
Genetic Programming ist eine evolutionäre Methode, die strukturelle Suche mit Interpretierbarkeit verbindet. Es bietet einzigartige Vorteile bei Aufgaben wie symbolischer Regression, Klassifikation und Steuerung — nicht nur durch die Optimierung von Parametern, sondern auch durch die direkte Suche nach und Erzeugung analysierbarer Programmausdrücke. Aufgrund der Heterogenität individueller Strukturen und unregelmäßiger Ausführungspfade bleiben jedoch die meisten bestehenden Genetic-Programming-Implementierungen auf CPU-basierte Ausführung beschränkt und haben lange Schwierigkeiten gehabt, sich wirklich an GPUs anzupassen. Dies schränkt die Recheneffizienz direkt ein und erschwert die Verarbeitung massiver Datensätze oder komplexer Simulationsumgebungen in modernen Anwendungen.
Um diese Herausforderung zu bewältigen, schlagen wir das EvoGP-Framework vor und reorganisieren Baumdarstellung, die Logik genetischer Operatoren und parallele Ausführungsmechanismen von Grund auf neu. Experimentelle Ergebnisse zeigen, dass EvoGP einen Spitzendurchsatz von über 10^11 GPops/s erreicht und die schnelle Auswertung von Populationen mit 500.000 Individuen innerhalb einer Sekunde ermöglicht — bis zu 304× schneller als bestehende GPU-Implementierungen. Dieser Meilenstein markiert einen definitiven Bruch mit Hardware-Anpassungsbarrieren und führt Genetic Programming in die Ära des GPU-beschleunigten Hochleistungsrechnens ein.
Die GPU-Anpassungsherausforderung in Genetic Programming
In den letzten Jahren sind GPUs dank ihres massiven Parallelismus und hohen Durchsatzes zu einer kritischen Infrastruktur für intelligentes Hochleistungsrechnen geworden. Dennoch ist es Genetic Programming bisher nicht gelungen, diesen Hardwarevorteil vollständig zu nutzen. Das zentrale Hindernis liegt im Fehlen von Darstellungs- und Ausführungsmethoden, die mit modernen Hardwarearchitekturen übereinstimmen. Das Single Instruction, Multiple Threads (SIMT)-Ausführungsmodell der GPU eignet sich hervorragend für die Verarbeitung regulärer, einheitlicher, batchfähiger Daten. Genetic-Programming-Individuen hingegen weisen erhebliche strukturelle Heterogenität auf — unterschiedliche Baumgrößen, Topologien und Auswertungslogiken. Auf der GPU werden diese Strukturen unmittelbar Probleme wie nicht-kontinuierlicher Speicherzugriff, ineffiziente dynamische Speicherallokation und starke Thread-Divergenz sichtbar.
Gleichzeitig muss ein System, um die GPU-Rechenleistung wirklich freizusetzen, sowohl Datenparallelität innerhalb einzelner Bäume als auch Individualparallelität über die Population hinweg bewältigen. Beide Modi unter einer einzigen Scheduling-Strategie zu vereinigen, das Speicherlayout zu optimieren und Ressourcenkonflikte zu vermeiden, stellt eine gewaltige Herausforderung für Systems Engineering dar. Viele frühere Implementierungen nutzten aufgrund grundlegender Designfehler nur Datenparallelität und ließen einen Großteil der parallelen Kapazität der GPU ungenutzt. EvoGP geht dieses Grundproblem an: Anstatt Genetic Programming mühsam auf GPUs laufen zu lassen, bietet es eine zweckgebundene zugrundeliegende Architektur, die Genetic Programming zu einem Rechenframework macht, das wirklich für die GPU-Ära bereit ist.
Tensorisierte Darstellung von Baumstrukturen
Um Genetic Programming in die GPU-Ära zu bringen, muss zunächst die Heterogenitätsbarriere individueller Strukturen beseitigt werden. Traditionelle zeiger- oder verkettungslistenbasierte Baumstrukturen erzeugen hochgradig unregelmäßige Speicherlayouts, die GPU-Batch-Ausführung vollständig blockieren. Zu diesem Zweck führt EvoGP eine innovative tensorisierte Darstellung ein und nutzt ein lineares Präfix-Kodierungsschema, um Baumstrukturen als zusammenhängende Arrays mit Knotentypen, Knotenwerten und Teilbaumgrößen zu kodieren.
