Cerrando la brecha entre la Optimización Multiobjetivo Evolutiva y la aceleración por GPU mediante la tensorización
Zhenyu Liang, Hao Li, Naiwei Yu, Kebin Sun y Ran Cheng, Senior Member, IEEE
Con el continuo aumento en la demanda de soluciones de optimización complejas en dominios como el diseño de ingeniería y la gestión de energía, los algoritmos de optimización multiobjetivo evolutiva (EMO) han captado una atención generalizada debido a sus robustas capacidades para resolver problemas multiobjetivo. Sin embargo, a medida que las tareas de optimización crecen en escala y complejidad, los algoritmos EMO tradicionales basados en CPU enfrentan cuellos de botella de rendimiento significativos.
Para abordar esta limitación, el equipo de EvoX propuso paralelizar los algoritmos EMO en GPUs a través de la metodología de tensorización. Aprovechando este método, han diseñado e implementado con éxito varios algoritmos EMO acelerados por GPU. Además, el equipo desarrolló “MoRobtrol”, una suite de pruebas para el control robótico multiobjetivo construida sobre el motor de física Brax, destinada a evaluar sistemáticamente el rendimiento de los algoritmos EMO acelerados por GPU.
Basándose en estos avances de investigación, el equipo de EvoX ha lanzado EvoMO, una librería de algoritmos EMO de alto rendimiento acelerada por GPU. El código fuente correspondiente está disponible públicamente en GitHub: https://github.com/EMl-Group/evomo
Metodología de Tensorización
En el campo de la optimización computacional, un tensor se refiere a una estructura de datos de arreglo multidimensional capaz de representar escalares, vectores, matrices y datos de orden superior. La tensorización es el proceso de convertir las estructuras de datos y las operaciones dentro de un algoritmo a un formato tensorial, permitiendo que el algoritmo aproveche plenamente las capacidades de cómputo paralelo de las GPUs.
En los algoritmos EMO, todas las estructuras de datos clave pueden expresarse en un formato tensorizado. Los individuos de una población pueden representarse mediante un tensor de soluciones X, donde cada vector fila corresponde a un individuo. Los valores de la función objetivo forman un tensor de objetivos F. Además, las estructuras de datos auxiliares, como los vectores de referencia y los vectores de peso, pueden expresarse como tensores R y W, respectivamente. Esta representación tensorial unificada permite realizar operaciones a nivel de población en el nivel de representación, sentando una base sólida para el cómputo paralelo a gran escala.
La tensorización de las operaciones de los algoritmos EMO es crucial para mejorar la eficiencia computacional y puede dividirse en dos capas: operaciones tensoriales básicas y tensorización del flujo de control. Las operaciones tensoriales básicas constituyen el núcleo de la implementación tensorizada de los algoritmos EMO, como se detalla en la Tabla I.
Tabla I: Operaciones Tensoriales Básicas

La tensorización del flujo de control reemplaza la lógica tradicional de bucles y condiciones con operaciones tensoriales paralelizables. Por ejemplo, los bucles for/while pueden transformarse en operaciones por lotes utilizando mecanismos de broadcasting o funciones de orden superior como vmap. Del mismo modo, los condicionales if-else pueden reemplazarse por técnicas de enmascaramiento (masking), donde las condiciones lógicas se codifican como tensores booleanos, permitiendo un cambio flexible entre diferentes rutas de computación.
En comparación con las implementaciones tradicionales de algoritmos EMO, el enfoque de tensorización ofrece ventajas significativas. Primero, proporciona una mayor flexibilidad, manejando naturalmente datos multidimensionales, mientras que los métodos convencionales a menudo se limitan a operaciones de matrices bidimensionales. Segundo, la tensorización mejora significativamente la eficiencia computacional mediante la ejecución paralela, evitando la sobrecarga asociada con bucles explícitos y ramificaciones condicionales. Por último, simplifica la estructura del código, lo que resulta en programas más concisos y fáciles de mantener.
Como se ilustra en la Fig. 1, por ejemplo, la implementación tradicional de la verificación de dominancia de Pareto depende de bucles anidados para realizar comparaciones elemento por elemento. En contraste, la versión tensorizada logra la misma funcionalidad a través de operaciones de broadcasting y enmascaramiento, permitiendo una evaluación paralela. Esto no solo reduce la complejidad del código, sino que también mejora drásticamente el rendimiento en tiempo de ejecución.

Fig. 1: Comparación entre las implementaciones convencionales y basadas en tensores de la detección de dominancia de Pareto.
Desde una perspectiva más profunda, la tensorización es muy adecuada para la aceleración por GPU porque las GPUs poseen una gran cantidad de núcleos paralelos, y su arquitectura de instrucción única y múltiples hilos (SIMT) se alinea naturalmente con los cálculos tensoriales, destacando particularmente en las operaciones de matrices. El hardware dedicado, como los Tensor Cores de NVIDIA, mejora aún más el rendimiento de las operaciones tensoriales. En general, los algoritmos que exhiben un alto paralelismo, contienen tareas computacionales independientes y tienen una ramificación condicional mínima son más propensos a la tensorización. Para algoritmos como MOEA/D, que involucran dependencias secuenciales, la estructura inherente plantea desafíos para la tensorización directa. Sin embargo, a través de la refactorización estructural y el desacoplamiento de cálculos críticos, aún es posible lograr una aceleración paralela efectiva.
