텐서화를 통한 진화 다목적 최적화와 GPU 가속의 연결
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun, 및 Ran Cheng, Senior Member, IEEE
엔지니어링 설계 및 에너지 관리와 같은 도메인 전반에 걸쳐 복잡한 최적화 솔루션에 대한 수요가 지속적으로 증가함에 따라, 진화 다목적 최적화(Evolutionary Multiobjective Optimization, EMO) 알고리즘은 다목적 문제를 해결하는 강력한 능력으로 인해 폭넓은 주목을 받고 있습니다. 그러나 최적화 작업의 규모와 복잡성이 증가함에 따라, 기존의 CPU 기반 EMO 알고리즘은 심각한 성능 병목 현상에 직면하고 있습니다.
이러한 한계를 해결하기 위해 EvoX 팀은 텐서화(tensorization) 방법론을 통해 GPU에서 EMO 알고리즘을 병렬화할 것을 제안했습니다. 이 방법을 활용하여 팀은 여러 GPU 가속 EMO 알고리즘을 성공적으로 설계하고 구현했습니다. 또한, 팀은 Brax 물리 엔진을 기반으로 구축된 다목적 로봇 제어를 위한 벤치마크 제품군인 **“MoRobtrol”**을 개발하여 GPU 가속 EMO 알고리즘의 성능을 체계적으로 평가하는 것을 목표로 하고 있습니다.
이러한 연구 성과를 바탕으로 EvoX 팀은 고성능 GPU 가속 EMO 알고리즘 라이브러리인 EvoMO를 출시했습니다. 해당 소스 코드는 GitHub에 공개되어 있습니다: https://github.com/EMl-Group/evomo
텐서화(Tensorization) 방법론
계산 최적화 분야에서 **텐서(tensor)**는 스칼라, 벡터, 행렬 및 고차원 데이터를 표현할 수 있는 다차원 배열 데이터 구조를 의미합니다. **텐서화(Tensorization)**는 알고리즘 내의 데이터 구조와 연산을 텐서 형태로 변환하여 알고리즘이 GPU의 병렬 컴퓨팅 기능을 완전히 활용할 수 있도록 하는 과정입니다.
EMO 알고리즘에서 모든 핵심 데이터 구조는 텐서화된 형식으로 표현될 수 있습니다. 개체군(population) 내의 개체들은 해(solution) 텐서 X로 표현될 수 있으며, 여기서 각 행 벡터는 하나의 개체에 해당합니다. 목적 함수 값들은 목적 텐서 F를 형성합니다. 또한, 참조 벡터(reference vectors)와 가중치 벡터(weight vectors) 같은 보조 데이터 구조는 각각 텐서 R과 W로 표현될 수 있습니다. 이러한 통합된 텐서 표현은 표현 수준에서 개체군 단위의 연산을 가능하게 하여 대규모 병렬 계산을 위한 견고한 기반을 마련합니다.
EMO 알고리즘 연산의 텐서화는 계산 효율성을 높이는 데 중요하며, 기본 텐서 연산과 제어 흐름 텐서화의 두 계층으로 나눌 수 있습니다. 기본 텐서 연산은 표 I에 자세히 설명된 바와 같이 EMO 알고리즘의 텐서화 구현의 핵심을 구성합니다.
표 I: 기본 텐서 연산

제어 흐름 텐서화는 기존의 루프 및 조건부 로직을 병렬화 가능한 텐서 연산으로 대체합니다. 예를 들어, for/while 루프는 브로드캐스팅(broadcasting) 메커니즘이나 vmap과 같은 고차 함수를 사용하여 배치(batched) 연산으로 변환될 수 있습니다. 마찬가지로, if-else 조건문은 마스킹(masking) 기법으로 대체될 수 있는데, 여기서 논리적 조건은 불리언(Boolean) 텐서로 인코딩되어 서로 다른 계산 경로 간의 유연한 전환을 가능하게 합니다.
기존의 EMO 알고리즘 구현과 비교할 때, 텐서화 접근 방식은 상당한 이점을 제공합니다. 첫째, 기존 방식이 종종 2차원 행렬 연산에 제한되는 반면, 텐서화는 다차원 데이터를 자연스럽게 처리하여 더 큰 유연성을 제공합니다. 둘째, 텐서화는 병렬 실행을 통해 계산 효율성을 크게 향상시켜 명시적인 루프 및 조건부 분기와 관련된 오버헤드를 방지합니다. 마지막으로, 코드 구조를 단순화하여 더 간결하고 유지 관리하기 쉬운 프로그램을 만듭니다.
예를 들어 그림 1에서 볼 수 있듯이, 파레토 지배(Pareto dominance) 확인의 기존 구현은 요소별 비교를 수행하기 위해 중첩 루프에 의존합니다. 반면, 텐서화된 버전은 브로드캐스팅 및 마스킹 연산을 통해 동일한 기능을 수행하여 병렬 평가를 가능하게 합니다. 이는 코드 복잡성을 줄일 뿐만 아니라 런타임 성능을 획기적으로 향상시킵니다.

그림 1: 파레토 지배 감지의 기존 구현과 텐서 기반 구현 간의 비교.