Für Bäume unterschiedlicher Größen führt EvoGP eine maximale zulässige Längenbeschränkung ein und verwendet NaN-Werte für Padding-Ausrichtung. Durch diese Umwandlung transformiert EvoGP morphologisch unterschiedliche Individuen in einer Population erfolgreich in Tensor-Matrizen fester Form mit speicherausgerichtetem Layout. Diese Tensorisierung beseitigt den Overhead dynamischer Speicherallokation und unregelmäßiger Indizierung und stellt sicher, dass die GPU einheitlichen Speicherzugriff und hochdurchsatzfähige parallele Berechnung durchführen kann — die Grundlage dafür, dass das gesamte Framework in die GPU-Ära eintritt.
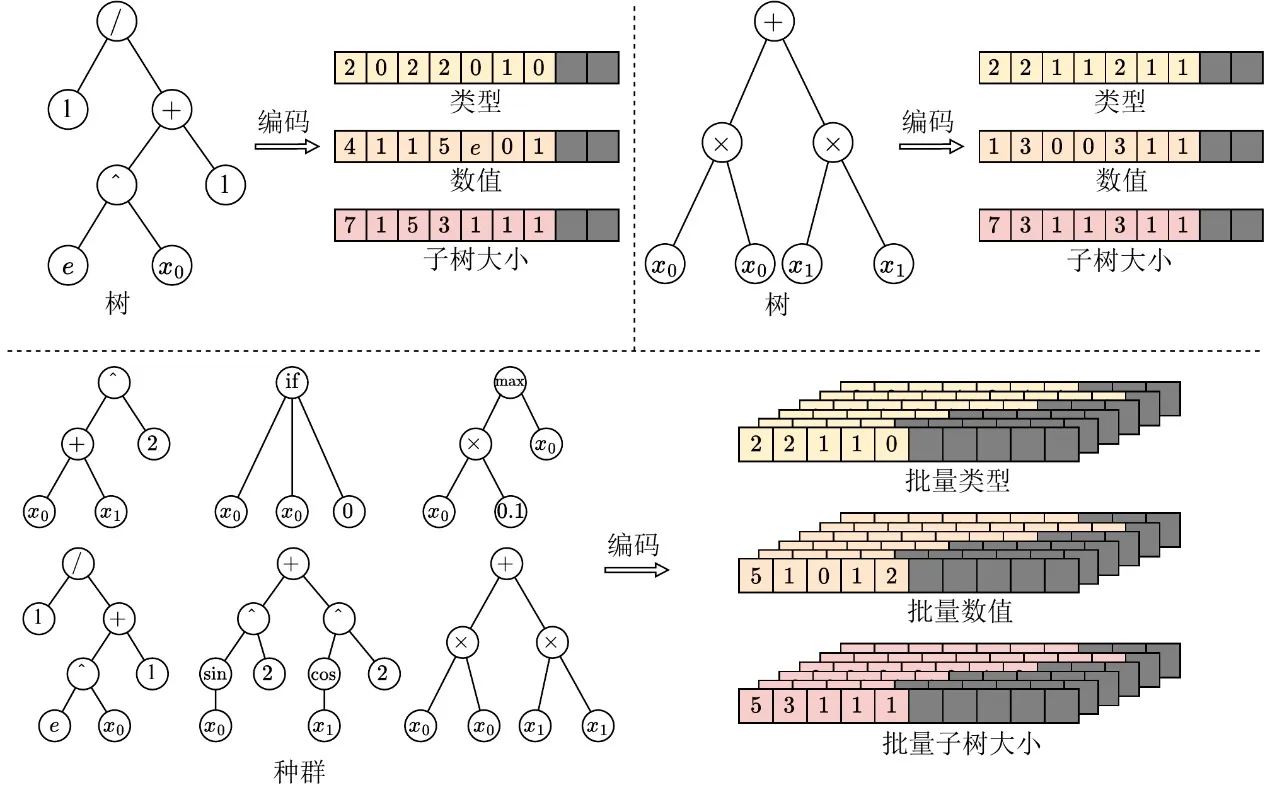
Abbildung 1: Tensorisierte Darstellung von Baumstrukturen. EvoGP kodiert Bäume in eine einheitliche Batch-Darstellung und ermöglicht so eine GPU-effiziente Verarbeitung von Programmindividuen mit unterschiedlichen Strukturen.