Ejemplo de Aplicación de Tensorización de Algoritmos
Basándose en la metodología de representación tensorizada, el equipo de EvoX ha diseñado e implementado versiones tensorizadas de tres algoritmos EMO clásicos: NSGA-III basado en dominancia, MOEA/D basado en descomposición y HypE basado en indicadores. La siguiente sección proporciona una explicación detallada utilizando MOEA/D como ejemplo. Las implementaciones tensorizadas de NSGA-III y HypE se pueden encontrar en el artículo de referencia.
Como se ilustra en la Fig. 2, el MOEA/D tradicional descompone un problema multiobjetivo en múltiples subproblemas, cada uno de los cuales se optimiza de forma independiente. El algoritmo consta de cuatro pasos principales: cruce y mutación, evaluación de aptitud (fitness), actualización del punto ideal y actualización del vecindario. Estos pasos se ejecutan secuencialmente para cada individuo dentro de un solo bucle. Este procesamiento secuencial genera una sobrecarga computacional sustancial cuando se trata de poblaciones grandes, ya que cada individuo debe completar todos los pasos en orden, lo que limita los beneficios potenciales de la aceleración por GPU. En particular, la actualización del vecindario depende de las interacciones entre individuos, lo que complica aún más la paralelización.

Fig. 2: Pseudocódigo de MOEA/D
Para abordar el problema de las dependencias secuenciales en el MOEA/D tradicional, el equipo introdujo un método de representación tensorizada dentro del bucle interno de selección ambiental. Al desacoplar el cruce y la mutación, la evaluación de aptitud, la actualización del punto ideal y la actualización del vecindario, estos componentes se tratan como operaciones independientes. Esto permite el procesamiento paralelo de todos los individuos, lo que lleva a la construcción de un algoritmo MOEA/D tensorizado, denominado TensorMOEA/D. En este algoritmo, la selección ambiental se divide en dos etapas principales: comparación y actualización de la población, y selección de soluciones de élite. Estas dos etapas se tensorizan principalmente a través de dos aplicaciones de la operación vmap. El proceso detallado se ilustra en la Fig. 3.
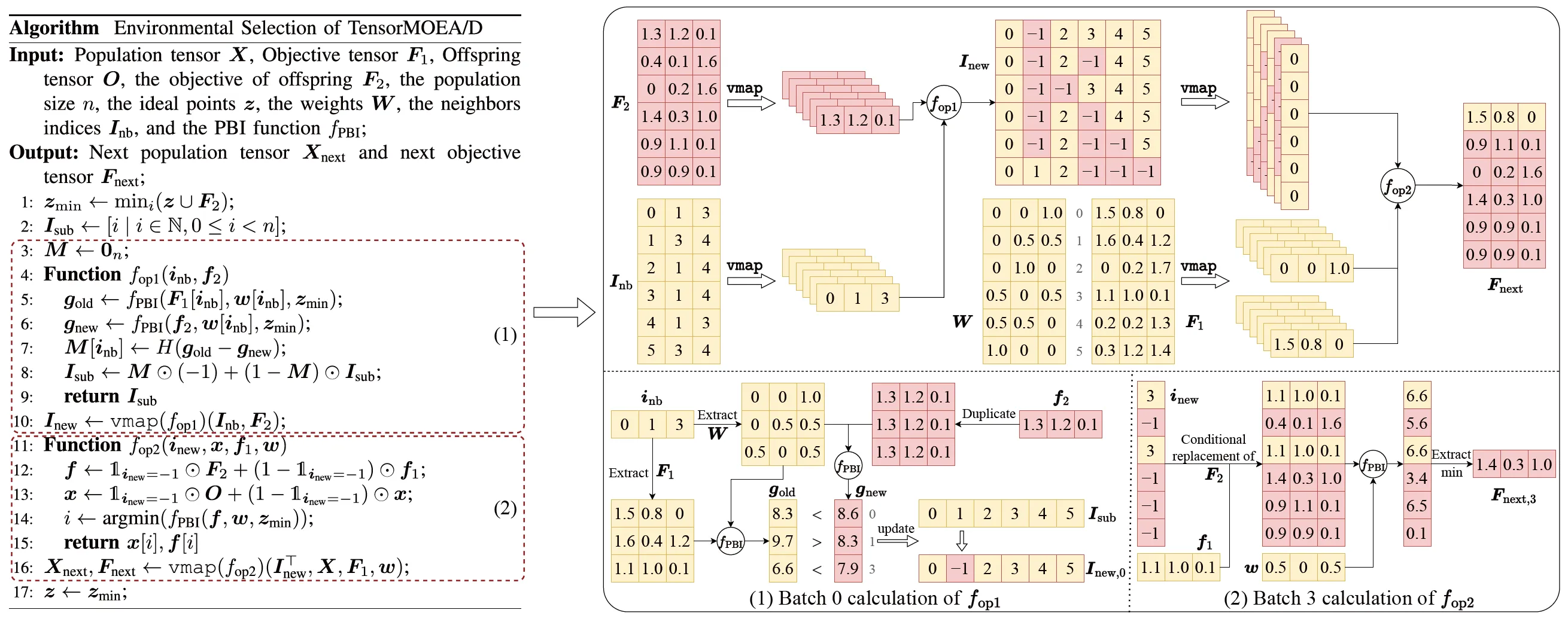

Fig. 3: Descripción general de la selección ambiental en el algoritmo TensorMOEA/D. Izquierda: Pseudocódigo del algoritmo. Derecha: Flujo de datos tensoriales del módulo (1) y el módulo (2). La parte superior de la figura derecha muestra el flujo de datos tensoriales general para los módulos (1) y (2), mientras que la parte inferior presenta el flujo de datos tensoriales de cálculo por lotes, con el módulo (1) a la izquierda y el módulo (2) a la derecha.