더 깊은 관점에서 볼 때, 텐서화는 GPU 가속에 매우 적합합니다. GPU는 수많은 병렬 코어를 보유하고 있으며, SIMT(Single-Instruction Multiple-Thread) 아키텍처가 텐서 계산, 특히 행렬 연산에 탁월하기 때문입니다. NVIDIA의 Tensor Cores와 같은 전용 하드웨어는 텐서 연산의 처리량을 더욱 향상시킵니다. 일반적으로 높은 병렬성을 보이고, 독립적인 계산 작업을 포함하며, 조건부 분기가 최소화된 알고리즘이 텐서화에 더 적합합니다. 순차적 의존성을 포함하는 MOEA/D와 같은 알고리즘의 경우, 고유한 구조로 인해 직접적인 텐서화에 어려움이 있습니다. 그러나 구조적 리팩토링과 핵심 계산의 분리(decoupling)를 통해 효과적인 병렬 가속을 달성하는 것이 여전히 가능합니다.
알고리즘 텐서화의 적용 사례
텐서화된 표현 방법론을 바탕으로 EvoX 팀은 세 가지 고전적인 EMO 알고리즘의 텐서화 버전을 설계하고 구현했습니다: 지배 기반의 NSGA-III, 분해 기반의 MOEA/D, 그리고 지표 기반의 HypE입니다. 다음 섹션에서는 MOEA/D를 예로 들어 자세히 설명합니다. NSGA-III와 HypE의 텐서화 구현은 참조된 논문에서 확인할 수 있습니다.