Einheitliche Refaktorierung genetischer Operatoren
Nach Abschluss der tensorisierten Darstellung von Baumstrukturen refaktoriert EvoGP genetische Operatoren weiter, um sie auf der untersten Ebene an die GPU-Architektur anzupassen. In traditionellen Baumdarstellungen erfordern strukturelle Änderungen wie Crossover oder Mutation typischerweise wiederholtes Sequenz-Parsing zur Bestimmung von Teilbaumgrenzen, was O(n)-Zeitkomplexität verursacht und GPU-Ausführung hochgradig ineffizient macht. Dank der explizit erhaltenen Teilbaumgrößen-Arrays in der tensorisierten Kodierung kann das System nun direkt in O(1)-Zeit auf Teilbaumgrenzen zugreifen und teures strukturelles Parsing vollständig eliminieren.
Auf dieser Grundlage extrahiert EvoGP die strukturellen Gemeinsamkeiten verschiedener baumbasierter genetischer Operatoren — wie Einpunkt-Crossover und Teilbaum-Mutation — und vereinheitlicht sie in einer einzigen zentralen Rechenprimitiven: Teilumbaustausch. Dies verwandelt komplexe strukturelle Evolution in hochreguläre Speicher-Slicing- und Tensor-Konkatenationsoperationen. Diese Refaktorierung reduziert den Kontrollfluss-Overhead bei paralleler Ausführung erheblich und macht den zentralen Evolutionsprozess von Genetic Programming zu einer Form von Berechnung, die gut zu modernem Hochdurchsatz-Hardware passt.
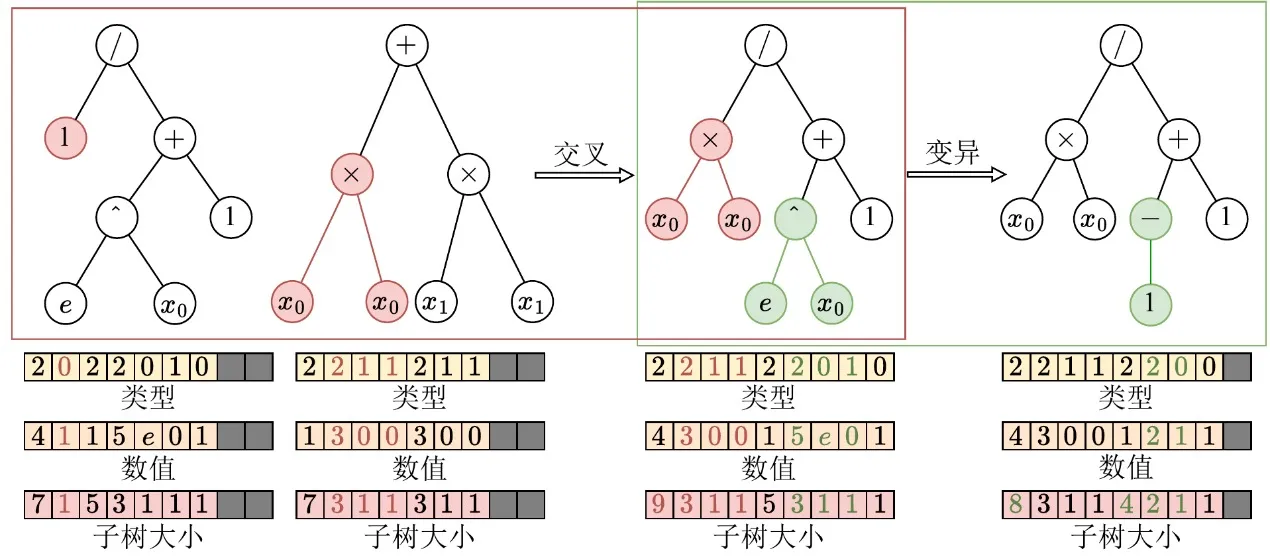
Abbildung 2: Vereinheitlichte Crossover/Mutations-Operationen. EvoGP vereinheitlicht mehrere baumbasierte genetische Operatoren unter einem einzigen zugrundeliegenden Mechanismus und macht den zentralen Evolutionsprozess besser für GPU-parallele Ausführung geeignet.