Para obtener una comprensión más completa del valor de la tensorización en los algoritmos EMO, se puede resumir desde tres perspectivas. Primero, la tensorización permite una transformación directa de las formulaciones matemáticas a un código eficiente, cerrando la brecha entre el diseño y la implementación del algoritmo. Por ejemplo, la Fig. 4 ilustra cómo el procedimiento de clasificación no dominada tensorizado puede traducirse directamente del pseudocódigo al código Python. Segundo, la tensorización simplifica significativamente la estructura del código al unificar las operaciones a nivel de población en una sola representación tensorial. Esto reduce la dependencia de bucles y sentencias condicionales, mejorando así la legibilidad y el mantenimiento del código. Tercero, la tensorización mejora la reproducibilidad de los algoritmos. Su representación estructurada facilita las pruebas comparativas y la reproducción consistente de los resultados.

Fig. 4: La transformación fluida de la clasificación no dominada tensorizada del pseudocódigo (Izquierda) al código Python (Derecha).
Demostración de Rendimiento
Para evaluar el rendimiento de los algoritmos de optimización multiobjetivo acelerados por GPU, el equipo de EvoX realizó sistemáticamente tres categorías de experimentos, centrándose en la aceleración computacional, el rendimiento de la optimización numérica y la efectividad en tareas de control robótico multiobjetivo.
Rendimiento de Aceleración Computacional:
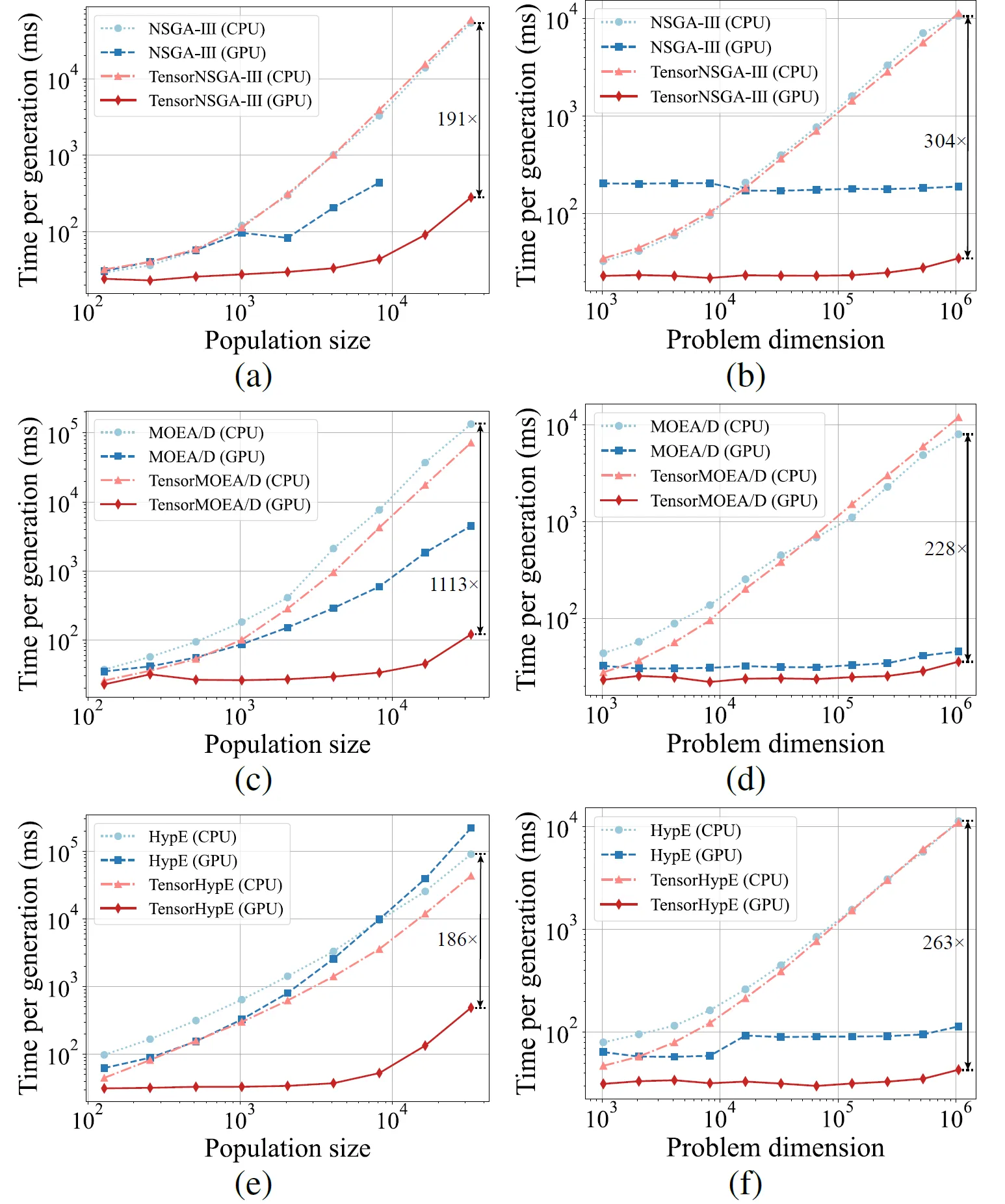
Fig. 5: Rendimiento de aceleración comparativo de NSGA-III, MOEA/D y HypE con sus contrapartes tensorizadas en plataformas CPU y GPU a través de varios tamaños de población y dimensiones de problemas.
Los resultados experimentales muestran que TensorNSGA-III, TensorMOEA/D y TensorHypE logran velocidades de ejecución significativamente más altas en GPUs en comparación con sus contrapartes basadas en CPU no tensorizadas. A medida que