Verbindung von evolutionärer mehrkriterieller Optimierung und GPU-Beschleunigung durch Tensorisierung
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun und Ran Cheng, Senior Member, IEEE
Mit der stetig steigenden Nachfrage nach komplexen Optimierungslösungen in Bereichen wie technischem Design und Energiemanagement haben Algorithmen der evolutionären mehrkriteriellen Optimierung (EMO) aufgrund ihrer robusten Fähigkeiten zur Lösung mehrkriterieller Probleme große Aufmerksamkeit erlangt. Da Optimierungsaufgaben jedoch an Umfang und Komplexität zunehmen, stoßen herkömmliche CPU-basierte EMO-Algorithmen auf erhebliche Leistungsengpässe.
Um diese Einschränkung zu beheben, schlug das EvoX-Team vor, EMO-Algorithmen mittels der Tensorisierungsmethodik auf GPUs zu parallelisieren. Unter Nutzung dieser Methode haben sie erfolgreich mehrere GPU-beschleunigte EMO-Algorithmen entworfen und implementiert. Darüber hinaus entwickelte das Team “MoRobtrol”, eine Benchmark-Suite für mehrkriterielle Robotersteuerung, die auf der Brax-Physik-Engine aufbaut und darauf abzielt, die Leistung von GPU-beschleunigten EMO-Algorithmen systematisch zu bewerten.
Basierend auf diesen Forschungsfortschritten hat das EvoX-Team EvoMO veröffentlicht, eine leistungsstarke Bibliothek für GPU-beschleunigte EMO-Algorithmen. Der entsprechende Quellcode ist öffentlich auf GitHub verfügbar: https://github.com/EMl-Group/evomo
Methodik der Tensorisierung
Im Bereich der rechnergestützten Optimierung bezeichnet ein Tensor eine mehrdimensionale Array-Datenstruktur, die Skalare, Vektoren, Matrizen und Daten höherer Ordnung darstellen kann. Tensorisierung ist der Prozess der Umwandlung von Datenstrukturen und Operationen innerhalb eines Algorithmus in Tensorform, wodurch der Algorithmus die parallelen Rechenkapazitäten von GPUs voll ausschöpfen kann.
In EMO-Algorithmen können alle wichtigen Datenstrukturen in einem tensorisierten Format ausgedrückt werden. Die Individuen einer Population können durch einen Lösungstensor X dargestellt werden, wobei jeder Zeilenvektor einem Individuum entspricht. die Zielfunktionswerte bilden einen Zieltensor F. Zusätzlich können Hilfsdatenstrukturen wie Referenzvektoren und Gewichtsvektoren als Tensoren R bzw. W ausgedrückt werden. Diese einheitliche Tensordarstellung ermöglicht Operationen auf Populationsebene auf der Repräsentationsebene und legt damit ein solides Fundament für groß angelegte parallele Berechnungen.
Die Tensorisierung von EMO-Algorithmus-Operationen ist entscheidend für die Steigerung der Recheneffizienz und kann in zwei Ebenen unterteilt werden: grundlegende Tensor-Operationen und Tensorisierung des Kontrollflusses. Grundlegende Tensor-Operationen bilden den Kern der tensorisierten Implementierung von EMO-Algorithmen, wie in Tabelle I detailliert dargestellt.
Tabelle I: Grundlegende Tensor-Operationen

Die Tensorisierung des Kontrollflusses ersetzt traditionelle Schleifen und bedingte Logik durch parallelisierbare Tensor-Operationen. Beispielsweise können for/while-Schleifen mithilfe von Broadcasting-Mechanismen oder Funktionen höherer Ordnung wie vmap in Batch-Operationen umgewandelt werden. Ähnlich können if-else-Bedingungen durch Maskierungstechniken ersetzt werden, bei denen logische Bedingungen als boolesche Tensoren kodiert werden, was ein flexibles Umschalten zwischen verschiedenen Berechnungspfaden ermöglicht.
Im Vergleich zu herkömmlichen Implementierungen von EMO-Algorithmen bietet der Tensorisierungsansatz erhebliche Vorteile. Erstens bietet er eine größere Flexibilität und handhabt natürlich mehrdimensionale Daten, während konventionelle Methoden oft auf zweidimensionale Matrixoperationen beschränkt sind. Zweitens verbessert die Tensorisierung die Recheneffizienz durch parallele Ausführung erheblich und vermeidet den Overhead, der mit expliziten Schleifen und bedingten Verzweigungen verbunden ist. Schließlich vereinfacht sie die Codestruktur, was zu prägnanteren und wartbareren Programmen führt.
Wie in Abb. 1 dargestellt, verlässt sich beispielsweise die traditionelle Implementierung der Überprüfung auf Pareto-Dominanz auf verschachtelte Schleifen, um elementweise Vergleiche durchzuführen. Im Gegensatz dazu erreicht die tensorisierte Version die gleiche Funktionalität durch Broadcasting- und Maskierungsoperationen, was eine parallele Auswertung ermöglicht. Dies reduziert nicht nur die Codekomplexität, sondern verbessert auch die Laufzeitperformance drastisch.

Abb. 1: Vergleich zwischen herkömmlichen und tensorbasierten Implementierungen der Pareto-Dominanz-Erkennung.