Adaptive Umschaltung paralleler Strategien
Um in der GPU-Ära zu bestehen, muss ein Algorithmus in der Lage sein, maximale Hardware-Rechenleistung zu extrahieren. Datenskalen variieren dramatisch zwischen Aufgaben, und eine einzige parallele Strategie kann keine stabile Geräteauslastung aufrechterhalten. Zu diesem Zweck entwirft und implementiert EvoGP eine adaptive parallele Strategie, die intra-individuelle und inter-individuelle Parallelität dynamisch basierend auf der Datensatzgröße kombiniert.
Bei der Verarbeitung kleiner bis mittelgroßer Datensätze verwendet das System einen hybriden Parallelmodus und kombiniert Daten- und Populationsparallelität innerhalb eines einzigen Compute-Kernels — sodass bei unzureichenden individuellen Workloads Populationsparallelität ungenutzte GPU-Kerne auslastet. Bei großskaligen Datensätzen kann eine einzelne Auswertungsaufgabe die Hardware sättigen, und das System wechselt automatisch in den rein datenparallelen Modus, startet unabhängige Compute-Kernels für die Auswertung jedes Individuums und lädt Baumstrukturen in schreibgeschützten Konstantenspeicher — wodurch Speicher-Broadcast-Effizienz maximiert und Speicherzugriffsdurchsatz deutlich verbessert wird. Dieser adaptive Mechanismus stellt sicher, dass das System über vielfältige Workloads hinweg extrem hohe Recheneffizienz aufrechterhält und bildet eine zentrale Garantie des GPU-Beschleunigungsframeworks.
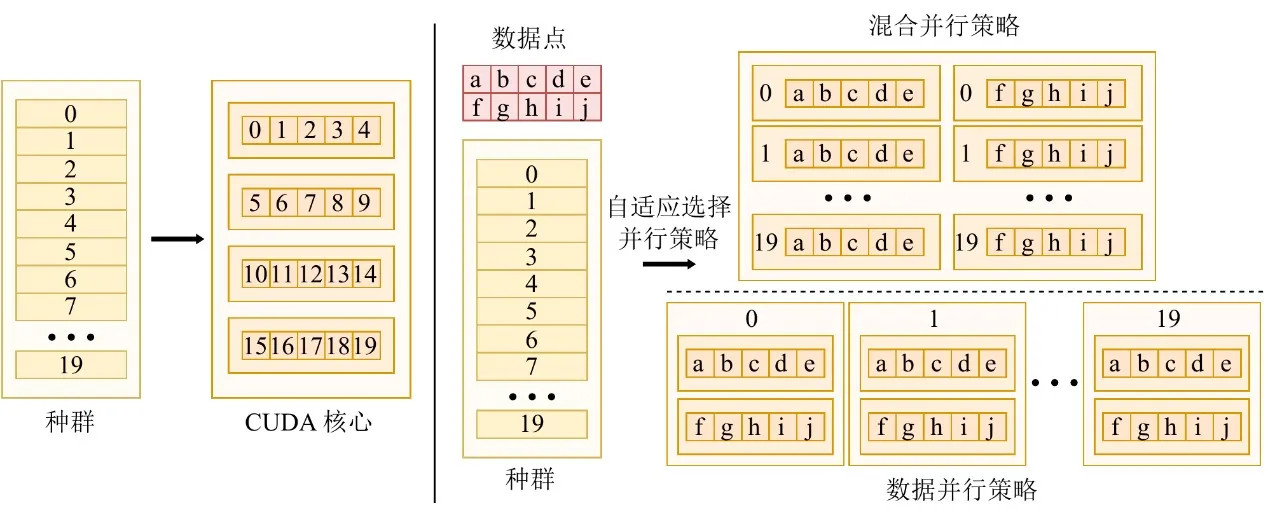
Abbildung 3: Adaptiver Parallelmechanismus. EvoGP wechselt automatisch zwischen verschiedenen Parallelmodi basierend auf der Aufgabenskala, um höhere Recheneffizienz aufrechtzuerhalten.