aumentan el tamaño de la población y la dimensionalidad del problema, la aceleración máxima observada alcanza hasta 1113x. Los algoritmos tensorizados demuestran una excelente escalabilidad y estabilidad al manejar tareas computacionales a gran escala; su tiempo de ejecución aumenta solo marginalmente, mientras mantienen un rendimiento consistentemente alto. Estos hallazgos resaltan las ventajas sustanciales de la tensorización para la aceleración por GPU en la optimización multiobjetivo.
Rendimiento en la Suite de Pruebas LSMOP:
Tabla II: Resultados Estadísticos (Media y Desviación Estándar) del IGD y el Tiempo de Ejecución (s) para Algoritmos EMO No Tensorizados y Tensorizados en LSMOP1–LSMOP9. Todos los Experimentos se Realizaron en una GPU RTX 4090 y se Resaltan los Mejores Resultados.
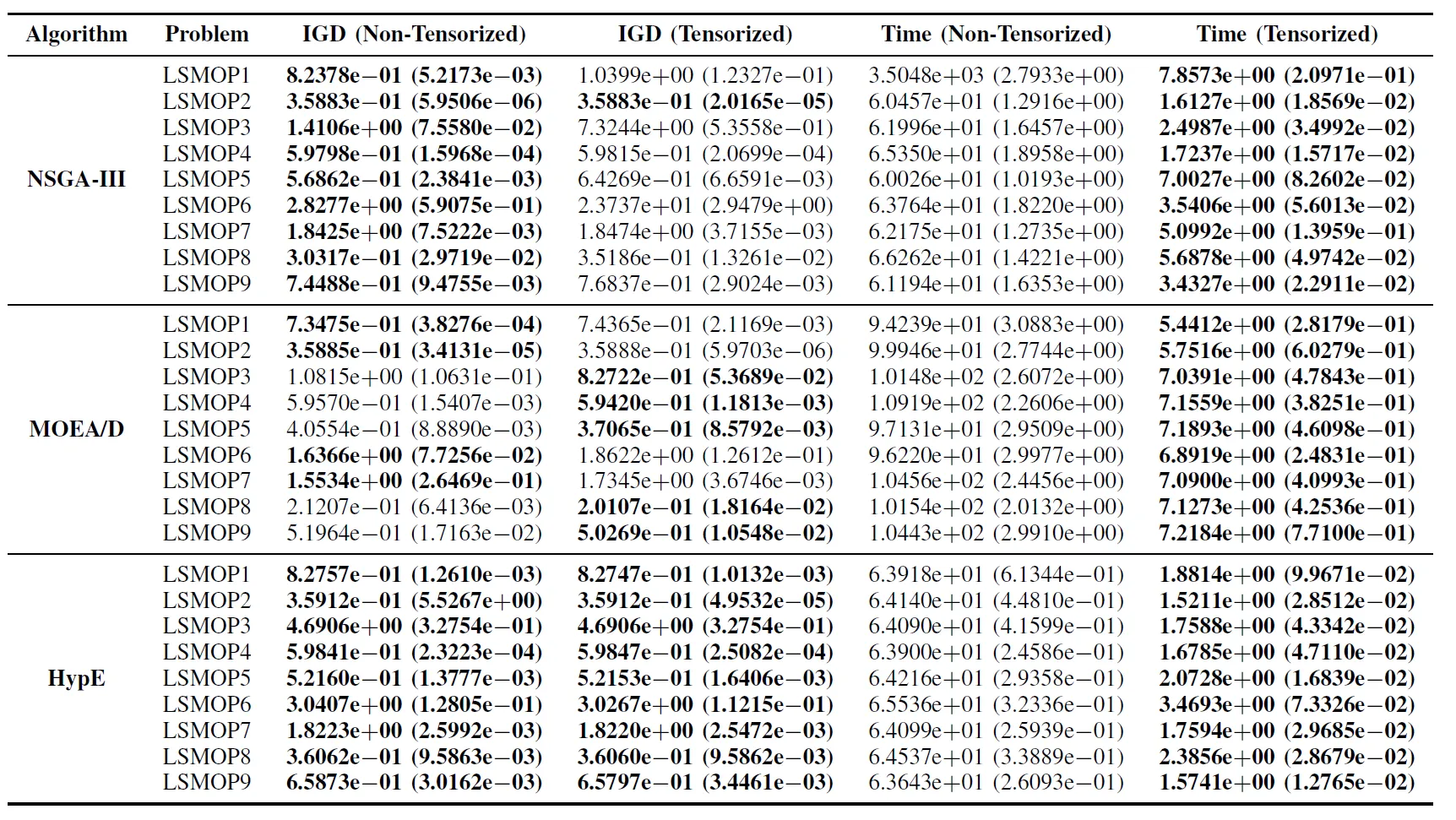