그림 2에서 볼 수 있듯이, 기존의 MOEA/D는 다목적 문제를 여러 하위 문제로 분해하여 각각 독립적으로 최적화합니다. 이 알고리즘은 교차(crossover) 및 변이(mutation), 적합도 평가, 이상점(ideal point) 업데이트, 이웃(neighborhood) 업데이트의 네 가지 핵심 단계로 구성됩니다. 이러한 단계들은 단일 루프 내에서 각 개체에 대해 순차적으로 실행됩니다. 이러한 순차적 처리는 대규모 개체군을 다룰 때 상당한 계산 오버헤드를 초래하는데, 각 개체가 모든 단계를 순서대로 완료해야 하므로 GPU 가속의 잠재적 이점이 제한되기 때문입니다. 특히 이웃 업데이트는 개체 간의 상호 작용에 의존하므로 병렬화를 더욱 복잡하게 만듭니다.

그림 2: MOEA/D의 의사코드(Pseudocode)
기존 MOEA/D의 순차적 의존성 문제를 해결하기 위해 팀은 환경 선택의 내부 루프 내에 텐서화된 표현 방식을 도입했습니다. 교차 및 변이, 적합도 평가, 이상점 업데이트, 이웃 업데이트를 분리(decoupling)함으로써 이러한 구성 요소들을 독립적인 연산으로 처리합니다. 이를 통해 모든 개체의 병렬 처리가 가능해져 TensorMOEA/D라고 불리는 텐서화된 MOEA/D 알고리즘을 구축할 수 있었습니다. 이 알고리즘에서 환경 선택은 비교 및 개체군 업데이트와 엘리트 솔루션 선택의 두 가지 주요 단계로 나뉩니다. 이 두 단계는 주로 두 번의 vmap 연산 적용을 통해 텐서화됩니다. 자세한 과정은 그림 3에 나와 있습니다.