Hochleistung und Benutzerfreundlichkeit vereinen
Die Vitalität eines Hochleistungsrechnen-Frameworks liegt nicht nur in der zugrundeliegenden Geschwindigkeit, sondern auch in Ökosystem-Kompatibilität und Benutzerfreundlichkeit. Viele praktische Anwendungen werden in Python-basierten Ökosystemen wie OpenAI Gym, MuJoCo, Brax und Genesis eingesetzt. Während es extreme GPU-Beschleunigung verfolgt, erreicht EvoGP nahtlose Integration mit bestehenden Entwicklungsökosystemen, indem es benutzerdefinierte hochleistungsfähige CUDA-Compute-Kernels als Custom-Operatoren innerhalb der PyTorch-Runtime einbettet.
Darüber hinaus verwendet EvoGP, um GPU-Architekturvorteile voll auszuschöpfen, ein vollständig GPU-residentes Modell und stellt sicher, dass Populationsdaten und Auswertungskontexte vollständig auf der GPU verbleiben — wodurch der kostspielige Host-Device-Datentransfer-Overhead traditioneller Frameworks vollständig eliminiert wird. Diese Zero-Copy-Designphilosophie ermöglicht EvoGP eine natürliche und effiziente Integration mit modernen GPU-beschleunigten Reinforcement-Learning-Umgebungen und bietet End-to-End-effiziente parallele Simulationsfähigkeiten als vollständiges System, das extreme Leistung mit hoher Skalierbarkeit in Einklang bringt.
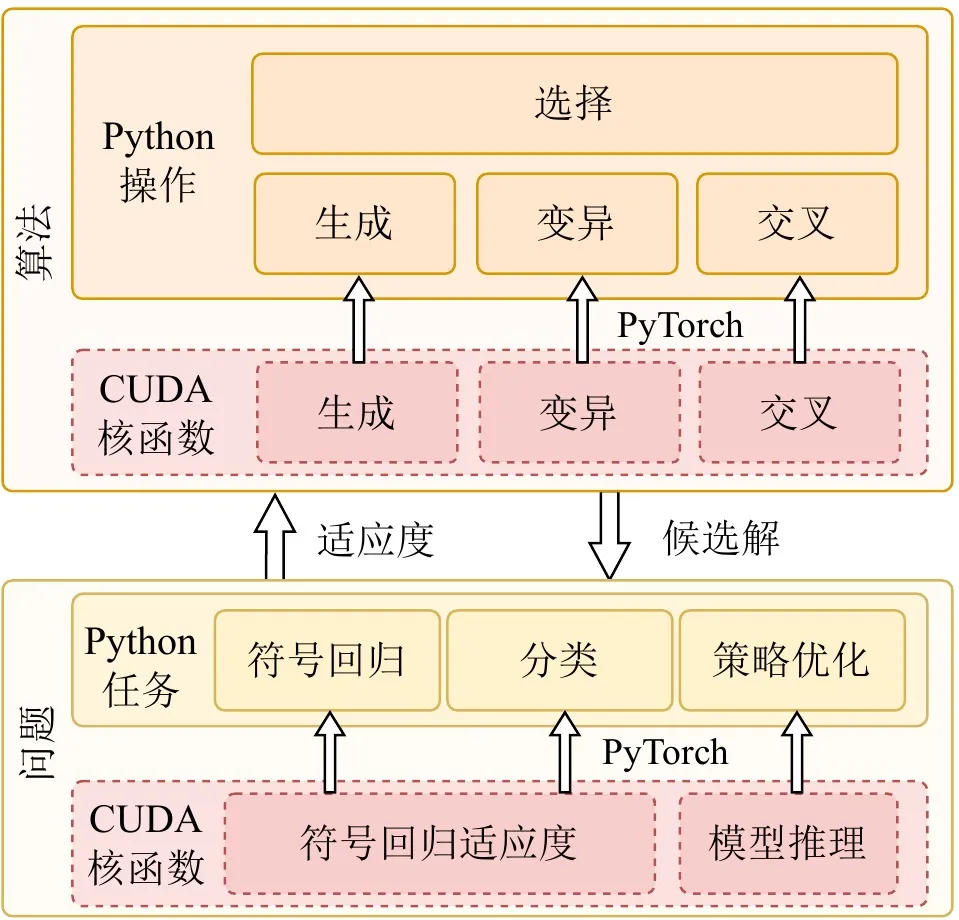
Abbildung 4: Gesamtarchitektur. EvoGP ist kein isoliertes Beschleunigungsmodul, sondern ein vollständiges Framework, das zugrundeliegende Leistung mit Benutzerfreundlichkeit der oberen Schicht in Einklang bringt.