Aus einer tieferen Perspektive eignet sich die Tensorisierung gut für die GPU-Beschleunigung, da GPUs über eine große Anzahl paralleler Kerne verfügen und ihre Single-Instruction-Multiple-Thread (SIMT)-Architektur natürlich mit Tensorberechnungen übereinstimmt, wobei sie besonders bei Matrixoperationen hervorragt. Dedizierte Hardware wie NVIDIAs Tensor Cores erhöht den Durchsatz von Tensoroperationen weiter. Im Allgemeinen sind Algorithmen, die eine hohe Parallelität aufweisen, unabhängige Rechenaufgaben enthalten und minimale bedingte Verzweigungen haben, besser für die Tensorisierung geeignet. Für Algorithmen wie MOEA/D, die sequentielle Abhängigkeiten beinhalten, stellt die inhärente Struktur Herausforderungen für die direkte Tensorisierung dar. Durch strukturelles Refactoring und die Entkopplung kritischer Berechnungen ist es jedoch dennoch möglich, eine effektive parallele Beschleunigung zu erreichen.
Anwendungsbeispiel der Algorithmus-Tensorisierung
Basierend auf der Methodik der tensorisierten Darstellung hat das EvoX-Team tensorisierte Versionen von drei klassischen EMO-Algorithmen entworfen und implementiert: den dominanzbasierten NSGA-III, den dekompositionsbasierten MOEA/D und den indikatorbasierten HypE. Der folgende Abschnitt bietet eine detaillierte Erklärung am Beispiel von MOEA/D. Tensorisierte Implementierungen von NSGA-III und HypE sind im referenzierten Paper zu finden.