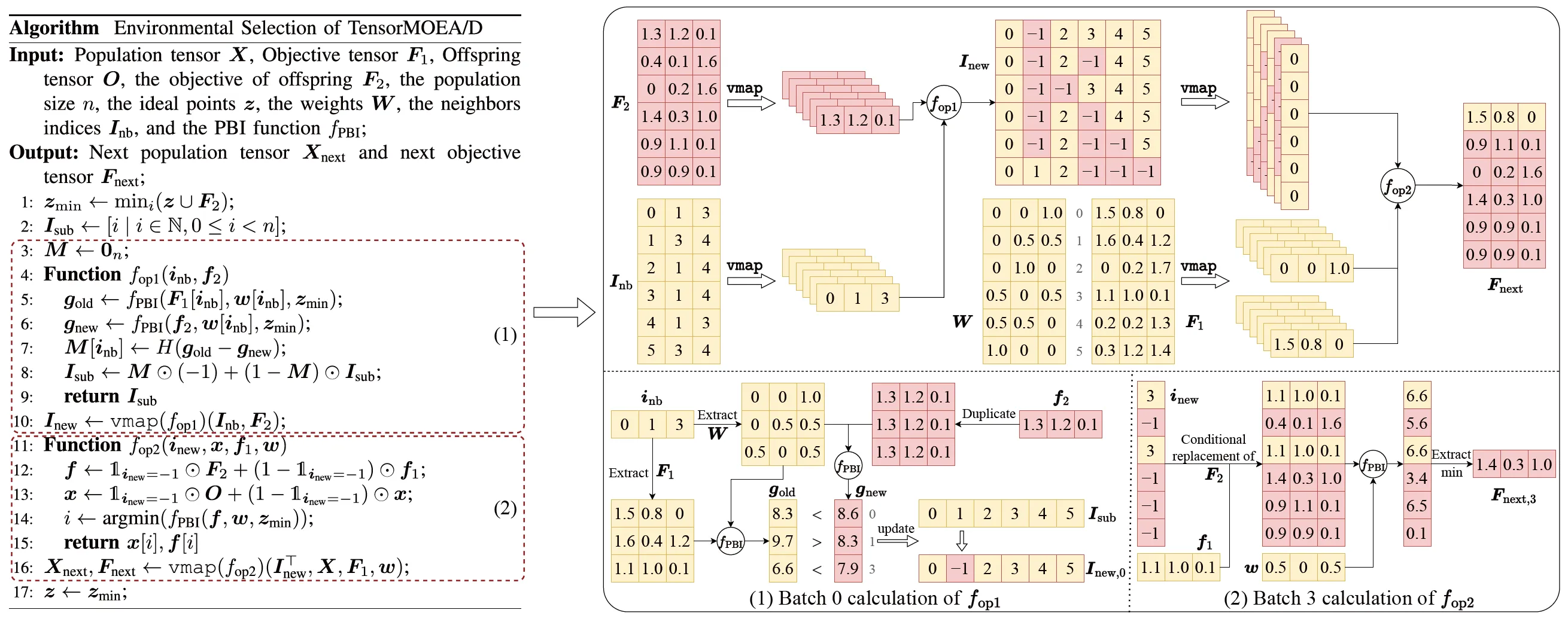

그림 3: TensorMOEA/D 알고리즘의 환경 선택 개요. 좌측: 알고리즘의 의사코드. 우측: 모듈 (1)과 모듈 (2)의 텐서 데이터 흐름. 우측 그림의 상단 부분은 모듈 (1)과 (2)의 전체 텐서 데이터 흐름을 보여주며, 하단 부분은 배치 계산 텐서 데이터 흐름을 나타냅니다(좌측이 모듈 (1), 우측이 모듈 (2)).
EMO 알고리즘에서 텐서화의 가치를 보다 포괄적으로 이해하기 위해 세 가지 관점에서 요약할 수 있습니다. 첫째, 텐서화는 수학적 공식에서 효율적인 코드로의 직접적인 변환을 가능하게 하여 알고리즘 설계와 구현 사이의 격차를 좁힙니다. 예를 들어, 그림 4는 텐서화된 비지배 정렬(non-dominated sorting) 절차가 의사코드에서 Python 코드로 어떻게 직접 변환될 수 있는지 보여줍니다. 둘째, 텐서화는 개체군 수준의 연산을 단일 텐서 표현으로 통합하여 코드 구조를 크게 단순화합니다. 이는 루프와 조건문에 대한 의존도를 줄여 코드 가독성과 유지 보수성을 향상시킵니다. 셋째, 텐서화는 알고리즘의 재현성을 높입니다. 구조화된 표현은 비교 테스트와 결과의 일관된 재현을 용이하게 합니다.

그림 4: 텐서화된 비지배 정렬이 의사코드(좌측)에서 Python 코드(우측)로 매끄럽게 변환되는 과정.
