく、すでに形成された方向性、構造、および閉ループ制約の下で継続的に生じます。まさにこの理由から、EvoGO が進歩させるのは、単なる「より良い解をより速く見つける」能力ではなく、進化最適化が経験から法則を生成し、その法則から解を継続的に生成するという新しい能力です。
EvoGO の哲学的な意義は、従来のオペレータを単に置き換えることにはありません。むしろ、最適化は事前に書かれたルールによってのみ推し進められる必要はないということをより明確に示している点にあります。経験の蓄積、分化、および組織化を通じて、それは独自の生成秩序を徐々に形成することができます。
結論と展望
EvoGO が焦点を当てているのは、従来の進化最適化パイプラインに対する単なる局所的な改善ではなく、最適化そのものがどのように起こるかについてのより根本的な再構築です。最適化をデータ準備、モデル学習、集団生成という3つの統一された段階に構成し、優良と劣悪のペアリングに基づく方向性データ構成、サロゲート誘導によるペア生成アーキテクチャ、および並列集団生成メカニズムを導入することで、EvoGO は標準的なベンチマークテストにおいてパフォーマンスと効率の両方で安定した優位性を示しています。同時に、次世代のワイドボディ旅客機の超臨界翼最適化設計を通じて、複雑な実際のエンジニアリング問題に対する潜在能力も検証しました。より高いレベルでは、この研究の意義は、進化最適化が必ずしも手動で指定されたヒューリスティックなルールに限定されたままである必要はないことを示した点にあります。最適化プロセス自体が、履歴経験から学習可能な法則として徐々に抽出される可能性があります。
オープンソースコード / コミュニティ
- 論文:
https://arxiv.org/abs/2602.01147 - GitHub:
https://github.com/EMI-Group/evogo - 上流プロジェクト(EvoX):
https://github.com/EMI-Group/evox - QQグループ:
297969717 - WeChat公式アカウント: 进化智能(Evolutionary Machine Intelligence)
EvoGO は EvoX フレームワークの上に構築されています。EvoX に興味がある場合は、EvoX の公式アカウントの記事(https://mp.weixin.qq.com/s/uT6qSqiWiqevPRRTAVIusQ)で詳細を確認することをお勧めします。