Wie in Abb. 2 dargestellt, zerlegt der traditionelle MOEA/D ein mehrkriterielles Problem in mehrere Teilprobleme, von denen jedes unabhängig optimiert wird. Der Algorithmus umfasst vier Kernschritte: Crossover und Mutation, Fitness-Evaluierung, Aktualisierung des idealen Punktes und Nachbarschaftsaktualisierung. Diese Schritte werden sequentiell für jedes Individuum innerhalb einer einzigen Schleife ausgeführt. Diese sequentielle Verarbeitung führt zu erheblichem Rechenaufwand bei großen Populationen, da jedes Individuum alle Schritte der Reihe nach abschließen muss, was die potenziellen Vorteile der GPU-Beschleunigung einschränkt. Insbesondere die Nachbarschaftsaktualisierung beruht auf Interaktionen zwischen Individuen, was die Parallelisierung weiter erschwert.

Abb. 2: Pseudocode von MOEA/D
Um das Problem der sequentiellen Abhängigkeiten im traditionellen MOEA/D zu lösen, führte das Team eine tensorisierte Darstellungsmethode innerhalb der inneren Schleife der Umweltselektion ein. Durch die Entkopplung von Crossover und Mutation, Fitness-Evaluierung, Aktualisierung des idealen Punktes und Nachbarschaftsaktualisierung werden diese Komponenten als unabhängige Operationen behandelt. Dies ermöglicht die parallele Verarbeitung aller Individuen, was zur Konstruktion eines tensorisierten MOEA/D-Algorithmus führt, der als TensorMOEA/D bezeichnet wird. In diesem Algorithmus ist die Umweltselektion in zwei Hauptphasen unterteilt: Vergleich und Populationsaktualisierung sowie Auswahl der Elite-Lösungen. Diese beiden Phasen werden primär durch zwei Anwendungen der vmap-Operation tensorisiert. Der detaillierte Prozess ist in Abb. 3 dargestellt.