성능 시연
GPU 가속 다목적 최적화 알고리즘의 성능을 평가하기 위해 EvoX 팀은 계산 가속, 수치 최적화 성능, 다목적 로봇 제어 작업에서의 효율성에 초점을 맞춰 세 가지 범주의 실험을 체계적으로 수행했습니다.
계산 가속 성능:
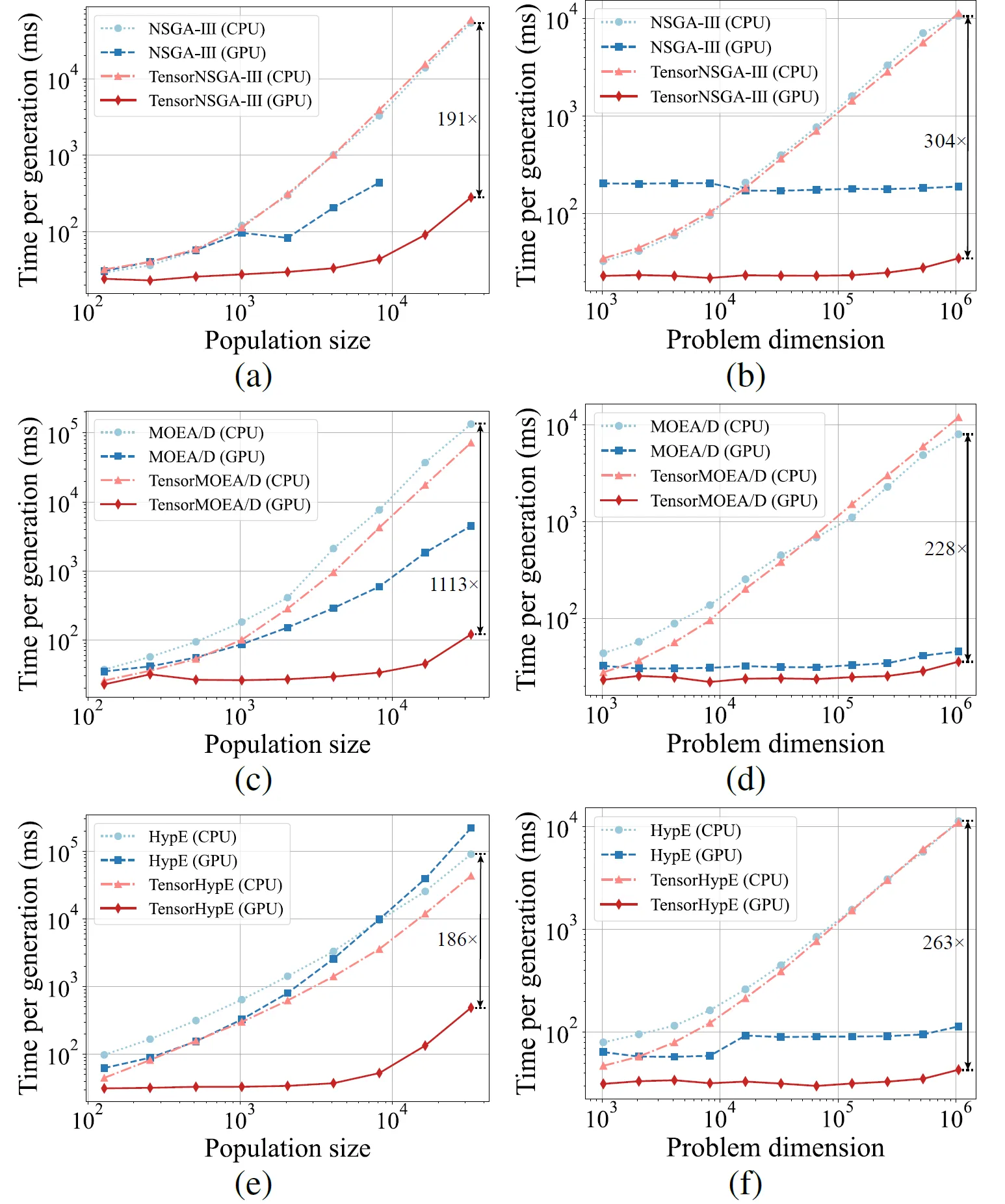
그림 5: 다양한 개체군 크기 및 문제 차원에 따른 CPU 및 GPU 플랫폼에서의 NSGA-III, MOEA/D, HypE와 텐서화된 버전의 가속 성능 비교.
실험 결과에 따르면 TensorNSGA-III, TensorMOEA/D, TensorHypE는 텐서화되지 않은 CPU 기반 대응 알고리즘에 비해 GPU에서 훨씬 더 높은 실행 속도를 달성했습니다. 개체군 크기와 문제 차원이 증가함에 따라 관찰된 최대 속도 향상은 1113배에 달했습니다. 텐서화된 알고리즘은 대규모 계산 작업을 처리할 때 뛰어난 확장성과 안정성을 보여주었습니다. 런타임은 아주 조금만 증가하면서도 일관되게 높은 성능을 유지했습니다. 이러한 결과는 다목적 최적화의 GPU 가속을 위한 텐서화의 상당한 이점을 강조합니다.
LSMOP 테스트 제품군에서의 성능:
표 II: LSMOP1—LSMOP9에서 비텐서화 및 텐서화된 EMO 알고리즘의 IGD 및 실행 시간(초)에 대한 통계 결과(평균 및 표준 편차). 모든 실험은 RTX 4090 GPU에서 수행되었으며 최상의 결과는 강조 표시됨.