Los resultados experimentales indican que los algoritmos EMO acelerados por GPU basados en representaciones tensorizadas mejoran significativamente la eficiencia computacional mientras mantienen, y en algunos casos incluso superan, la precisión de optimización de sus contrapartes originales.
Tareas de Control Robótico Multiobjetivo:
Para evaluar exhaustivamente el rendimiento práctico de los algoritmos EMO acelerados por GPU, el equipo desarrolló una suite de pruebas llamada MoRobtrol para el control robótico multiobjetivo. Las tareas incluidas en esta suite se enumeran en la Tabla III.
Tabla III: Descripción General de los Problemas de Control Robótico Multiobjetivo en la Suite de Pruebas MoRobtrol Propuesta
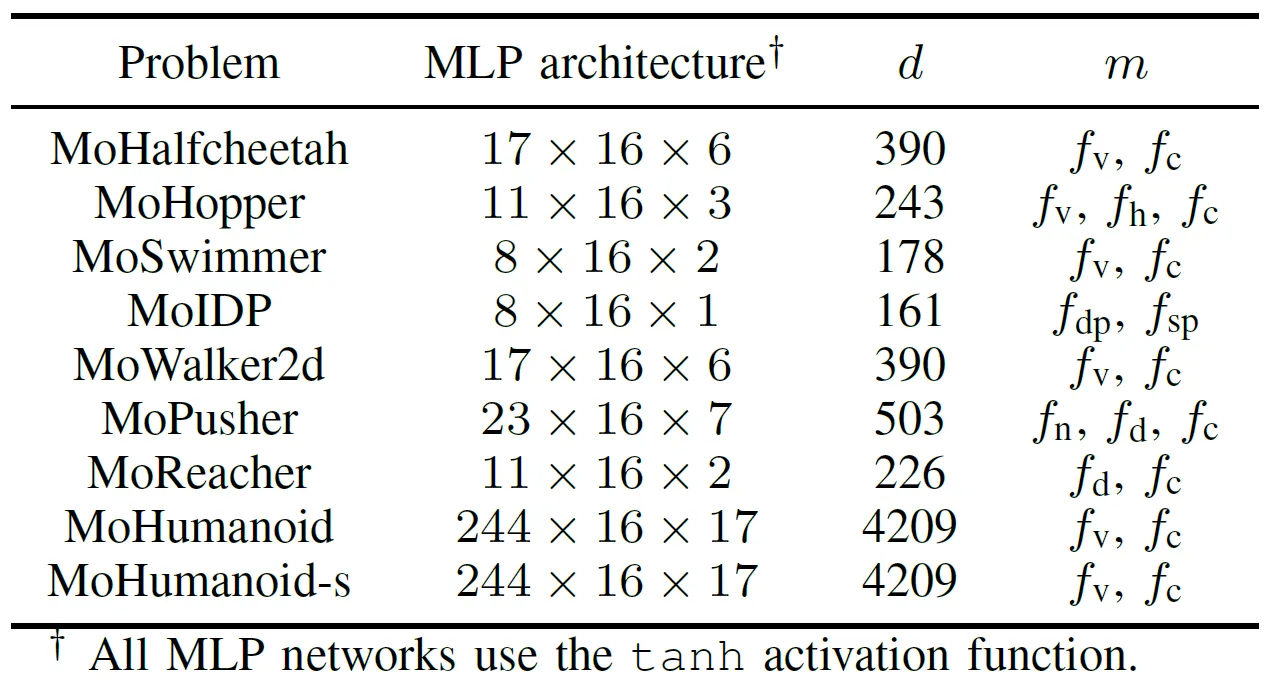
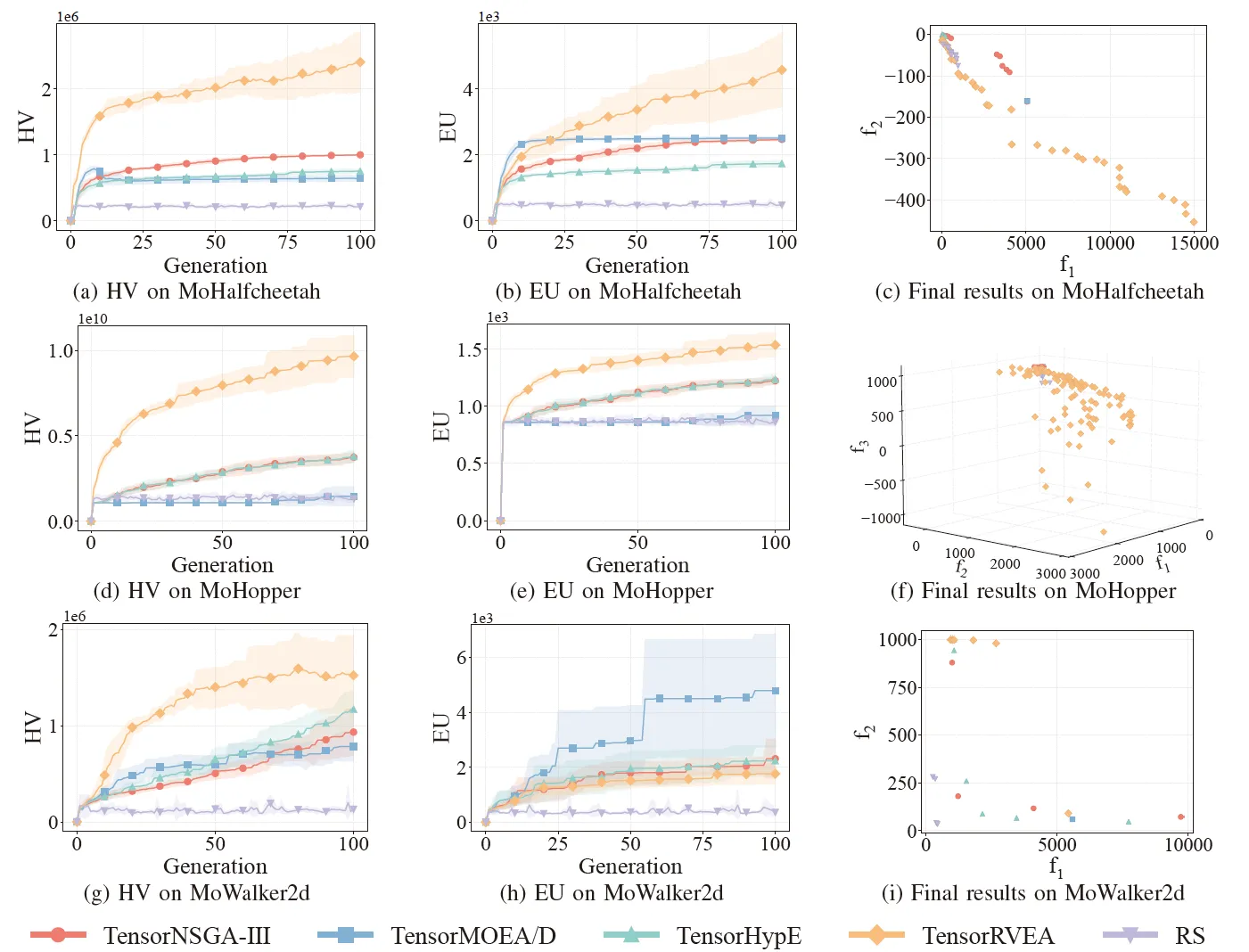
Fig. 6: Rendimiento comparativo (HV, EU y visualización de resultados finales) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA y búsqueda aleatoria (RS) en varios problemas: MoHalfcheetah (390D), MoHopper (243D) y MoWalker2d (390D). Nota: Los valores más altos para todas las métricas indican un mejor rendimiento.