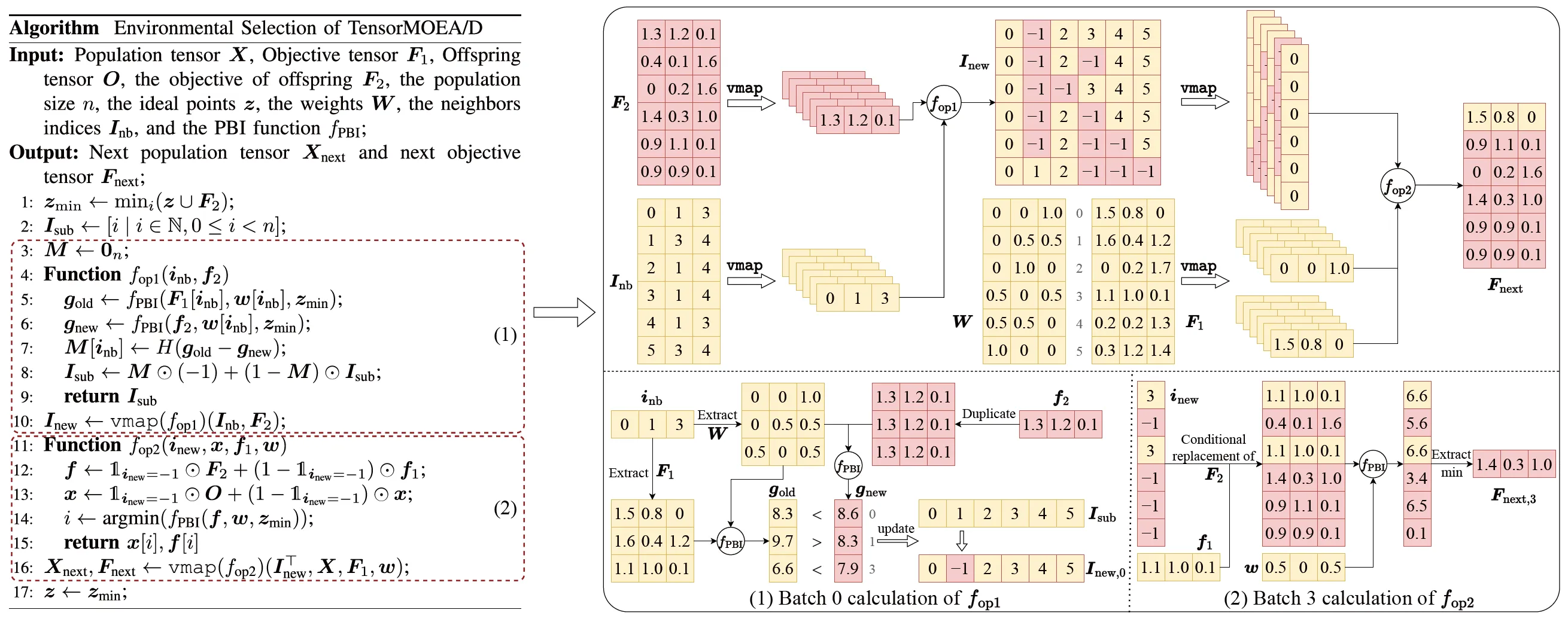

Abb. 3: Überblick über die Umweltselektion im TensorMOEA/D-Algorithmus. Links: Pseudocode des Algorithmus. Rechts: Tensor-Datenfluss von Modul (1) und Modul (2). Der obere Teil der rechten Abbildung zeigt den gesamten Tensor-Datenfluss für die Module (1) und (2), während der untere Teil den Tensor-Datenfluss der Batch-Berechnung darstellt, mit Modul (1) links und Modul (2) rechts.
Um ein umfassenderes Verständnis für den Wert der Tensorisierung in EMO-Algorithmen zu gewinnen, kann dieser aus drei Perspektiven zusammengefasst werden. Erstens ermöglicht die Tensorisierung eine direkte Transformation von mathematischen Formulierungen in effizienten Code, wodurch die Lücke zwischen Algorithmusdesign und Implementierung verringert wird. Abb. 4 veranschaulicht beispielsweise, wie das tensorisierte Verfahren der nicht-dominierten Sortierung direkt vom Pseudocode in Python-Code übersetzt werden kann. Zweitens vereinfacht die Tensorisierung die Codestruktur erheblich, indem Operationen auf Populationsebene in einer einzigen Tensordarstellung vereinheitlicht werden. Dies reduziert die Abhängigkeit von Schleifen und bedingten Anweisungen und verbessert so die Lesbarkeit und Wartbarkeit des Codes. Drittens verbessert die Tensorisierung die Reproduzierbarkeit von Algorithmen. Ihre strukturierte Darstellung erleichtert vergleichende Tests und die konsistente Reproduktion von Ergebnissen.