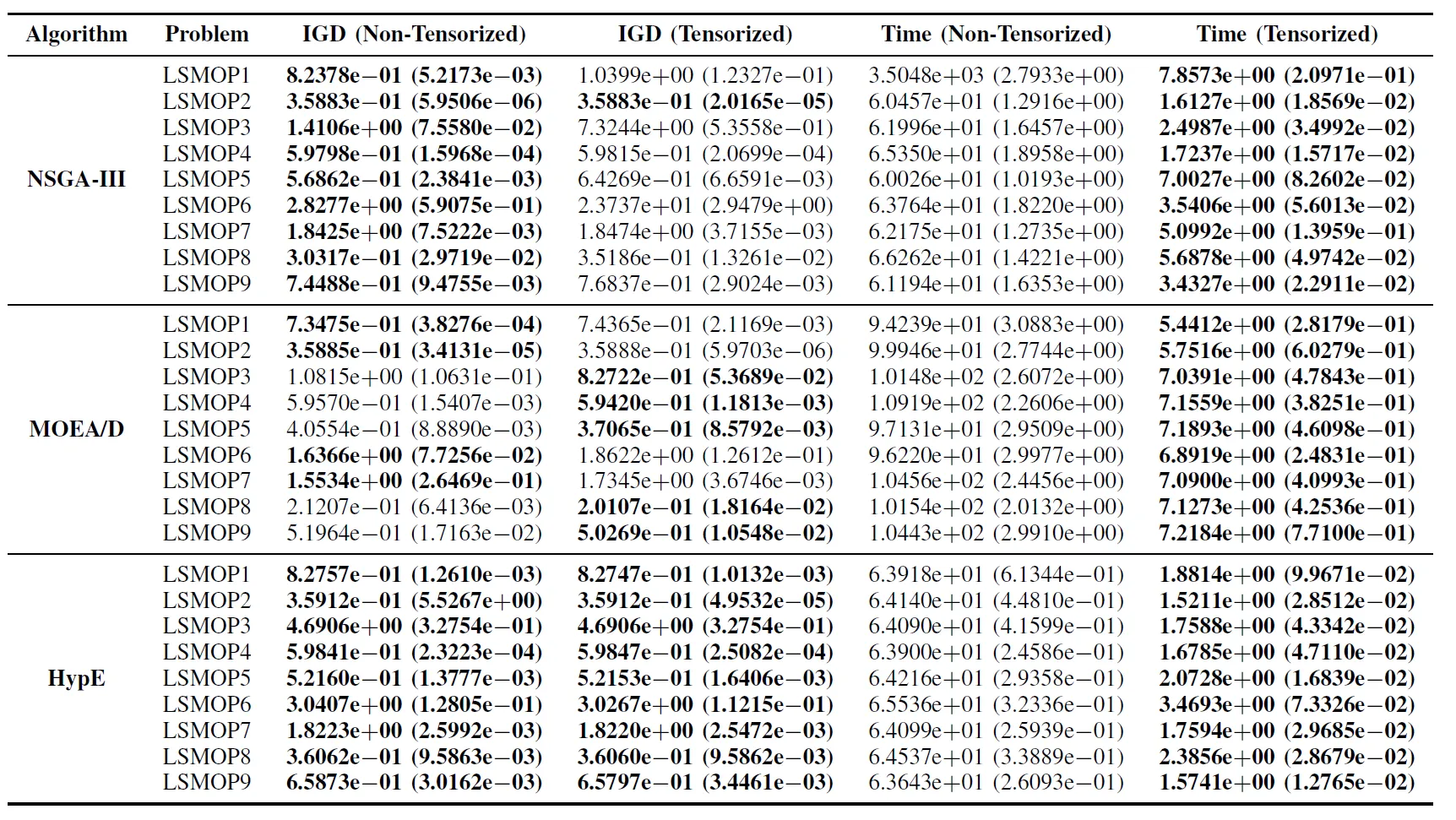
실험 결과는 텐서화된 표현을 기반으로 하는 GPU 가속 EMO 알고리즘이 계산 효율성을 크게 향상시키면서도 원래 알고리즘의 최적화 정확도를 유지하거나 경우에 따라서는 능가함을 나타냅니다.
다목적 로봇 제어 작업:
GPU 가속 EMO 알고리즘의 실제 성능을 종합적으로 평가하기 위해 팀은 다목적 로봇 제어를 위한 MoRobtrol이라는 벤치마크 제품군을 개발했습니다. 이 제품군에 포함된 작업은 표 III에 나열되어 있습니다.
표 III: 제안된 MoRobtrol 벤치마크 테스트 제품군의 다목적 로봇 제어 문제 개요
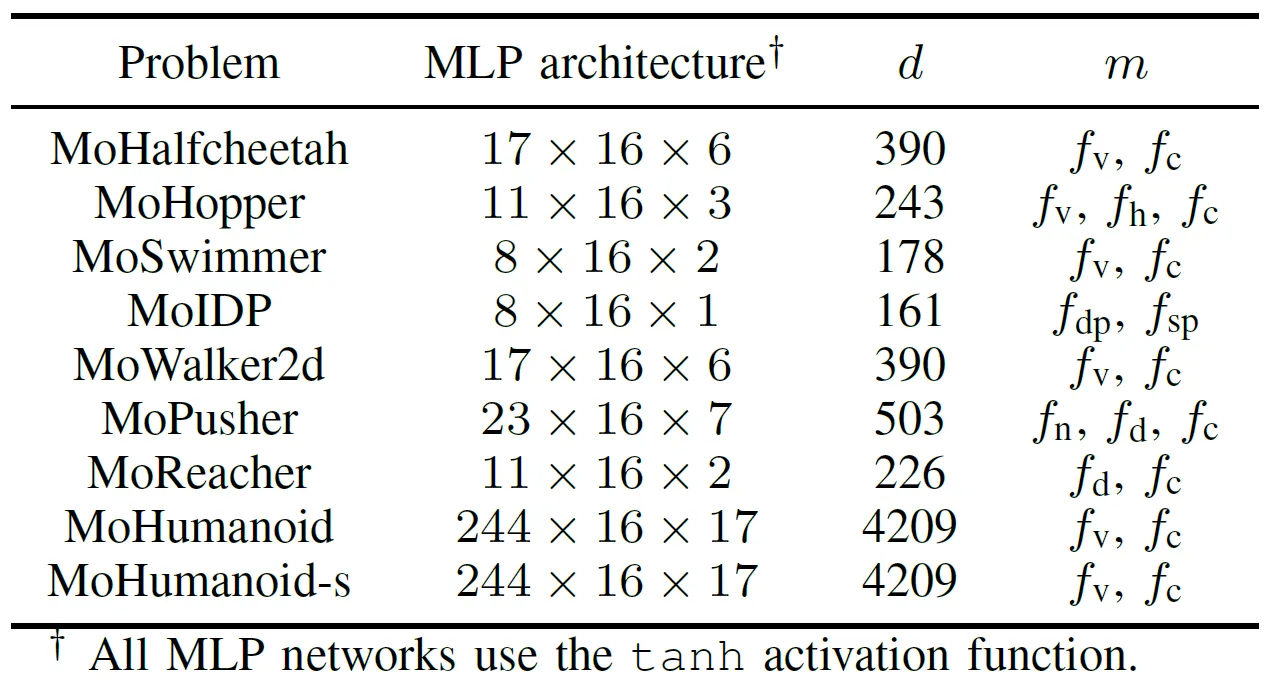
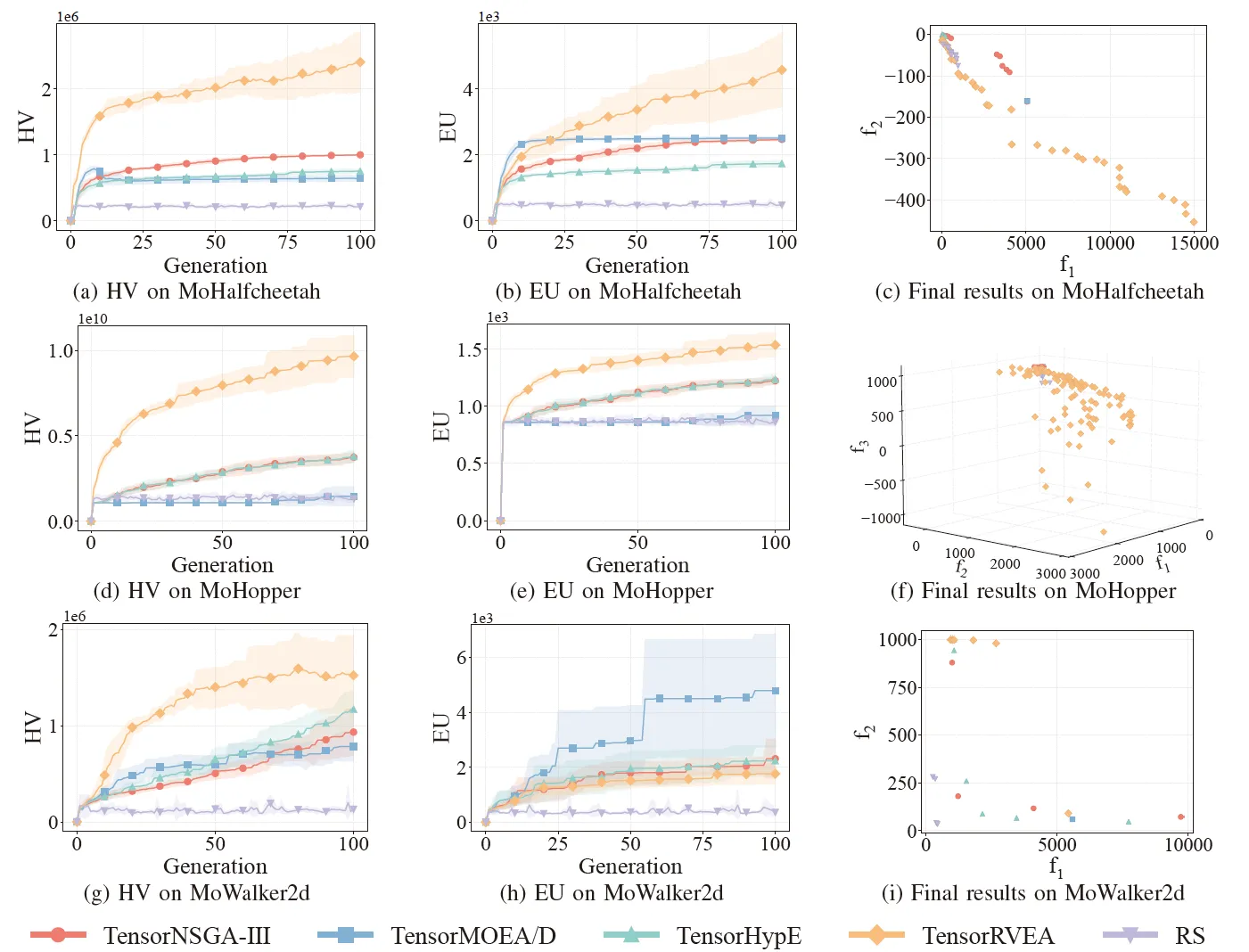
그림 6: 다양한 문제(MoHalfcheetah (390D), MoHopper (243D), MoWalker2d (390D))에 대한 TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA 및 무작위 탐색(RS)의 비교 성능(HV, EU 및 최종 결과 시각화). 참고: 모든 지표에서 값이 높을수록 성능이 우수함을 나타냄.