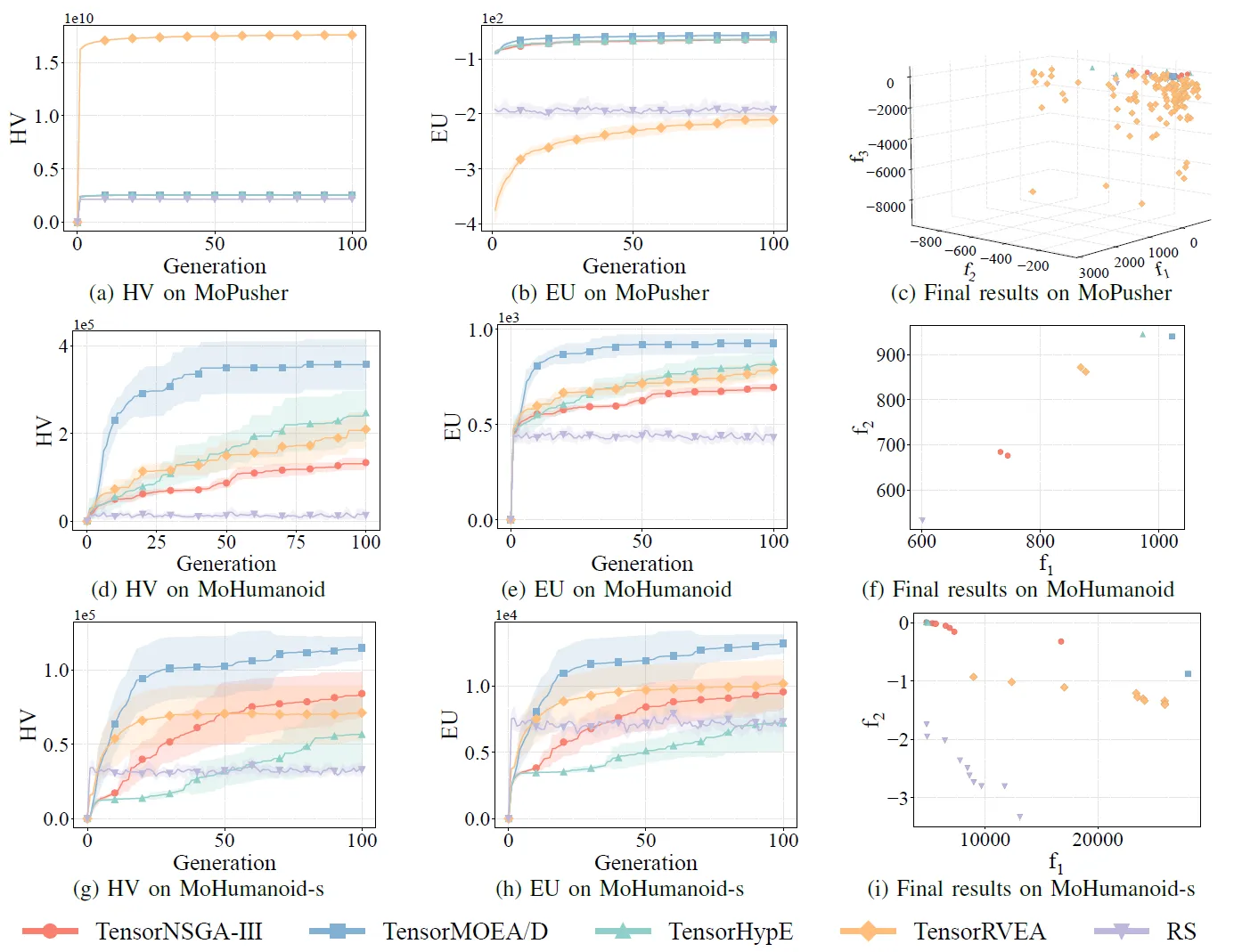
Fig. 7: Rendimiento comparativo (HV, EU y visualización de resultados finales) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA y búsqueda aleatoria (RS) en varios problemas: MoPusher (503D), MoHumanoid (4209D) y MoHumanoid-s (4209D). Nota: Los valores más altos para todas las métricas indican un mejor rendimiento.
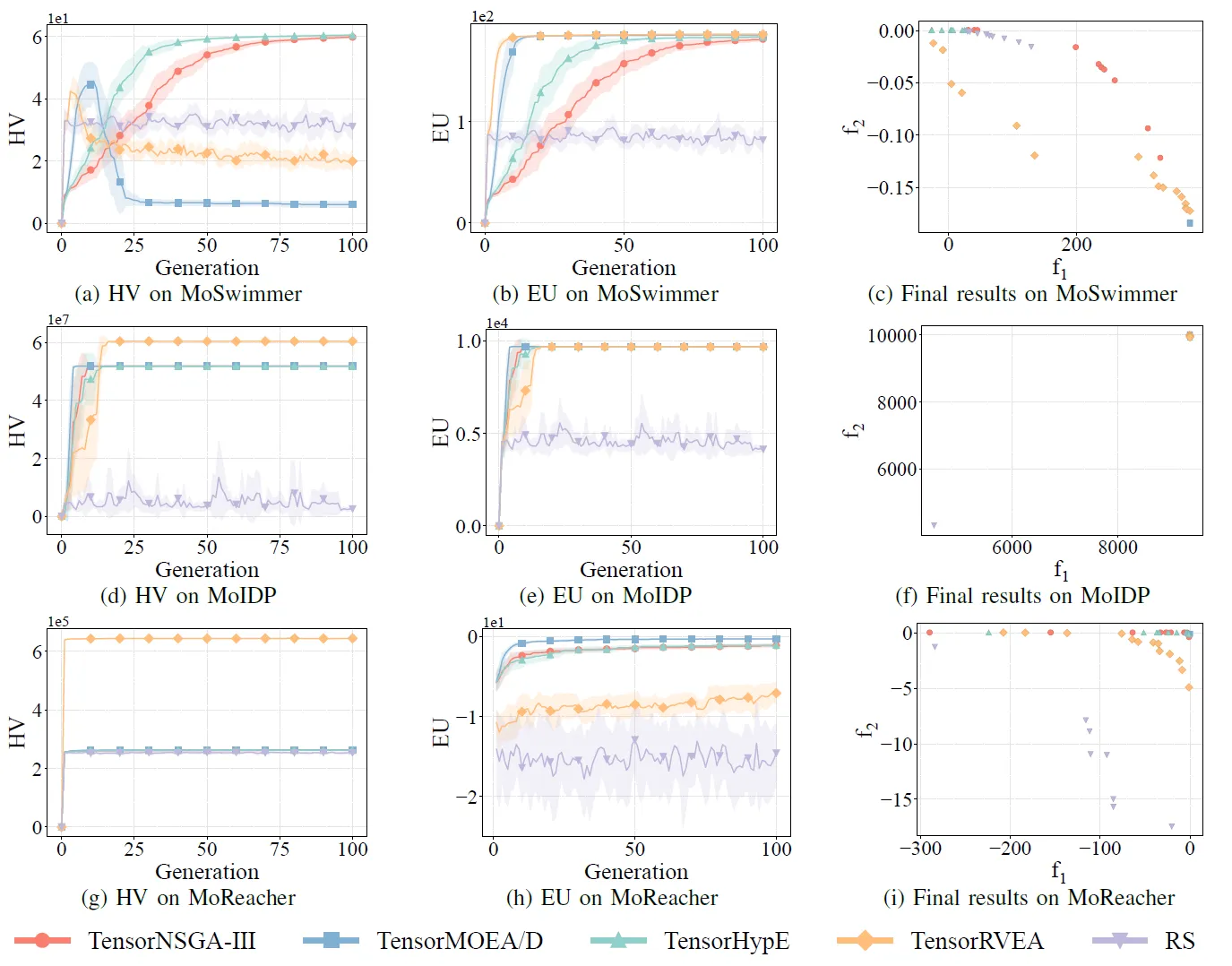
Fig. 8: Rendimiento comparativo (HV, EU y visualización de resultados finales) de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA y búsqueda aleatoria (RS) en varios problemas: MoSwimmer (178D), MoIDP (161D) y MoReacher (226D). Nota: Los valores más altos para todas las métricas indican un mejor rendimiento.
Los experimentos compararon el rendimiento de TensorNSGA-III, TensorMOEA/D, TensorHypE, TensorRVEA y Búsqueda Aleatoria (RS) dentro de la suite MoRobtrol. Los resultados muestran que TensorRVEA logró el mejor rendimiento general, obteniendo los valores de HV más altos y demostrando una buena diversidad de soluciones en múltiples entornos. TensorMOEA/D exhibió una fuerte adaptabilidad en tareas a gran escala, destacando particularmente en la consistencia de preferencia de las soluciones. TensorNSGA-III y TensorHypE mostraron un rendimiento similar y fueron competitivos en varias tareas. En general, los algoritmos basados en descomposición tensorizados demostraron ventajas superiores en la resolución de problemas complejos y a gran escala.
Conclusión y Trabajo Futuro