Abb. 4: Die nahtlose Transformation der tensorisierten nicht-dominierten Sortierung vom Pseudocode (Links) zum Python-Code (Rechts).
Leistungsdemonstration
Um die Leistung von GPU-beschleunigten mehrkriteriellen Optimierungsalgorithmen zu bewerten, führte das EvoX-Team systematisch drei Kategorien von Experimenten durch, die sich auf die Rechenbeschleunigung, die numerische Optimierungsleistung und die Effektivität bei Aufgaben der mehrkriteriellen Robotersteuerung konzentrierten.
Leistung der Rechenbeschleunigung:
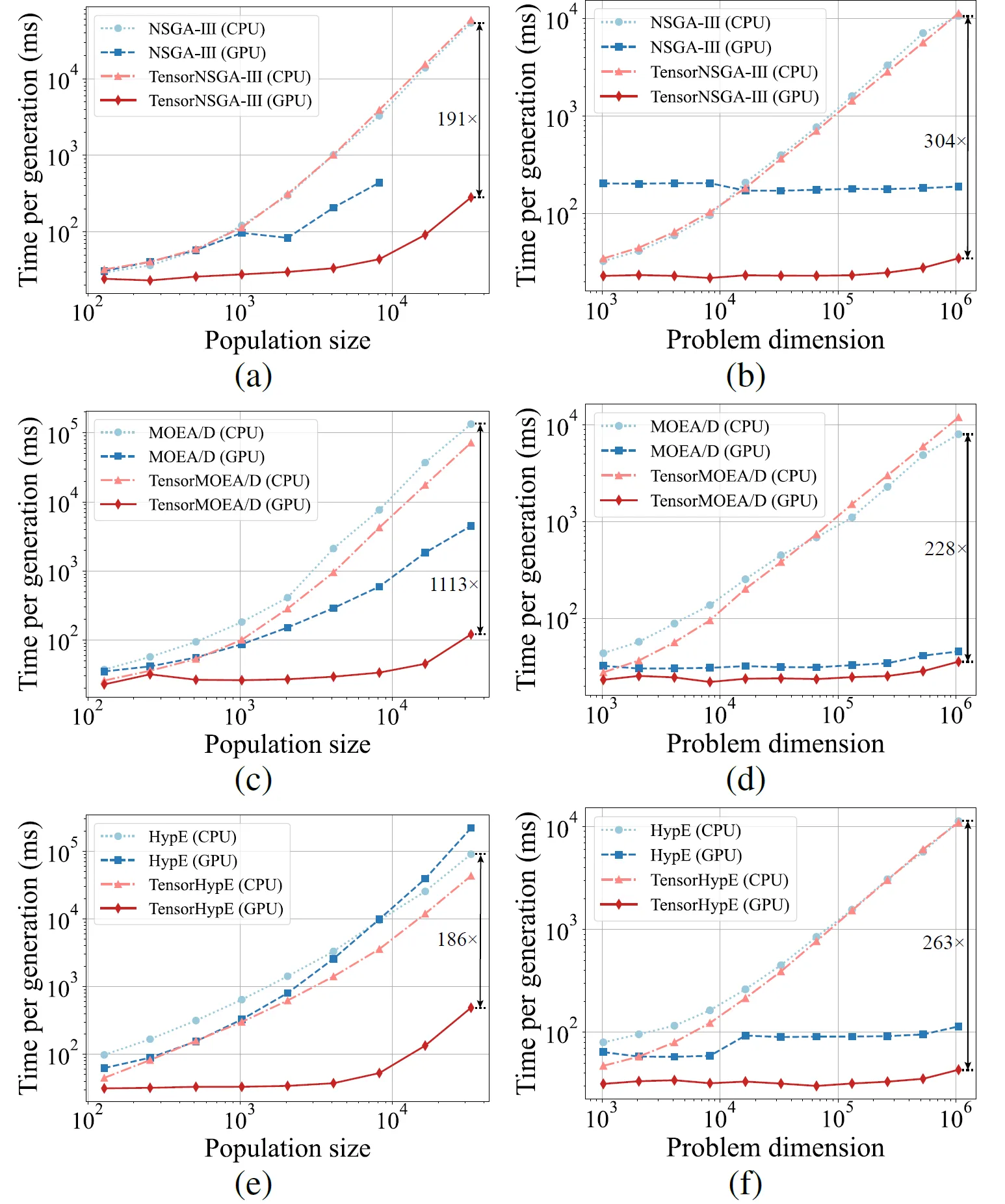
Abb. 5: Vergleichende Beschleunigungsleistung von NSGA-III, MOEA/D und HypE mit ihren tensorisierten Gegenstücken auf CPU- und GPU-Plattformen über verschiedene Populationsgrößen und Problemdimensionen hinweg.
Die experimentellen Ergebnisse zeigen, dass TensorNSGA-III, TensorMOEA/D und TensorHypE auf GPUs im Vergleich zu ihren nicht-tensorisierten CPU-basierten Gegenstücken deutlich höhere Ausführungsgeschwindigkeiten erreichen. Mit zunehmender Populationsgröße und Problemdimensionalität erreicht der maximal beobachtete Speedup bis zu 1113x. Die tensorisierten Algorithmen zeigen eine hervorragende Skalierbarkeit und Stabilität bei der Bewältigung großer Rechenaufgaben – ihre Laufzeit steigt nur geringfügig an, während sie eine konstant hohe Leistung beibehalten. Diese Ergebnisse unterstreichen die erheblichen Vorteile der Tensorisierung für die GPU-Beschleunigung in der mehrkriteriellen Optimierung.