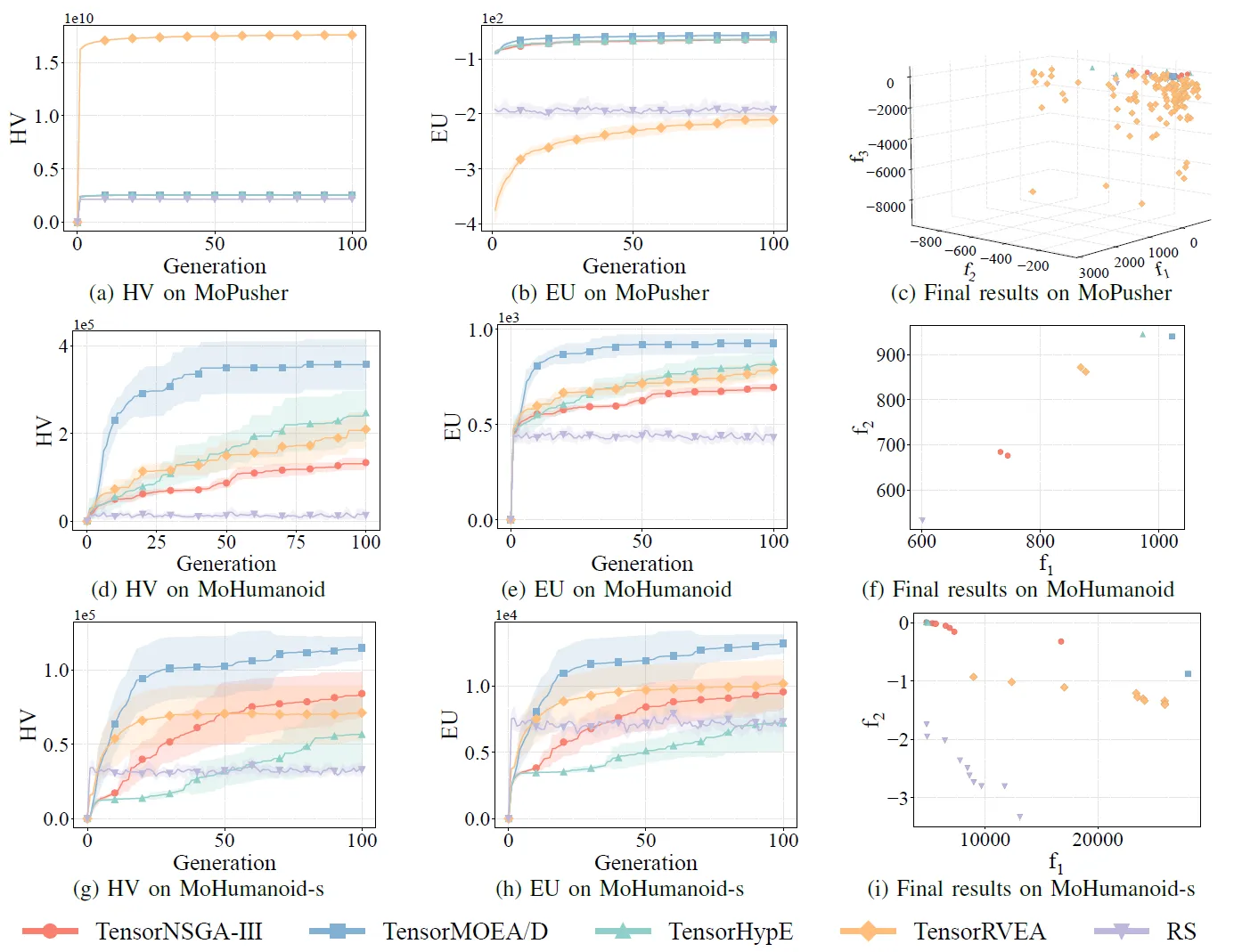
그림 7: 다양한 문제(MoPusher (503D), MoHumanoid (4209D), MoHumanoid-s (4209D))에 대한 TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA 및 무작위 탐색(RS)의 비교 성능(HV, EU 및 최종 결과 시각화). 참고: 모든 지표에서 값이 높을수록 성능이 우수함을 나타냄.
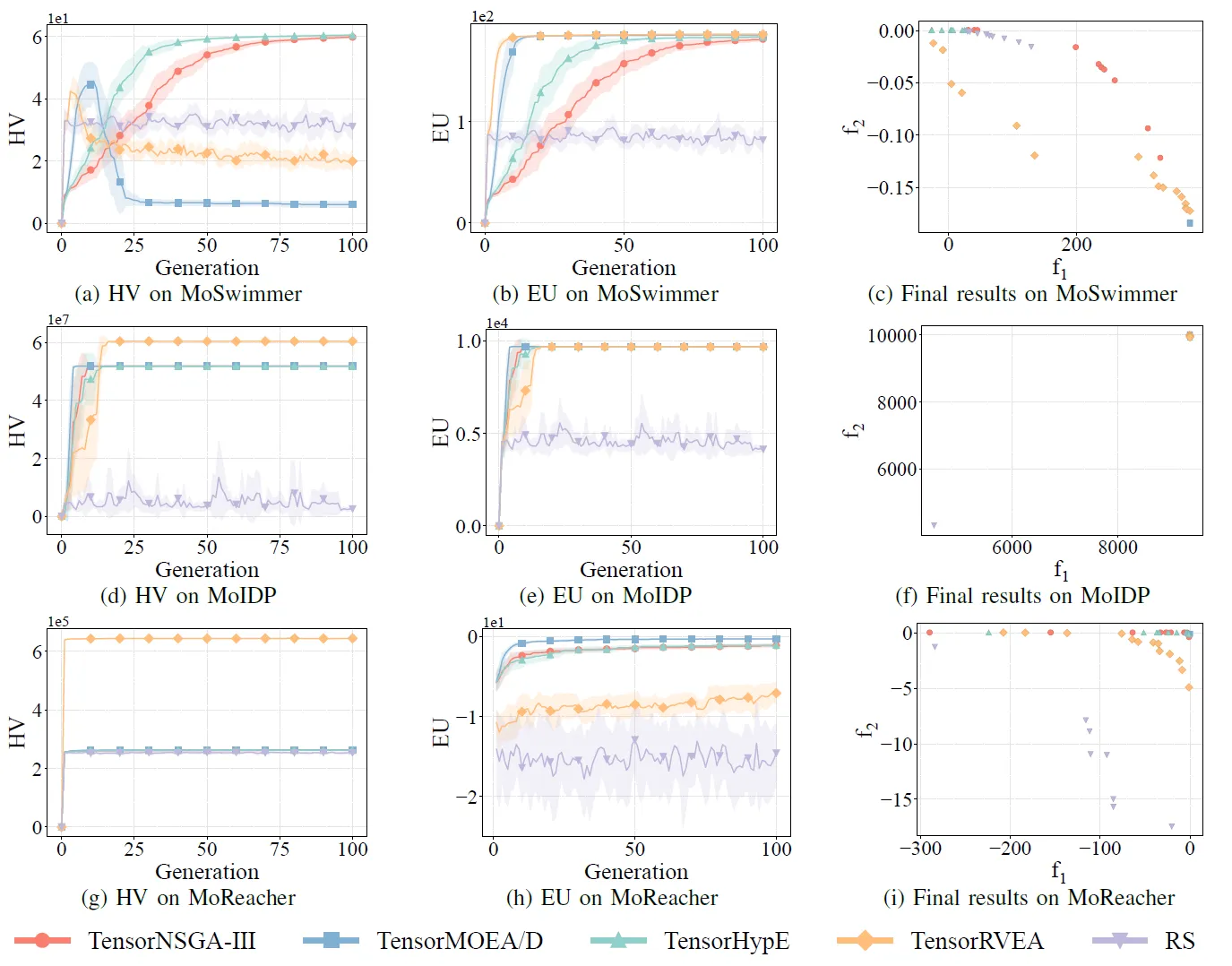
그림 8: 다양한 문제(MoSwimmer (178D), MoIDP (161D), MoReacher (226D))에 대한 TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA 및 무작위 탐색(RS)의 비교 성능(HV, EU 및 최종 결과 시각화). 참고: 모든 지표에서 값이 높을수록 성능이 우수함을 나타냄.
실험에서는 MoRobtrol 벤치마크 내에서 TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA 및 무작위 탐색(RS)의 성능을 비교했습니다. 결과에 따르면 TensorRVEA가 가장 높은 HV 값을 얻고 여러 환경에서 우수한 해의 다양성을 보여주며 전반적으로 최고의 성능을 달성했습니다. TensorMOEA/D는 대규모 작업에서 강력한 적응성을 보였으며, 특히 해의 선호도 일관성(preference consistency)에서 탁월했습니다. TensorNSGA-III와 TensorHypE는 유사한 성능을 보였으며 여러 작업에서 경쟁력을 갖추었습니다. 전반적으로 텐서화된 분해 기반 알고리즘은 대규모 및 복잡한 문제를 해결하는 데 있어 우수한 이점을 보여주었습니다.