Este estudio propone una metodología de representación tensorizada para abordar las limitaciones de los algoritmos EMO tradicionales basados en CPU en términos de eficiencia computacional y escalabilidad. El enfoque se ha aplicado a varios algoritmos representativos, incluidos NSGA-III, MOEA/D y HypE, logrando mejoras significativas de rendimiento en GPUs mientras se mantiene la calidad de la solución. Para validar su aplicabilidad práctica, el equipo también desarrolló MoRobtrol, una suite de pruebas de control robótico multiobjetivo que reformula las tareas de control robótico en entornos de simulación física como problemas de optimización multiobjetivo. Los resultados demuestran el potencial de los algoritmos tensorizados en escenarios computacionalmente intensivos como la inteligencia incorporada (embodied intelligence). Aunque el método de tensorización ha mejorado sustancialmente la eficiencia algorítmica, aún queda margen para mejoras adicionales. Las direcciones futuras incluyen la mejora de los operadores principales, como la clasificación no dominada, el diseño de nuevas operaciones tensorizadas para sistemas multi-GPU y la integración de datos a gran escala y técnicas de aprendizaje profundo para mejorar aún más el rendimiento en problemas de optimización a gran escala.
Código de Fuente Abierta / Recursos de la Comunidad
Artículo:
https://arxiv.org/abs/2503.20286
GitHub:
https://github.com/EMI-Group/evomo
Proyecto Principal (EvoX):
https://github.com/EMI-Group/evox
Grupo de QQ: 297969717

EvoMO está construido sobre el framework EvoX. Si está interesado en aprender más sobre EvoX, no dude en consultar el artículo oficial sobre EvoX 1.0 publicado en nuestra cuenta pública de WeChat para obtener más detalles.