Leistung auf der LSMOP-Testsuite:
Tabelle II: Statistische Ergebnisse (Mittelwert und Standardabweichung) der IGD und Laufzeit (s) für nicht-tensorisierte und tensorisierte EMO-Algorithmen in LSMOP1–LSMOP9. Alle Experimente wurden auf einer RTX 4090 GPU durchgeführt und die besten Ergebnisse sind hervorgehoben.
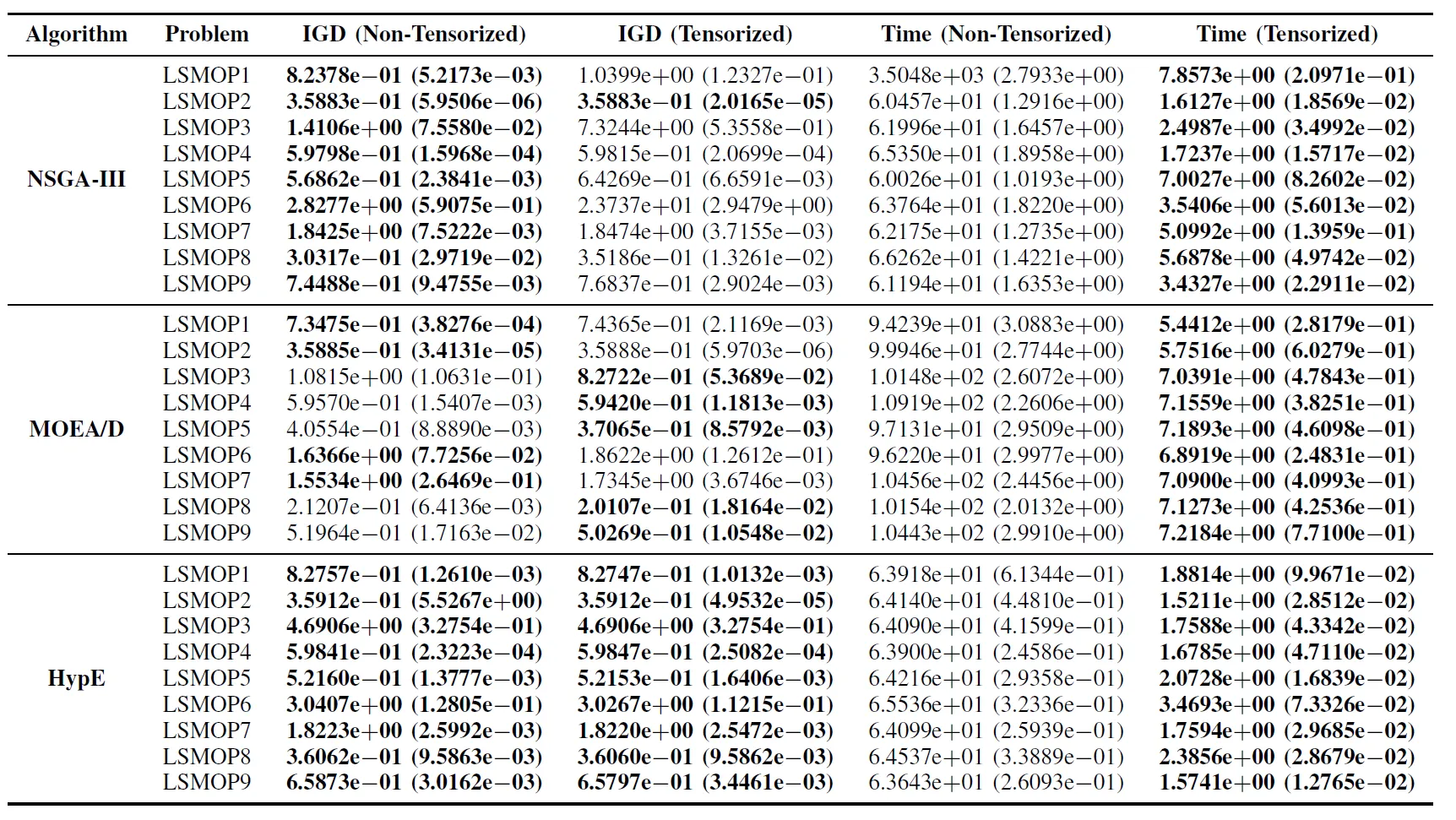
Die experimentellen Ergebnisse zeigen, dass die GPU-beschleunigten EMO-Algorithmen, die auf tensorisierten Darstellungen basieren, die Recheneffizienz erheblich verbessern, während sie die Optimierungsgenauigkeit ihrer ursprünglichen Gegenstücke beibehalten und in einigen Fällen sogar übertreffen.
Aufgaben der mehrkriteriellen Robotersteuerung:
Um die praktische Leistung von GPU-beschleunigten EMO-Algorithmen umfassend zu bewerten, entwickelte das Team eine Benchmark-Suite namens MoRobtrol für die mehrkriterielle Robotersteuerung. Die in dieser Suite enthaltenen Aufgaben sind in Tabelle III aufgeführt.
Tabelle III: Überblick über Probleme der mehrkriteriellen Robotersteuerung in der vorgeschlagenen MoRobtrol Benchmark-Testsuite
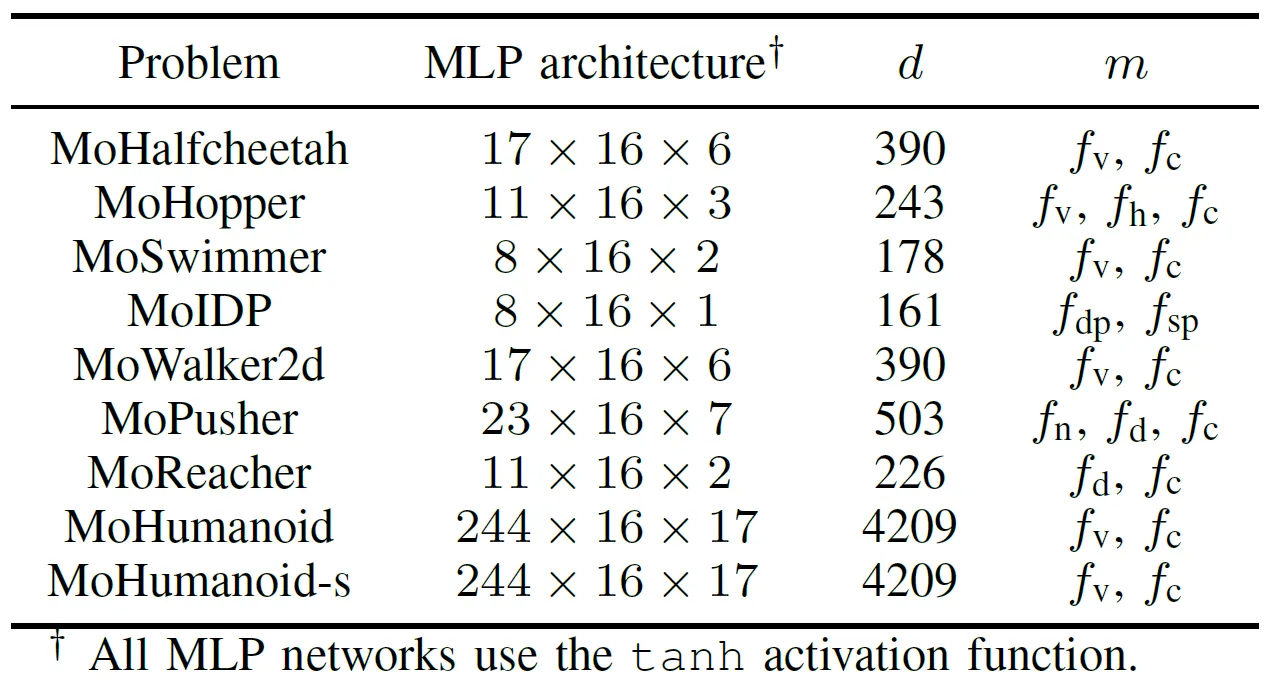
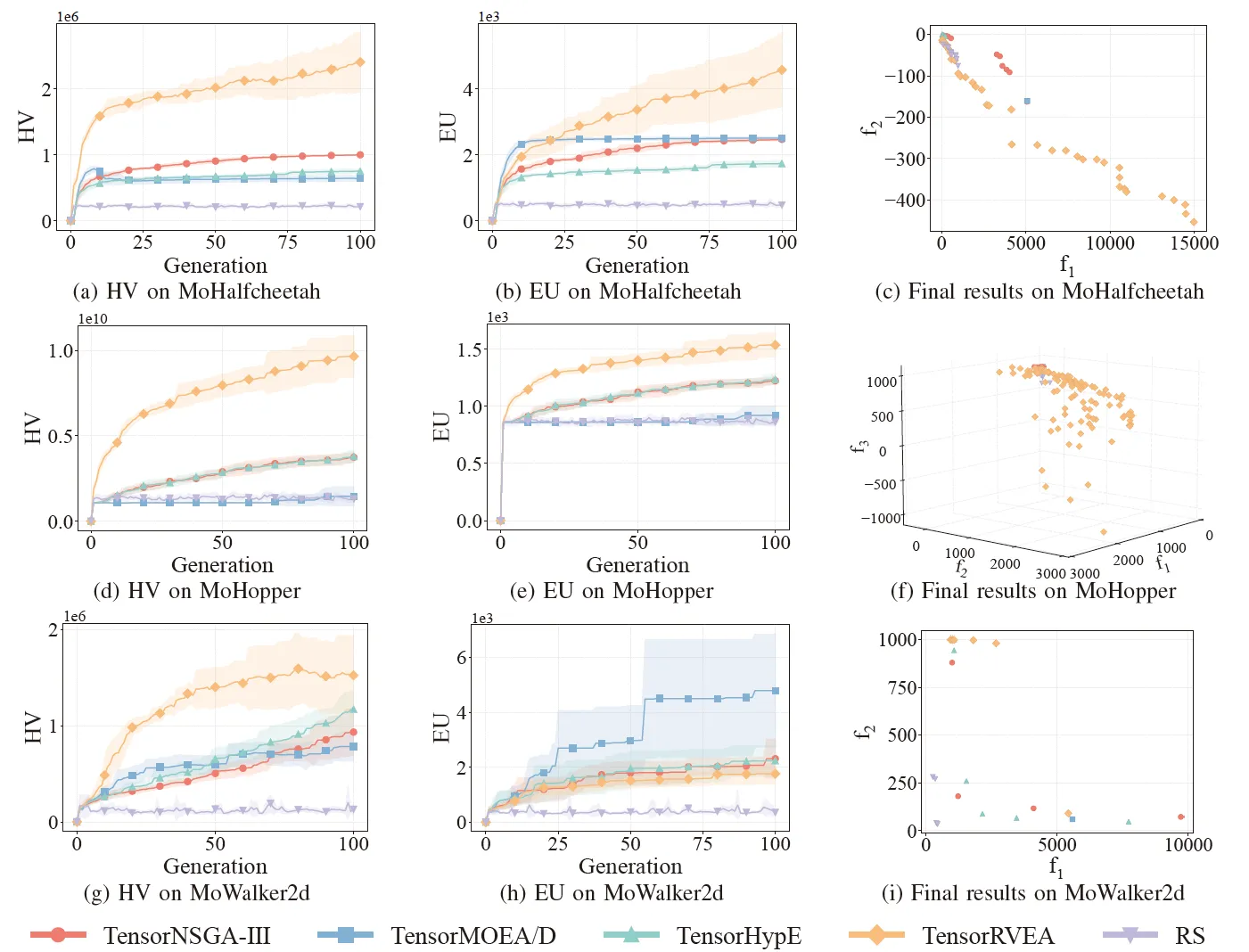
Abb. 6: Vergleichende Leistung (HV, EU und Visualisierung der Endergebnisse) von TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA und Zufallssuche (RS) über verschiedene Probleme hinweg: MoHalfcheetah (390D), MoHopper (243D) und MoWalker2d (390D). Hinweis: Höhere Werte bei allen Metriken zeigen eine bessere Leistung an.