결론 및 향후 연구
이 연구는 계산 효율성과 확장성 측면에서 기존 CPU 기반 EMO 알고리즘의 한계를 해결하기 위해 텐서화된 표현 방법론을 제안합니다. 이 접근 방식은 NSGA-III, MOEA/D, HypE를 포함한 여러 대표적인 알고리즘에 적용되어 해의 품질을 유지하면서 GPU에서 상당한 성능 향상을 달성했습니다. 실제 적용 가능성을 검증하기 위해 팀은 물리 시뮬레이션 환경의 로봇 제어 작업을 다목적 최적화 문제로 재구성한 다목적 로봇 제어 벤치마크 제품군인 MoRobtrol도 개발했습니다. 결과는 체화된 지능(embodied intelligence)과 같이 계산 집약적인 시나리오에서 텐서화된 알고리즘의 잠재력을 보여줍니다. 텐서화 방법이 알고리즘 효율성을 크게 향상시켰지만, 여전히 개선의 여지가 있습니다. 향후 방향에는 비지배 정렬과 같은 핵심 연산자 개선, 멀티 GPU 시스템을 위한 새로운 텐서화 연산 설계, 대규모 최적화 문제에서의 성능을 더욱 향상시키기 위한 대규모 데이터 및 딥러닝 기술의 통합이 포함됩니다.
오픈 소스 코드 / 커뮤니티 리소스
논문:
https://arxiv.org/abs/2503.20286
GitHub:
https://github.com/EMI-Group/evomo
업스트림 프로젝트 (EvoX):
https://github.com/EMI-Group/evox
QQ 그룹: 297969717

EvoMO는 EvoX 프레임워크를 기반으로 구축되었습니다. EvoX에 대해 더 알고 싶으시다면, 자세한 내용을 위해 WeChat 공식 계정에 게시된 EvoX 1.0 공식 기사를 확인해 주시기 바랍니다.