Leistung bei großen Populationsskalen freisetzen
Das Durchbrechen von Rechenengpässen erweitert direkt die Suchgrenzen evolutionärer Algorithmen und ermöglicht es Genetic Programming, wirklich von der GPU-Ära zu profitieren. In der Vergangenheit waren ultra-große Populationseinstellungen oft unpraktikabel aufgrund prohibitiver Rechenkosten. Unter EvoGPs hochdurchsatzfähigem populationsparallelem Mechanismus ist die Verarbeitung massiver Individuenzahlen in der Praxis wirklich machbar geworden.
Kern-Benchmark-Tests zeigen, dass EvoGPs Spitzendurchsatz 10^11 GPops/s übersteigt und unter massiver Parallelität erstaunliche Geschwindigkeit demonstriert — die umfassende Auswertung von Populationen bis zu 500.000 Individuen in nur einer Sekunde. In der Laufzeit etabliert es einen entscheidenden Vorsprung gegenüber bestehenden GPU-Implementierungen. Entscheidender ist, dass der Algorithmus in großskaligen Populationstests exzellente Skalierbarkeit zeigt: bei Fehlerkonvergenz in symbolischer Regression, Verbesserung der Klassifikationsgenauigkeit und kumulierten Belohnungen in Robotersteuerungsaufgaben liefern größere Populationen durchgängig bessere Endleistung. Dies beweist, dass EvoGP nicht nur Rechengeschwindigkeit freisetzt — es ermöglicht größeren Populationen, qualitativ hochwertigere Lösungen in kürzerer Laufzeit zu erreichen und hebt grundlegend das Suchpotenzial und die Leistungsgrenze von Genetic-Programming-Methoden an.
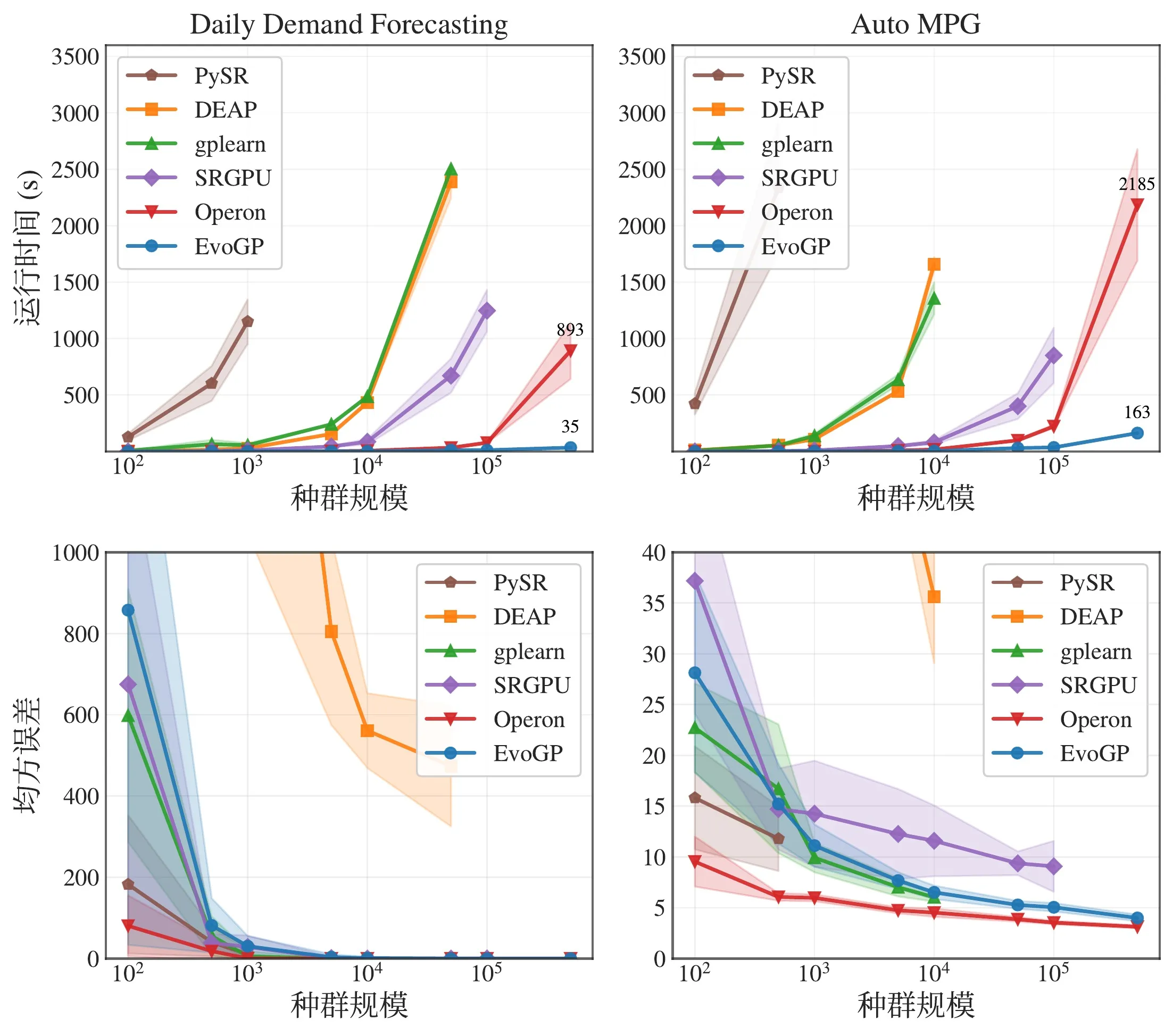
Abbildung 5: Gesamtleistungsvergleich. EvoGP erzielt signifikante Leistungsvorteile über mehrere Aufgabeneinstellungen hinweg bei stabiler Ergebnisqualität.
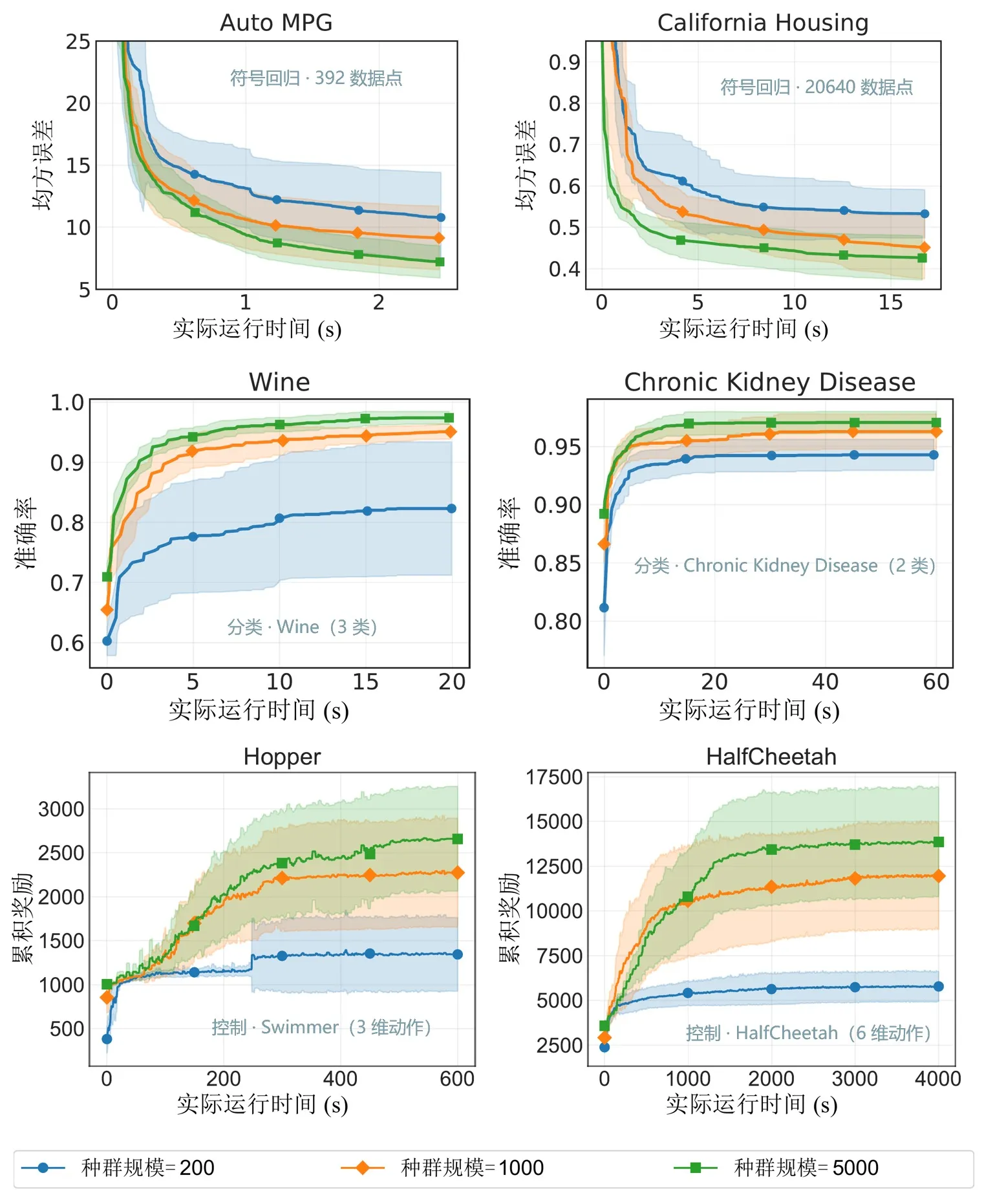
Abbildung 6: Leistung bei verschiedenen Populationsskalen. EvoGP macht größere Populationsgrößen innerhalb akzeptabler Zeit praktisch nutzbar und erschließt stärkeres Suchpotenzial.
Fazit
Das EvoGP-Framework beantwortet systematisch die Frage, wie Genetic Programming moderne GPU-Architekturen effektiv nutzen kann. Es ist kein einfacher Patch für bestehende Implementierungen, sondern erreicht fundamentale Innovationen im zugrundeliegenden Design durch tensorisierte Darstellung, Operator-Refaktorierung und adaptive Parallelität — und eröffnet vollständig den Weg für Genetic Programming in Hochleistungsrechnen-Systeme. Diese Arbeit demonstriert nicht nur die anhaltende Vitalität klassischer evolutionärer Methoden im Rechenzeitalter, sondern bietet auch eine hoch skalierbare systemweite Lösung für interpretierbares maschinelles Lernen und autonome Agenten-Entscheidungsfindung — und markiert den wahren Eintritt von Genetic Programming in die GPU-beschleunigte Ära.
Open Source / Community
📄 Paper:
https://ieeexplore.ieee.org/document/11390710
🔗 GitHub:
https://github.com/EMI-Group/evogp
🔼 Upstream Project (EvoX):
https://github.com/EMI-Group/evox
🌐 QQ Group: 297969717

QQ Group | Evolutionary Machine Intelligence