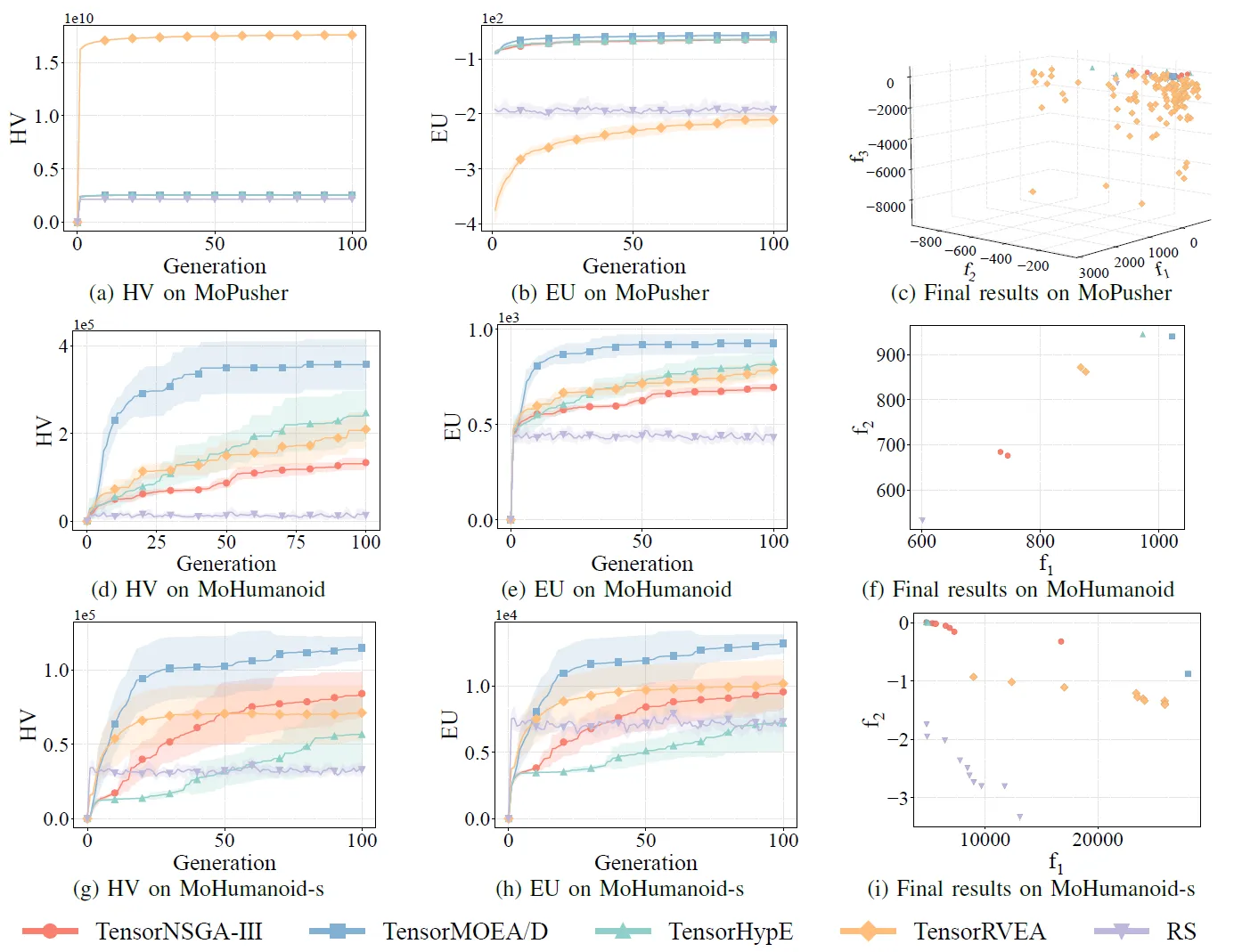
Abb. 7: Vergleichende Leistung (HV, EU und Visualisierung der Endergebnisse) von TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA und Zufallssuche (RS) über verschiedene Probleme hinweg: MoPusher (503D), MoHumanoid (4209D) und MoHumanoid-s (4209D). Hinweis: Höhere Werte bei allen Metriken zeigen eine bessere Leistung an.
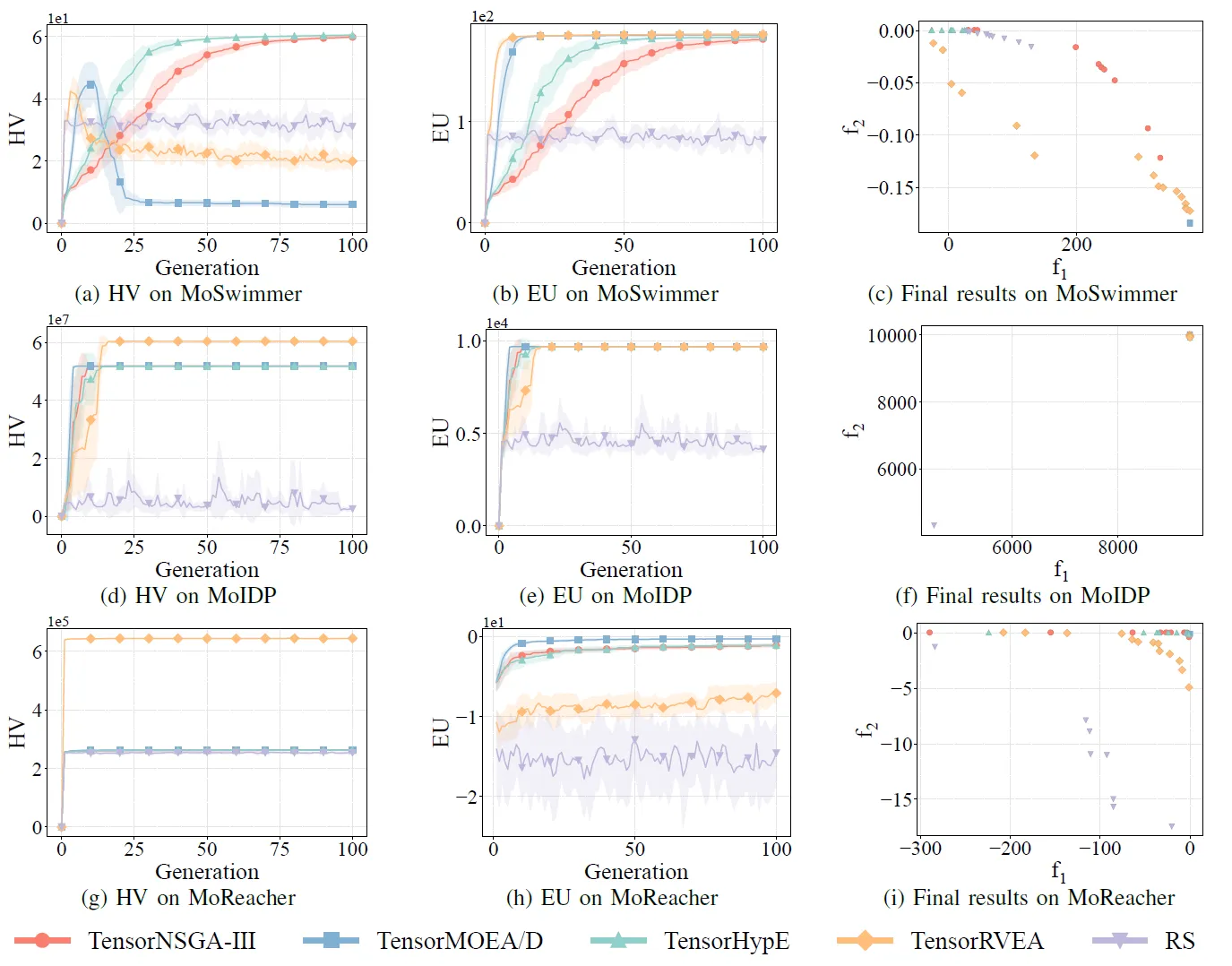
Abb. 8: Vergleichende Leistung (HV, EU und Visualisierung der Endergebnisse) von TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA und Zufallssuche (RS) über verschiedene Probleme hinweg: MoSwimmer (178D), MoIDP (161D) und MoReacher (226D). Hinweis: Höhere Werte bei allen Metriken zeigen eine bessere Leistung an.
Die Experimente verglichen die Leistung von TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA und Random Search (RS) innerhalb des MoRobtrol-Benchmarks. Die Ergebnisse zeigen, dass TensorRVEA die beste Gesamtleistung erzielte, die höchsten HV-Werte erreichte und eine gute Lösungsvielfalt über mehrere Umgebungen hinweg demonstrierte. TensorMOEA/D zeigte eine starke Anpassungsfähigkeit bei groß angelegten Aufgaben und zeichnete sich besonders durch die Präferenzkonsistenz der Lösungen aus. TensorNSGA-III und TensorHypE zeigten eine ähnliche Leistung und waren bei mehreren Aufgaben wettbewerbsfähig. Insgesamt zeigten tensorisierte dekompositionsbasierte Algorithmen überlegene Vorteile bei der Lösung groß angelegter und komplexer Probleme.
Fazit und zukünftige Arbeit
Diese Studie schlägt eine Methodik der tensorisierten Darstellung vor, um die Einschränkungen traditioneller CPU-basierter EMO-Algorithmen in Bezug auf Recheneffizienz und Skalierbarkeit zu beheben. Der Ansatz wurde auf mehrere repräsentative Algorithmen angewendet, darunter NSGA-III, MOEA/D und HypE, und erzielte signifikante Leistungsverbesserungen auf GPUs bei gleichzeitiger Beibehaltung der Lösungsqualität. Um die praktische Anwendbarkeit zu validieren, entwickelte das Team auch MoRobtrol, eine Benchmark-Suite für mehrkriterielle Robotersteuerung, die Aufgaben der Robotersteuerung in physikalischen Simulationsumgebungen als mehrkriterielle Optimierungsprobleme neu formuliert. Die Ergebnisse demonstrieren das Potenzial tensorisierter Algorithmen in rechenintensiven Szenarien wie der verkörperten Intelligenz (Embodied Intelligence). Obwohl die Tensorisierungsmethode die algorithmische Effizienz erheblich verbessert hat, bleibt Raum für weitere Verbesserungen. Zukünftige Richtungen umfassen die Verbesserung von Kernoperatoren wie der nicht-dominierten Sortierung, das Design neuer tensorisierter Operationen für Multi-GPU-Systeme und die Integration von groß angelegten Daten und Deep-Learning-Techniken, um die Leistung bei groß angelegten Optimierungsproblemen weiter zu steigern.
Open-Source-Code / Community-Ressourcen
Paper:
https://arxiv.org/abs/2503.20286
GitHub:
https://github.com/EMI-Group/evomo
Upstream-Projekt (EvoX):
https://github.com/EMI-Group/evox
QQ-Gruppe: 297969717

EvoMO baut auf dem EvoX-Framework auf. Wenn Sie mehr über EvoX erfahren möchten, schauen Sie sich gerne den offiziellen Artikel zu EvoX 1.0 an, der auf unserem öffentlichen WeChat-Account veröffentlicht wurde, um weitere Details zu erfahren.
